





人脸多任务IQA Benchmark:F-Bench(2025 ICCV)
该论文提出了首个大规模 AI 生成、定制及修复人脸质量评估数据库FaceQ,包含 12,255 张图像和 491,130 条多维度人工评分,基于该数据库构建了人脸生成、定制、修复模型的人类偏好基准F-Bench,同时设计了基于大型多模态模型(LMM)的一站式质量评估模型F-Eval。F-Bench 评估了 29 个主流模型的性能,揭示了各模型在质量、真实性、身份保真度和文本图像一致性等维度的优劣;F-Eval 通过双视觉编码器和多专家 LoRA 调优,在所有任务和维度上均实现了超越现有方法的性能,为 AIGC 人脸相关任务的质量评估提供了全面解决方案。参考资料如下:
[1]. 代码地址
[2]. 论文地址
论文整体结构思维导图如下:

专题介绍
图像质量评价(Image Quality Assessment, IQA)是图像处理、计算机视觉和多媒体通信等领域的关键技术之一。IQA不仅被用于学术研究,更在影像相关行业内实现了完整的商业化应用,涉及影视、智能手机、专业相机、安防监控、工业质检、医疗影像等。IQA与图像如影随形,其重要程度可见一斑。
但随着算法侧的能力不断突破,AIGC技术发展火热,早期的IQA或已无法准确评估新技术的能力。另一方面,千行百业中各类应用对图像质量的需求也存在差异和变化,旧标准也面临着适应性不足的挑战。
本专题旨在梳理和跟进IQA技术发展内容和趋势,为读者分享有价值、有意思的IQA。希望能够为底层视觉领域内的研究者和从业者提供一些参考和思路。
系列文章如下:
【1】🔥IQA综述
【2】PSNR&SSIM
【3】Q-Insight
【4】VSI
【5】LPIPS
【6】DISTS
【7】Q-align
【8】GMSD
【9】NIQE
【10】MUSIQ
【11】CDI
【12】Q-BENCH
【13】Q-Instruct
【14】A-Fine
【15】MANIQA
【16】CLIPIQA
一、研究背景
论文作者抓住了现有人脸任务的痛点:AI 生成、定制、修复人脸常出现结构失真、身份偏移、文本图像不一致等问题,现有评估方法(通用 IQA、自然人脸 FQA)缺乏针对性,无法精准匹配人类偏好。下图总结了本文作者的贡献所在:

可以分为3点:
- 构建首个专属数据库FaceQ,覆盖多任务、多维度人工标注。从图中可以看到任务包含人脸生成、定制、复原任务;标注包含了多个维度,有质量、真实性、对应性等。
- 建立基准F-Bench,系统评估主流模型性能并揭示优劣。多个主流模型,都是熟悉的方法;
- 设计一站式评估模型F-Eval,实现多维度质量精准预测。此为作者设计的一个IQA模型,用LMM模型微调得来的。
二、FaceQ 数据库构建
FaceQ的数据提示词来自 MS-COCO 与 GPT-4o;参考图含自采与公开数据;低质图像含合成(模糊 / 噪声等)与真实(公开数据集)两类。
数据集的统计如下表:

可以看到FaceQ包含12,255 张图像,生成子集(4,032 张)、定制子集(4,200 张)、修复子集(4,023 张),491,130 条人工评分,最终生成 32,000+ MOS 值,评估维度包含以下4项:
- 质量:色彩、清晰度等整体感知;
- 真实性:接近真实照片的程度;
- 身份保真度:定制 / 修复任务中身份保留程度;
- 文本图像一致性:生成 / 定制任务与提示词的匹配度。
人工打分是由180 名正常视力参与者,经培训后评分;采用 0-5 分滑动条,按 ITU-R BT.50014 标准执行;3% 异常值剔除,Z-score 标准化至 0-100 分。得分公式如下所示:
MOS
norm
(
i
)
=
MOS
(
i
)
−
μ
σ
×
10
+
50
\text{MOS}_{\text{norm}}(i) = \frac{\text{MOS}(i) - \mu}{\sigma} \times 10 + 50
MOSnorm(i)=σMOS(i)−μ×10+50其中
MOS
(
i
)
\text{MOS}(i)
MOS(i) 代表第
i
i
i 个样本的原始人工评分均值;
μ
\mu
μ 代表所有原始MOS值的全局均值;
σ
\sigma
σ 代表所有原始MOS值的全局标准差;
MOS
norm
(
i
)
\text{MOS}_{\text{norm}}(i)
MOSnorm(i) 代表标准化后的MOS值(映射至0-100分区间)。
异常值剔除方法如下所示:
Z
(
i
)
=
x
(
i
)
−
x
ˉ
std
(
x
)
Z(i) = \frac{x(i) - \bar{x}}{\text{std}(x)}
Z(i)=std(x)x(i)−xˉ其中
x
(
i
)
x(i)
x(i) 代表第
i
i
i 个标注者对某样本的评分;
x
ˉ
\bar{x}
xˉ 代表该样本所有标注者评分的均值;
std
(
x
)
\text{std}(x)
std(x) 代表该样本所有标注者评分的标准差;
Z
(
i
)
Z(i)
Z(i) 为Z-score值,本文剔除
∣
Z
(
i
)
∣
>
3
|Z(i)| > 3
∣Z(i)∣>3 的异常评分。
以下是FaceQ的一些数据集示意:

左中右分别是人脸生成、定制以及复原任务的评估,每个任务会采取不同的维度,不会将4个维度全部评估,只会关注跟本任务相关的维度。
由于是benchmark,因此会评估比较多的方法,作者选了29 个主流模型(14 生成 + 6 定制 + 9 修复),含 Stable Diffusion 系列、Flux-dev、PhotoMaker 等。
三、F-Bench 基准分析
评估范围包含29 个人脸模型 + 26 种现有质量评估方法。
首先是各类任务的MOS评分分布结果如下图所示:

作者有以下几个发现:
- 生成任务:文本图像一致性得分最高(模型提示词理解能力强),真实性得分最低( photorealism 不足)。
- 定制任务:质量维度整体最差(注入身份易牺牲画质),身份保真度呈双峰分布(人类判断非此即彼)。
- 修复任务:质量得分优于身份保真度,真实低质图像修复难度高于合成图像。
然后是不同模型的MOS结果表现:

有以下结论:
- 人脸生成:Flux-dev、SD3、Realistic Vision为领先模型,优势体现在真实性与质量平衡,提示词匹配精准。
- 人脸定制:IP-Adapter-FaceID-Plus、PhotoMaker、InstantID为领先模型,优势体现在身份保真度高,兼顾画质与文本一致性。
- 人脸复原:StableSR、CodeFormer、DiffBIR为领先模型 ,优势体现在细节保留好,身份还原准,鲁棒性强。
对生成类任务的提示词做了实验:

生成任务中,动作、表情、面部属性类提示词评分最低(复杂属性难精准生成),通用、背景类提示词评分最高。年龄维度:定制 / 修复任务中老年人图像质量波动大;性别维度:修复任务中男性图像表现略优。
四、F-eval模型设计与性能
F-eval是作者设计的一个IQA网络,如下图所示。

模型架构设计,输入是图像(单张 / 成对)、提示词、可选参考图;编码器选择Qwen-VL-2.5-ViT(视觉特征)+ ArcFace(人脸身份特征),均经微调;特征融合选择双投影器将视觉 / 人脸特征映射至语言空间,与文本特征拼接后输入 Qwen-VL2.5-7B;调优策略选择指令调优(适配多维度评估)+ 多专家 LoRA(4 个专家对应 4 个维度,路由器动态激活)。
五、实验
定量实验如下:

FaceQ-Gen 与 FaceQ-Cus 子集现有 QA 模型性能对比,结论如下:
- 传统 IQA 模型(如 NIQE、ILNIQE)在所有维度上表现最差,因这类模型针对自然图像退化设计,无法适配 AIGC 人脸的专属失真(如身份偏移、结构异常)。
- 深度学习 - based IQA 模型(如 MANIQA、PromptIQA)经 FaceQ 微调后性能显著提升,但在文本图像一致性维度仍有短板。
- AIGC IQA 模型中,MINTIQA 微调后表现最优,但仍不及 F-Eval;CLIPScore、BLIPScore 因侧重高层语义,与人类偏好相关性低。
- 人脸 IQA 模型(如 DSL-FIQA)在质量维度有一定适配性,但身份保真度、文本图像一致性维度表现不足。
- F-Eval 在所有任务和维度上的 SRCC、KRCC、PLCC 指标均最优,尤其是在身份保真度和文本图像一致性维度,优势显著。
FaceQ-Res 合成子集 QA 模型性能对比,结论如下:

- 传统 NR-IQA、FR-IQA 模型在合成修复数据上的相关性指标普遍较低,无法有效评估修复图像的质量和身份保真度。
- 深度学习 - based IQA 模型(如 TReS、PromptIQA)微调后性能提升明显,在质量维度表现接近 F-Eval,但身份保真度维度仍有差距。
- 人脸 IQA 模型中,ArcFace 在身份保真度维度表现突出,但质量评估能力弱;DSL-FIQA 在质量维度有一定优势,但综合性能不及 F-Eval。
- F-Eval 在合成修复数据的质量和身份保真度维度均保持最优,验证了其在合成退化场景下的评估能力。
FaceQ-Res 真实世界子集 QA 模型性能对比,结论如下:

- 所有现有 QA 模型在真实世界修复数据上的性能均低于合成数据,说明真实场景的复杂退化对评估模型挑战更大。
- 深度学习 - based IQA 模型中,MANIQA、HyperIQA 微调后在质量维度表现较好,但身份保真度维度仍依赖人脸专属特征提取。
- F-Eval 在真实世界修复数据的质量和身份保真度维度仍保持领先,且与现有模型的性能差距较合成数据更大,体现其对复杂真实场景的强适配性。
接下来是消融实验:

结论如下:
- 人脸编码器的加入能显著提升模型性能,尤其是身份保真度维度,证明人脸专属特征提取对评估准确性的重要性。
- 投影器是跨模态特征融合的关键,移除投影器会导致特征空间不统一,性能大幅下降。
- 多专家 LoRA(MoLE)设计优于单 LoRA 和任务级 LoRA,能有效避免不同评估维度间的特征干扰,提升多维度评估的精准度。
F-Eval 完整消融实验结果:
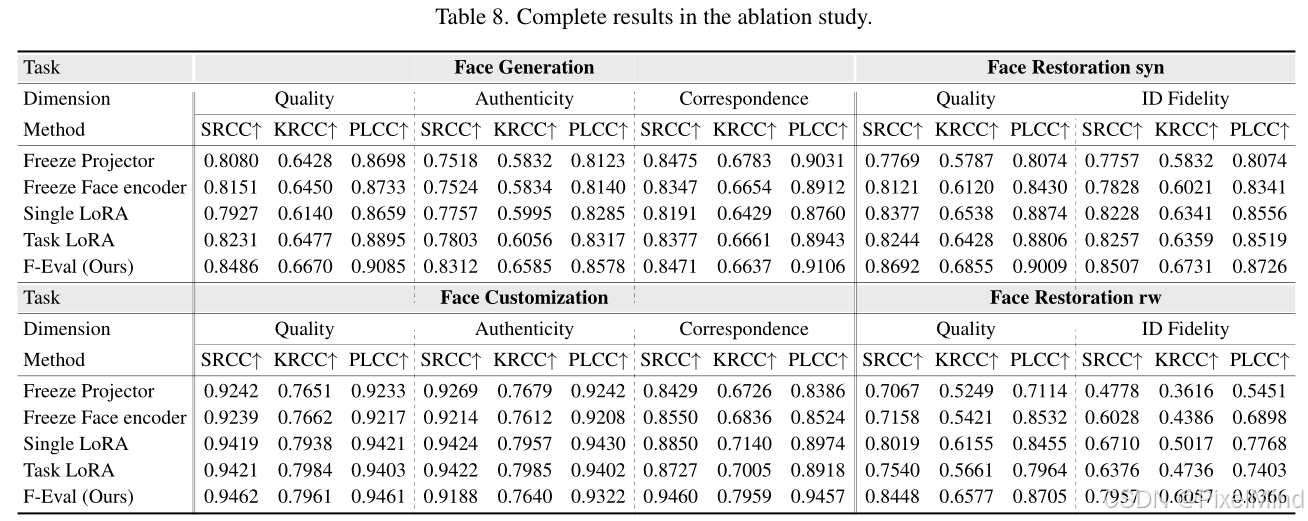
进一步验证了核心组件(人脸编码器、投影器、多专家 LoRA)在所有任务和维度上的有效性,各组件的缺失均会导致不同程度的性能退化。F-Eval 的全组件架构能最大化融合视觉、人脸、文本跨模态特征,实现对三大任务、四大维度的一站式精准评估。
六、总结
FaceQ数据集填补了人脸 AIGC 质量评估数据库的空白,F-Bench 为模型优化提供了明确方向。设计的F-Eval IQA方法实现了多任务多维度的精准评估,为 AIGC 人脸相关应用提供了可靠的质量衡量工具。
感谢阅读,欢迎留言或私信,一起探讨和交流,如果对你有帮助的话,也希望可以给博主点一个关注,谢谢。


















 2674
2674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










