




阅读:
七、web自动化测试
GUI自动化测试学习内容:
- 了解自动化测试的相关概念
- 掌握Selenium Webdriver常用API
- 掌握自动化测试中的元素定位方法
- 掌握自动化测试中的元素操作
- 掌握自动化测试断言操作
- 掌握unittes框架的基本应用及自动化管理
一)自动化测试的相关概念
什么是自动化测试?
自动化测试就是把人对软件的测试行为转化由机器执行测试行为的一种实践。对于最常见的GUI自动化测试来讲,就是由自动化测试模拟之前那需要人工在软件界面上的各种操作,并且自动验证其结果是否符合预期结果。
自动化测试是否会把测试工程师淘汰?
从分析——计划——设计——实现——执行这个流程中,分析、计划、设计是需要人工进行的,实现、执行的过程中,也有自动化无法满足要求的情况。
什么样的项目适合自动化?
- 需求文档、不会频繁变更
- 研发和维护周期长,需要频繁执行回归测试
- 需要在多种平台上重复运行相同测试的场景
- 性能、兼容性通过手工测试无法实现,或者手工测试成本太高
- 被测软件的开发较为规范,能够保证系统的可测试性
- 测试人员具备一定的编程能力
1)自动化测试的类型分类
自动化测试有广义和狭义之分:
- 广义:借助工具进行软件测试都可以成为自动化测试
- 狭义:主要指基于UI层的自动化测试
测试划分:功能、性能、安全
测试阶段划分:基于代码的单元测试、集成阶段的接口测试、系统测试阶段的UI自动化
2)自动化测试用例设计原则
自动化测试用例设计原则:
- 自动化测试一般集中在需要重复测试的基本功能、基本业务流以及正向路径操作,不要将复杂的异常测试、复杂业务流程操作等加入到自动化测试用例中
- 自动化测试用例应尽量保持用例之间的独立性,最好不要形成依赖关系
- 自动化测试如果对数据进行了修改,在测试结束后应尽量保持还原,避免对其他用例执行产生影响
- 每个自动化测试用例只能验证一个功能点
二)webdriver
1)webdriver环境配置
什么是Selenium webdriver?
Se:硒
- 一种开源、免费的自动化测试工具,目前80%以上的公司都在使用它进行自动化测试
- 多浏览器支持:Firefox、Chrome、IE、Opera
- 多平台支持:Java、Python、Ruby、php、C#,JavaScript
- 简单(API简单),灵活(用开发语言驱动)
01环境配置
- 通过pip install selenium安装最新的selenium
- 下载对应的chromedriver或geckodriver,并将driver房到环境变量路径中
Chromedriver下载镜像:
geckodriver下载镜像(firefox):
http://npm.taobao.org/mirrors/geckodriver/
3.在pycharm中导入webdriver即可使用
from selenium import webdriver02 webdriver的工作原理

即编写脚本通过http请求发送relful请求,如:find_ element_ by_ class_ name ,脚本通过driver. exe驱动server 服务器,创建session, 绑定ip,向浏览器进行发送操作,并返回响应结果。
2 )自动化测试的基本操作
01自功化测试的基本操作示例
LOVE四步法:

eg

02 webriver常用API -浏览器操作
打开: driver. get(URL)
关闭:driver.quit()结束进程或driver.close()仅关闭当前窗口
设置窗口大小:driver.set_window_size(200, 500)
最大化窗口:driver.maxmize_window()
获取网页资源:driver.page_source
获取窗口名称:driver.name
刷新页面:driver.refresh()
获取页面标题:driver.title
获取当前页面的url地址:driver.curret_url
获取当前页面截图:driver.get_screenshot_as_file(path)03 web常用定位方式
webdriver常用API——常用的八种定位方式:
- id(不重复)
- name(有可能重复)
- class name(特指具有class属性的元素)
- tag name
- link text<a>
- partial link text<a>
- xpath(万能,可在chrome中用$x调试)
- css selector(万能,可以在chrome中用$$调试)
格式:
from selenium import webdriver
driver = webdriver.Chrome()
#id定位
name = driver.find_element('id', 'username')
name.send_keys('教育')
#name属性定位
driver.find_element('name', 'sex').click() # 选中性别中男这个选项 返回找到的第一个值
driver.find_elements('name', 'sex')[1].click() # find_elements将以列表形式返回多个符合条件的元素,返回列表的第二个,列表从0下标开始
#class name属性定位
driver.find_element('class name', 'dotborder').send_keys('凡云教育')
#对于复合样式的元素,不能直接使用class name方法来进行定位,以下语句报错
driver.find_element('class name', 'dotborder border').send_keys('aaaaa')
#tag name定位:一般用于寻找同类元素,返回列表
elements = driver.find_elements('tag name', 'input')
print(len(elements))
#link text和partial link text专门用于定位超链接a标签。
driver.find_element('link text', '打开百度').click() #全匹配
driver.find_element('partial link text', '百度').click()#部分匹配
#xpath定位
#绝对路径定位法
print(driver.find_element('xpath', '/html/body/form'))
#相对路径定位法
print(driver.find_element('xpath', '//tbody/tr[3]/td[2]/i').text)
print(driver.find_element('xpath', '//tbody/tr[3]//i').text)
#xpath属性定位
print(driver.find_element('xpath', "//input[@type='file']"))
driver.find_element('xpath', "//input[@type='text'][@mode='sub']").send_keys('18')
# xpath模糊定位
print(driver.find_element('xpath', "//*[contains(text(), '60岁')]").text)
driver.find_element('xpath', "//textarea[contains(@placeholder, 'yourself')]").send_keys('hello,教育')
find_element和find_elements
对于查找元素的方法,在webdriver中四种不同的写法,请注意区别:
- find_element('xx','selector')根据指定的方式定位元素,仅返回找到的第一个元素,如果美有元素符合则直接抛出异常
- find_elements('xx','selector')根据指定的方式定位元素,以列表形式返回找到的所有元素,如果没有元素符合则返回空列表
- find_element_by_xx('selector')根据指定的方式定位元素,仅返回找到的第一个元素,如果美有元素符合则直接抛出异常
- find_elements_by_xx('selector')根据指定的方式定位元素,以列表形式返回找到的所有元素,如果没有元素符合则返回空列表
三)Selenium+webdriver操作
1)Selenium元素查找
01、基本元素
- id:find_element('id','selector')
- name:find_element('name','selector')
- class name:find_elemnet('class name','selector')
- tag name:find_elementfind_elements('tag name','selector')
使用无痕窗口,因为没有任何cookie,代码打开的浏览器就是没有的,所以定位元素的时候,使用无痕窗口打开。
find_element和find_elements
对于查找元素的方法,在webdriver中四种不同的写法,请注意区别:
- find_element('xx','selector')根据指定的方式定位元素,仅返回找到的第一个元素,如果美有元素符合则直接抛出异常
- find_elements('xx','selector')根据指定的方式定位元素,以列表形式返回找到的所有元素,如果没有元素符合则返回空列表
- find_element_by_xx('selector')根据指定的方式定位元素,仅返回找到的第一个元素,如果美有元素符合则直接抛出异常
- find_elements_by_xx('selector')根据指定的方式定位元素,以列表形式返回找到的所有元素,如果没有元素符合则返回空列表
eg:
对于一段html
<input id="username_id" type="text" name="username" class="red">如下代码都可以获取到这个标签:
#id
driver.find_element_by_id("username_id")
#name
driver.find_elemenet_by_name("username")
#class_name
driver.find_element_by_class_name("red")
#tag
driver.find_element_by_tag_name("input")
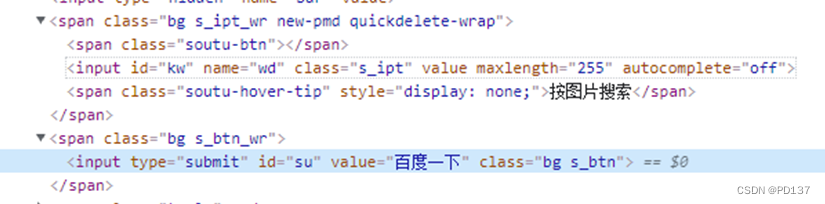
实例:
from selenium import webdriver
from time import sleep
driver=webdriver.Chrome()
url = 'https://www.baidu.com'
#使用浏览器打开指定页面
driver.get(url)
#id 查找元素(标签、标记、节点)
driver.find_element("id","kw").send_keys("肖战王一博")
driver.find_element("id","su").click()
#name
driver.find_element("name","wd").send_keys("肖战王一博")
driver.find_element("id","su").click()
#class_name
driver.find_element("class name","s_ipt").send_keys("肖战王一博")
driver.find_element("id","su").click()
sleep(3)
#关闭浏览器
driver.quit()复合样式不能用class去定位,直接报错,可以使用css selector进行定位

02、超链接(a标签)
- link text
- partial link text
- 超链接的例子
对于一段html
<a herf="http://www.baidu.com" id = "fwA" target="_blank">访问 百度 网站</a>如下代码都可以获取到这个标签
#link_text
driver.find_element("link text","访问 百度 网站")
#partial_link_text
driver.find_element("partial link text","访问")注意:
如果相同的规则回队应多个标签,那么这些方法会返回第一个
实际例子:
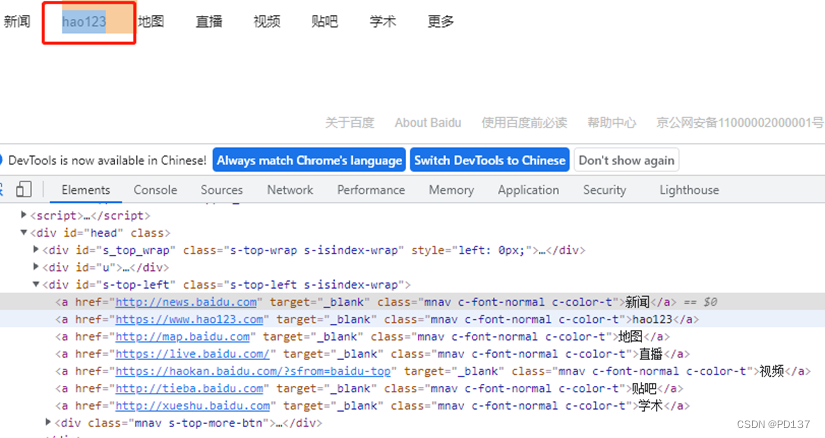
#定位a标签
#link_text
driver.find_element("link text","hao123").click()
#partial_link_text 如果文本比较长 ,定位部分可以使用这个,能够完整尽量完整
driver.find_element("partial link text","hao12").click()03、css选择器
web页面元素:
1、HTML页面基本结构
<html>
<head></head> html文档头部区域,页面不可见
<body></body> html文档内容区域,页面可见
</html>2、常见的页面元素:
- 容器型元素:div、form、table
- 页面元素:link、img、input(button、text、file)、select、checkbox、radio、textarea、submit
css选择器语法:




















 2582
2582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










