




本文是【训练LLM系列】的第一篇,主要重点介绍NanoGPT代码以及中文、英文预训练实践。最新版参见我的知乎:https://zhuanlan.zhihu.com/p/716442447
除跑通原始NanoGPT代码之外,分别使用了《红楼梦》、四大名著和几十本热门网络小说,进行了字符级、自行训练tokenizer以及使用Qwen2的Tokenizer的中文GPT训练尝试,并展示了续写的效果。
可供快速预训练中文GPT使用。
第二篇会通过debug分析的方式来学习NanoGPT。后续还会介绍一些开源小LLM训练项目,也是实践+代码分析的思路。
码字不易,转载请注明出处:LeonYi
0、前言
当下开源效果每过一段时间就越来越好,大模型已被头部大厂垄断,绝大多数人都不会有训练LLM的需要
大部分场景是偏应用工作中因向业务效果看齐,更多时间会花在提示词优化、数据+各种任务LoRA微调,连领域微调或全参微调的时间都越来越少或没有。
学习小LLM训练的目的,是为了掌握原理,也可以为训练自己的LLM提供指导经验:
-
项目积累的是实战落地经验,但深入LLM训练原理也很重要,这可以为设计更可行和靠谱的方案提供支撑。实战和原理互为补充。
-
就算跑过小模型预训练和增量预训练开源LLM,还是差点什么。原因在于没有深入到具体的训练过程、吃透原理。
预训练过程属于整数据和启动脚本,调参空间实在有限。只能算跑通
-
目前进展日新月异,ToDoList越来越多,与其更多的时间精力跟踪前沿,不如花时间吃透基础。模型算法千变万化但不离其宗,掌握基础可以不变应万变。
稳定且能够迁移的一些基本原理: 基础模型算法、分词器、优化器、Pytorch底层原理、算法涉及的统计、矩阵、微积分等数学、高性能计算和计算机系统原理。
使用开源的LLM有时像黑盒,但自己掌握原理实践训练出小的LLM,大模型的黑盒就被解开了。
尤其是,准备数据SFT自己训练好的Base模型,在回答问题时,是一种非常特殊的感觉。
总之,最近对小规模LLM训练实践了一番。学习的思路: 先跑项目,再学习代码,然后改动实践。
1、NanoGPT介绍
NanoGPT是karpathy在23年开源的复现GPT2规模LLM的项目:https://github.com/karpathy/nanoGPT。
项目无特别依赖,给定语料本地笔记本即可快速训练自己的小规模的因果语言模型。
1.1 项目解析
项目主要代码:
-
data
- 存放原始数据,以及预处理Tokenize的数据
- 预处理Tokenize代码(支持非常简单的字符级分词,和tiktoken的GPT2分词)。
- 预处理代码的逻辑:划分训练和验证数据,然后分词后,保存为numpy的int格式,持久化为bin文件,用于在训练时基于numpy的memmap分batch读取硬盘上的大的tokenized文件,供mini-batch的训练。
这里非常容易就可以用Transformers的tokenizers训练一个自己的分词器或直接用Qwen2等现有tokenizer
-
config
- 存放训练和微调gpt2,以及评估open gpt2的代码
这里可以自定义模型配置,以及训练的超参数
- 存放训练和微调gpt2,以及评估open gpt2的代码
-
model.py
- 实现了GPT
-
train.py
- GPT训练代码。支持PyTorch Distributed Data Parallel (DDP)的进行单机多卡和多机多卡分布式训练。
-
sample.py
- GPT推理
特性:
- 特别适合在Pycharm上debug每一步训练过程,深入理解TransformerDecoder的训练步骤。
- 适合对代码进行魔改(直接把model.py换成modeling_qwen.py,或一步步修改model.py的GPT模型结构)
接下来,对代码做个简要介绍。
实际上GPT模型结构的代码,和之前我的一篇numpy实现GPT文章:https://zhuanlan.zhihu.com/p/679330102 非常类似,只不过从numpy迁移到torch.
1.2 NanoGPT的模型代码实现
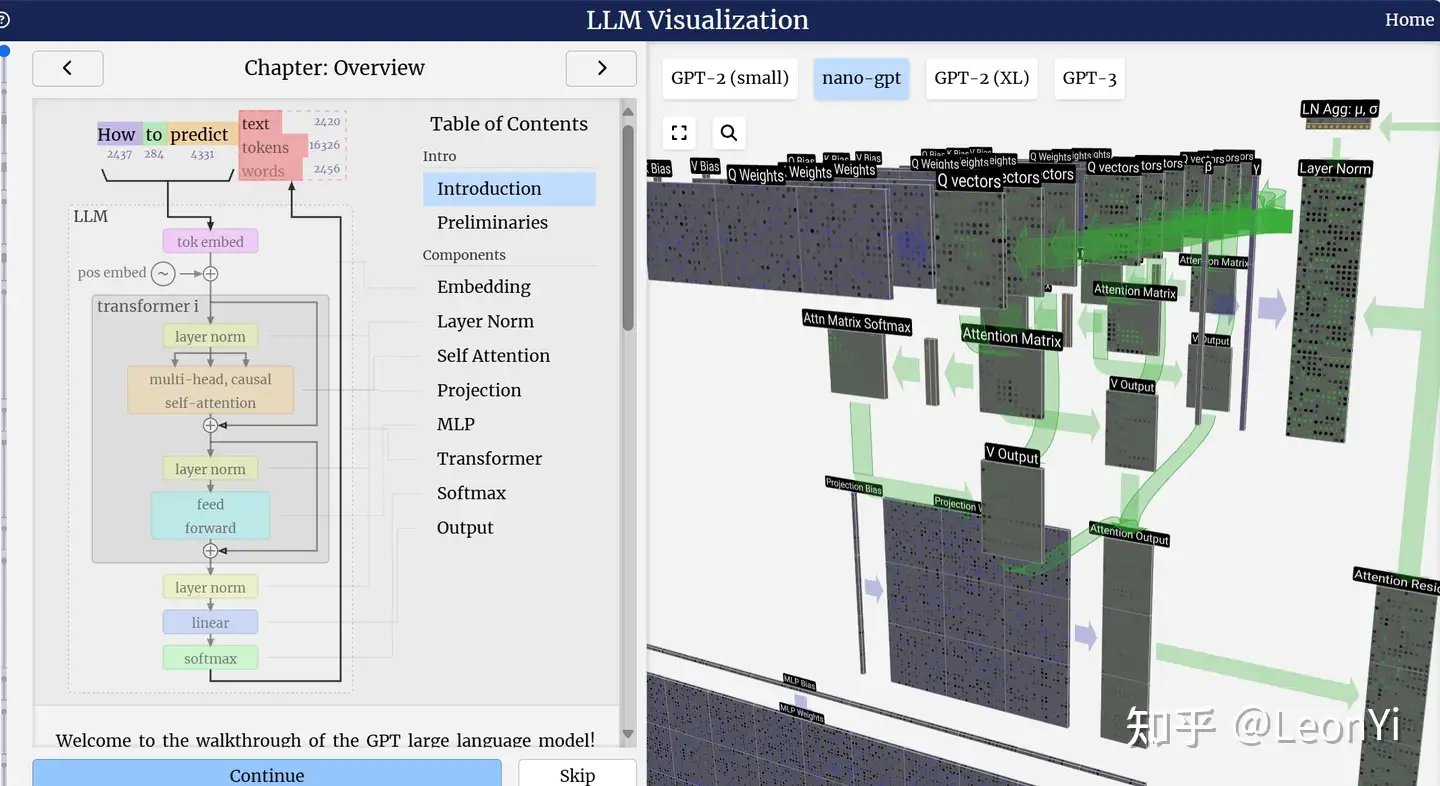
LLM-visualization项目: https://bbycroft.net/llm
可同时结合LLM-visualization和Pycharm Debug NanoGPT的代码,效果最佳。
GPT核心是CausalSelfAttention+LayerNorm+MLP构成的TransformerDecoder, 即下面代码中的Block。
import math
import inspect
from dataclasses import dataclass
import torch
import torch.nn as nn
from torch.nn import functional as F
class LayerNorm(nn.Module):
""" LayerNorm but with an optional bias. PyTorch doesn't support simply bias=False """
def __init__(self, ndim, bias):
super().__init__()
self.weight = nn.Parameter(torch.ones(ndim))
self.bias = nn.Parameter(torch.zeros(ndim)) if bias else None
def forward(self, input):
return F.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)
class MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd, bias=config.bias)
self.gelu = nn.GELU()
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd, bias=config.bias)
self.dropout = nn.Dropout(config.dropout)
def forward(self, x):
x = self.c_fc(x) # 升维变化, (B, T, C) -> (B, T, 4*C)
x = self.gelu(x)
x = self.c_proj(x)
x = self.dropout(x)
return x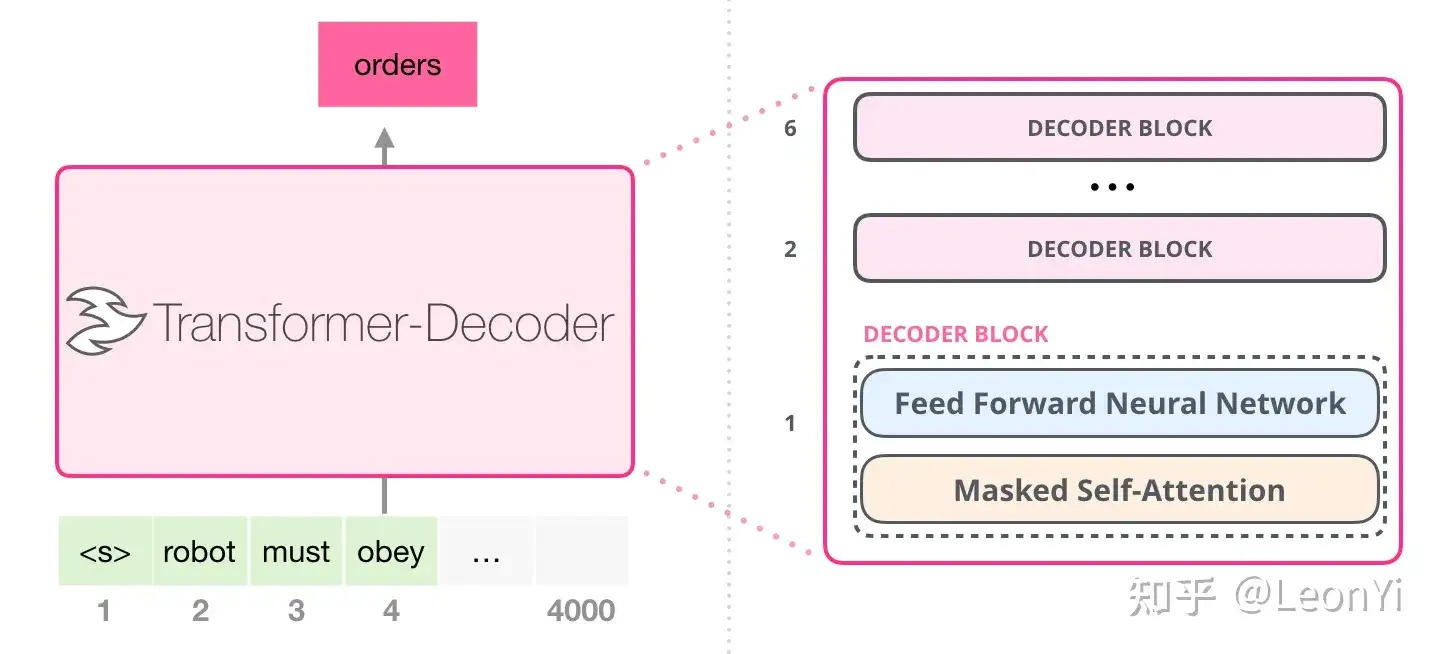
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
assert config.n_embd % config.n_head == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)
# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
# regularization
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.dropout = config.dropout
# flash attention make GPU go brrrrr but support is only in PyTorch >= 2.0
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention')
if not self.flash:
print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, sel



















 7183
7183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










