



最近AI圈有个说法正在快速成为共识:模型不是护城河,Loop Engineering 才是。
LangChain 官方博客最新发布了一篇题为《The Art of Loop Engineering》的文章,系统拆解了循环工程的完整架构。今天,我们就以这篇 LangChain 的官方文章为核心,深度解读什么是循环工程?它为什么比模型调优更重要?以及它到底分为哪几个层级?
为什么需要 Loop Engineering?
当下,**模型本身变得越来越“不值钱”。**谁都能调最强的 API、谁都能下最新的开源权重。真正能拉开差距的,是另一件事。
传统软件的逻辑是确定的,1+1 永远等于 2,写对一次就永远对。但大模型是概率性的,同一句话,今天这么答、明天那么答,会编造、会出错、会随数据慢慢漂移。你没法假设它一次就对。
所以做 AI 产品,你得在每个可能出错的地方,装一个 “会回头看、不对就修”的循环。把这些循环设计好、组织好,就是 Loop Engineering(循环工程)。
这个概念在 2026 年 6 月被正式命名并系统化。Claude Code 负责人 Boris Cherny 的一句话道出了核心:“I don’t prompt Claude anymore. I have loops running that prompt Claude. My job is to write loops.”翻译过来就是你的角色从每次手动提问变成了设计一个能一直问下去的循环。
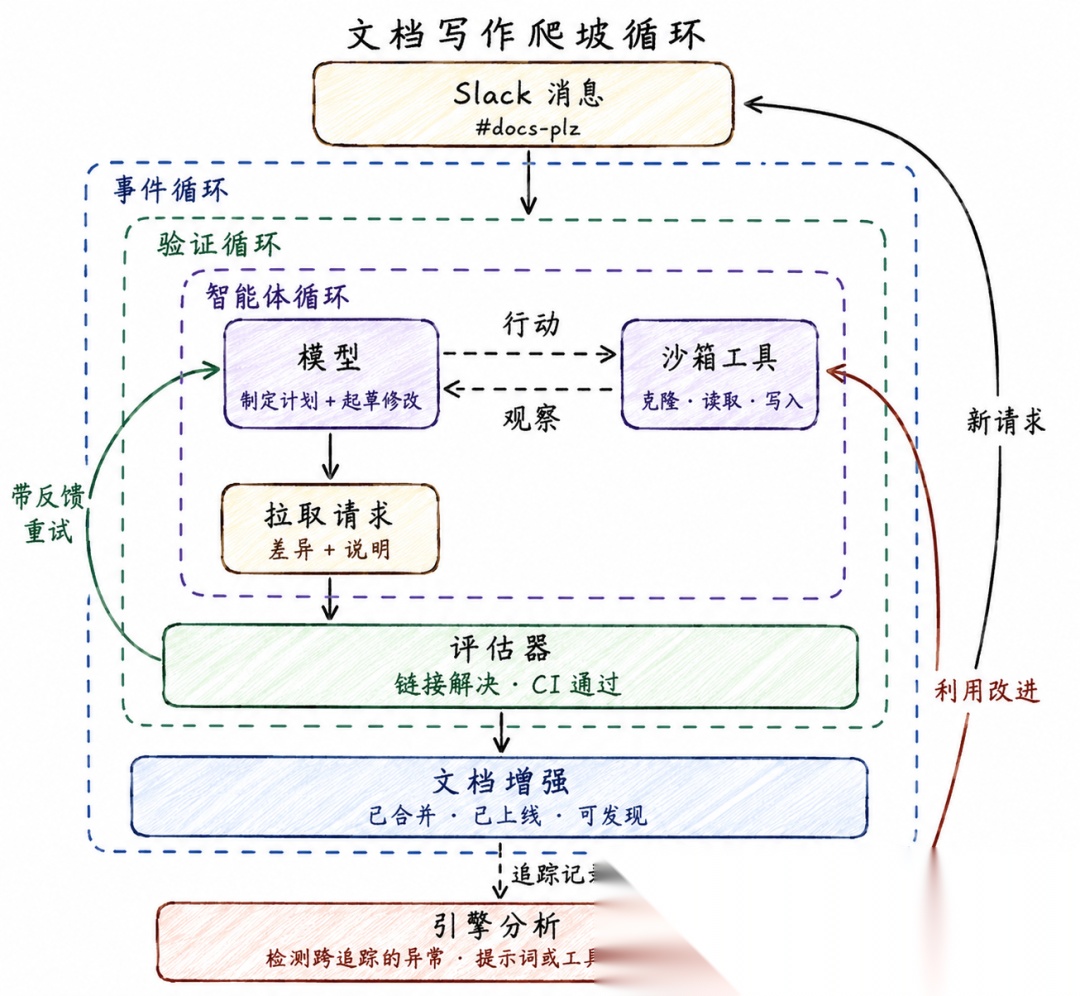
Loop Engineering的四层循环
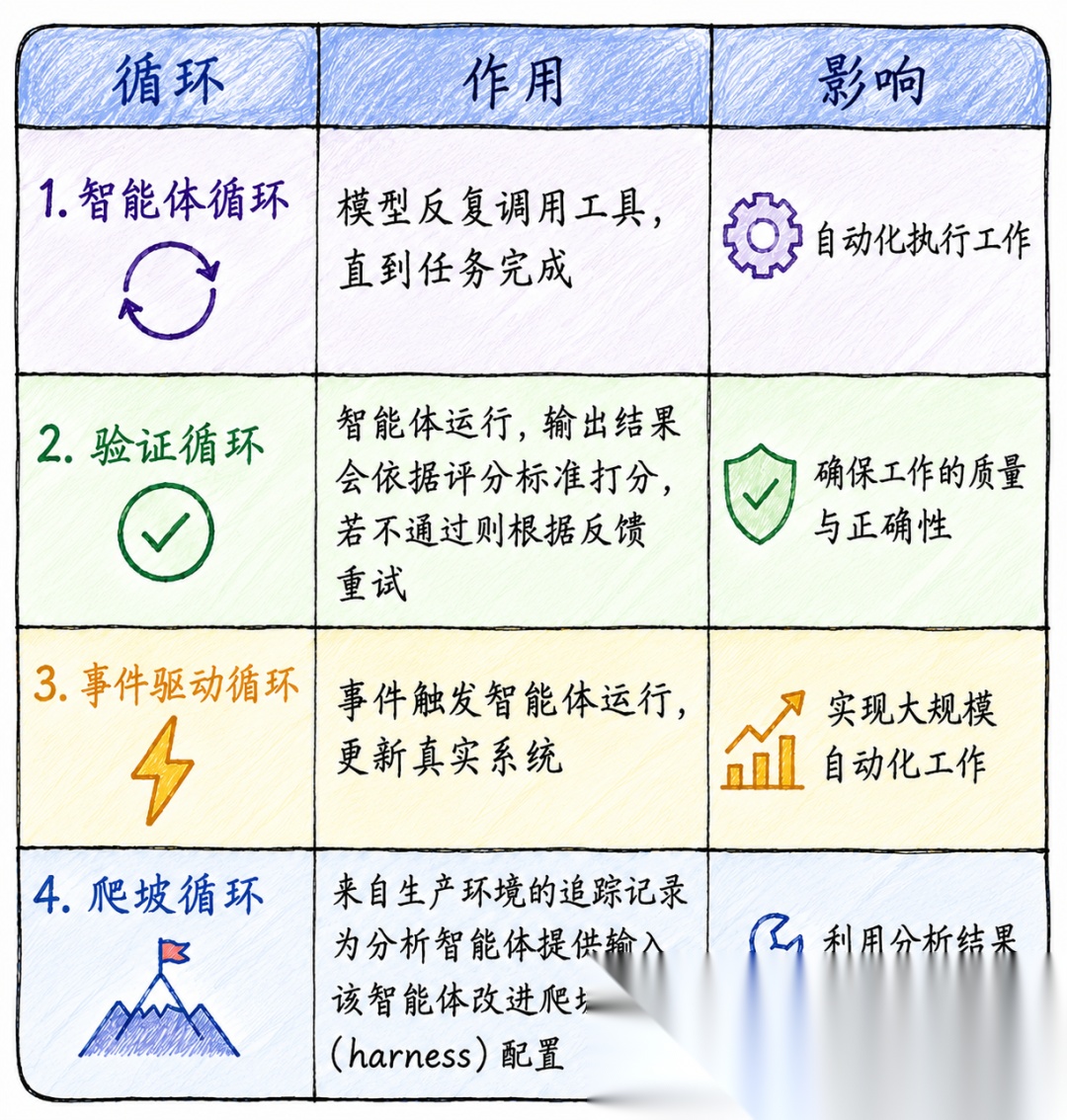
第一层:智能体循环(Agent Loop)
最底层、最基础的循环。
核心就是接受需求 → 让模型选择要执行的工具 → 执行工具 → 继续调用模型,直到模型不再调用任何工具为止。这是所有智能体系统赖以运转的基础单元。
用大白话说就是模型在循环里调用工具,直到任务完成。
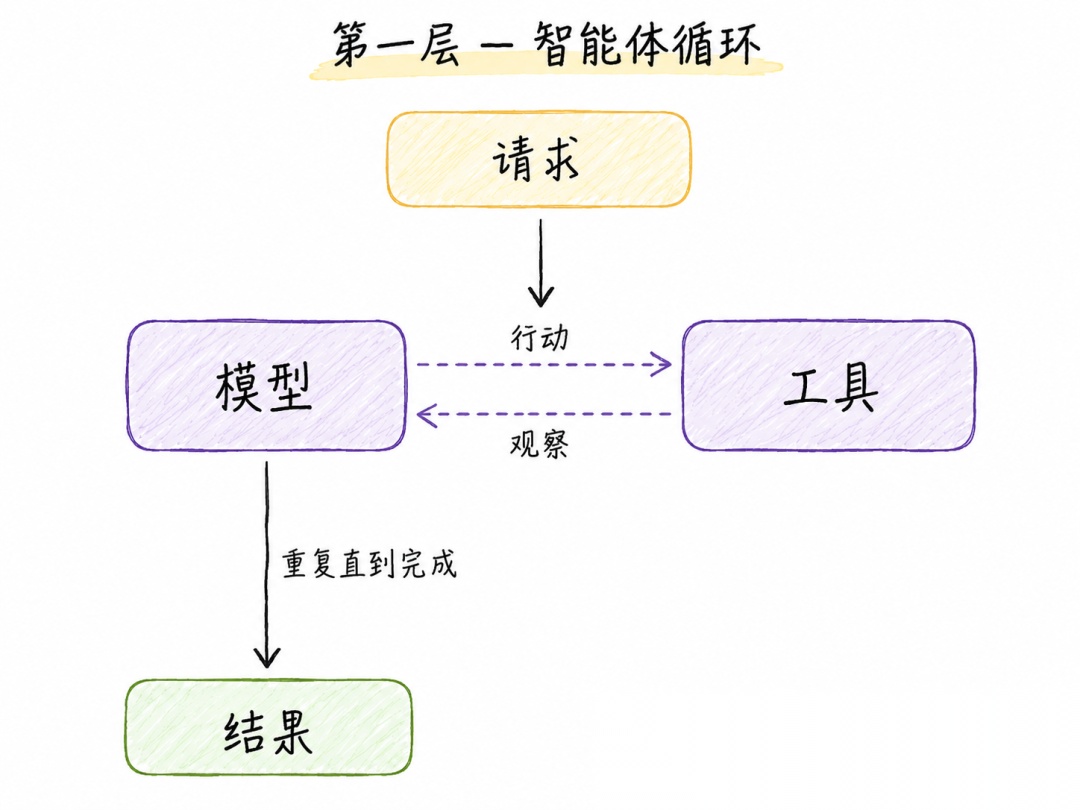
LangChain展示了内部的文档智能体落地表现(后续都以此为例)。在收到优化接口文档请求后,智能体循环执行克隆代码仓库→读取原有文档文件→撰写修改方案→发起PR 请求等等。
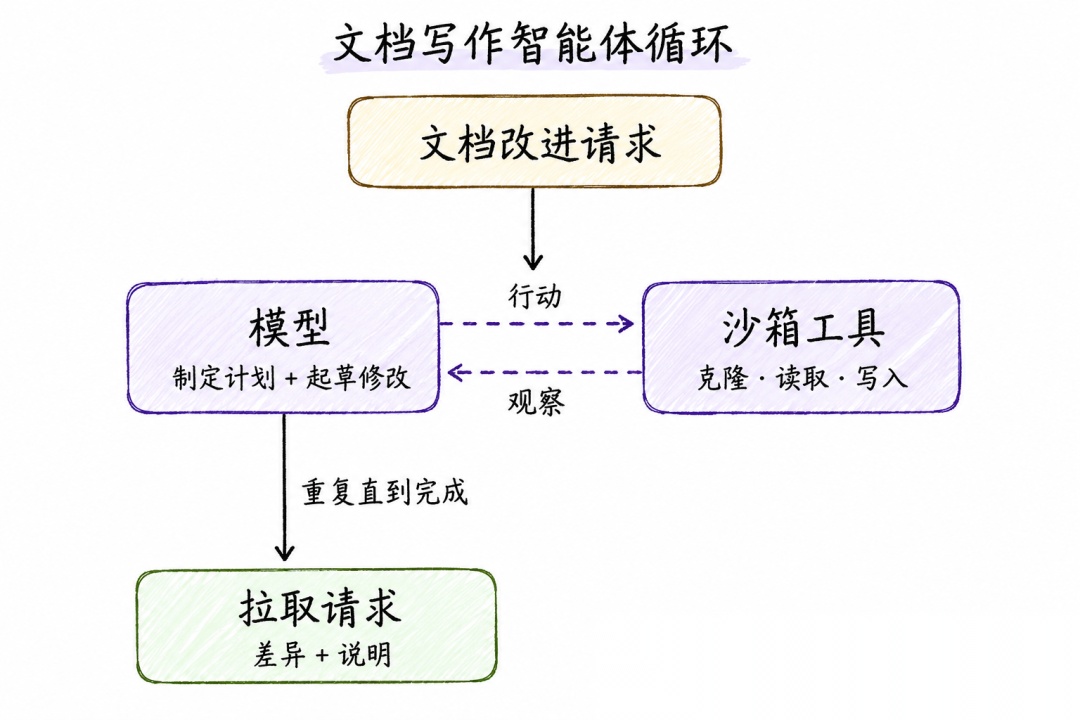
第二层:验证循环(Verification Loop)
给智能体输出增加一个标准化质检层,不合格自动带反馈回去重跑,保障交付质量。
整个流程就是执行完整智能体循环→校验器对照评分标准评估输出→不达标携带失败反馈回传给模型重试,校验通过则结束流程。
校验器分为两种:
-
确定性规则校验:固定脚本检测链接有效性、CI 流程、代码格式;
-
LLM 裁判校验:用另一大模型人工定义评分标准,从内容完整性、受众适配度做主观评审。
LangChain的文档智能体在生成文档 PR 后,校验器自动执行全链路检测:文档超链接全部可访问、代码 CI 检查无报错、修改范围严格匹配原始需求。任意一项不通过,自动把错误清单发给智能体重新修改。
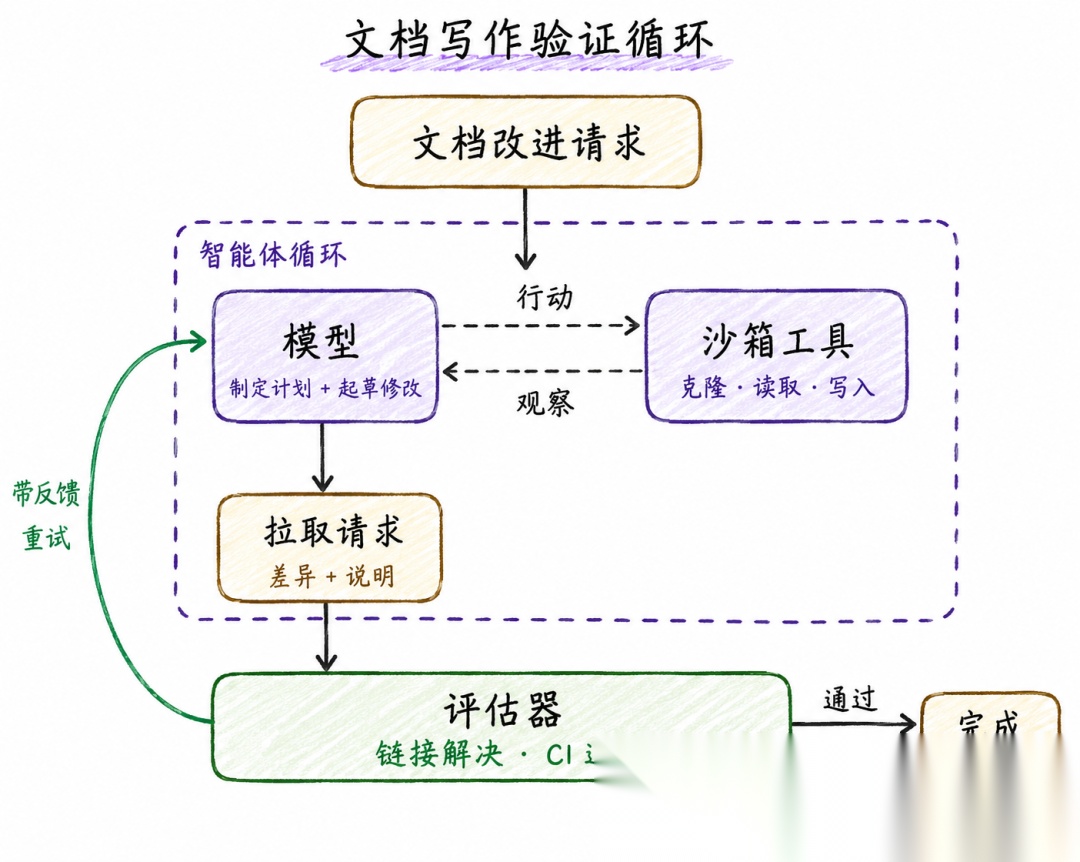
第三层:事件驱动循环(Event-driven Loop)
脱离人工手动触发,把智能体接到真实环境里,实现 7×24 小时规模化后台自动化。整个流程是外部事件触发→启动校验循环→执行智能体任务→完成后同步更新业务系统,等待下一轮事件唤醒。
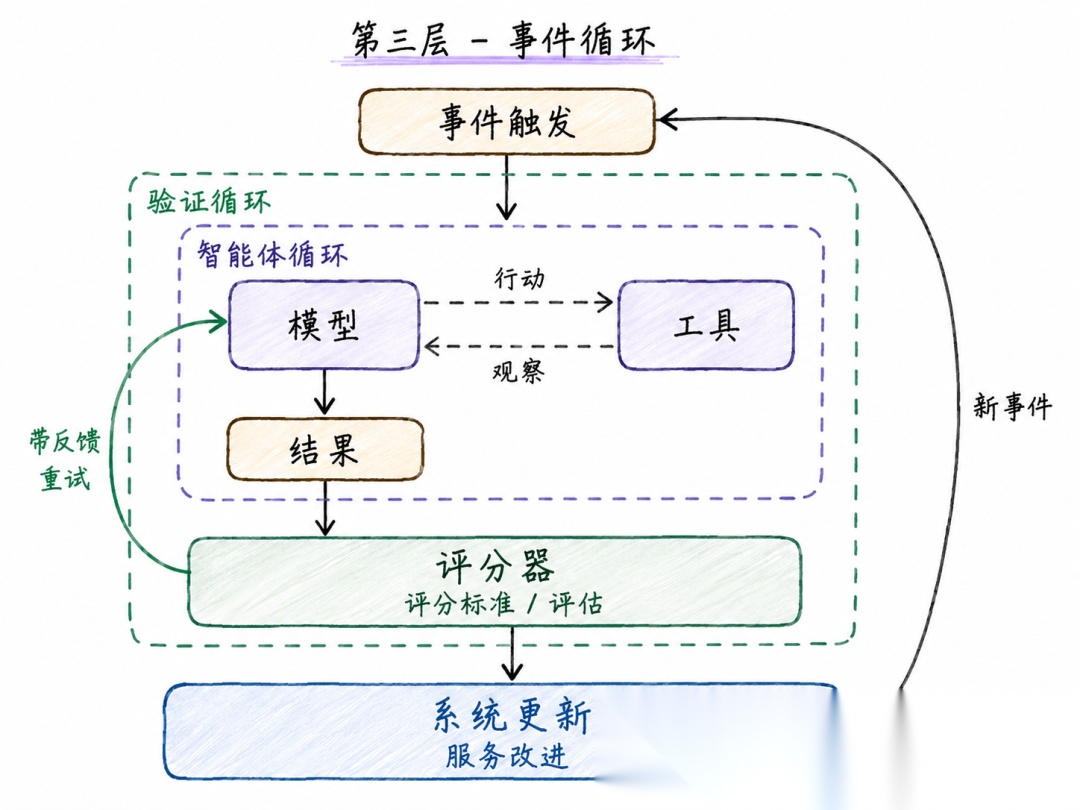
文档智能体的事件驱动循环首先是发送文档优化需求,消息作为事件自动唤醒整套校验 + 执行循环,文档修改合并上线后同步更新知识库索引,等待下一次用户请求。
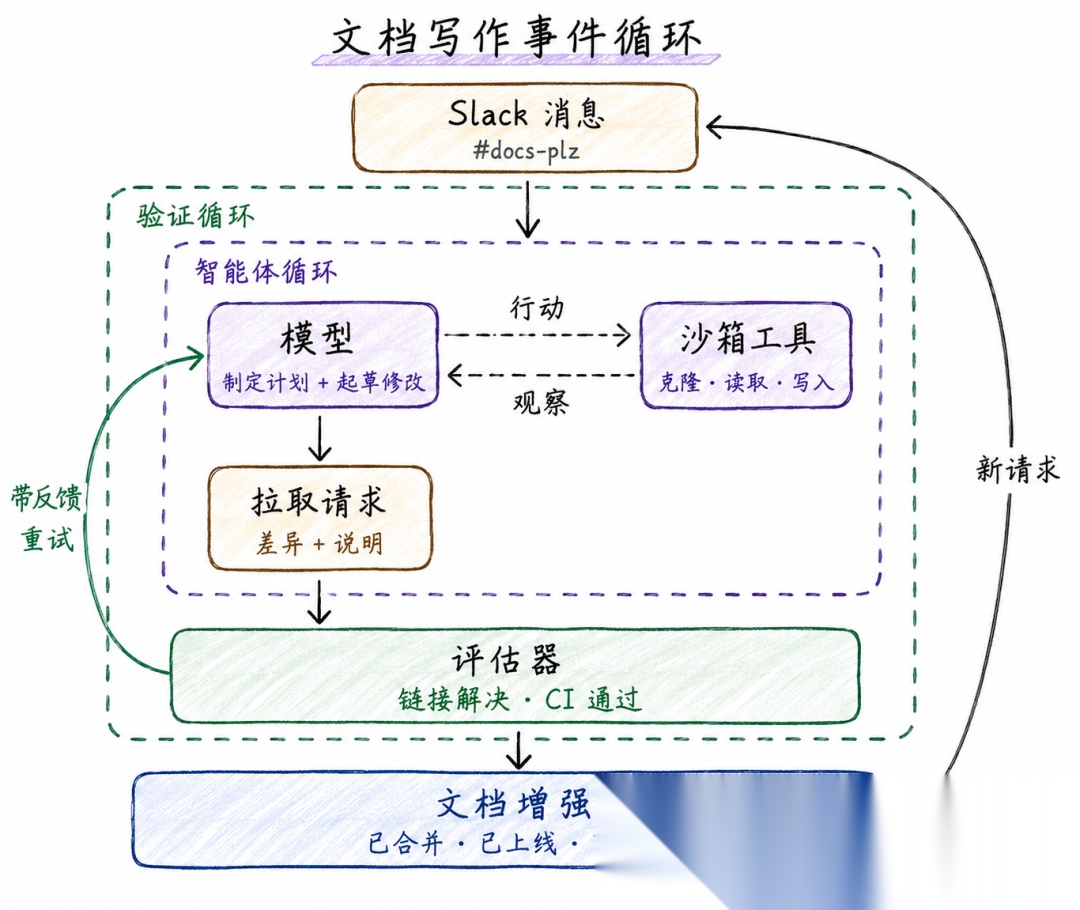
前两层只是单次运行的工具,事件循环让智能体嵌入业务流水线,从临时调用脚本升级为持续运转的自动化服务。
第四层:爬坡循环(Hill Climbing Loop)
这一层是最重要的一层。前三层是实现工作自动化,第四层是实现改进自动化!
利用全链路运行日志(Trace),包括模型推理记录、工具调用历史、校验失败反馈、迭代重试记录,然后让一个分析智能体去看这些记录、找出问题,反过来修改智能体自己的配置,实现自我进化。
整个流程是事件触发完整三层内层循环→生成全流程运行轨迹日志→分析智能体扫描日志识别系统性缺陷→自动更新提示词、工具、校验规则,反向优化内层循环逻辑。
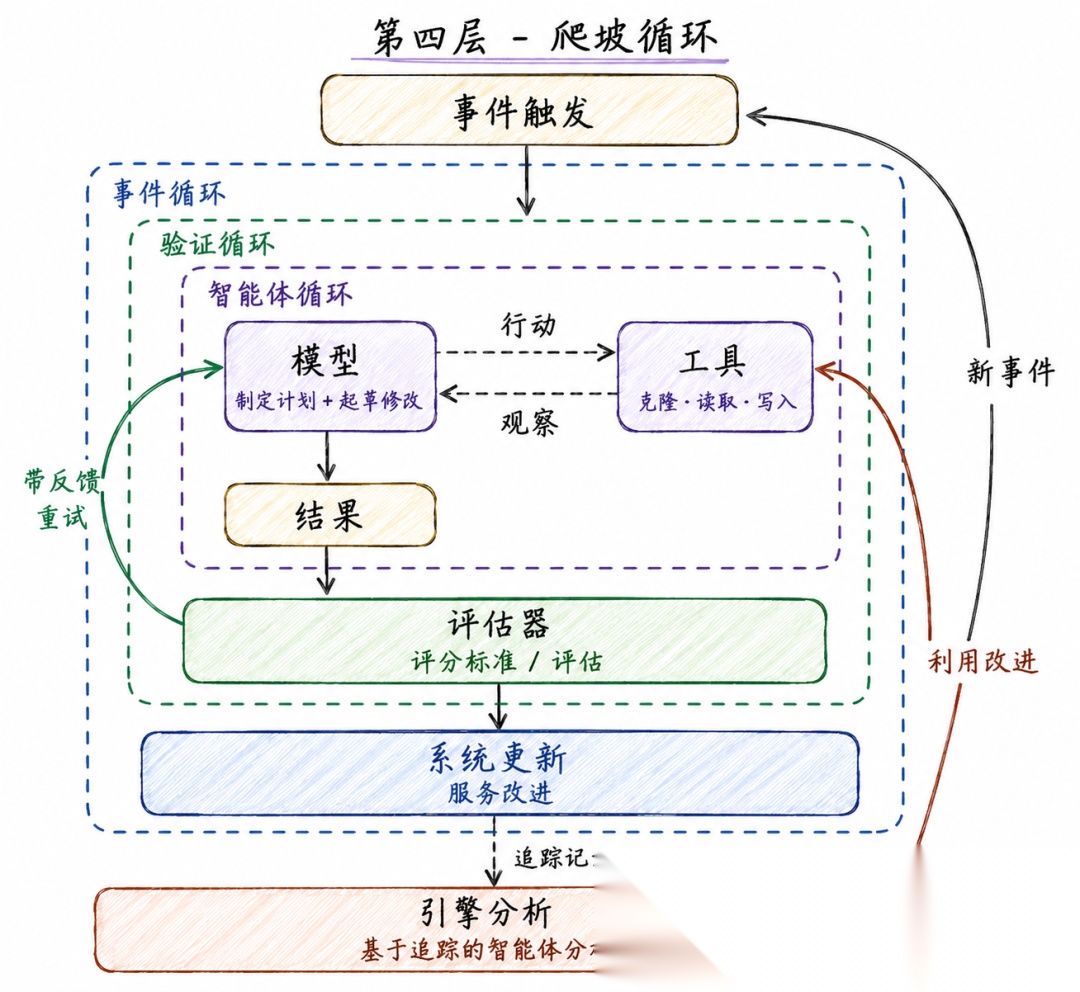
文档智能体的实际运行表现是LangSmith Engine(轨迹分析智能体)定期扫描所有文档修改日志,多次出现同类问题(如 API 参数描述缺失、代码示例报错)时,自动生成优化工单,更新智能体基础提示词、补充专用校验规则,从根源降低后续出错概率。
如果说前三层是让 AI 替你工作,那第四层就是让 AI 替你优化它自己的工作方式。
人机协同,自动化不等于淘汰人工
四层循环全程预留人工介入节点,规避纯自动化高风险场景,实现 Human-in-the-loop可控设计:
-
智能体执行层:数据库操作、资金交易等高风险工具调用前,强制人工审批;
-
校验层:复杂业务文案、面向客户的对外输出,由人类担任评审裁判;
-
事件服务层:智能体生成交付物后,人工确认再同步至业务系统;
-
自优化层:系统自动生成的提示词、工具配置修改,必须人工审核后上线。
机器负责标准化、重复性、大批量校验;人类负责价值判断、行业专业审美、高风险决策,二者互补而非替代。
写在最后
市面上开源/闭源大模型能力差距持续缩小,单纯依赖模型、堆砌提示词的智能体极易被复刻。真正的差异化竞争力,是层层嵌套循环搭建的完整管控体系。过去 AI 工程师 80% 精力消耗在调优提示词,未来核心工作是设计多层反馈循环、定义校验标准、搭建日志分析优化链路,让系统自动生成、迭代提示词与执行策略。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】



















 167
167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










