



知识:
流处理计算:流数据经过有向无环图DAG处理
A stream graph is comprised of operators, which conduct computation on the incoming tuples, and directed edges, each of which connects two operators and transmits tuples between them.
Tuples are structured data items with strongly-typed attributes. Operators are event-driven and execute only when there is a tuple received. Figure 1 shows an example of a stream graph.
流处理图由运算符operators,之间的有向边构成
运算符operators:对传入的元组tuple进行计算,只有收到元组tuple的时候才会执行
有向边:连接运算符operators,传输tuple
tuples:是强类型属性的数据结构
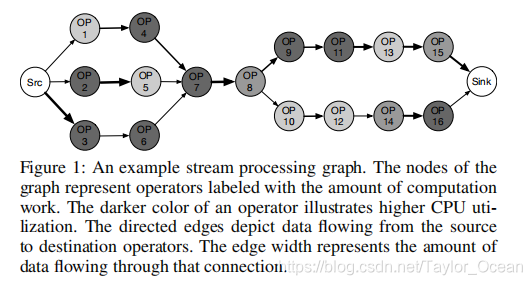
上图:节点代表有计算任务的运算符。
运算符颜色越深代表CPU利用率越高
有向边:源运算符到目的运算符的数据流。
边的粗度代表之间流经的数据量的大小。
如果通信的运算符处在同一个worker node计算机器上,可以用简单的函数调用进行通信。
如果通信的运算符不处在同一个worker node计算机器上,通过网络进行通信。函数调度比网络通信更有效。
问题:
流处理中的资源分配问题。
为了将流处理图的计算任务分配到计算设备(由CPU或者GPU执行)上。
目标:为了最大限度提高吞吐量(每秒处理的元组tuple数),资源分配同时平衡平均分配计算任务这种工作负载和最小化通信成本。
运算符分配到资源上可以分为两步图划分问题:
1.确定正确的分区k数
2.然后执行k路划分,将运算符划分为k个子集
(寻找最优图划分)图分割问题是NP-完全问题。
本文:
we present a graph-aware encoderdecoder framework to learn a generalizable resource allocation strategy that can properly distribute computation tasks of stream processing graphs unobserved from training data.
We, for the first time, propose to leverage graph embedding to learn the structural information of the stream processing graphs. Jointly trained with the graph-aware decoder using deep reinforcement learning, our approach can effectively find optimized solutions for unseen graphs.
我们提出一种图-感知编码器和解码器框架,实现通用资源分配策略,适当的分配流处理图中的计算任务。
我们首次提出利用图嵌入学习流处理图的结构信息,通过使用深度强化学习的图感知编码器和解码器联合训练,为未见过的图找到分配策略。
该策略可以智能的分割具有不同结构的流处理图,同时捕获流处理系统的性能相关因素。图感知编码器-解码器能够为各种图生成优化的解决方案。
1.DRL(深度强化学习DRL)作为图划分解决方案:使用DRL来训练了一个良好的图划分策略,可推广到不同的流处理图。
DRL需要将拓扑中的属性(整个图的全局信息,运算符在图中的位置、关键路径、运算符的CPU利用率和通信成本、设备分配预测之间的关系)捕获到状态表示中。
2.具有图感知状态表示的可推广模型:一个好的图分区策略应该可以推广到不同的输入图结构。
问题定义:

本文特定针对同构的物理节点,不考虑异构集群。
预测分配图有难度,因为运算符分配到设备节点上,不仅要考虑拓扑结构,还和其他节点有关。所以需要对整个拓扑结构进行联合推断。
将联合推理问题表述为一个搜索问题,在每个步骤中将一个设备节点id附加到拓扑结构中的运算符上。
图编码器-解码器模型:
首先用图编码器对输入流图(拓扑图)进行编码
编码后的图用于一个图感知的解码器,以顺序的方式来产生资源设备worker node节点的分配
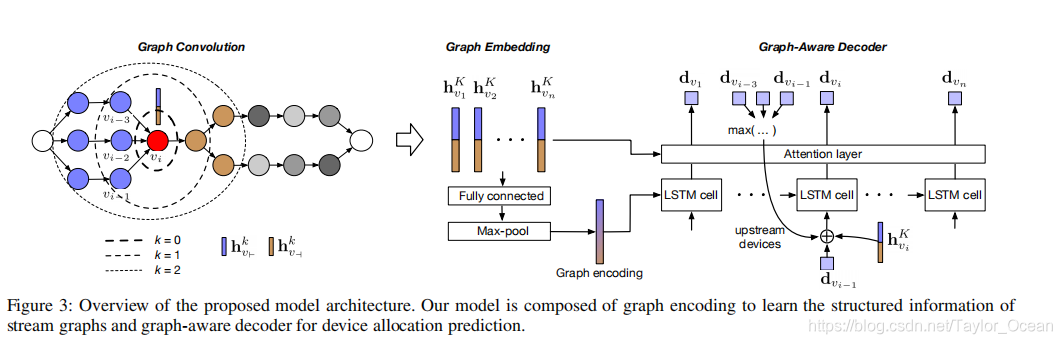
流图编码器
1.将图Gx嵌入到一个嵌入空间中,每个图中的节点都有一个嵌入的上下文信息。(使用图卷积网络GCN实现编码)
2.GCN使用邻居节点的嵌入迭代的更新该节点的嵌入:
在第k步中,对于每个运算符节点v,

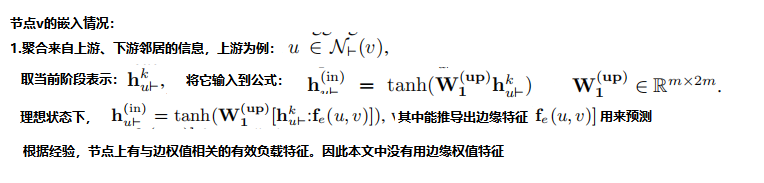



















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












