







四、Transformer之多头注意力机制的深度源码剖析
---
从公式到工程:Transformer 多头注意力机制的深度源码剖析
摘要:多头注意力(Multi-Head Attention)是 Transformer 架构取得成功的基石。本文将以一段经典的 PyTorch 实现为核心,逐层拆解其背后的数学公式、张量变换细节与并行化设计思想。我们将看到,如何通过巧妙的线性投影合并与维度重塑,将原本需要对多个独立子空间循环的操作,转化为一次高效的大矩阵乘法,从而在保持数学等价性的同时,最大化 GPU 的并行算力。
1. 数学定义:多个子空间的“分而治之”
在进入代码之前,有必要精确回顾多头注意力的数学定义。设输入的查询、键、值矩阵分别为 Q , K , V ∈ R n × d model {Q, K, V \in \mathbb{R}^{n \times d_{\text{model}}}} Q,K,V∈Rn×dmodel,其中 n {n} n 为序列长度。给定头数 h {h} h,每个头的隐维度为 d k = d model / h {d_k = d_{\text{model}} / h} dk=dmodel/h。
对于第
i
{i}
i个头,我们引入四个可学习的投影矩阵:
W
i
Q
,
W
i
K
,
W
i
V
∈
R
d
model
×
d
k
,
W
O
∈
R
d
model
×
d
model
{W_i^Q, W_i^K, W_i^V \in \mathbb{R}^{d_{\text{model}} \times d_k}, \quad W^O \in \mathbb{R}^{d_{\text{model}} \times d_{\text{model}}}}
WiQ,WiK,WiV∈Rdmodel×dk,WO∈Rdmodel×dmodel
该头的输出为缩放点积注意力:
head
i
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
=
softmax
(
Q
W
i
Q
(
K
W
i
K
)
T
d
k
)
V
W
i
V
{ \text{head}_i = \text{Attention}(Q W_i^Q, K W_i^K, V W_i^V) = \text{softmax}\left(\frac{Q W_i^Q (K W_i^K)^T}{\sqrt{d_k}}\right) V W_i^V}
headi=Attention(QWiQ,KWiK,VWiV)=softmax(dkQWiQ(KWiK)T)VWiV
最终,所有头的结果沿最后一个维度拼接后,通过输出投影矩阵 (W^O) 混合:
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
head
1
,
…
,
head
h
)
W
O
{ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h) \, W^O }
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
这一公式构成了所有实现的起点。但在实际编码中,若直接创建 h {h} h 组独立的小矩阵,会导致大量的核函数启动和低效的显存操作。下文代码展示了一种等效的稠密实现——所有头的投影在一次线性变换中完成。
2. 类初始化:准备聚合投影矩阵
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
专家的解读:
- 整除断言:
assert d_model % h == 0是工程严谨性的体现。它强制d_model能够均匀分配给每个头,避免因无法整除导致的信息畸变。原论文中,典型配置为 d model = 512 , h = 8 {d_{\text{model}}=512, h=8} dmodel=512,h=8,恰好 (d_k=64)。 clones(nn.Linear(d_model, d_model), 4):这里一次性克隆了四个完全相同的线性层,分别扮演 W Q , W K , W V , W O {W^Q, W^K, W^V, W^O} WQ,WK,WV,WO的角色。关键在于,每个矩阵的维度都是 d model × d model {d_{\text{model}} \times d_{\text{model}}} dmodel×dmodel,而非 d model × d k {d_{\text{model}} \times d_k} dmodel×dk。这种设计是为实现“一次投影,然后切分”。从数学上看,大的 W Q ∈ R d model × d model {W^Q \in \mathbb{R}^{d_{\text{model}} \times d_{\text{model}}}} WQ∈Rdmodel×dmodel 可以看作所有头的 W i Q {W_i^Q} WiQ按列拼接的转置:
W Q = [ W 1 Q ∣ W 2 Q ∣ … ∣ W h Q ] ⋅ (某种重排) {W^Q = \left[ W_1^Q \;|\; W_2^Q \;|\; \dots \;|\; W_h^Q \right] \cdot \text{(某种重排)} } WQ=[W1Q∣W2Q∣…∣WhQ]⋅(某种重排)
通过后续的view操作,我们能无损地从大矩阵的结果中提取出每个头对应的那一部分,而不牺牲任何表达能力。self.attn = None:该实例变量不参与前向计算,仅作为缓存,用于事后分析注意力分布(例如可视化注意力权重)。这是研究者的友好设计。- Dropout 放置:这里的
dropout将在attention函数内部作用于注意力权重矩阵,是 Transformer 正则化的重要环节。
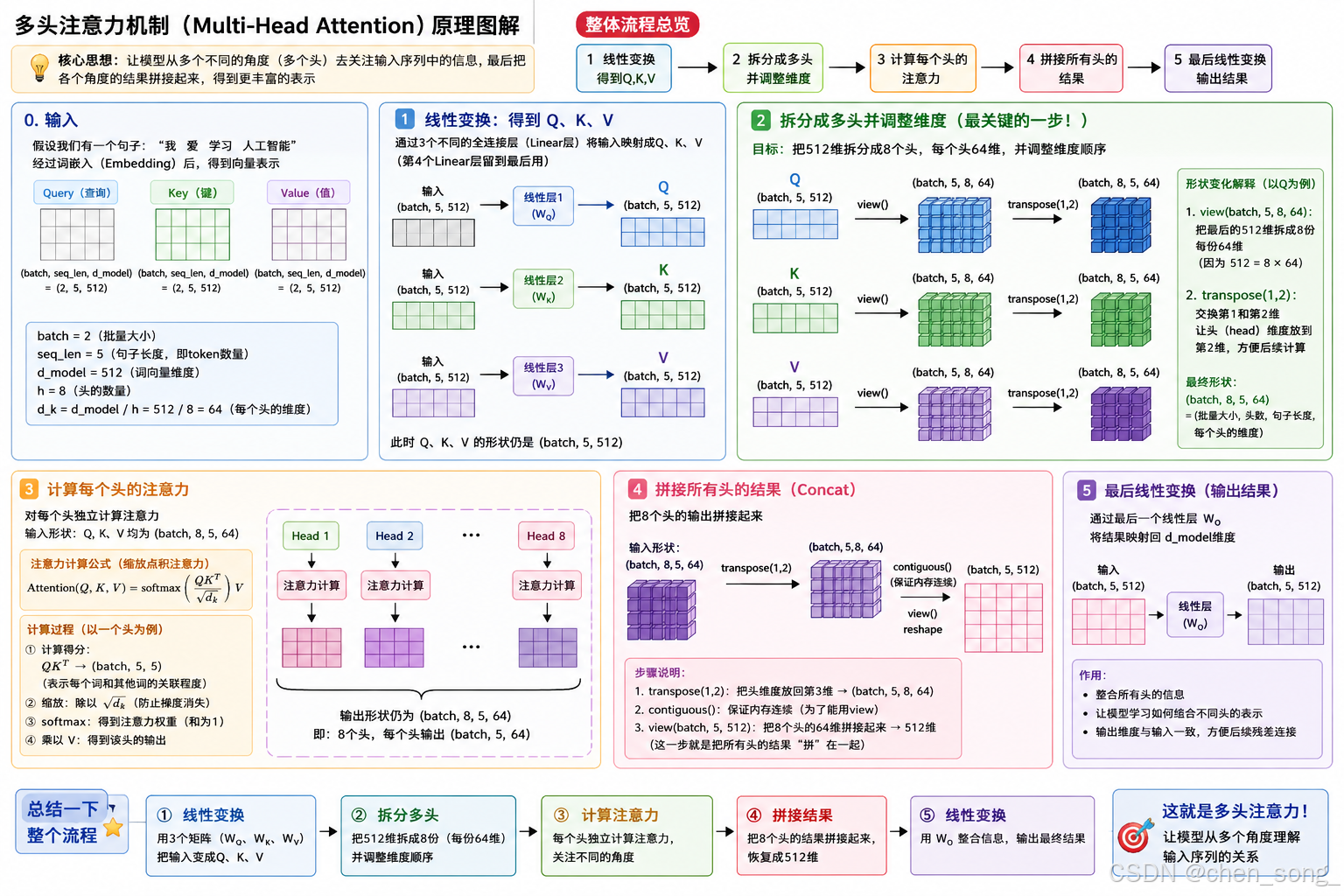
3. 前向传播:张量体操与并行注意力
3.1 掩码预处理
def forward(self, query, key, value, mask=None):
if mask is not None:
mask = mask.unsqueeze(1)
输入 mask 的形状通常为 (batch, seq_len) 或 (batch, 1, seq_len),用于屏蔽填充符或实现自回归解码。unsqueeze(1) 将其变为 (batch, 1, 1, seq_len) 或 (batch, 1, seq_len, seq_len)(取决于原始形状),以便与后续注意力分数张量 (batch, h, seq_len, seq_len) 进行广播。这种维度对齐利用了 PyTorch 的广播语义,使得同一个 mask 可以自动作用于所有头,无需手动复制。
3.2 联合投影与多头拆分:核心张量变换
这是整个实现中最高光的段落:
nbatches = query.size(0)
query, key, value = [
l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))
]
逐步拆解这个列表推导式:
-
l(x):对于查询query,通过self.linears[0](即 W Q {W^Q} WQ进行线性投影。输入x形状为(nbatches, seq_len, d_model),输出形状不变,仍为(nbatches, seq_len, d_model)。但此刻输出的每个d_model维向量,已经混合了所有头的投影信息。 -
.view(nbatches, -1, self.h, self.d_k):将最后一个维度d_model重塑为(h, d_k)。张量形状变为(nbatches, seq_len, h, d_k)。这一操作没有发生数据复制,仅仅是视图变化,它将原本连续排列的 512 个数值重新解释为 8 组、每组 64 个数值。 -
.transpose(1, 2):交换第 1 维(序列长度)和第 2 维(头数),得到最终形状(nbatches, h, seq_len, d_k)。这一步是逻辑上的分组完成:现在每个头 i 对应的查询张量独立地占据一个维度,即[:, i, :, :],形状为(nbatches, seq_len, d_k),便于在后续注意力计算中,通过一次批量矩阵乘法并行处理所有头。
数学等价性证明:为什么这种“大矩阵→切分”与“多个小矩阵独立投影”效果相同?假设 (X) 是一个行向量,我们希望得到
[
X
W
1
Q
,
X
W
2
Q
,
…
,
X
W
h
Q
]
{ [X W_1^Q, X W_2^Q, \dots, X W_h^Q] }
[XW1Q,XW2Q,…,XWhQ],将它们拼接成一个
h
d
k
{hd_k}
hdk 维的向量。若我们将所有小矩阵按列拼接成
W
big
=
[
W
1
Q
,
W
2
Q
,
…
,
W
h
Q
]
{W_{\text{big}} = [W_1^Q, W_2^Q, \dots, W_h^Q]}
Wbig=[W1Q,W2Q,…,WhQ],则显然
X
W
big
{X W_{\text{big}}}
XWbig 正好就是拼接后的结果。因此,一次大矩阵乘法再 view 完美等价于先拆分后多个小矩阵乘法的拼接。该设计将
h
{h}
h次独立的小矩阵乘法融合为一次大矩阵乘法,显著提升了计算密度和 GPU 利用率。
3.3 缩放点积注意力计算
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
此处的 attention 函数虽未给出,但其标准实现必然包含缩放点积的核心公式。为完整性,我们给出其典型逻辑:
def attention(query, key, value, mask=None, dropout=None):
d_k = query.size(-1)
# (batch, h, seq, d_k) @ (batch, h, d_k, seq) -> (batch, h, seq, seq)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9) # 被屏蔽位置赋予极小值
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
# (batch, h, seq, seq) @ (batch, h, seq, d_k) -> (batch, h, seq, d_k)
return torch.matmul(p_attn, value), p_attn
专家注记:
- 缩放因子 d k {\sqrt{d_k}} dk:当 d k {d_k} dk 较大时,点积的方差随之增长,将 softmax 推向梯度极小的饱和区。除以 d k {\sqrt{d_k}} dk使方差控制为 1,保持梯度稳定。
- Mask 填充值:使用
−
10
9
{-10^9}
−109 而非
float('-inf'),是一种数值安全的技巧,避免 softmax 出现 NaN。 - Dropout:直接作用在 softmax 后的注意力权重上,按概率随机丢弃某些连接,迫使模型不依赖单一强特征。
self.attn赋值:保存的是 softmax 后的概率矩阵p_attn,形状(batch, h, seq, seq),可用于后续解释性分析或制定更复杂的约束(如适配器)。
3.4 多头合并与最终投影
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
从注意力的输出 (nbatches, h, seq_len, d_k) 回到 (nbatches, seq_len, d_model) 的过程需要两步:
-
transpose(1, 2):将头维度和序列维度换回,得到(nbatches, seq_len, h, d_k)。此时,数据在内存中的排列不再是“按头连续”,而是“按序列位置,每个位置内各头相邻”。 -
.contiguous().view(nbatches, -1, self.h * self.d_k):- 由于
transpose之后张量的内存布局并非 C 语言风格连续(stride 发生变化),直接调用view会报错。因此必须调用.contiguous()强制复制并整理内存,使其变为连续布局。 - 随后的
.view将最后两个维度合并,自然地完成了所有头的拼接(Concat),恢复为d_model维。此处的拼接完全是零成本的维度解释变更。
- 由于
-
最终投影
self.linears[-1](x):即乘以 W O {W^O} WO。它是四个克隆线性层中的最后一个,对拼接后的多头信息进行线性混合。这一步允许不同头之间的信息交互,是整个多头机制的收束点。
4. 设计哲学与深层洞察
- 并行化万岁:通过“聚合投影 + view + transpose”的模式,代码将原本串行的“对每个头分别做注意力”转化为一次大规模并行计算。在现代 GPU 上,单次大矩阵乘法(GEMM)的执行效率远高于多次小矩阵乘法,这正是 Tensor Core 最擅长的场景。
- 内存连续性技巧:
transpose与view的组合使用是深度学习框架中修改张量形状的常见范式。程序员必须时刻关注内存布局,在必要处插入contiguous(),它虽然带来一次额外复制,但保证了view的合法性和后续计算的正确性。 - 模块化与可解释性:将
attention单独作为一个函数,使核心运算解耦;将投影矩阵集中在一个ModuleList里,使参数管理干净。同时,self.attn的设计体现了对模型可解释性的尊重——任何外部调用者都可以轻易获取到注意力权重,用于画图、分析或加入辅助损失。
5. 总结
本文深入剖析了一段不到 30 行的 PyTorch 多头注意力代码,揭示了其背后从数学到工程的精妙映射。我们见证了四个 nn.Linear 如何隐式地代表所有头的全部投影,view 和 transpose 如何在不增加计算量的前提下完成子空间拆分与拼接,以及 contiguous() 如何在灵活性中注入内存安全的保障。
真正理解这段代码,意味着你已掌握 Transformer 家族最核心的算子实现范式。无论是后续研究 BERT、GPT 或 ViT,你都会发现其注意力模块几乎都是此代码的同构变体。透彻理解它,就拿到了理解整个自注意力宇宙的钥匙。
Transformer原理分析:https://chensongpoixs.github.io/artificial_intelligence/Transfomer


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










