




ultralytics现有CBAM
代码
conv.py已存在官方实现的简版CBAM
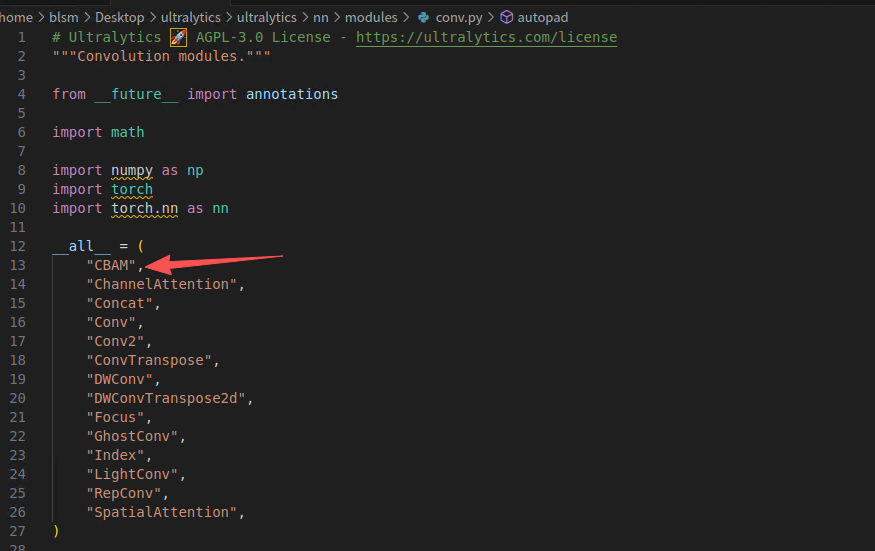
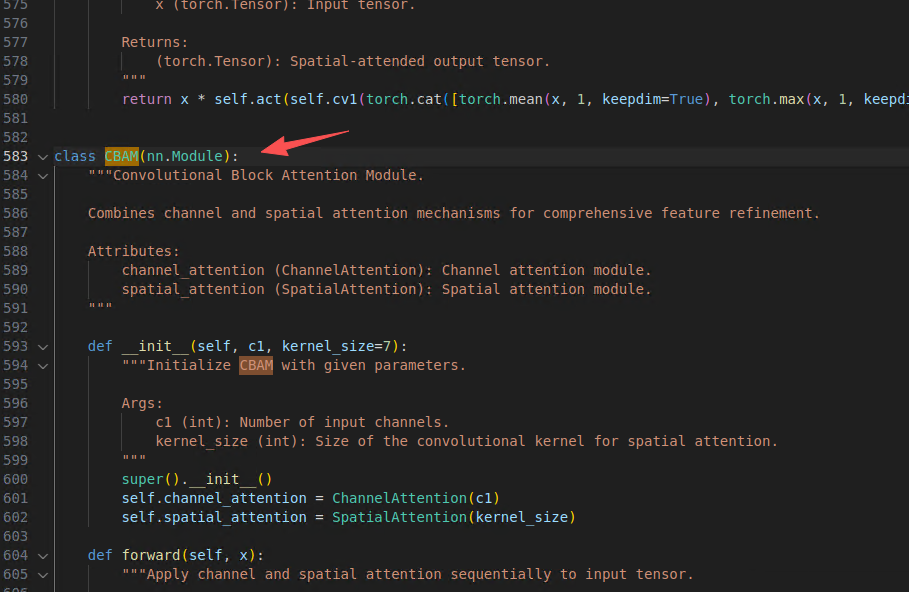
如何使用
打开tasks.py
引入模块加入 CBAM
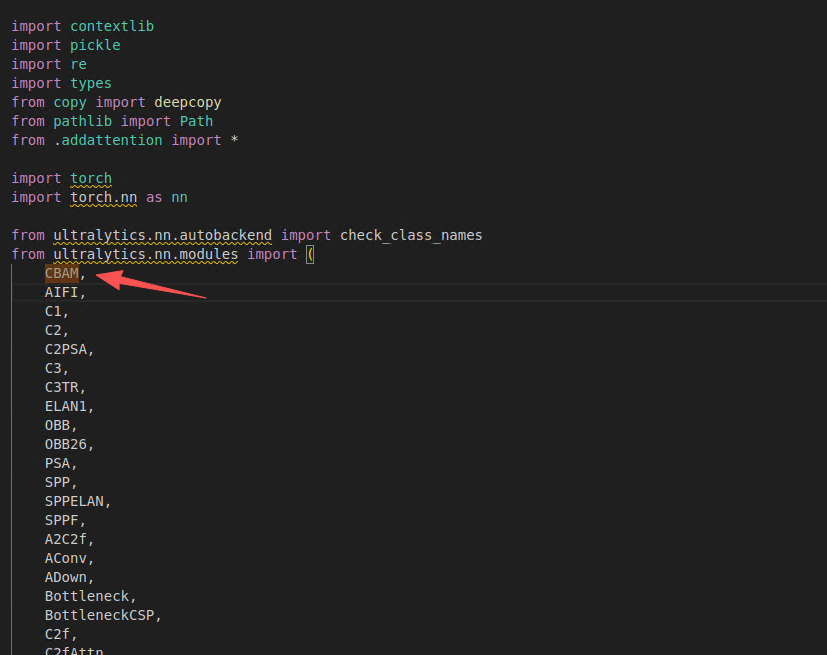
基础模块加入 CBAM
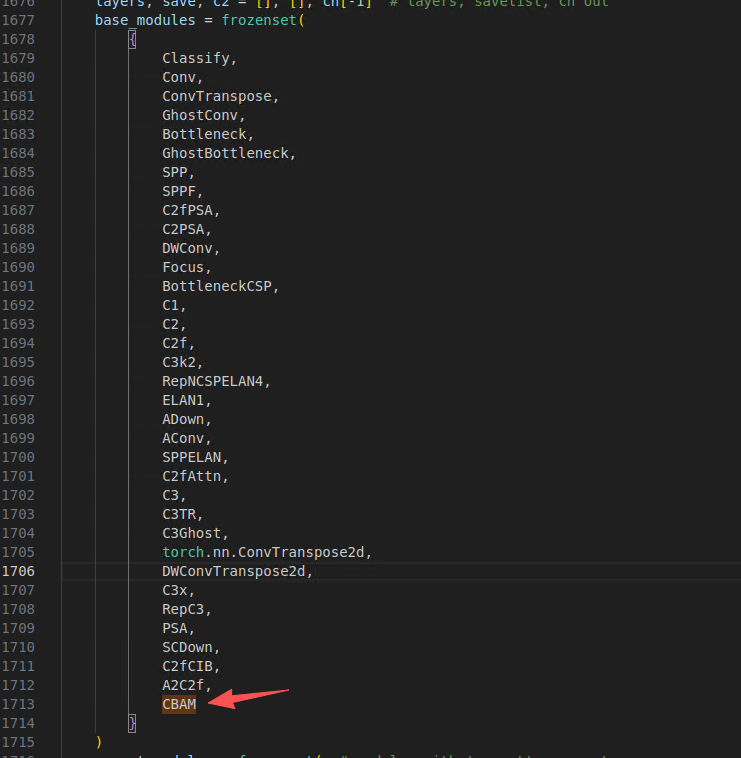
此时,如果你的yolo11n-p2-cbam.yaml中使用了 CBAM
并且你必须手动指定CBAM 参数 [c1, kernel_size],才能正常训练
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11-P2 纯原生内置 CBAM 纯 YAML 适配版(完全不改任何源码)
nc: 80
scales:
n: [0.50, 0.25, 1024] # 宽度缩放因子为 0.25
# YOLO11-P2 backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0 (实际通道: 16)
- [-1, 1, Conv, [128, 3, 2]] # 1 (实际通道: 32)
- [-1, 2, C3k2, [256, False, 0.25]] # 2 (实际通道: 64)
- [-1, 1, Conv, [256, 3, 2]] # 3 (实际通道: 64)
- [-1, 2, C3k2, [512, False, 0.25]] # 4 (实际通道: 128)
- [-1, 1, Conv, [512, 3, 2]] # 5 (实际通道: 128)
- [-1, 2, C3k2, [512, True]] # 6 (实际通道: 128)
- [-1, 1, Conv, [1024, 3, 2]] # 7 (实际通道: 256)
- [-1, 2, C3k2, [1024, True]] # 8 (实际通道: 256)
# 【CBAM 1】:上一层输出是 256,对应内置 CBAM 参数 [c1, kernel_size]
# 必须手工填入 256,并显式指定 kernel_size 为 7(或者 3)
- [-1, 1, CBAM, [256, 7]] # 9
- [-1, 1, SPPF, [1024, 5]] # 10
- [-1, 2, C2PSA, [1024]] # 11
# YOLO11-P2 head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 12
- [[-1, 6], 1, Concat, [1]] # 13
- [-1, 2, C3k2, [512, False]] # 14 (实际通道: 128)
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 15
- [[-1, 4], 1, Concat, [1]] # 16
- [-1, 2, C3k2, [256, False]] # 17 (实际通道: 64)
# 【CBAM 2】:上一层输出通道是 64,必须显式指定核大小
- [-1, 1, CBAM, [64, 7]] # 18
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 19
- [[-1, 2], 1, Concat, [1]] # 20
- [-1, 2, C3k2, [128, False]] # 21 (实际通道: 32)
# 【CBAM 3】:上一层输出通道是 32
- [-1, 1, CBAM, [32, 7]] # 22
- [-1, 1, Conv, [128, 3, 2]] # 23
- [[-1, 18], 1, Concat, [1]] # 24 cat 18层
- [-1, 2, C3k2, [256, False]] # 25 (实际通道: 64)
# 【CBAM 4】:上一层输出通道是 64
- [-1, 1, CBAM, [64, 7]] # 26
- [-1, 1, Conv, [256, 3, 2]] # 27
- [[-1, 14], 1, Concat, [1]] # 28 cat 14层
- [-1, 2, C3k2, [512, False]] # 29 (实际通道: 128)
# 【CBAM 5】:上一层输出通道是 128
- [-1, 1, CBAM, [128, 7]] # 30
- [-1, 1, Conv, [512, 3, 2]] # 31
- [[-1, 11], 1, Concat, [1]] # 32 cat 11层
- [-1, 2, C3k2, [1024, True]] # 33 (实际通道: 256)
# 【CBAM 6】:上一层输出通道是 256
- [-1, 1, CBAM, [256, 7]] # 34
# Detect 头
- [[22, 26, 30, 34], 1, Detect, [nc]] # 35
这样存在的问题
模型无法随意切换大小(失去 YOLO 动态缩放)
因为完全没动 tasks.py,YOLO 就不知道怎么动态缩放这个模块的通道。
在这份 YAML 中,手工把 yolo11n(width=0.25)缩放后的通道数 256 硬编码写进了括号里。
这意味着:这个 YAML 只能跑 yolo11n。如果你以后想把模型换成大模型(比如切换到 scales 里的 m 或者 x),你必须手动写通道数。kernel_size 最佳值就是7 所以不用改
自适应通道数据
首先去掉上面在 base_modules 中加入的 CBAM
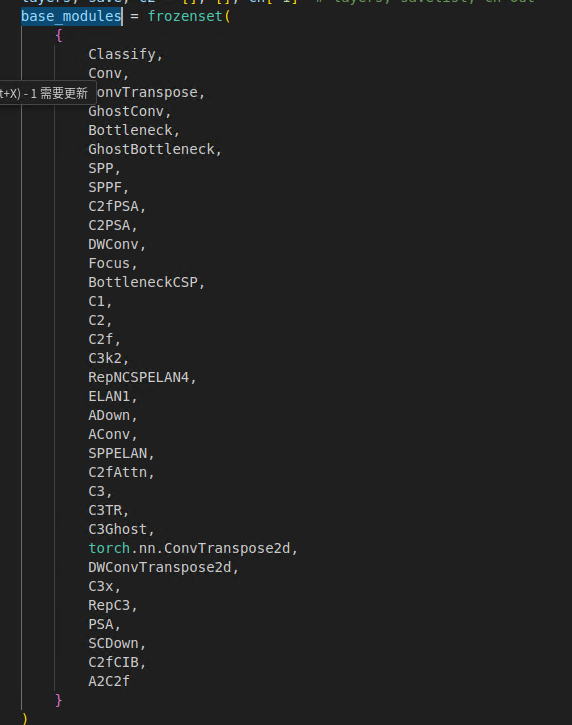
在if m in base_modules: 分支后加入拦截代码
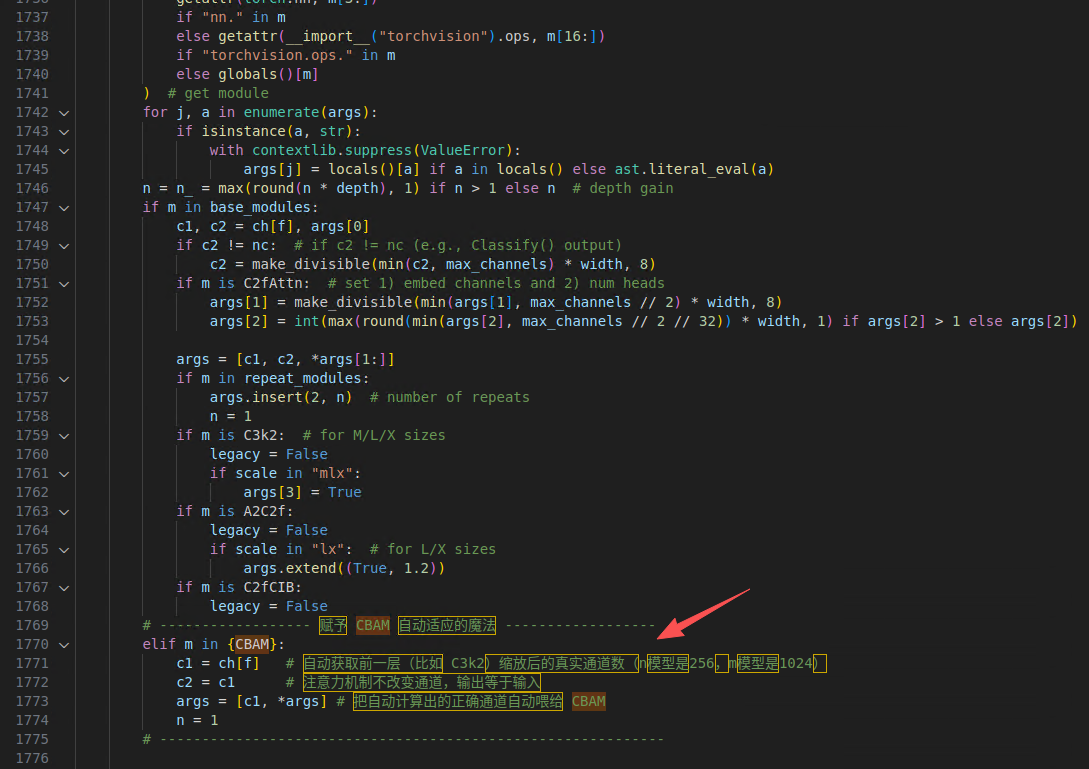
# ------------------ 赋予 CBAM 自动适应的魔法 ------------------
elif m in {CBAM}:
c1 = ch[f] # 自动获取前一层(比如 C3k2)缩放后的真实通道数(n模型是256,m模型是1024)
c2 = c1 # 注意力机制不改变通道,输出等于输入
args = [c1, *args] # 把自动计算出的正确通道自动喂给 CBAM
n = 1
# ------------------------------------------------------------
# Ultralytics YOLO , AGPL-3.0 license
# YOLO11 object detection model with P2-P5 outputs + CBAM 自动通道版
# Parameters
nc: 80 # number of classes
scales:
# [depth, width, max_channels]
n: [0.50, 0.25, 1024]
s: [0.50, 0.50, 1024]
m: [0.50, 1.00, 512]
l: [1.00, 1.00, 512]
x: [1.00, 1.50, 512]
# YOLO11-P2 backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]] # 2
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]] # 4
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]] # 6
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]] # 8
- [-1, 1, CBAM, []] # 9 【自动计算通道】
- [-1, 1, SPPF, [1024, 5]] # 10
- [-1, 2, C2PSA, [1024]] # 11
# YOLO11-P2 head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 12
- [[-1, 6], 1, Concat, [1]] # 13 cat backbone 第 6 层
- [-1, 2, C3k2, [512, False]] # 14
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 15
- [[-1, 4], 1, Concat, [1]] # 16 cat backbone 第 4 层
- [-1, 2, C3k2, [256, False]] # 17 (P3/8-small)
- [-1, 1, CBAM, []] # 18 【自动计算通道】
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 19
- [[-1, 2], 1, Concat, [1]] # 20 cat backbone 第 2 层
- [-1, 2, C3k2, [128, False]] # 21 (P2/4-xsmall)
- [-1, 1, CBAM, []] # 22 【自动计算通道】
- [-1, 1, Conv, [128, 3, 2]] # 23
- [[-1, 18], 1, Concat, [1]] # 24 cat 刚才第 18 层的 CCBAM
- [-1, 2, C3k2, [256, False]] # 25 (P3/8-small)
- [-1, 1, CBAM, []] # 26 【自动计算通道】
- [-1, 1, Conv, [256, 3, 2]] # 27
- [[-1, 14], 1, Concat, [1]] # 28 cat 刚才第 14 层的 C3k2
- [-1, 2, C3k2, [512, False]] # 29 (P4/16-medium)
- [-1, 1, CBAM, []] # 30 【自动计算通道】
- [-1, 1, Conv, [512, 3, 2]] # 31
- [[-1, 11], 1, Concat, [1]] # 32 cat backbone 最后一层(第 11 层)
- [-1, 2, C3k2, [1024, True]] # 33 (P5/32-large)
- [-1, 1, CBAM, []] # 34 【自动计算通道】
# Detect 头的输入应当严格绑定 [22, 26, 30, 34] 这四个检测特征层
- [[22, 26, 30, 34], 1, Detect, [nc]] # 35 Detect(P2, P3, P4, P5)
训练即可
自定义的CBAM模块加入
加入源代码
如图所示 在 nn 文件夹中建立一个 addattention文件夹用于存放自定义模型
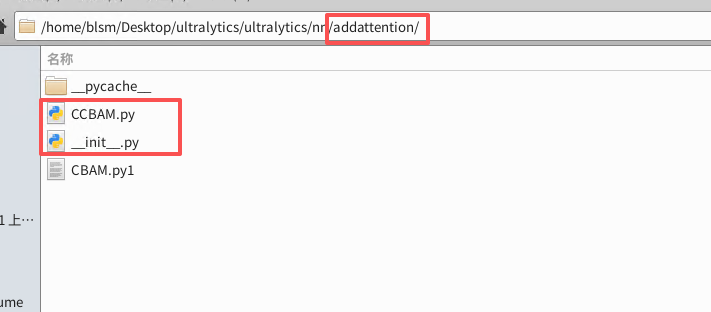
新增一个 CCBAM.py 和一个 __init__.py
CCBAM.py 代码
import torch
import math
import torch.nn as nn
import torch.nn.functional as F
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
class ChannelGate(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max']):
super(ChannelGate, self).__init__()
self.gate_channels = gate_channels
self.mlp = nn.Sequential(
Flatten(),
nn.Linear(gate_channels, gate_channels // reduction_ratio),
nn.ReLU(),
nn.Linear(gate_channels // reduction_ratio, gate_channels)
)
self.pool_types = pool_types
def forward(self, x):
channel_att_sum = None
for pool_type in self.pool_types:
if pool_type=='avg':
avg_pool = F.avg_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( avg_pool )
elif pool_type=='max':
max_pool = F.max_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( max_pool )
elif pool_type=='lp':
lp_pool = F.lp_pool2d( x, 2, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( lp_pool )
elif pool_type=='lse':
# LSE pool only
lse_pool = logsumexp_2d(x)
channel_att_raw = self.mlp( lse_pool )
if channel_att_sum is None:
channel_att_sum = channel_att_raw
else:
channel_att_sum = channel_att_sum + channel_att_raw
scale = F.sigmoid( channel_att_sum ).unsqueeze(2).unsqueeze(3).expand_as(x)
return x * scale
def logsumexp_2d(tensor):
tensor_flatten = tensor.view(tensor.size(0), tensor.size(1), -1)
s, _ = torch.max(tensor_flatten, dim=2, keepdim=True)
outputs = s + (tensor_flatten - s).exp().sum(dim=2, keepdim=True).log()
return outputs
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.compress = ChannelPool()
self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = F.sigmoid(x_out) # broadcasting
return x * scale
class CCBAM(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max'], no_spatial=False):
super(CCBAM, self).__init__()
self.ChannelGate = ChannelGate(gate_channels, reduction_ratio, pool_types)
self.no_spatial=no_spatial
if not no_spatial:
self.SpatialGate = SpatialGate()
def forward(self, x):
x_out = self.ChannelGate(x)
if not self.no_spatial:
x_out = self.SpatialGate(x_out)
return x_out
init.py代码
from .CCBAM import *
修改 tasks.py
加入导入模块
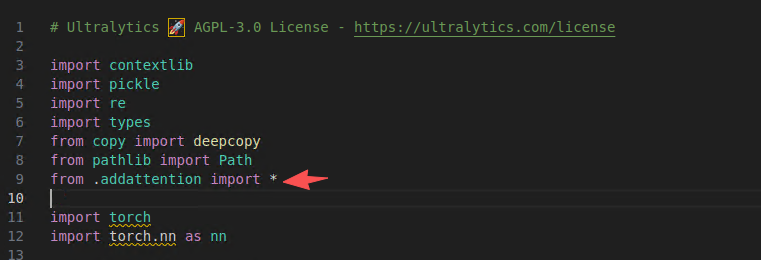
在if m in base_modules: 分支后加入拦截代码
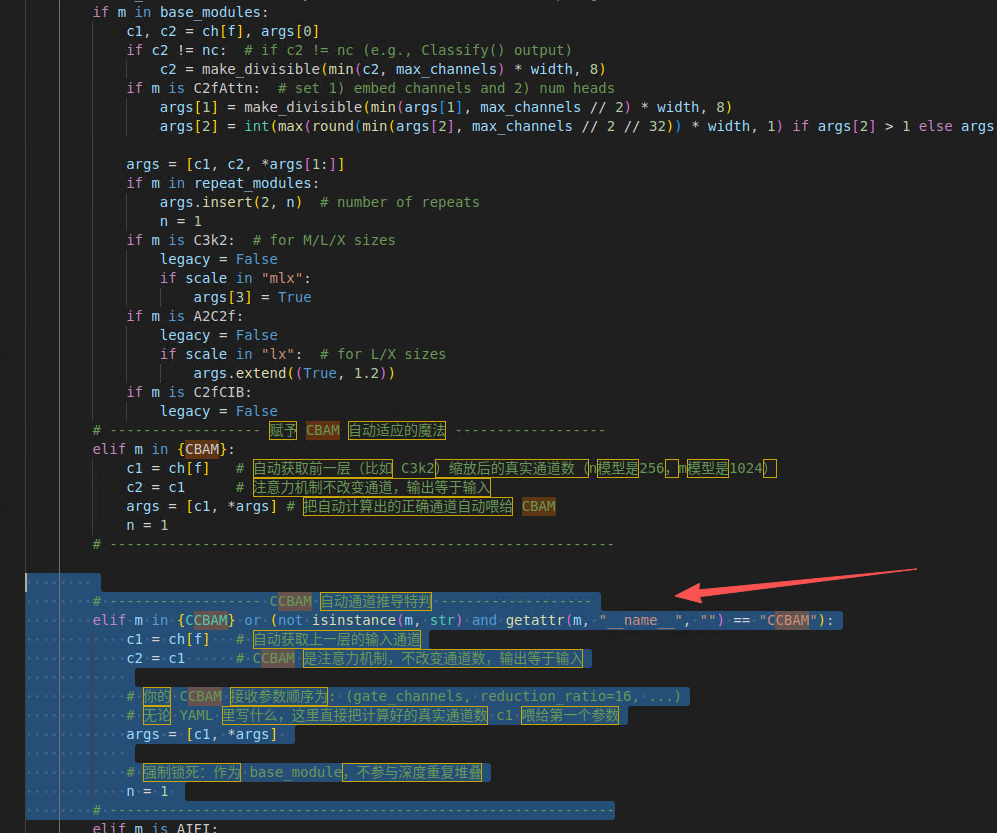
# ------------------ CCBAM 自动通道推导特判 ------------------
elif m in {CCBAM} or (not isinstance(m, str) and getattr(m, "__name__", "") == "CCBAM"):
c1 = ch[f] # 自动获取上一层的输入通道
c2 = c1 # CCBAM 是注意力机制,不改变通道数,输出等于输入
# 你的 CCBAM 接收参数顺序为: (gate_channels, reduction_ratio=16, ...)
# 无论 YAML 里写什么,这里直接把计算好的真实通道数 c1 喂给第一个参数
args = [c1, *args]
# 强制锁死:作为 base_module,不参与深度重复堆叠
n = 1
# ------------------------------------------------------------
yaml配置文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P2-P5 outputs + CCBAM 自动通道精简版
# Parameters
nc: 80 # number of classes
scales:
# [depth, width, max_channels]
n: [0.50, 0.25, 1024]
s: [0.50, 0.50, 1024]
m: [0.50, 1.00, 512]
l: [1.00, 1.00, 512]
x: [1.00, 1.50, 512]
# YOLO11-P2 backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]] # 2
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]] # 4
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]] # 6
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]] # 8
- [-1, 1, SPPF, [1024, 5]] # 9 -> 先扩大感受野
- [-1, 2, C2PSA, [1024]] # 10 -> 再注入空间自注意力
- [-1, 1, CCBAM, []] # 11 -> 作为 Backbone 终极提炼层 (1024卡槽)
# YOLO11-P2 head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 12
- [[-1, 6], 1, Concat, [1]] # 13 融合 Backbone 第 6 层 (512) -> 当前总通道 1536
- [-1, 2, C3k2, [512, False]] # 14 输出 512
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 15
- [[-1, 4], 1, Concat, [1]] # 16 融合 Backbone 第 4 层 (512) -> 当前总通道 1024
- [-1, 2, C3k2, [256, False]] # 17 输出 256
- [-1, 1, CCBAM, []] # 18 【自动通道:输出 256】
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 19
- [[-1, 2], 1, Concat, [1]] # 20 融合 Backbone 第 2 层 (256) -> 当前总通道 512
- [-1, 2, C3k2, [128, False]] # 21 (P2/4-xsmall) -> 输出 128
- [-1, 1, CCBAM, []] # 22 【自动通道:输出 128】 -> 🚀 检测层 1 (极小目标)
# ----- 自底向上(PANet 路径聚合) -----
- [-1, 1, Conv, [256, 3, 2]] # 23 通道数从 128 提升至 256,与第 18 层完全对齐
- [[-1, 18], 1, Concat, [1]] # 24 融合 18 层 CCBAM (256) -> 当前总通道 512
- [-1, 2, C3k2, [256, False]] # 25 (P3/8-small) -> 输出 256
- [-1, 1, CCBAM, []] # 26 【自动通道:输出 256】 -> 🚀 检测层 2 (小目标)
- [-1, 1, Conv, [512, 3, 2]] # 27
- [[-1, 14], 1, Concat, [1]] # 28 融合 14 层 C3k2 (512) -> 当前总通道 1024
- [-1, 2, C3k2, [512, False]] # 29 (P4/16-medium) -> 输出 512
- [-1, 1, CCBAM, []] # 30 【自动通道:输出 512】 -> 🚀 检测层 3 (中目标)
- [-1, 1, Conv, [1024, 3, 2]] # 31 通道数从 512 提升至 1024,与第 11 层完全对齐
- [[-1, 11], 1, Concat, [1]] # 32 融合 11 层 CCBAM (1024) -> 当前总通道 2048
- [-1, 2, C3k2, [1024, True]] # 33 (P5/32-large) -> 输出 1024
- [-1, 1, CCBAM, []] # 34 【自动通道:输出 1024】 -> 🚀 检测层 4 (大目标)
# 检测头:绑定四个特征层
- [[22, 26, 30, 34], 1, Detect, [nc]] # 35 Detect(P2, P3, P4, P5)
训练即可


















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










