



作者:庞子奇UIUC CS PhD(已授权)
https://zhuanlan.zhihu.com/p/1912734467589650419
>> 加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术

OpenAI发布了Thinking with Images[1],道理很简单:如果Vision-Language Model可以自由地使用一些基本操作帮助视觉理解,比如说放大、旋转。那么也可以在只基于文字的Test-time Scaling的基础上,进一步增强视觉Reasoning能力。
时间虽然只过去了短短一个月,Thinking with Images早已变成了“万军之战”的前线,每天盯着Arxiv就不断地有新的论文冒出来。下面就是来自战地记者的报道。希望这个极简版报道可以帮助社区里的研究者理清脉络、找全Related works。
受限于篇幅,战地记者只能讲四个有代表性的工作。完整的相关Paper的列表在最后,各位大佬可以拉到最后看看自己的文章是不是在其中。
1. 缘起:
Prompting - VisualSketch Pad

这是去年NeurIPS的文章,算是Thinking with Image在学术界最早开始探索的一个文章。VisualSketch Pad的想法很简单:那就是通过使用Tools (工具) 来制作新的Image,成为Chain-of-thought (思维链) 的一部分。比如说,面对几何题可以做辅助线、面对自然图片可以去用Detection工具搜索。
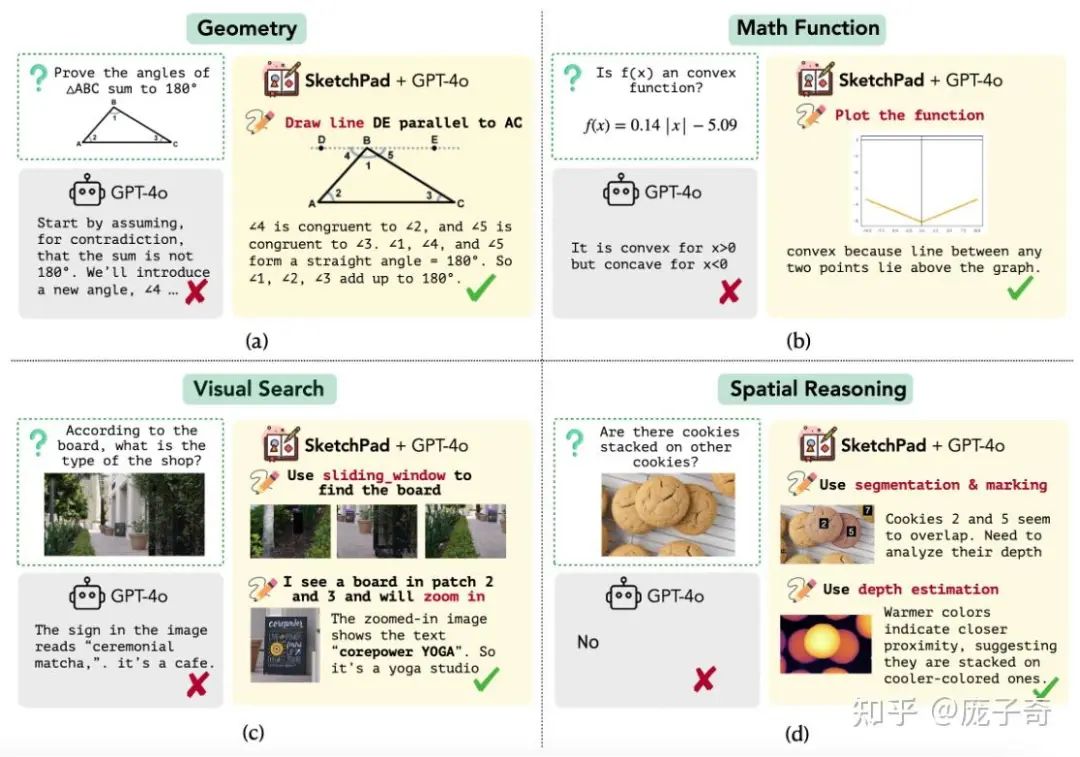
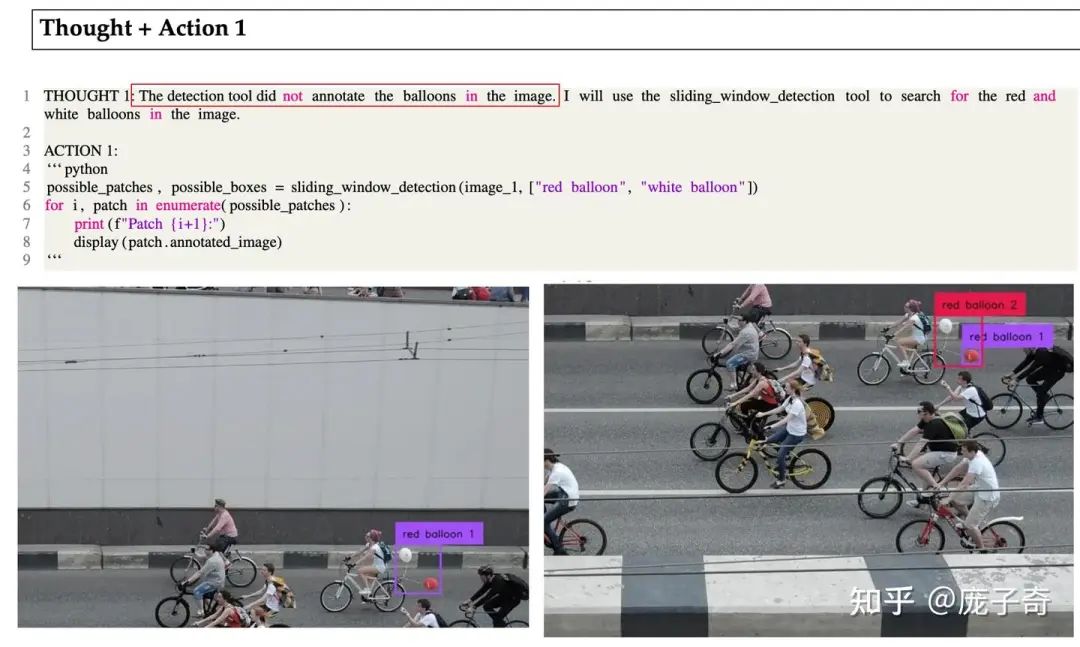
我个人是相信由研究者制作的SFT数据和in-context example决定了智能被激发的形式,所以VisualSketchPad的In-context Example下了心思,特意做了一个需要做思维链修正的例子,深得我心:
2. 进步:
Tool Learning - VisualToolAgent

当Tool的数量很多的时候,一个很自然的问题就是——到底什么工具去处理图片好。比如说在上面的VisualSketchPad里面,工具的调用和选择完全是基于In-context Example和模型本身的能力的。而这篇新文章的最主要贡献就是利用强化学习(RL)让模型学会了根据问题选择合理的工具。
做法其实不复杂:下面的Agent就是一个VLM,它可以根据问题选择合适的工具辅助视觉模型进行推理,而这个Policy是被RL训练得到的。
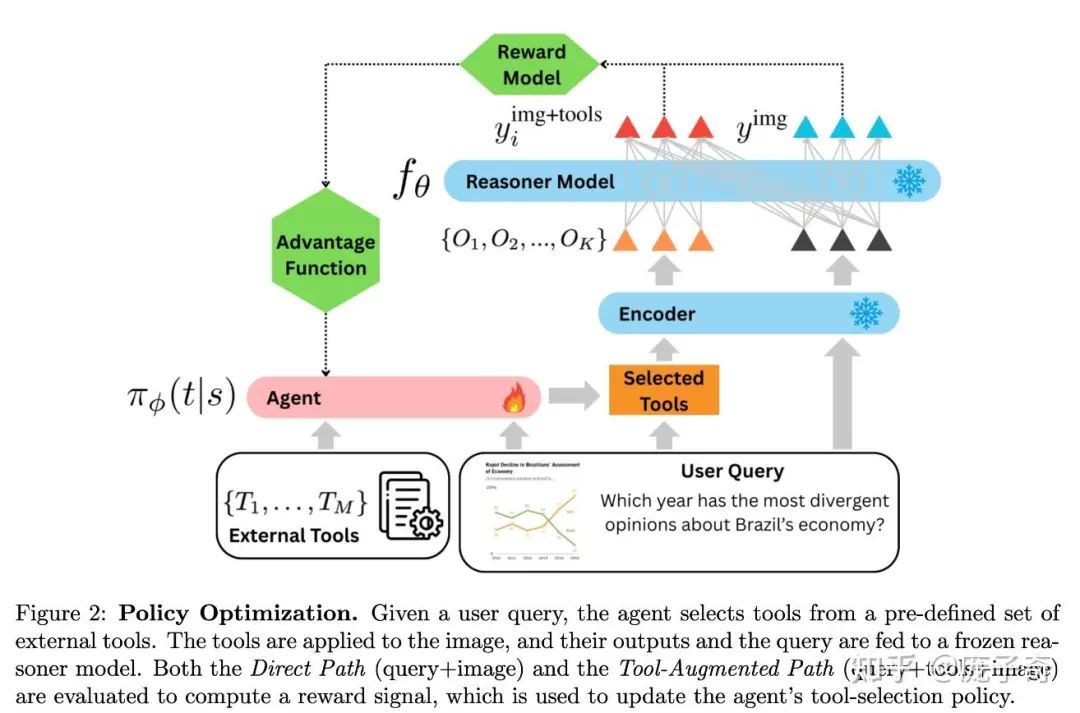
这个论文里一个非常有意思的结论是:对工具的选择可以迁移到新的VLM上,比如说在Qwen上训练的Tool Policy可以直接拿来用给GPT4o,说明对工具的使用又何尝不是一种可以泛化的知识呢。
3. 发展A:
原生Grounding - DeepEyes

这个论文我非常喜欢,而且作者 @ChenShawn 也写了自己的一些总结。这个文章和之前两个的区别在于,它是一种“极简”的对Tool的使用,与其调用外界的Detection模型,不如让模型自己去内化Grounding。这件事情的好坏当然Debateable,而且通用模型当然很难打过专业的感知模型,但是战地记者本人感觉这种做法更符合对AGI的追求和期待。
方法非常朴素:模型自己学习Grounding,然后中间的Agent去调用工具查看图片的细节,然后多轮对信息进行聚合。但是这个论文的一些细节我非常喜欢。
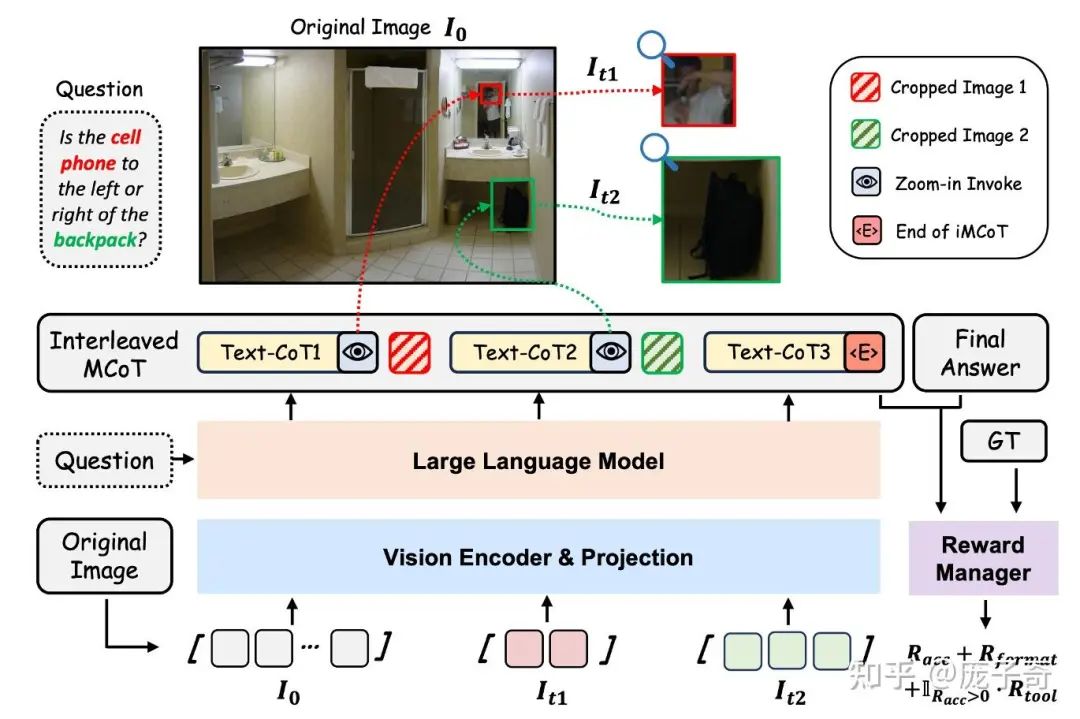
细节1
当且仅当最终结果是对的,对工具的使用才会被鼓励,所以模型不会去瞎用工具。

细节2
训练数据选得好,V*、ArxivQA和ThinkLite-VL组合在一起,基本包含了现在大家主流Evaluate的图像理解,比较方便学术界研究去Follow。
细节3
作者分析了训练过程中的Dynamics,和Search-R1对比其实有很多点可以挖掘:
-
• Response Length都是先下降再上升,但是DeepEyes多了一个下降阶段;
-
• Search-R1对工具的调用一直在增长,但是DeepEyes最后工具的使用其实有一个下降。
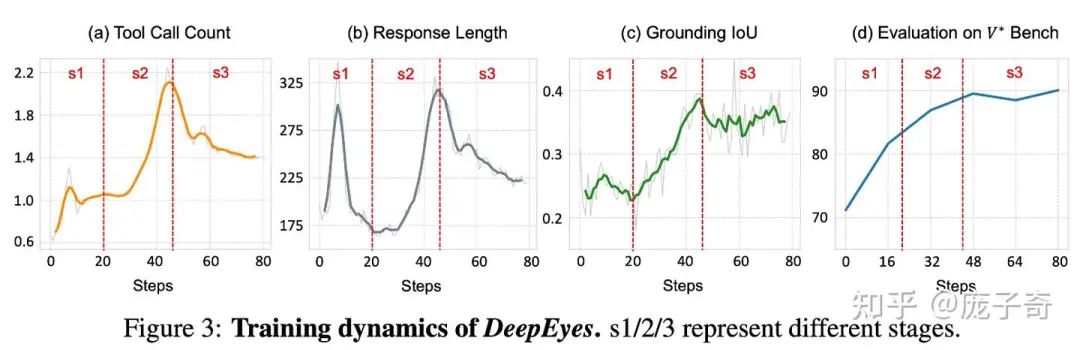
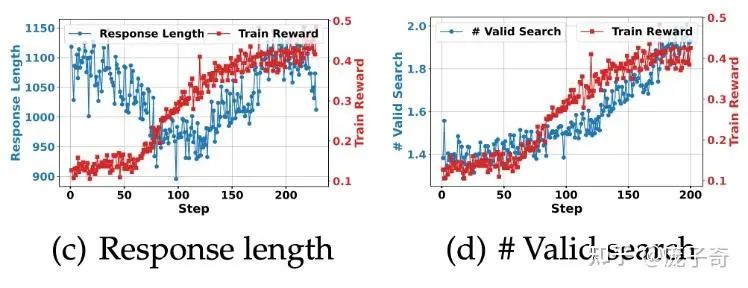
唯一的遗憾是,好像DeepEyes还是需要16xA100跑两天以上,对于学术界研究(e.g., 战地记者本人),还是太难了。
4. 发展B:
原生Image Tools - Thinking Only with Images

类似工作的最后一层就是,是不是可以用有生成能力的模型原生去修改图像,这样连调用工具都省了。当然,这件事情的好坏见仁见智,但是战地记者本人非常喜欢这个方向,因为和我自己尝试推进视觉GPT时刻的思考非常一致。
这个文章的做法就是,利用Large Vision Model,可以在图片上标记出中间思考步骤,比如说走迷宫。
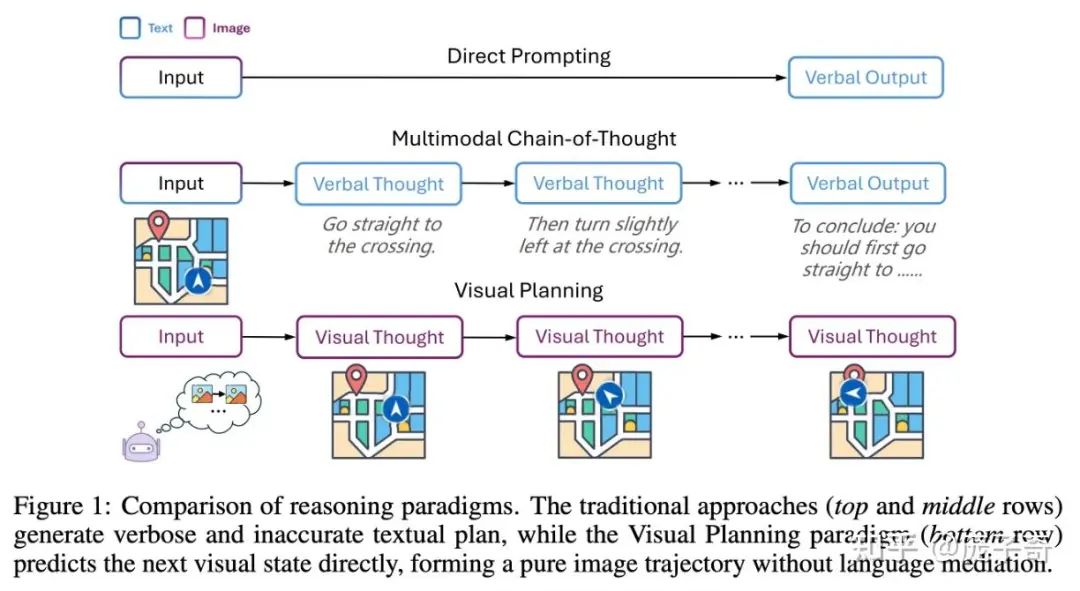
文章里有很多细节,但是战地记者本人最喜欢的事情在于这个文章展示了一种对于Exploration & Exploitation的Insight。为了让模型可以造出Valid的中间步骤,这个文章需要一个Pre-training阶段,让Large Vision Model去学习合理的Trajectory会产生怎样的图片。这里有两种选择:
-
• 让模型随机去探索;
-
• 让模型学习正确Trajectories的分布。
非常有意思的是,让模型学习随机探索,也就是学习一个更类似于World Model的东西,而不是Policy,带来了更好的Exploration和最终结果。所以我相信这个论文对搞robotics的同学可能也会有启发。
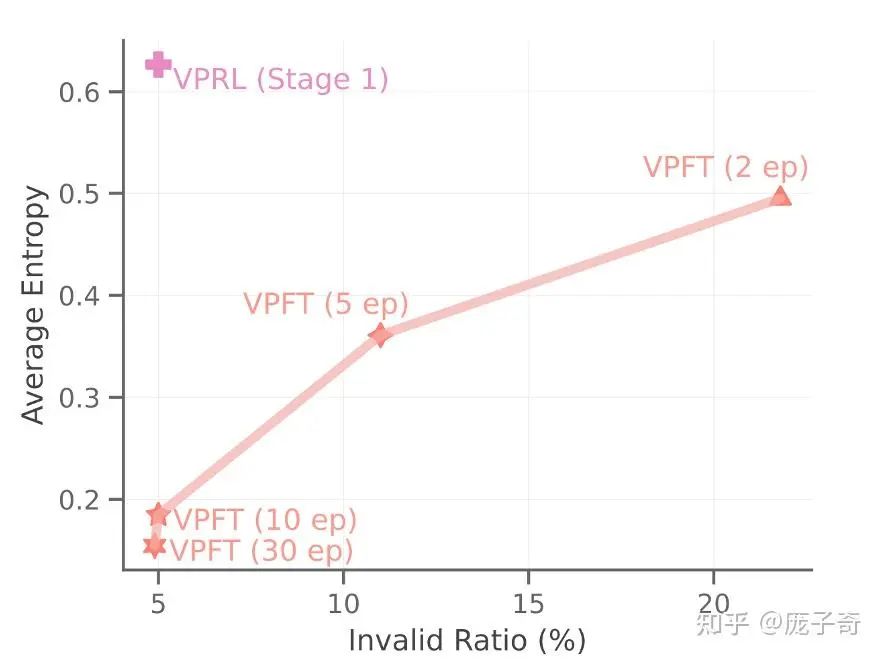
5. 未来会怎么样
一个月过去,出现了很多方法,虽说有些人觉得大同小异,不过都是GRPO的VLM应用,但是我本人还是感觉体现出了很多作者对于“什么是有效的智能”的独特理解。未来的亟需解决的一些任务包括:
-
• 因为VERL尚不稳定,所以整个领域也许需要Converge到一个Codebase上、同时用类似的Evaluation Benchmark才可以公平比较。
-
• 同理,multi-turn的作用是什么、怎么让multi-turn发挥最大的意义好像也不明朗。
-
• 我自己相信SFT数据的重要、Reasoning数据的重要,所以我个人思考的一个问题在于,什么样的Reasoning是我们真正想要而Cold-start强化学习很难带给我们的。
-
• 抛砖引玉,欢迎大家贡献自己觉得重要的问题!
6. Complete Paper List
除去上面重点讲解的四篇论文,下面也是最近涌现的优秀工作:
• Thinking with Generated Images
https://arxiv.org/abs/2505.22525
• SAM-R1: Leveraging SAM for Reward Feedback in Multimodal Segmentation via Reinforcement Learning
https://arxiv.org/abs/2505.22596
• Omni-R1: Reinforcement Learning for Omnimodal Reasoning via Two-System Collaboration
https://arxiv.org/abs/2505.20256
• GRIT: Teaching MLLMs to Think with Images
https://arxiv.org/abs/2505.15879
• Chain-of-Focus: Adaptive Visual Search and Zooming for Multimodal Reasoning via RL
https://arxiv.org/abs/2505.15436
• Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
https://arxiv.org/abs/2505.15966
• UniVG-R1: Reasoning Guided Universal Visual Grounding with Reinforcement Learning
https://arxiv.org/abs/2505.14231
• OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
https://arxiv.org/abs/2505.08617
• Perception-R1: Pioneering Perception Policy with Reinforcement Learning
https://arxiv.org/abs/2504.07954
引用链接
[1] Thinking with Images: https://openai.com/index/thinking-with-images/
往期推荐
揭示小规模SFT在R1-Style强化学习中的关键作用
梳理 RL-reasoning 的进展
总结!2025年大模型Agent RL训练多轮planning技术
万字长文总结!Reasoning模型的强化学习实现路径
强化学习算法梳理:从 PPO 到 GRPO 再到 DAPO
从字节、百川、Bespoke Labs 3个大模型项目,看RL驱动下的Agent技术趋势
Transformer原作、斯坦福、清华交大三篇论文共识:基座模型边界锁死RL能力上限


















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










