




微软PIKE-RAG:多层次多粒度体系化智能化知识库构建方案
笔者注:PIKE-RAG是微软亚洲研究院的一个知识库设计和构建工作,高度体系化,里面拆解问题、单点能力设计、整体流程设计等各方面都有比较大的借鉴价值,因而写这篇文章记录一下
作者认为传统的RAG大致有3个方面的问题:
- 多样化的数据源(Knowledge source diversity):因而也需要知识库具备存储多样化数据(即多模态)和推理的能力
- 特定领域泛化缺陷(Domain specialization deficit):知识库对问题的关键部分会给出不准确或者不完整的知识,导致最终回复效果违反基本原理
- 架构同质化(One-size-fits-all):通过同一套技术框架解决不同类型问题,但RAG的真实场景下需要多样化的能力,特别是提取、理解、组织领域知识和基本原理的能力
笔者注:原文中的rationale本意指的是“基本原理”、“根本原因”的意思,论文的上下文中,知识库可以提供召回的原因其实意味着它在通过推理选出要找回的内容,推理过程文本构成了rationale。
故而研究团队提出了specialized Knowledge and Rationale Augmented Generation (PIKE-RAG),名字略显复杂,意思是知识进行特殊处理且增强了基本原理的生成模式。
问题分类定义
作者梳理了影响RAG任务的关键因素(笔者表示完全赞同):
- 知识的相关性和完整性(Relevance and Completeness of Knowledge)
- 知识提取的复杂度(Complexity of Knowledge Extraction)
- 理解和推理的深度(Depth of Understanding and Reasoning)
- 知识蒸馏的有效性(Effectiveness of Knowledge Utilization)
笔者注:如果知识蒸馏让比较难理解的话,可以等价替换为知识总结,意思大致相同。
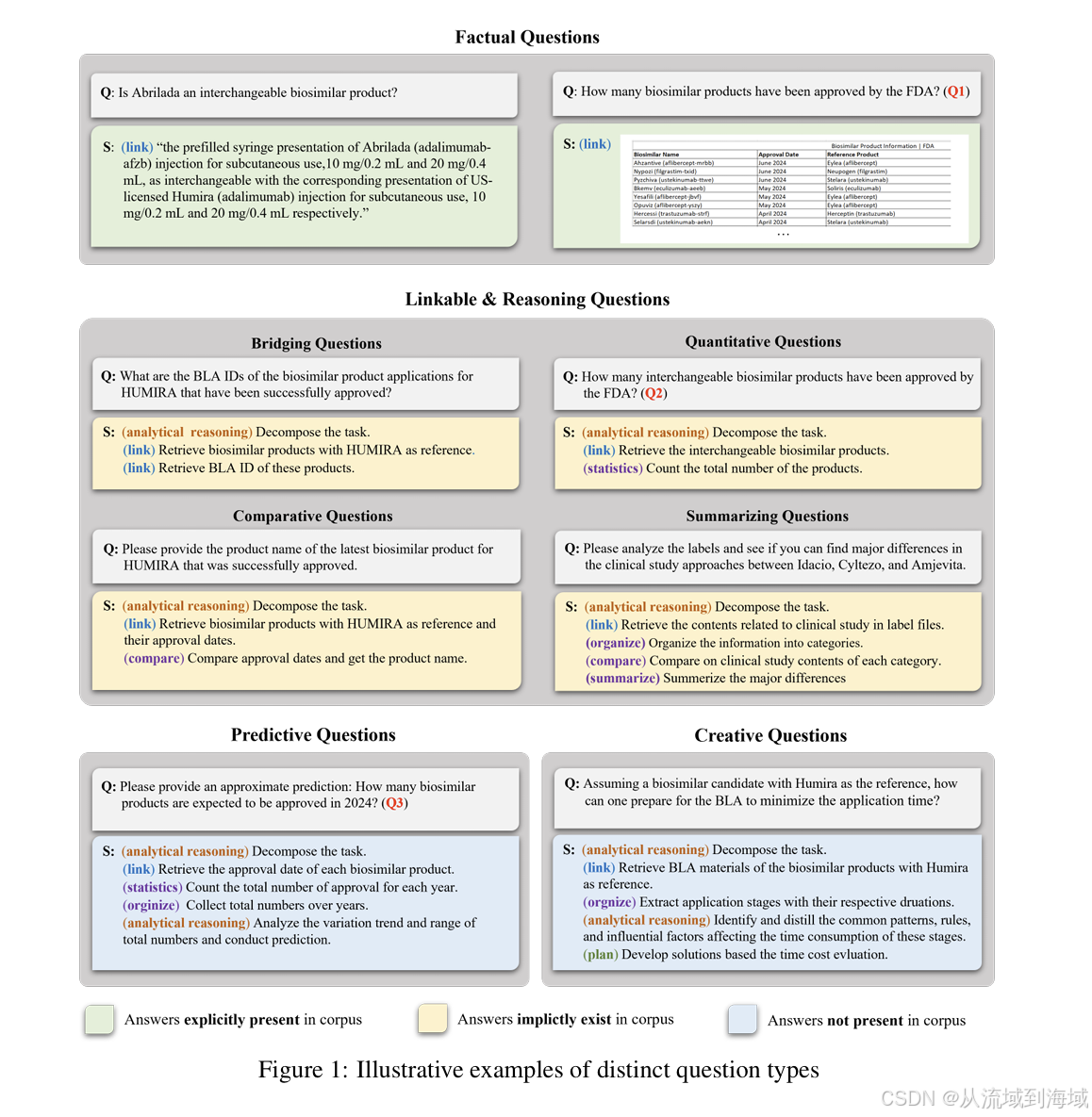
如上图,研究团队首先将RAG预期要解决的问题分为以下4类,其中联系与推理问题还可以继续向下细分:
- 事实问题(Factual Questions)
- 联系与推理问题(Linkable-Reasoning Questions)
- 关联性问题(Bridging Questions)
- 定量问题(Quantitative Questions)
- 比较问题 (Comparative Questions)
- 总结问题(Summarizing Questions)
- 预测性问题(Predictive Questions)
- 创造性问题(Creative Questions)
四类问题中,事实问题在知识库语料显式存在答案;联系与推理问题在语料库中隐式存在答案,需要将检索到的显式知识关联一下才能得出答案;预测




















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










