




摘要:大型视觉语言模型(LVLMs)中语言与视觉的融合,通过提升适应性、上下文推理能力和超越传统架构的泛化能力,彻底革新了基于深度学习的目标检测领域。这篇深度综述通过三步研究分析流程,系统梳理了当前LVLMs领域的最新进展:首先探讨视觉语言模型在目标检测中的运作机制,阐述这些模型如何运用自然语言处理(NLP)和计算机视觉(CV)技术实现目标检测与定位的革命性突破;接着解析近期LVLMs在架构创新、训练范式及输出灵活性方面的优势,重点说明其如何实现先进的目标检测上下文理解;随后全面评估视觉与文本信息整合的方法论,展示利用LVLMs实现更复杂目标检测与定位策略所取得的进展;此外,通过可视化图表直观呈现LVLMs在定位、分割等多样化场景中的表现,并将其实时性能、适应性和复杂度与传统深度学习系统进行对比。综合分析表明,LVLMs有望很快达到甚至超越传统目标检测方法的性能水平。然而,鉴于传统深度学习方法与 LVLMS 各自独特且互补的优势特性,预计未来将采用融合这两种目标检测模型的混合方案,以最大限度提升系统的速度、可靠性和鲁棒性。此外,本综述还指出了当前 LVLM 模式存在的若干主要局限性,提出了应对这些挑战的解决方案,并为该领域未来的发展制定了清晰路线图。基于本研究,我们得出结论:近期LVLM(大型视觉语言模型)的技术进步已并将继续对目标检测及自动化应用产生深远影响。
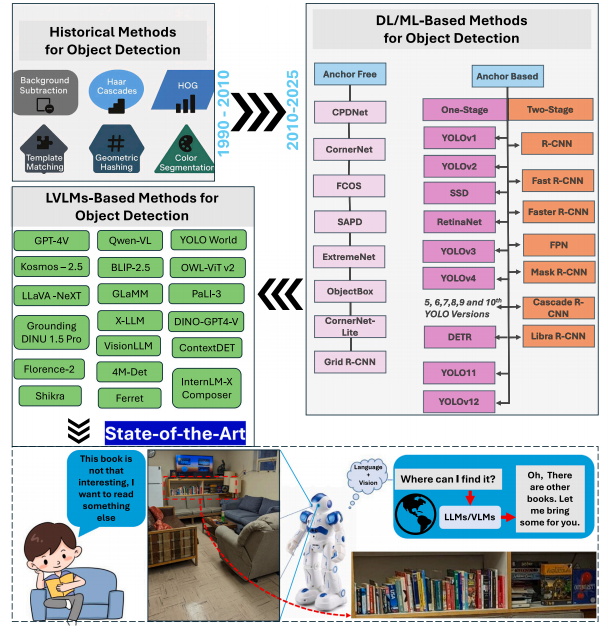
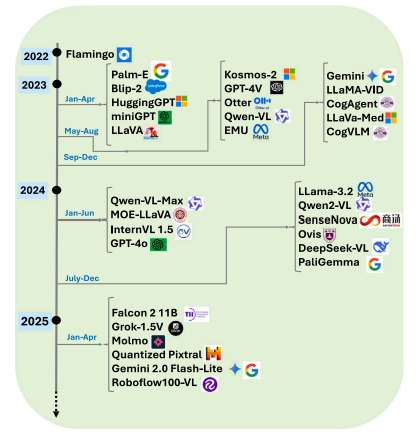
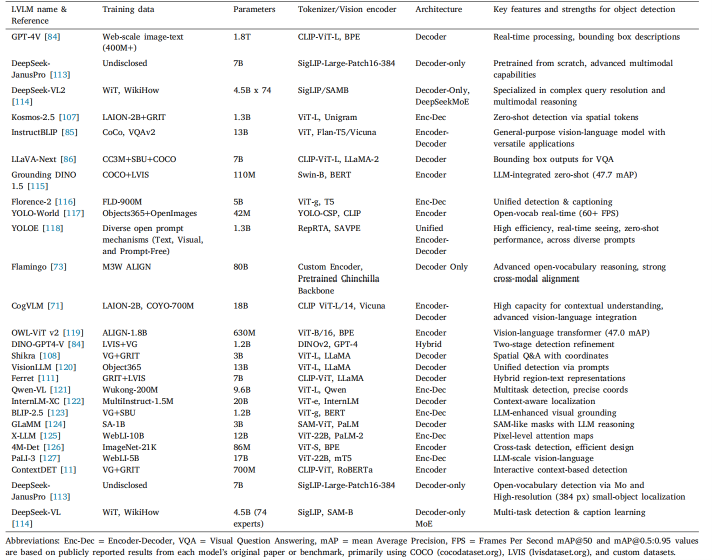
结论:目标检测长期以来一直是计算机视觉领域的核心任务,传统的支持向量机(SVM)和手工特征提取方法已逐渐被YOLO、Mask R-CNN、Faster R-CNN以及检测变换器(DETRs)等深度学习架构所取代。这些模型在多个领域的实时定位与分类任务中均展现出卓越性能。然而,近期出现的语言视觉模型(LVLMs)通过将自然语言理解与视觉感知相结合,开创了全新的研究范式,实现了更具上下文感知性、可泛化性且语义丰富的目标检测能力。在这篇首篇关于该主题的综述文章中,我们系统评估了当前最前沿的研究进展,并深入剖析了多模态语言视觉模型在目标检测方面的架构创新。本研究不仅重点阐述了语言视觉模型的关键架构改进与方法论,还与YOLO、Faster R-CNN等传统模型进行了全面对比。研究发现:虽然语言视觉模型在上下文理解与多模态交互方面表现优异,但传统框架对于需要在边缘设备上实现高速、高精度实时处理的应用场景仍具有重要价值。因此,我们的分析充分证明了语言视觉模型与传统目标检测系统之间的互补性。自然语言处理(NLP)与计算机视觉在低维语言模型(LVLM)中的融合,为提升场景理解能力及自动化标注等初步任务开辟了新途径;与此同时,专用计算机视觉模型仍持续承担精确的实时定位任务。本文探讨了多模态低维语言模型的基本运作机制及其演进历程。相关技术正通过直观的语言驱动界面融合发展,以推动视觉任务的进步,并详细阐述了这些系统固有的挑战与局限性。展望未来,大语言模型(LVLM)与传统深度学习模型很可能共存发展,彼此互补、强化各自的核心优势。这种融合有望提升目标检测系统的性能,使其在各种应用场景中更具适应性、高效性和易用性。我们的分析揭示了若干主要挑战,包括高昂的计算成本、对输入提示的依赖性、噪声伪标签以及预训练阶段与检测阶段之间的领域差异。为解决这些问题,我们提出了包含区域感知预训练、模型压缩、强化学习及改进型多模态融合等解决方案。我们认为本综述可作为基础性文献,深入剖析基于 LVLM 的目标检测现状,并为这一快速发展的自动化与机器人领域未来的创新奠定基础——该领域亟需将上下文推理与空间精度实现有机结合。
关于人工智能写作辅助技术的声明
我们使用ChatGPT和Perplexity来提升语法准确性并优化句子结构;所有由AI生成的修订内容均经过全面审查并根据相关性进行编辑。此外,还采用ChatGPT-4o生成逼真的可视化效果。

















&spm=1001.2101.3001.5002&articleId=162155463&d=1&t=3&u=4ffc6ded4b494ffeb55eca8dadb6adbf)
 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










