




深扒 K8s 有状态应用的“存储之痛”:Longhorn + MySQL StatefulSet 生产级落地方案
把 MySQL 放进 Kubernetes,从来不是“写个 StatefulSet 就完事”的问题。真正的难点不在容器,而在存储、一致性、故障恢复、主从拓扑、调度约束、备份恢复以及高并发场景下的性能边界。
本文不讲“跑起来”的 Demo,而是从架构原理、工程化落地、生产级 YAML、压测调优、故障演练和演进路线六个维度,系统拆解 Longhorn + MySQL StatefulSet 的可落地方案。
1. 为什么 K8s 上的有状态应用总是“最后一公里最难”
对于无状态服务,Kubernetes 的心智模型非常统一:
- Pod 挂了可以重建
- 实例扩了可以负载均衡
- 节点故障可以自动漂移
- Deployment 可以声明式升级和回滚
但数据库、消息队列、搜索引擎这类有状态应用完全不同。它们关心的不是“实例还在不在”,而是下面这些问题:
- 数据写到哪里了
- 写入是不是已经持久化
- 节点故障后数据是否还能挂载回来
- 重建出来的 Pod 还是不是原来的身份
- 主从关系、日志位点、快照备份是否一致
- 存储延迟抖动是否会直接放大成业务 RT 抖动
这也是很多团队第一次把 MySQL 搬到 K8s 时最容易踩的坑:
- 只关心
StatefulSet,忽略底层持久化卷的故障模型 - 只验证了“Pod 删除后数据还在”,没有验证“节点故障 + 卷重建 + 主从恢复”
- 只考虑了正常路径,没有考虑卷降级、网络抖动、磁盘写满、副本重建风暴
- 误把“存储高可用”当成“数据库高可用”
一句话概括:
Kubernetes 解决的是实例编排问题,Longhorn 解决的是卷高可用问题,而 MySQL 主从、高并发写入、一致性保障,仍然需要数据库层面的工程设计。
2. 先说结论:Longhorn + StatefulSet 适合什么,不适合什么
在进入细节之前,先把适用边界讲清楚。
2.1 这套方案适合的场景
- 中小规模生产环境,已经全面容器化,希望统一交付和运维入口
- 业务对 RPO/RTO 有要求,但尚未复杂到必须引入数据库 Operator
- 需要节点故障后卷自动漂移、快照备份、增量恢复能力
- 团队更熟悉 K8s/Helm,而不是传统物理机或虚拟机运维
- 希望把 MySQL 和应用、监控、备份一起纳入 GitOps 或平台化体系
2.2 这套方案不适合的场景
- 极致低延迟写入场景,对单次事务写延迟极其敏感
- 超大规模 OLTP 主库,持续高 IOPS、fsync 压力巨大
- 要求自动故障切主、自动重建拓扑、自动备份编排、自动 PITR
- 跨机房/跨地域容灾已经是刚需
2.3 一个很重要的认知边界
Longhorn 提供的是:
- 卷副本冗余
- 卷挂载与重建
- 快照与备份
- 节点故障后的卷恢复能力
Longhorn 不直接提供:
- MySQL 主从自动选主
- 复制拓扑自动修复
- 数据库连接串切换
- SQL 级别的一致性修复
所以本文的定位非常明确:
用 Longhorn 保证卷的韧性,用 StatefulSet 保证实例身份稳定,用 MySQL GTID 复制保障主从链路,用备份与恢复策略补齐灾备闭环。
3. 真实业务背景:为什么订单系统最容易暴露“存储之痛”
假设我们正在支撑一个典型电商订单域:
- Nginx Ingress 承接公网流量
- Spring Boot 订单服务横向扩到 20 到 50 个 Pod
- Redis 承担热点缓存和幂等控制
- Kafka 承担异步削峰、订单事件分发
- MySQL 承担订单主数据、事务扣减、支付状态流转
这类系统的数据库特点很典型:
- 写多读也不少
- 事务多、索引多、随机 I/O 多
- 延迟抖动会直接反映到下单 RT
- 容忍不了长时间不可用
- 出问题时排障窗口很小
最常见的传统问题通常是:
- 单机磁盘性能或容量达到天花板。
- 主机宕机后人工恢复时间过长。
- 备份存在,但恢复流程不稳定。
- 应用已经容器化,数据库仍然是“机房孤岛”。
- 测试环境和生产环境交付模式割裂。
这就是 Longhorn + StatefulSet 的切入点:
把数据库纳入统一平台交付,同时保留足够的稳定性和恢复能力。
4. 整体架构:不是“把 MySQL 放上去”,而是搭一条完整的数据链路
4.1 目标架构
本文采用如下生产基线:
- Kubernetes 多节点集群
- Longhorn 提供分布式块存储
- MySQL 8.0 单主双从
- GTID 复制
- StatefulSet 提供稳定网络身份和独立 PVC
- 主从分别通过读写 Service、只读 Service 暴露
- 通过备份任务把快照或逻辑备份落到对象存储
- 结合 PDB、反亲和、拓扑分散、探针、资源配额保障稳定性
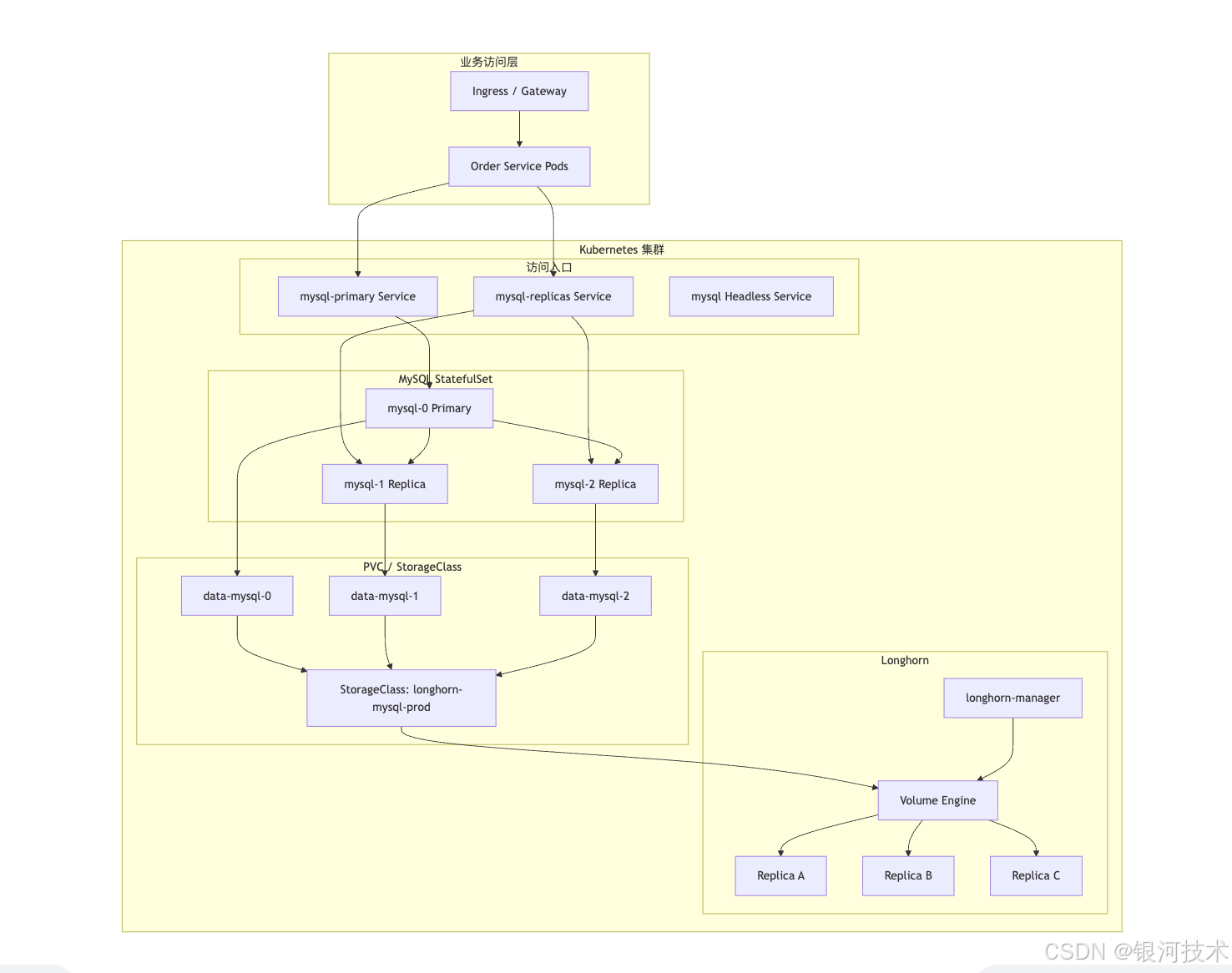
4.2 设计原则
这套方案遵循 6 个原则:
- 实例身份稳定:每个 MySQL Pod 必须具备稳定主机名和独立卷。
- 存储与调度协同:卷的创建位置、Pod 的调度位置、Longhorn 副本位置要配合设计。
- 数据库和存储分层容灾:Longhorn 保卷,MySQL 保主从与一致性。
- 默认考虑节点故障:不是“会不会坏”,而是“坏了后如何恢复”。
- 默认考虑高并发:从参数、IO 路径、连接数、资源隔离上预留容量。
- 默认考虑可演进:今天用 StatefulSet,明天可以平滑升级到 Operator。
5. Longhorn 到底解决了什么问题
很多文章只会说“Longhorn 是云原生分布式存储”,但这句话对排障没有帮助。生产环境真正需要理解的是它的架构、I/O 路径和故障行为。
5.1 Longhorn 的核心组件
Longhorn 的关键组件可以分成四层:
- API / 控制层
- Longhorn Manager 运行在每个节点,负责监听 CRD、卷调度、副本管理、快照/备份编排。
- CSI 接入层
- Kubernetes 通过 CSI 调用 Longhorn 完成卷创建、挂载、扩容、卸载。
- 数据平面
- 每个卷对应一个 Engine,负责处理 I/O,并把写入同步分发给多个 Replica。
- 副本层
- Replica 以文件形式落盘到宿主机磁盘目录,由 Longhorn 维护卷块数据和快照链。
5.2 “一卷一引擎”的意义
Longhorn 最有辨识度的设计就是:
每一个卷都有独立的 Engine 和 Replica 进程。
这意味着:
- 某个卷异常,不会拖垮整套存储服务
- 每个卷都能独立重建、独立快照、独立迁移
- 性能隔离和故障隔离都比“大一统存储进程”更清晰
但它的代价也很明确:
- 小卷很多时,控制面对象数量会增加
- 卷越多、快照链越长,后台维护成本越高
- 高并发随机写场景下,多副本同步复制会带来额外网络和 fsync 开销
5.3 Longhorn 的写入路径
对于挂载到 MySQL Pod 的一个 RWO 卷,简化后的写路径如下:
- MySQL 进程发起页写、redo log 写、binlog 写。
- 容器内文件系统把写请求提交到挂载的块设备。
- 块设备实际上由 Longhorn CSI 挂载出来。
- Engine 收到写请求后,同步转发给所有健康副本。
- 所有副本确认后,Engine 再向上层返回成功。
这条链路意味着:
- 一次数据库写入,并不是本地磁盘单次落盘那么简单
- 事务提交延迟会受网络抖动、节点负载、磁盘性能、卷副本健康状态影响
innodb_flush_log_at_trx_commit、sync_binlog、Longhorn 副本数之间存在明显耦合
5.4 为什么 Longhorn 能扛节点故障
因为卷数据不是只放在一个节点上,而是多个副本分散在不同节点磁盘上。
当某个节点宕机时:
- 原 Pod 消失
- StatefulSet 会重建 Pod
- Longhorn 会选择健康副本重新组装卷
- 卷重新 attach 到新的 Pod 所在节点
- MySQL 用原有数据目录启动
注意,这里恢复的是“卷级可用性”,不是“数据库角色自动切换”。
如果宕掉的是主库 mysql-0,Pod 虽然能拉起来,但应用侧是否需要摘流、主从是否延迟、只读库是否顶上,仍要看你的数据库治理能力。
5.5 Longhorn 的关键优势与代价
优势:
- 部署简单,适合 K8s 原生团队
- 卷快照、备份、恢复能力完整
- UI 和 CRD 可视化、可编排
- 相比 Ceph,运维复杂度更低
代价:
- 高写入延迟通常高于本地盘
- 高 IOPS 场景要谨慎评估
- 卷重建时会消耗网络和磁盘带宽
- 如果副本数、磁盘空间、节点拓扑配置不当,会出现反复降级重建
6. Kubernetes 中 MySQL 的真正难点,不是 StatefulSet,而是“身份 + 数据 + 拓扑”
6.1 StatefulSet 能解决什么
StatefulSet 能提供三件事:
- 稳定的 Pod 名称,例如
mysql-0、mysql-1 - 稳定的网络标识,通过 Headless Service 形成稳定域名
- 为每个 Pod 创建独立 PVC
这三点刚好适合数据库:
- 主从复制需要可预测的实例身份
- 每个实例必须有自己的数据目录
- 数据和 Pod 之间不能像 Deployment 那样随意互换
6.2 StatefulSet 不能解决什么
它不能自动帮你:
- 选主
- 切主
- 修复复制拓扑
- 管理备份
- 做 PITR
- 做连接串漂移
所以正确理解是:
StatefulSet 是数据库运行时外壳,不是数据库治理平台。
6.3 为什么很多“StatefulSet + MySQL 示例”不能直接上生产
常见演示版问题:
- 所有 Pod 用同一份配置,没有区分主从角色
- 把 root 密码明文写在 ConfigMap
- 没有 PDB、反亲和、资源边界
- 探针过于粗糙,启动慢时被误杀
- 没有考虑磁盘目录初始化问题
- 没有 GTID,主从切换复杂
- 只给出 YAML,不给演练和恢复步骤
本文下面给出的实现,会尽量把这些坑补齐。
7. 生产方案选型:为什么这里选择“单主双从 + GTID + Longhorn 三副本”
7.1 数据库拓扑选择
我们采用:
mysql-0作为主库mysql-1、mysql-2作为从库- 应用写流量走
mysql-primary - 应用读流量走
mysql-replicas
原因很简单:
- 架构清晰,符合多数中型业务习惯
- 故障模型容易理解
- 成本可控
- 便于未来迁移到 Operator
7.2 复制方式选择
采用 MySQL 8 的 GTID 复制,而不是文件位点复制。
GTID 的优势:
- 主从重建更简单
- 角色切换时更容易自动对齐
- 减少维护 binlog file/position 的复杂度
7.3 存储副本数为什么默认 3
Longhorn 默认常见是 3 副本,这也是生产中最稳妥的平衡点:
- 1 副本:没有高可用意义
- 2 副本:容灾能力提升,但遇到故障时冗余不足
- 3 副本:能覆盖更多单点故障场景




















 1830
1830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










