




 本文深入探讨了概率论的应用,包括回归分析、多变量分析和随机过程,并详细讲解了信息论的基本原理,如信息量、信息熵及其在计算机科学中的应用。文章指出,信息的意外程度与信息量成正比,而信息熵则是衡量信息不确定性的重要指标。
本文深入探讨了概率论的应用,包括回归分析、多变量分析和随机过程,并详细讲解了信息论的基本原理,如信息量、信息熵及其在计算机科学中的应用。文章指出,信息的意外程度与信息量成正比,而信息熵则是衡量信息不确定性的重要指标。
概率论的各类应用
回归分析和多变量分析
随机过程
信息论
意外程度 = 信息量
意外程度越大,消息包含的信息量也越大。
为了用数学方式描述这一理论,我们需要设计出一种概率越低值反而越大的指标。可选的方案有很多,我们最终选的是以下的方案:
得知该消息时的意外程度 = log 1 概 率 \frac{1}{概率} 概率1
注意:① 这里的 log 都表示以2为底数
② log 具有以下的性质:
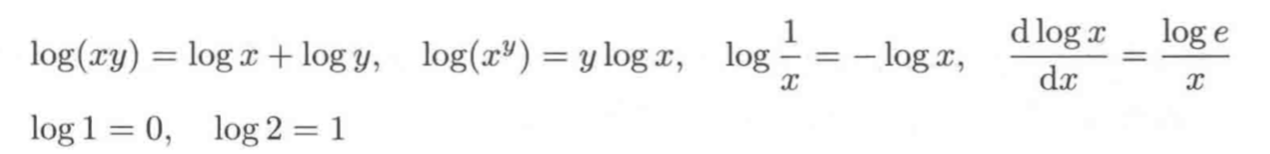
这种意外程度与计算机内存容量及通信量中使用的比特数概念关系密切。实际上,通过log2 定义的意外程度的单位正是比特(bit)。
信息熵
对于一个事件 Y ,其意外程度的期望为:
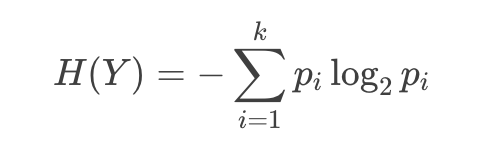
其中,i=1,2,…k 为事件 Y 的k个可能结果;pi 为每个结果发生的概率。
小结
可以看出,我们对于 log(
1
p
\frac{1}{p}
p1)可以有多种理解:
可以看做是信息的度量——信息量,也可以看做是意外程度的度量,还可以是不纯度得度量,其具体的值还可以看做是具体的比特(bit);而所有可能结果的集合事件,用期望计算的结果即是信息熵:
意外程度的期望 = 信息熵 = 信息的不确定性
参考:
- 《程序员的数学》
- 机器学习算法/模型——决策树

















:概率论的应用:随机过程、信息熵、图论&spm=1001.2101.3001.5002&articleId=104326096&d=1&t=3&u=6b846ccc82314320a94579ca161e4990)
 4093
4093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










