



AI 编码模型的竞争,已经从“谁能写出一段更漂亮的代码”,走到了更难的一层:模型能不能读懂一个完整仓库?能不能在多轮执行里记住最初的约束?能不能改完代码、看懂报错、继续修,最后把任务收口到一个可验证的结果?
GLM-5.2这次升级,瞄准的就是这些更接近真实开发现场的问题。1M 上下文、可调思考强度、工具调用、上下文缓存、结构化输出,再加上IndexShare和MTP带来的推理效率优化,让它看起来更像一个能长期跟着项目走的工程搭档。
前端榜单杀到第 2:GLM-5.2 先把实力摆上桌
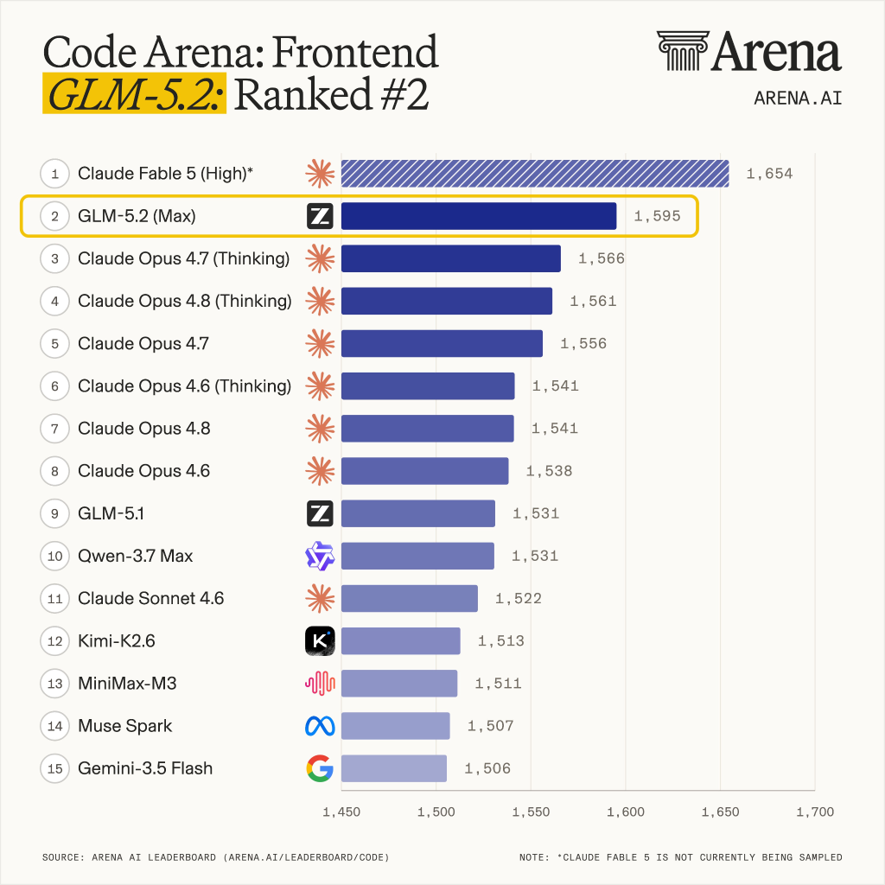
在 Code Arena: Frontend榜单中,GLM-5.2 Max以1595分排到第2,仅次于Claude Fable 5(High),同时高于多款Claude、Qwen、Kimi、MiniMax与Gemini模型。前端榜单不是简单的刷题场。它考的是模型对需求、布局、组件、状态和交互的综合把握,也考输出代码能不能真的跑起来。
GLM-5.2 已经在一个高关注的真实编码赛道里冲进了前列。对开发者来说,这比泛泛而谈“代码能力提升”更有说服力。
更重要的是,前端能力往往很难靠“模板答案”蒙混过去。按钮位置不对、组件状态没接上、样式细节塌掉,用户一眼就能看出来。GLM-5.2能在这个榜单里排到第2,说明它对产品形态和代码实现之间的关系有了更好的把握。这种能力对实际业务很有用。很多团队缺的不是一个能写几行代码的助手,而是一个能把需求翻译成可运行界面的模型。
1M 上下文:终于能把项目背景一次讲清楚
GLM-5.2的1M上下文,最有价值的地方不在数字本身,而在它改变了任务的颗粒度。以前让模型处理一个复杂项目,常常要把代码、需求、日志、配置、测试结果拆成一段一段喂进去。人负责补上下文,模型负责局部回答。到了长任务后半段,它很容易忘掉前面的约束。
1M 上下文让情况变得不一样。代码、文档、接口说明、报错堆栈、历史决策,可以被放进同一个工作面里。模型读到的材料更多,也更有机会沿着同一条任务线继续往下做。项目盘点、技术债梳理、接口迁移、中等规模重构、测试补齐、文档整理,这些过去很容易被切碎的工作,开始变得适合交给模型连续推进。再加上最大128K的输出能力,GLM-5.2在长答案、长 patch、长报告上也留出了足够空间。
让模型改一个跨模块接口,前面讲过的兼容策略、测试边界、命名习惯,后面仍然要记得住。否则它改得越多,风险越大。长上下文的价值就在这里:让模型少一点“半路失忆”,多一点持续工作的手感。
会写代码还不够,能跑完整流程才稀缺
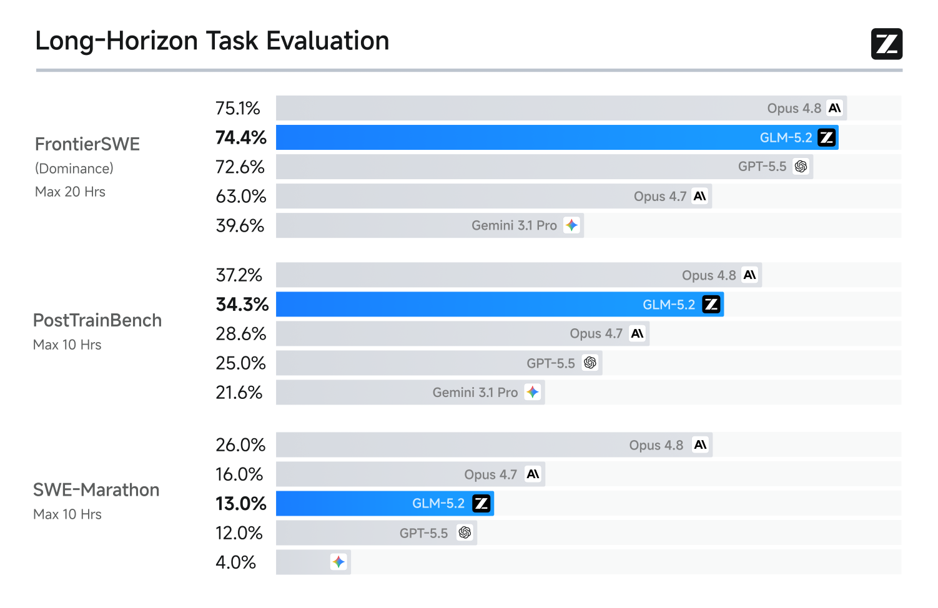
GLM-5.2 的亮点,不在单轮问答里,而在Coding Agent和长程软件工程任务里。Terminal-Bench 2.1、SWE-bench Pro、MCP-Atlas、FrontierSWE等基准上,它相比GLM-5.1有明显提升;在PostTrainBench 和SWE-Marathon这类更长的任务里,也展现出开放模型中少见的持续执行能力。
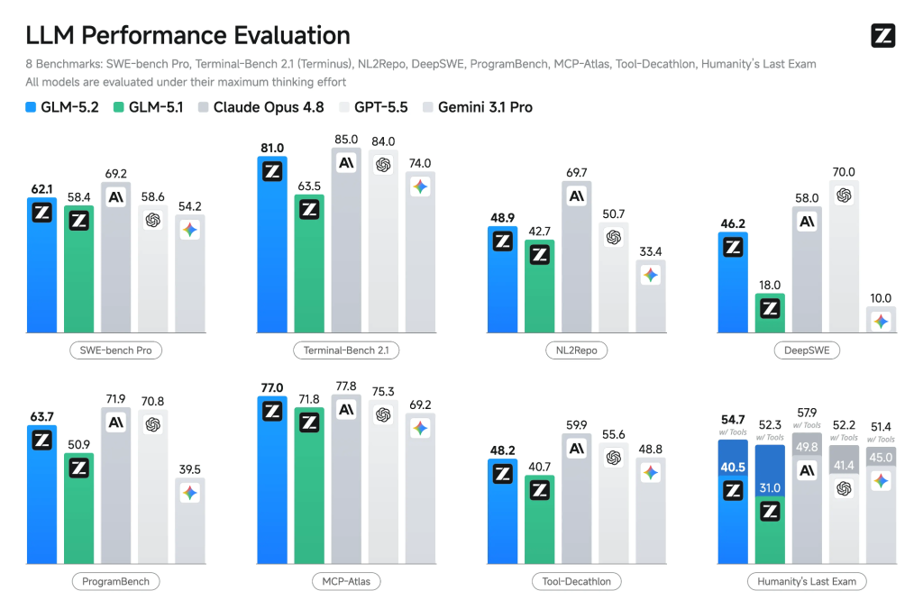
这些评测看的不是“回答像不像正确答案”,而是模型能不能完成一条完整链路:理解任务,拆步骤,调用工具,修改文件,看反馈,再继续验证。真实开发就是这样。很少有任务一次就对,更多时候是反复试、反复改、反复确认。GLM-5.2 的进步,恰好落在这条链路上。
它并没有把AI Coding停在“更快生成”这一层,而是往执行过程里走:先弄清楚要改什么,再决定怎么改,改完还能继续看结果。模型越往这里走,越接近工程师每天面对的工作。
可快可深:GLM-5.2 把“思考强度”交给任务决定
模型能力变强之后,一个很现实的问题会冒出来:是不是每个任务都要用最高强度去跑?显然没必要。修一个小样式、解释一段日志、补一个单测,和改跨模块架构、跑长程debugging,不该消耗同样的推理预算。GLM-5.2 把effort level做成可调选项,意思很直接:简单任务快一点,难题再多想一会儿。
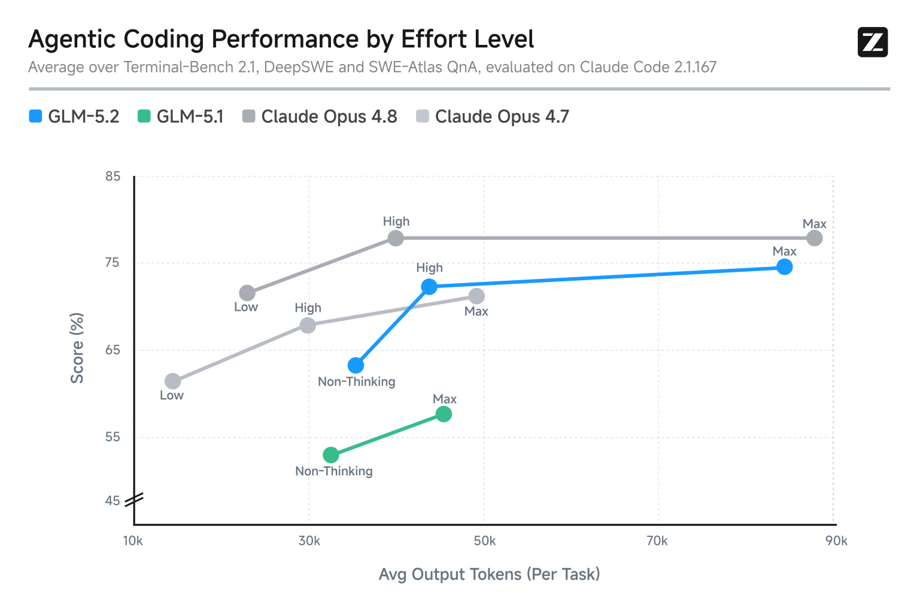
GLM-5.2从Non-Thinking到High,再到 Max,曲线一路往上;在相近token消耗下,明显拉开GLM-5.1,并进入Claude Opus 4.7 和Opus 4.8附近的区间。对团队来说,这不是一个小开关,而是把成本、速度和效果放到同一张表里管理。
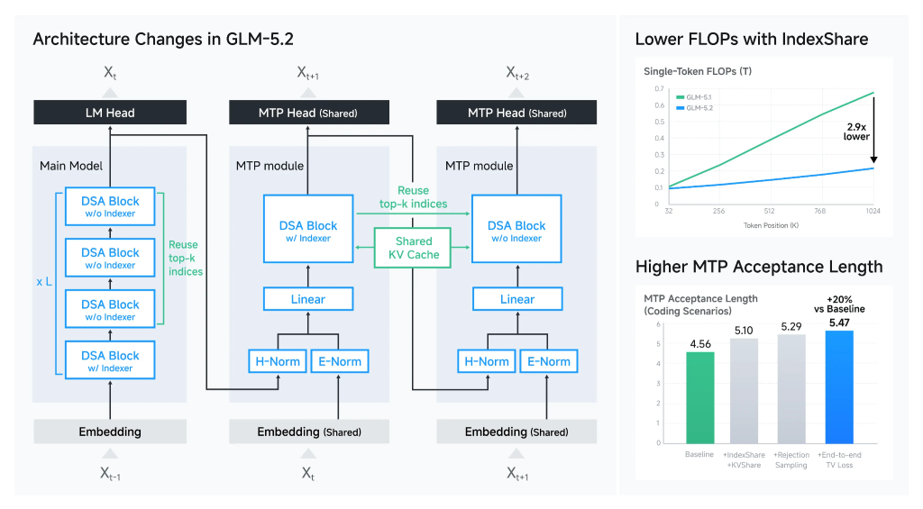
当然,只能调 effort 还不够。长上下文要长期用,底层计算也得省下来。IndexShare会在稀疏注意力层之间复用indexer,减少长上下文定位信息时的重复计算;在1M 上下文长度下,单token FLOPs相比GLM-5.1最多可降低 2.9 倍。MTP 结构也做了优化,用于speculative decoding 的acceptance length提升到 5.47,相比基线约提高 20%。
从试用到工作流:它更像一个工程搭档
GLM-5.2 更有意思的地方,是它把“强”落在了真实工作里。它会回答算法题,也能给出代码;更重要的是,它能在长上下文里理解目标、记住约束、处理反馈,把复杂任务一步步往前推。
个人开发者可以怎么用?不要只让它写一个孤立 demo。把它放进真实项目里,让它读仓库结构、解释架构、定位耦合点、生成重构方案、补测试、写文档、整理风险清单。团队里也一样。repo 问答、代码审查辅助、迁移规划、CI/CD 故障分析、工具编排式开发,都是更适合检验 GLM-5.2 的场景。
上一阶段 AI Coding 主要解决“写得更快”。GLM-5.2 代表的方向更进一步:把复杂任务往交付阶段推。工程师当然仍然要定义目标、设边界、做判断,但模型能承担的那部分工作正在变长,也变重。
结语:GLM-5.2 不是只会写代码,它在靠近工程生产力
回头看GLM-5.2,它最值得关注的地方不是某一个单点能力,而是几个能力开始合在一起:前端榜单冲到第2,1M上下文能装下更完整的项目背景,长程任务评测开始看重流程闭环,IndexShare和 MTP又把成本问题往下压了一层。AI Coding正在从“生成代码”走向“推进工程”。GLM-5.2站在这个变化里,而且位置很靠前。
社区地址
OpenCSG社区:
https://opencsg.com/models/zai-org/GLM-5.2
Hugging Face社区:
https://huggingface.co/zai-org/GLM-5.2
关于OpenCSG
OpenCSG是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论,由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。


















 6991
6991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










