



MySQL索引
部分参考资料链接
B+树的生成方式:动画讲解:MySQL的B+树根页不动,插入数据和页分裂原理_哔哩哔哩_bilibili
为什么要使用B+树:深入理解Mysql索引底层原理(看这一篇文章就够了)-CSDN博客
哈希索引与B+树索引的终极对决:为何B+树成为数据库索引的王者?-CSDN博客
全文索引:MySQL全文索引深度解析:从原理到实战,解锁高效文本搜索_mysql 全文搜索-CSDN博客
mysql核心知识之全文索引的使用_in boolean mode-CSDN博客
索引分类:MySQL索引:7大类型+4维分类_mysql索引类型-CSDN博客
语法和问题:MySQL索引详解:从原理到实战,一文吃透索引核心知识点_mysql索引原理-CSDN博客
优化器:MySQL优化器为什么会选错索引?_哔哩哔哩_bilibili
索引的问题:小林coding | MySQL部分
一、索引是什么
索引是数据库中为了加快查询速度而建立的辅助数据结构,它通过记录“键值 → 数据位置”的映射,减少数据查找的范围。
可以把索引理解成“书的目录”:
- 没有索引 → 一本书从第一页翻到最后(全表扫描)
- 有索引 → 直接查目录找到页码(快速定位)
二、为什么需要索引,索引的作用
索引的核心价值只有一个:减少磁盘IO次数,提升查询效率。
索引并非只有“优点”,它也有代价——索引会占用额外的存储空间,且插入、更新、删除数据时,需要同步维护索引(比如插入一条数据,既要存数据,也要更新索引结构),会略微降低写操作的效率。因此,索引不是“建得越多越好”,而是要“按需建”。
三、索引分类
1. 按数据结构分
1. B+树索引
2. Hash索引
3. 倒排索引(全文索引)
什么是倒排索引?
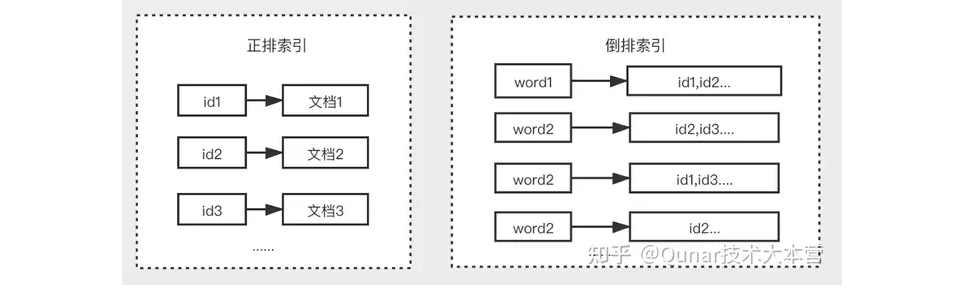
传统索引:文档 → 单词列表
倒排索引:单词 → 包含该单词的文档列表
4. R-Tree索引(空间索引)
2. 按存储结构分
1. 聚簇索引:叶子结点存储索引和数据
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则innoDB会自动生成一个rowid作为隐藏的聚集索引。
2. 非聚簇索引:叶子结点只包含主键值,查询需回表:通过主键值到聚簇索引中查找数据
 PS: 这个表下面应该是双向链表
PS: 这个表下面应该是双向链表
3. 按字段特性分
1. 主键索引
唯一,不允许为NULL。
innodb中一定是聚簇索引。
自动创建。
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY -- 列级定义
);
-- 或表级定义
ALTER TABLE users ADD PRIMARY KEY (id);
2. 唯一索引
唯一,可为NULL
CREATE UNIQUE INDEX uq_email ON users(email);
3. 普通索引
只是加速查找,无特点
CREATE INDEX idx_age ON users(age);
4. 前缀索引
- 对文本列前N个字符建立索引
- 大幅减少索引空间
-- 对address列前10字符建索引
CREATE INDEX idx_addr_prefix ON users(address(10));
4. 高级索引类型
1. 联合索引
通过将多个字段组合成一个索引,该索引就被称为联合索引。
最左前缀原则
即
CREATE INDEX idx_age_name_sex ON users(age,name,sex);
当条件跳过age时不使用索引,当中间断层时,不使用索引。
age相同,找name,name相同,找sex。
2. 覆盖索引
即你要找的字段在索引中全都可以得到,而不需要回表。
覆盖索引是一种索引优化手段。
覆盖索引就是用空间(更大的索引)换时间(不回表)。
3. 函数索引(MySQL 8.0+)
当我们创建了一个
-- 假设在 birth_date 列上有普通索引
CREATE INDEX idx_birth ON user(birth_date);
-- 这个查询用不上索引!
SELECT * FROM user WHERE YEAR(birth_date) = 1990;
原因:索引存储的是 birth_date 的原始值,而查询条件是对它做了 YEAR() 函数计算。数据库无法把 YEAR(birth_date)=1990 映射到 birth_date 的原始值范围。
这时候就需要函数索引了
-- MySQL 8.0+ / PostgreSQL 等支持
CREATE INDEX idx_birth_year ON user((YEAR(birth_date)));
-- 现在可以用索引了
SELECT * FROM user WHERE YEAR(birth_date) = 1990;
四、MySQL中怎么实现索引以及MySQL为什么要使用B+树而不是其他
1. 哈希索引

我们知道,哈希索引是通过哈希函数转换一个哈希值,通过哈希值去找数据。
哈希索引的查找过程:
键值: ‘Alice’ --> 哈希函数 --> 哈希值: 0x8A3D --> 映射到桶#3 --> 指向数据行地址
这种查询方式在精准的等值查询情况下固然很快,但如果发生哈希冲突呢?如果发生大量的哈希冲突呢?
但是实际的应用场景下,用户还需要范围查询、排序查询、最值查询、模糊查询等等,而这些哈希索引都满足不了。
2. 二叉搜索树
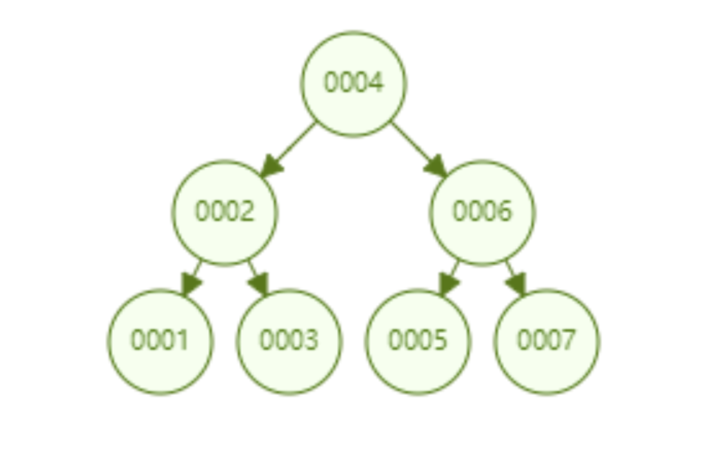
说到二叉搜索树,就不得不说其致命缺点了,在一种极端的情况下,我们按从小到大的顺序插入数据,那么二叉树就可能变成

这是不被允许的,如果这样的话,那么查找的速度将会极其慢。
而且我们知道,mysql的主键一般都是自增的,如果采用这个作为底层,那么这种情况的出现是必然的。
3. AVL树(平衡二叉树)和红黑树
红黑树:

红黑树虽然解决了像之前二叉搜索树那样极端情况,但是还是可能出现右倾的趋势

所以红黑树也不适用。
那AVL树呢?

说到AVL树,我们知道它有一个旋转功能,使得其平衡因子维持在1以下(即左右子树高度差不超过1),那么AVL树能否使用呢?
其实看起来AVL树没有什么短板,但是其查找效率还可以优化。
我们知道,但凡是二叉树,它一个节点就只能有一个数据,那么这对于磁盘IO来说是不够友好的,因为我们每次进行一次磁盘IO只能取出一个数据,这肯定是不行的,那么怎么减少磁盘IO的次数呢?
4. B树

同样的一组数据,我们可以明显看到B树的高度要远远低于AVL树,这也就意味着我们磁盘IO的次数就变少了,性能就提升了。
那么能否继续优化呢?
5. B+树

这里我们可以看到,B+树相对于B树,非叶子结点只存储索引,让每一个固定大小的节点(数据页)可存储的索引数目增多,也就意味着树变矮了,磁盘IO的次数就变少了。
同时这种方式更加稳定,更符合程序员对稳定的追求。
同时B+树相对于B树的底层叶子结点之间还有一个链表相连,这对于范围查找非常有帮助。
由于B+树有大量的冗余节点,导致B+树的增删效率相较于B树效率更快。
其实MySQL底层的B+树结构与此不同,
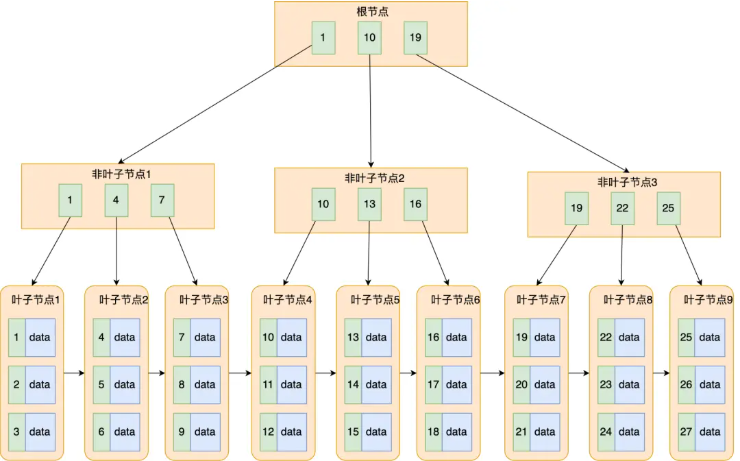
InnoDB的实现没有浪费空间去存储多余的指针,每个索引记录天然就携带一个子节点指针。
MySQL的B+树叶子结点之间使用的是双向链表。
InnoDB 主要使用 B+树 作为索引结构,同时在内部通过自适应哈希索引对热点查询进行优化。
InnoDB的自适应哈希索引:
这是一个精妙的“黑科技”。InnoDB会自动监测频繁访问的B+树索引页,并在内存中为这些热点数据构建一个哈希索引。这样,应用无需感知,即可享受到哈希的O(1)查询速度,同时保留了B+树的所有优势。这本质上是数据库内部的自我优化,而非用户可操控的结构。
五、一点索引优化
索引的本质是“以空间换时间”:必须权衡查询加速与写入维护成本。
索引不是万能的:应清醒认识索引失效的必然场景(如小表、低选择性列)。
必备的 EXPLAIN 分析工具:重点解读 type、key、rows 和 Extra 等关键列。
慢查询日志分析工具:如 pt-query-digest,可聚合分析慢查询日志,快速定位问题。
自动化索引优化:云数据库服务通常提供自动SQL优化功能,可自动识别问题SQL并生成优化建议。
利用 Index Condition Pushdown (ICP索引下推):在 MySQL 5.6+ 中,可在索引层面直接过滤部分数据,减少回表次数。
注意:
优化器也会出错
优化器为什么会出错呢?
答:MySQL 优化器不是“算出最优方案”,而是基于统计信息“估算哪个成本更低”,但统计不准或模型简化时,就会选错索引。


















 4195
4195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










