




ThunderAgent: 简单快速且程序感知的智能体推理系统
随着大语言模型(LLM)在复杂多轮智能体工作流中的广泛应用,如何高效处理这些工作流成为了一个关键挑战。ThunderAgent 提出了一个简单、快速且程序感知的智能体推理系统,通过统一的程序抽象和智能调度策略,实现了显著的吞吐量提升和资源优化。
论文标题: ThunderAgent: A Simple, Fast and Program-Aware Agentic Inference System
来源: arXiv:2602.13692v1 + https://arxiv.org/abs/2602.13692
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
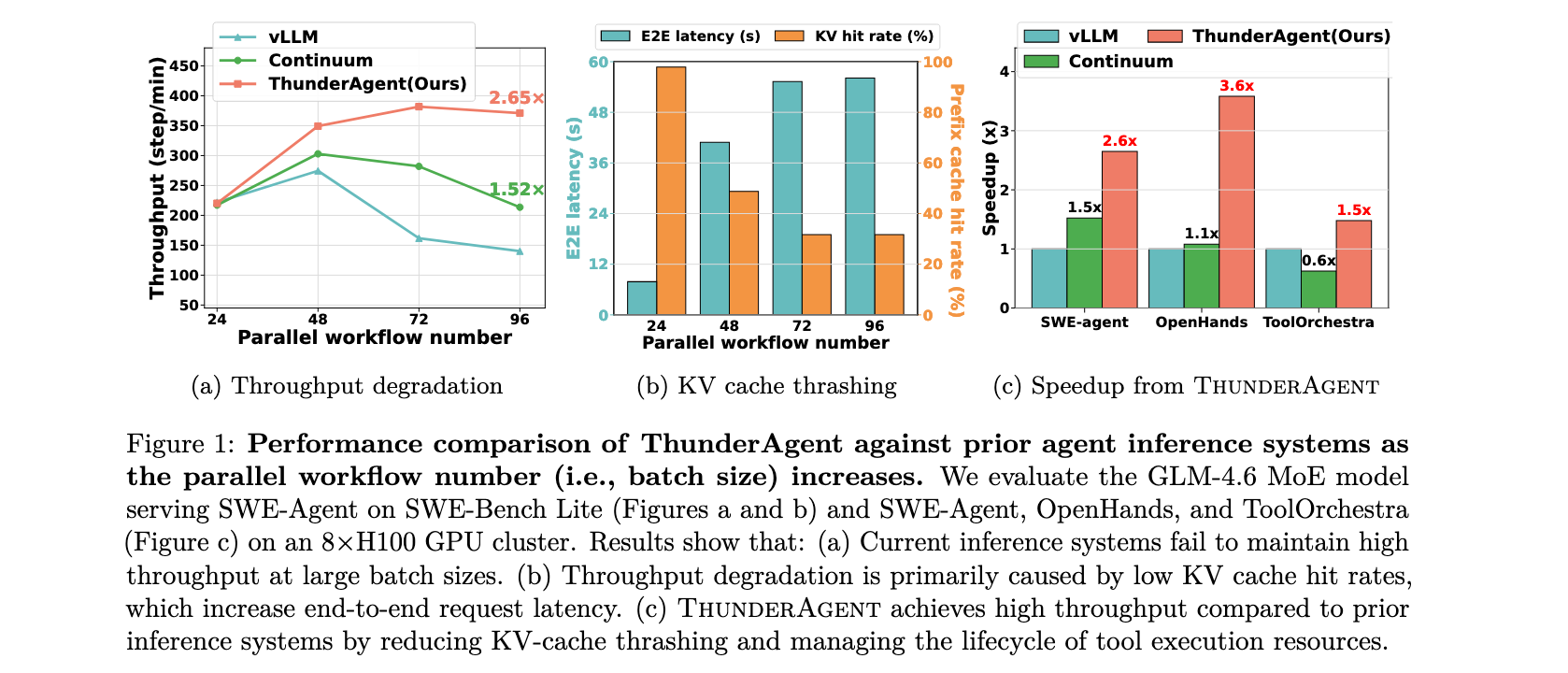
随着大语言模型技术的发展,LLM 已经超越了基础聊天机器人的范畴,被广泛应用于复杂的智能体系统中。这些智能体通过交替进行长推理和外部工具调用(如编译器、检索器)来解决现实世界问题,通常作为无需实时人工干预的多步骤工作流自主运行。然而,现有的推理系统在处理大量并发智能体请求时,吞吐量会显著下降,如图 1a 所示。同时,在强化学习(RL)中,rollout 占据了总时间的 70 % 70\% 70%以上。
研究问题
当前智能体推理系统存在三个主要缺陷:
- KV Cache 颠簸:现有系统在工具执行期间过早驱逐 KV Cache,缺乏对未来工作流中重用的预见,导致工具完成后需要重新运行 prefill 来恢复整个交互历史,将智能体工作流的平均端到端延迟增加高达 7.14 7.14 7.14倍。
- 跨节点内存不平衡:在多节点推理设置中,现有引擎将同一智能体工作流的所有请求固定到同一节点以最大化 KV Cache 命中率。但随着智能体工作流中上下文长度快速且不可预测地扩展,一些节点达到容量而其他节点利用率不足。
- 工具生命周期感知缺失:现有系统无法决定何时释放和准备工具执行所需的资源和环境,导致未使用的沙箱和 API 服务器继续占用关键磁盘空间和网络端口,造成累积资源耗尽和系统故障。
主要贡献
ThunderAgent 的核心贡献按重要性降序排列如下:
- 程序抽象:将智能体工作流抽象为智能体程序,作为统一的一级调度单元,持续跨越多个模型调用和工具执行,向运行时暴露语义状态。
- 程序感知调度器:基于程序抽象,将智能体推理调度建模为约束优化问题,通过状态感知暂停和动态迁移机制最小化重新计算和缓存开销,最大化 prefilling 和 decoding 吞吐量。
- 程序感知工具资源管理:通过跟踪执行依赖关系,将 I/O 密集的环境初始化与 LLM 推理重叠,并实现生命周期感知的垃圾回收器,防止累积资源泄漏。
方法论精要
程序抽象设计
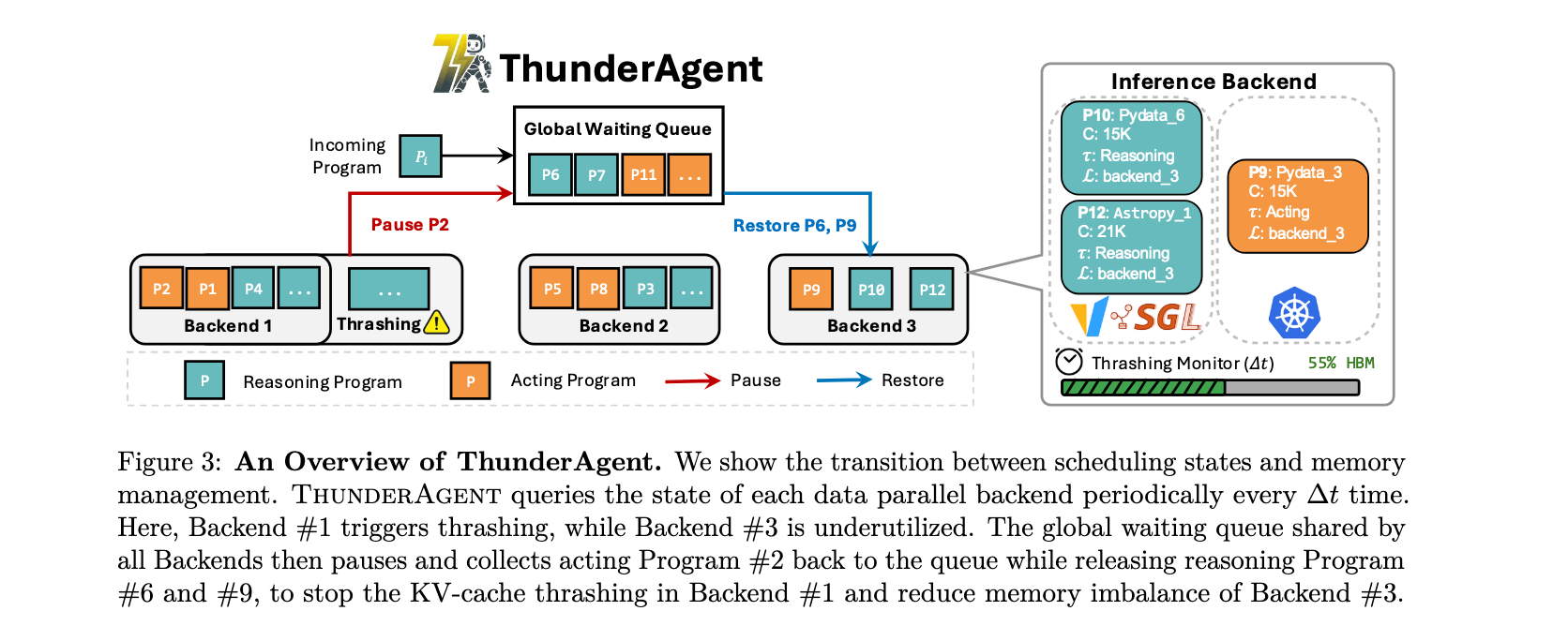
ThunderAgent 首先提出了智能体程序(Agentic Program)作为基础抽象,它封装了智能体工作流的逻辑执行流程和系统级依赖。形式上,一个智能体程序 P 定义为元组:
P = ⟨ I D , c , T , L , τ , s ⟩ P = \langle ID, c, T, L, \tau, s \rangle P=⟨ID,c,T,L,τ,s⟩
其中,ID 表示唯一的全局标识符;c 表示上下文中的 token 数量,对应活动执行期间的 KV Cache 内存占用;T 跟踪程序使用的工具环境集合,以便在不再需要时进行垃圾回收;L、τ 和 s 分别表示节点放置、执行阶段和调度状态,便于程序级 KV Cache 颠簸减少和跨节点迁移。这个抽象使得调度与执行后端(如 vLLM/SGLang)解耦,实现了新工作流的无缝集成。

成本模型框架
在多轮智能体推理中,只有用于活动 prefilling 和 decoding 的资源对系统的有效吞吐量有贡献,而重新计算、已用容量和空闲缓存构成了资源浪费。ThunderAgent 采用空间-时间积(STP)作为主要指标,定义为内存占用在处理时间上的积分。智能体推理的总成本包含五个不同的组件:decoding、prefilling、recomputation、unused capacity 和 idle caching。在这个分解中,Cost_decode 和 Cost_prefill 表示对推理吞吐量有贡献的有效工作。其余项是浪费的系统开销:Cost_recompute 源自 KV Cache 颠簸;Cost_unused 反映了数据并行(DP)推理后端副本之间的内存不平衡;Cost_caching 在外部工具执行期间持有内存时累积。
程序感知调度策略
基于上述成本模型,调度策略的优化目标是最小化非生产性开销组件,从而最大化吞吐量。
程序感知等待队列
为了解决 KV Cache 颠簸问题,ThunderAgent 引入了程序感知等待队列。系统利用此队列调度程序执行,根据它们的 token 长度 c 和执行阶段 τ 来决定应该在 GPU 中执行哪个程序以及应该交换出哪个程序。调度器行为通过两个基本操作形式化:Restore 将程序接纳到活动执行中,给程序分配一个有可用容量的后端;Pause 从活动执行中移除程序,解除程序与后端的绑定,释放其 KV Cache 以进行抢占。
周期性颠簸检测
程序抽象提供了活动程序的 KV Cache 大小,这在请求级系统中是不可用的。ThunderAgent 定义 DP 后端 L 的颠簸条件为程序内存需求超过总容量的状态:
C total < ∑ p ∈ L c p C_{\text{total}} < \sum_{p \in L} c_p Ctotal<∑p∈Lcp
与仅在到达时检查是否接纳工作流的基础调度器不同,ThunderAgent 实现了定期监视器,以固定间隔 Δt 评估内存使用情况,允许主动检测和减轻由上下文增长引起的内存压力。当 KV Cache 颠簸迫在眉睫时,ThunderAgent 调用 Pause 操作来暂停活动程序并释放内存,直到总内存使用低于限制。相反,当后端有可用空间时,ThunderAgent 通过 Restore 从等待队列恢复暂停的程序。
时间衰减机制
为了平衡缓存成本和重新计算成本,ThunderAgent 在颠簸检查中融入了时间衰减机制,逐渐降低活动程序 token 的有效权重:
C total < ∑ p ∈ L , τ = R c p + ∑ q ∈ L , τ = A c q × f ( t q ) C_{\text{total}} < \sum_{p \in L, \tau = R} c_p + \sum_{q \in L, \tau = A} c_q \times f(t_q) Ctotal<∑p∈L,τ=Rcp+∑q∈L,τ=Acq×f(tq)
其中 t_q 是程序 q 在当前步骤的工具执行时间,f(t) 是设计用于平衡 Cost_caching 和 Cost_recompute 的时间衰减函数。通过动态降低长期空闲活动程序的有效内存优先级,f(t) 鼓励调度器驱逐保持空闲的缓存。
最短优先驱逐策略
当需要释放内存时,ThunderAgent 采用最短优先驱逐策略。引理 4.1 指出,给定具有上下文长度 c i c_i ci的程序 P i P_i Pi,重新填充其 KV Cache 产生的重新计算成本与 c i c_i ci成二次方比例。基于此引理,当需要释放内存容量 ΔC 时,调度器旨在选择程序子集 S 进行驱逐,在满足约束的同时最小化总重新计算成本。该优化问题的目标通过选择较小的 c i c_i ci来严格最小化。
全局程序感知等待队列
为了解决跨节点内存不平衡问题,ThunderAgent 将所有后端副本的等待队列统一为一个全局程序感知等待队列。这种设计的动机是 Cost_unused 仅在暂停的程序留在等待队列中而某些副本有空闲内存时才会产生。恢复策略与负载平衡而非严格的 KV 感知路由保持一致,允许将暂停的程序分派给任何有可用内存容量的副本。结果,全局队列限制了未使用成本,使得对于每个节点在 Δ t \Delta t Δt期间都有 C unused < c min ⋅ Δ t C_{\text{unused}} \lt c_{\text{min}} \cdot \Delta t Cunused<cmin⋅Δt。
工具资源管理策略
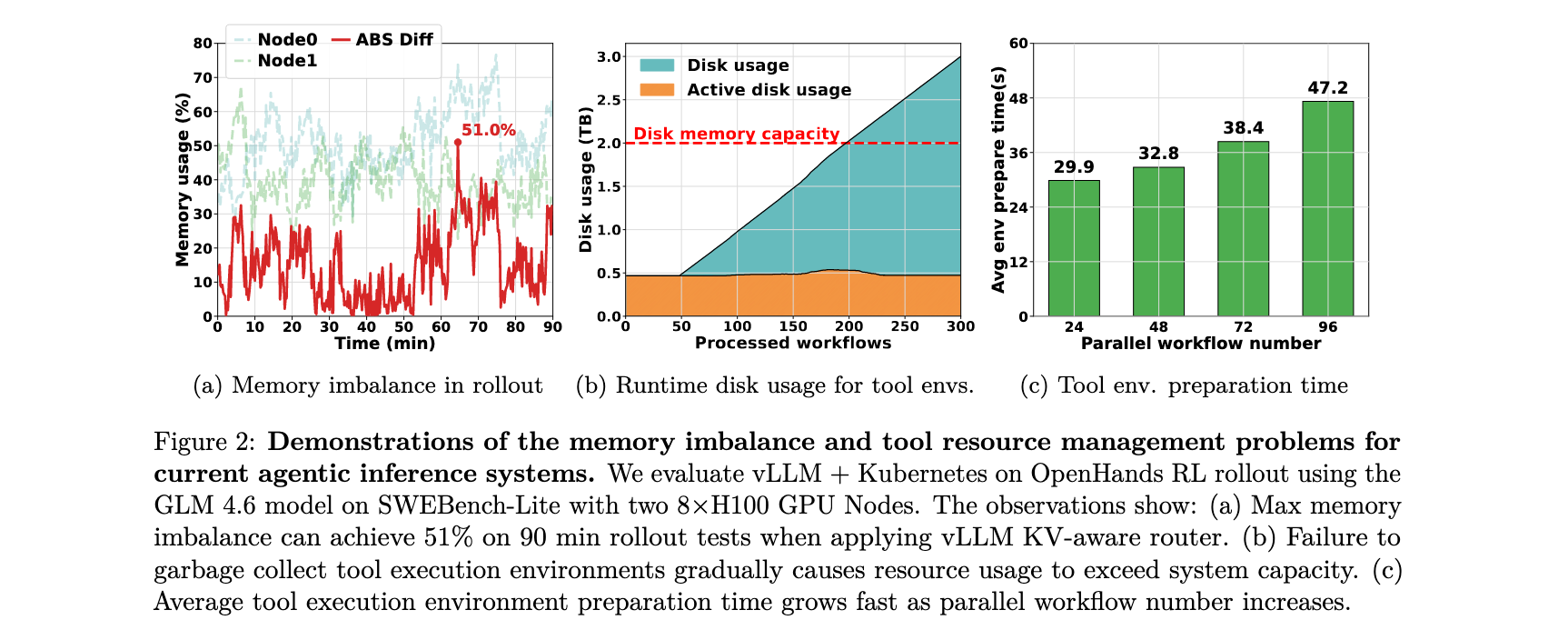
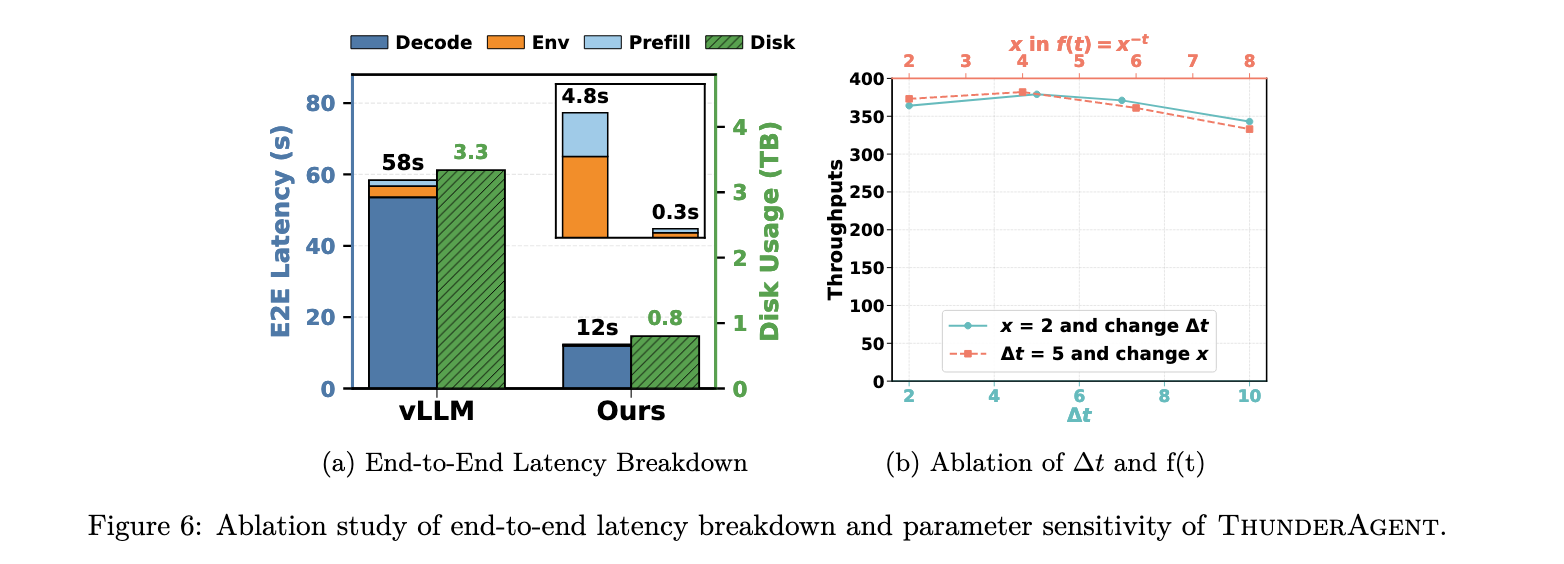
ThunderAgent 通过两个关键策略缓解资源泄漏和环境设置开销。基于钩子的垃圾回收实现了生命周期钩子,严格耦合工具资源的持久性与智能体程序的调度状态 s。当程序终止时,收集器触发立即的拆除序列,系统地回收沙箱、网络套接字和计算槽。图 2b 中的活动磁盘使用情况展示了资源管理策略有效地防止了过量资源的积累,随着时间的推移保持近乎恒定的磁盘内存消耗。异步环境准备监控全局等待队列,当高优先级程序接近恢复阈值时,系统在分配 GPU 内存之前异步恢复其执行环境。这种技术有效地隐藏了初始化开销,显著减少了工具调用繁重工作流(如编码代理和科学代理)的端到端延迟,如图 2c 所示。
实验洞察
ThunderAgent 在多样化的智能体工作流上进行了全面评估,包括编码、路由和科学研究代理,以及在从 RTX5090 \text{RTX5090} RTX5090到 H100 集群的多硬件配置上的 RL rollout。
实验设置
评估涵盖编码代理服务(SWEBench-Lite 数据集上的 OpenHands 和 mini-SWEAgent)、其他代理服务(HLE 上的 ToolOrchestra,ScienceAgentBench 上的 OpenHands)以及 RL rollout(两个 8 × H100 8 \times \text{H100} 8×H100节点)。模型采用 GLM-4.6( 355 B 355\text{B} 355B)和 Qwen-3( 235 B 235\text{B} 235B),使用 OpenHands 和 mini-SWEAgent 框架,在 8 × H100 8 \times \text{H100} 8×H100节点上以张量并行( TP8 \text{TP8} TP8)量化为 FP8。
服务评估结果
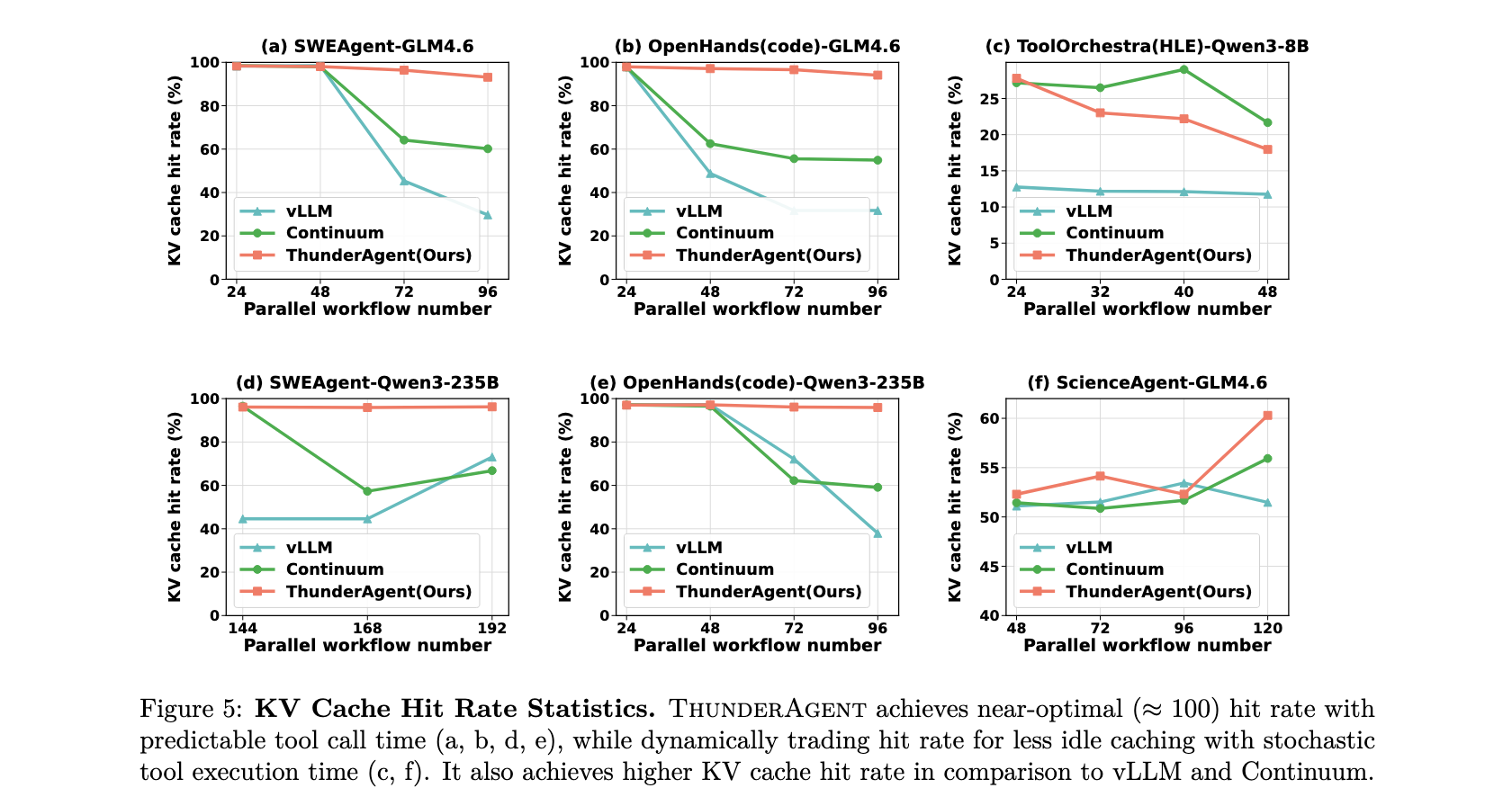
图 4 展示了 ThunderAgent 在高并发水平(如 96 96 96个并行程序)下表现出卓越的吞吐量,在多样化基础模型和数据集上实现了比 vLLM 高 1.48 − 3.58 1.48-3.58 1.48−3.58倍、比 Continuum 高 1.17 − 3.31 1.17-3.31 1.17−3.31倍的加速。这种收益来自程序感知调度器,它维持了近乎最优的 KV Cache 命中率(对于 Mini-SWE-Bench 和 OpenHands 约为 100 % 100\% 100%,见图 5a、b、d、e)并实现了环境的异步准备。相比之下,Continuum 在高并发下遭受性能下降。如图 5 所示,其 KV Cache 命中率从 > 90 % \gt 90\% >90%显著下降到约 60 % 60\% 60%。
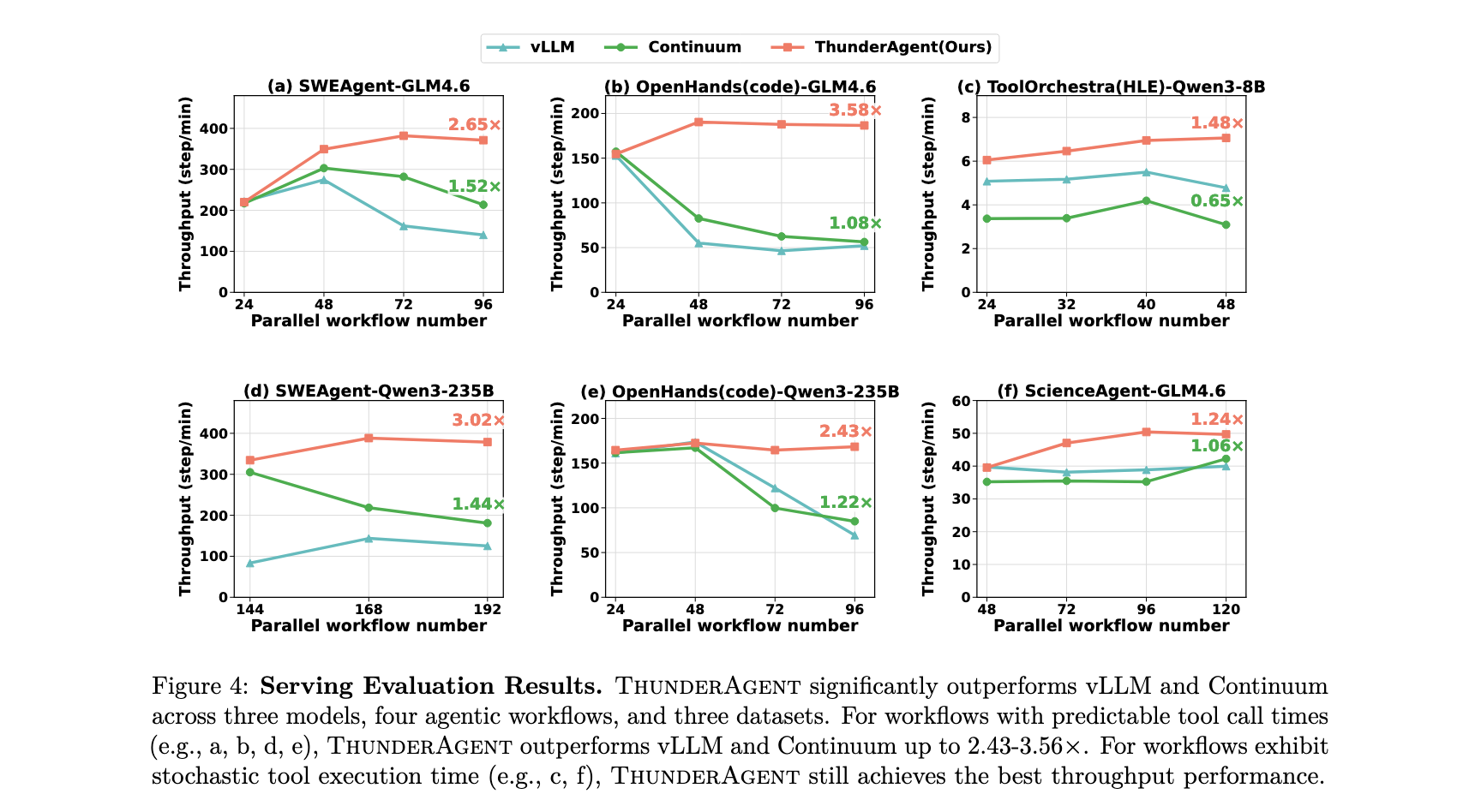
ThunderAgent 在并行工作流数量扩展超过 GPU 内存限制时仍保持最大可实现吞吐量。如图 4 所示,ThunderAgent 确保吞吐量随着并行工作流数量保持稳定,而基线系统一旦工作负载超过内存限制就会遭受严重的吞吐量崩溃。ThunderAgent 不仅在具有确定性工具模式的工作流(图 4a、b、d、e)中优于基线,而且在高度随机条件下(图 4c、f)也是如此。这来自动态程序感知等待队列策略。
Rollout 评估结果
表 2 显示,ThunderAgent 在双节点 H100 集群上( 3 3 3小时持续时间)可以保持有效的可扩展性,比 vLLM + Gateway 基线实现 1.79 − 3.92 1.79-3.92 1.79−3.92倍的吞吐量增加,使其对于内存密集型分布式 RL 工作流非常高效。

消融研究
图 6a 分解了 OpenHands rollouts 的平均端到端延迟。吞吐量收益主要来自 prefill 和 decode 延迟的减少。此外,工具资源管理策略(第 4.4 节)为延迟改进贡献了约 10 % 10\% 10%,同时提供了 4.2 4.2 4.2倍的磁盘内存节省。图 6b 研究了检测周期 Δ t \Delta t Δt和衰减函数 f ( t ) = x − t f(t) = x^{-t} f(t)=x−t的敏感性。ThunderAgent 在不同参数设置下保持高吞吐量,证明了方法的鲁棒性。
KV Cache 命中率分析
图 5 展示了 KV Cache 命中率统计。ThunderAgent 在具有可预测工具调用时间的工作流中实现了近乎最优( ≈ 100 % \approx 100\% ≈100%)的命中率,而在具有随机工具执行时间的工作流中动态权衡命中率以减少空闲缓存。它还实现了比 vLLM 和 Continuum 更高的 KV Cache 命中率。
工具执行时间变异性分析
附录 C 和图 9 表明,实际代理工具调用难以表征且通常不可预测。在代码中心设置中(如使用 SWE-agent 或 OpenHands 服务 SWE-Bench),代理主要调用本地轻量级工具,工具延迟相对稳定且方差较低。然而,在更广泛和现实的场景中(如使用 ToolOrchestra 服务 HLE),工作流更依赖远程服务工具,使工具执行时间变得波动且难以预测。
内存不平衡分析
图 2a 展示了当前智能体推理系统的内存不平衡问题。在 90 90 90分钟的智能体 RL rollout 快照中,两个 DP 节点之间的内存使用差异在超过 37 37 37分钟内超过 20 % 20\% 20%,达到峰值不平衡 51 % 51\% 51%。
磁盘使用分析
图 2b 展示了运行时工具环境的磁盘使用情况。未能垃圾收集工具执行环境逐渐导致资源使用超过系统容量。这是因为完成的工作流的未使用资源(如 Docker 镜像)在工作流完成时不会被回收。
环境准备时间分析
图 2c 展示了工具环境准备时间。平均工具执行环境准备时间随着并行工作流数量增加而快速增长。如果 LLM 推理引擎需要等待环境完全准备,这种开销将扩展推理系统的端到端延迟。



















 2238
2238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










