



NVIDIA 发布 LocateAnything-3B!面向视觉定位任务的 3B 级视觉语言模型。
模型定位
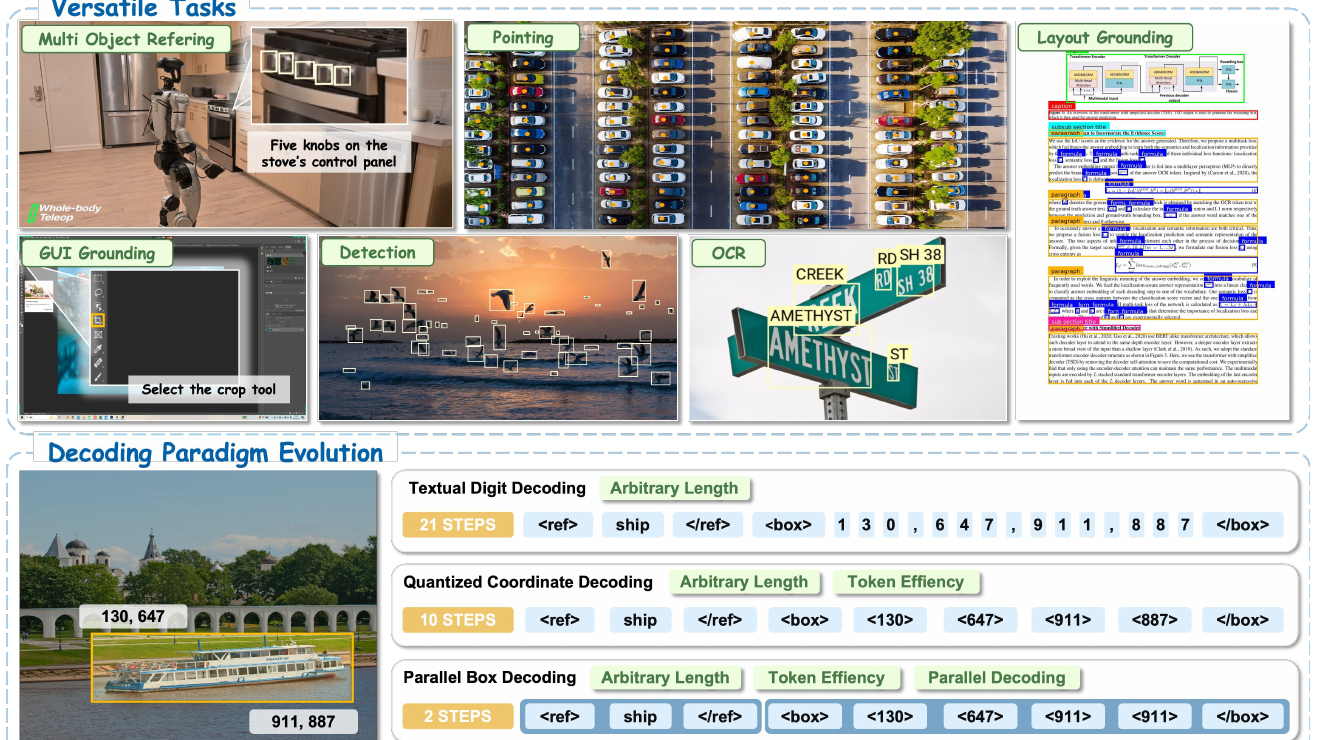
LocateAnything-3B 是一个用于快速、高质量 visual grounding 的视觉语言定位模型。它接收图像和文本指令作为输入,输出目标在图像中的结构化位置结果,包括 bounding box 或 point。
与传统目标检测模型相比,LocateAnything-3B 不局限于固定类别,而是能够基于自然语言描述完成开放式定位。它覆盖开放目标检测、密集目标检测、指代表达理解、GUI 元素定位、OCR 文本定位、文档布局定位和点定位等任务。
它的核心价值在于:让多模态模型不仅能理解图像内容,还能输出可解析、可使用的空间坐标结果。
核心创新
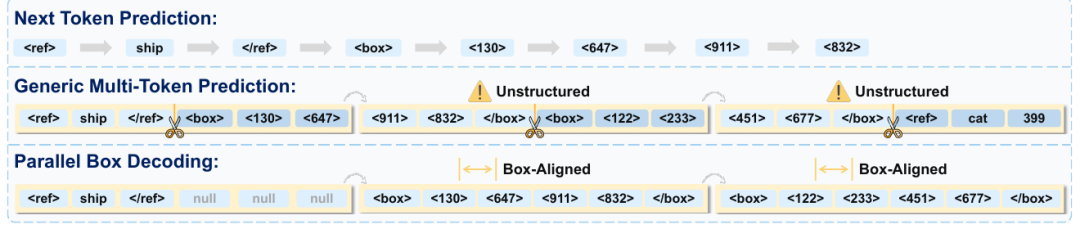
LocateAnything-3B 最重要的技术创新是 Parallel Box Decoding,即把一个框作为完整的原子单元生成,而不是将其拆散为多个独立 token。
LocateAnything-3B会把bounding box或 point 视为结构化空间单元,在一个并行步骤中预测完整坐标。这种方式更贴合视觉定位任务的本质:目标框不是普通文本,而是具有内部约束关系的空间结构。
传统坐标解码像是逐个拼接坐标数字;PBD 则更像是直接生成完整空间单元。因此,它能够在提升解码吞吐的同时,增强目标框内部的结构一致性。
模型结构
LocateAnything-3B 并不是简单地在视觉语言模型后面增加检测模块,而是把定位任务重新组织成结构化生成问题。
模型整体由视觉编码器、语言解码器和中间投影模块组成。视觉编码器负责提取图像中的细粒度视觉信息,语言解码器结合图像信息和文本指令生成定位结果,中间的 projector 用于连接视觉特征与语言模型。
LocateAnything-3B 的输出采用 block-based output formulation。它不把定位结果看作普通文本序列,而是将输出组织成固定长度的功能块。
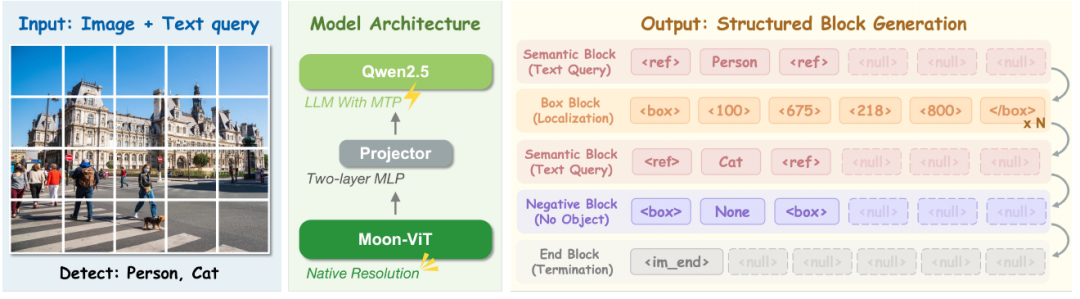
这种结构化输出让定位结果更加规范,也更便于后续系统解析。对于 visual grounding 来说,模型最终输出的不是自然语言描述,而是可以直接被程序读取的空间结果。
三种推理模式
Parallel Box Decoding 可以提升推理效率,但复杂视觉场景中仍然可能出现格式异常或空间歧义。为此,LocateAnything-3B 设计了三种推理模式:Fast Mode、Slow Mode 和 Hybrid Mode。
Fast Mode 主要使用并行解码,一次生成完整的 box-aligned block,优势是速度快,适合低延迟任务。
Slow Mode 使用传统 next-token prediction,逐 token 生成坐标,速度较慢,但稳定性更强。
Hybrid Mode 是默认平衡方案。它优先使用并行解码,在检测到不可靠输出时,局部回退到逐 token 解码进行修正。
这种机制可以概括为:简单区域快速生成,复杂区域局部校正。Hybrid Mode 并不是在速度和精度之间做单一取舍,而是动态结合两种解码方式。它保留了 PBD 的速度优势,也提升了复杂场景下的鲁棒性。
大规模数据支撑通用定位能力
高质量视觉定位能力不仅来自模型结构,也依赖训练数据规模与覆盖范围。
LocateAnything-3B 使用的 LocateAnything-Data 覆盖多种视觉定位任务,包含:12M unique images、138M language queries、785M annotated bounding boxes。
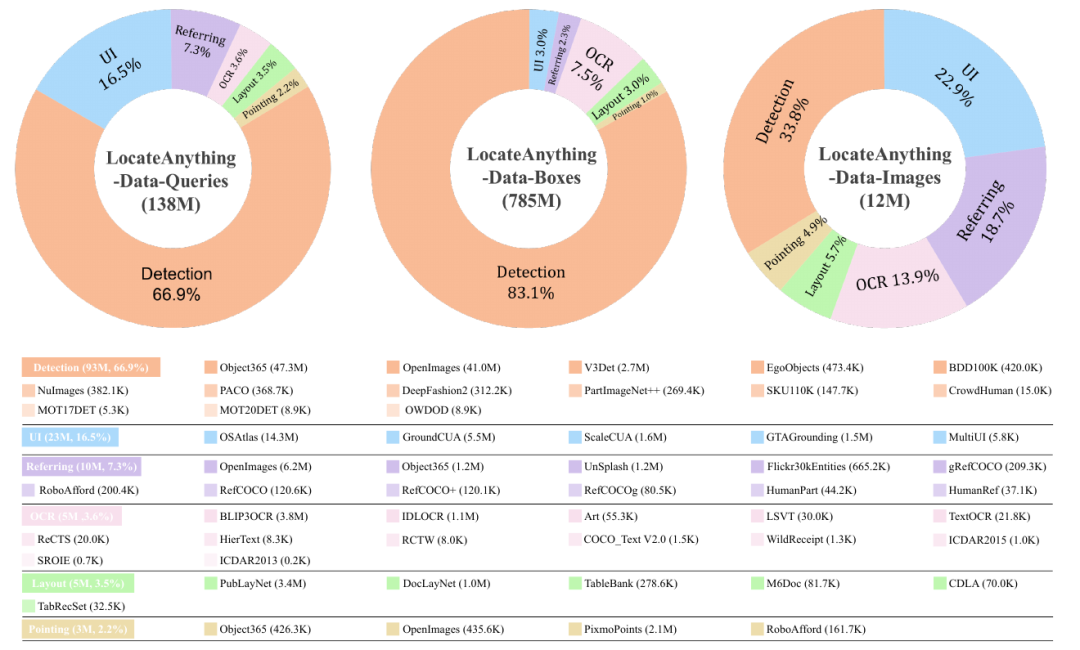
数据任务中,通用目标检测是数据主体,在 queries中占比约 66.9%,在 boxes中占比约 83.1%。GUI grounding占 queries 的 16.5%,referring comprehension占 7.3%,OCR文本定位占 3.6%,layout grounding占 3.5%,point-based localization占 2.2%。
这种数据构成使 LocateAnything-3B 不只学习单一检测能力,而是在多个任务之间建立统一的空间对齐能力。它能够处理自然场景、界面截图、文档版面、文字区域和点位预测等多种视觉定位形式。
实验表现:更快,也更准
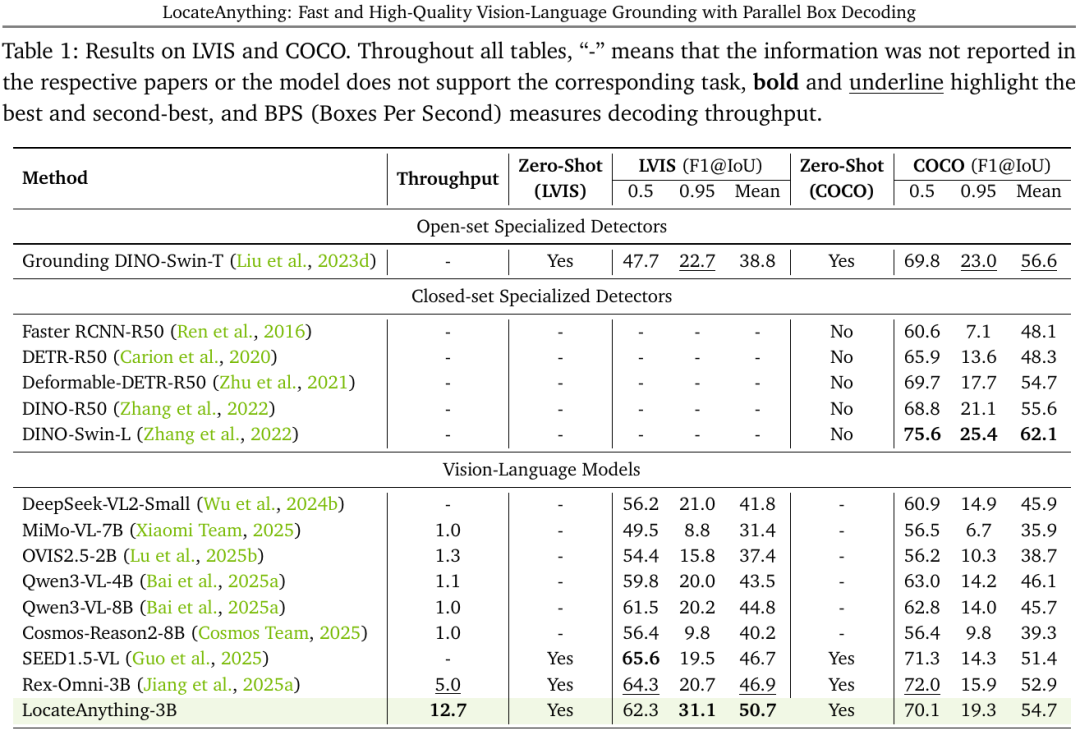
LocateAnything-3B 的核心优势,不只是提升了推理速度,而是在更快的同时保持了较高的定位质量。
传统视觉语言模型通常需要逐个生成坐标 token,推理链路较长。LocateAnything-3B 通过 Parallel Box Decoding,将目标框作为完整结构并行生成,从而显著提升了解码效率。
在多类视觉定位任务中,它都展示出较强的稳定性,包括通用检测、密集检测、GUI grounding、文档布局定位和 OCR 文本定位等。尤其是在高精度定位场景下,模型不仅能找到目标,也能更准确地贴合目标边界。
整体来看,LocateAnything-3B 的意义不只是“更快”,而是通过结构化、并行化的坐标生成方式,让视觉语言模型在速度、精度和泛化能力之间取得了更好的平衡。
LocateAnything-3B 的意义,不只是发布了一个新的 3B 级视觉语言模型。更重要的是,它展示了一种新的视觉定位思路:把坐标生成从普通 token 序列中解放出来,重新组织为更符合空间结构的 box-level decoding。
LocateAnything-3B 将语言理解和空间定位更紧密地结合起来,使模型从“看懂图像”进一步走向“找准目标”。Parallel Box Decoding 提升了解码效率,block-based output 增强了输出结构,Hybrid Mode 平衡了速度与稳定性,大规模 LocateAnything-Data 则为模型提供了多任务空间理解基础。
如果说多模态模型的第一阶段是理解图像内容,那么 LocateAnything-3B 代表的方向,就是让模型进一步具备精确的空间感知能力。未来的视觉语言模型,不仅要知道图像中有什么,还要知道它在哪里,并把这个位置结果交给后续系统使用
社区地址
OpenCSG社区:
https://opencsg.com/models/nvidia/LocateAnything-3B
Hugging Face社区:
https://huggingface.co/nvidia/LocateAnything-3B
关于OpenCSG
OpenCSG是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论,由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。


















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










