







作者:来自 Elastic Tyler Perkins
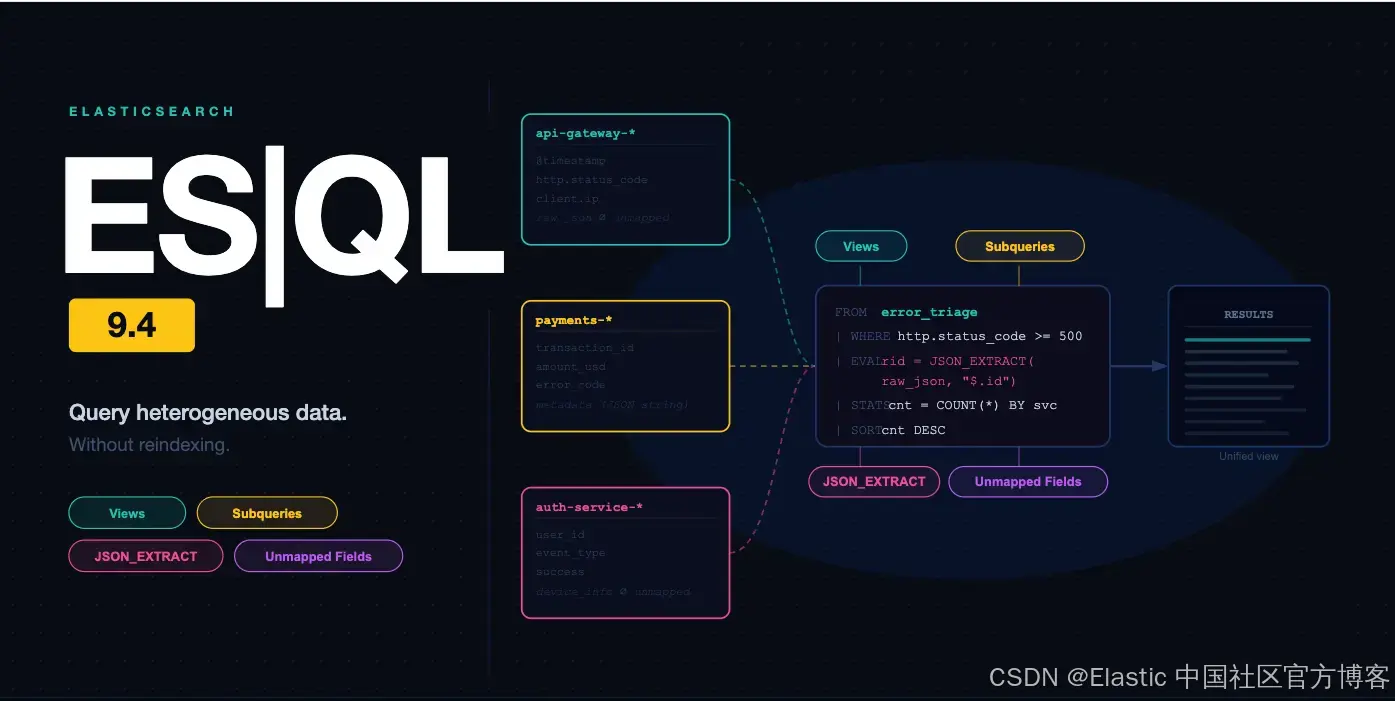
查询你从未映射过的字段,在一个管道中组合具有不同模式的索引,并将查询逻辑复用为命名视图。这是 ES|QL 迄今为止最重大的数据访问能力扩展。
亲自体验 Elasticsearch:深入了解我们在 Elasticsearch Labs 仓库 中提供的示例 notebooks,开始 免费云试用,或立即在你的 本地计算机 上体验 Elastic。
ES|QL 在本次发布中新增了三项能力,改变了你建模和查询数据的方式:逻辑 视图 允许你定义一次查询,并在任何 dashboard 或 alert 中通过名称引用;FROM 中的 子查询 允许你在单个管道中组合具有不兼容 schema 的索引;读取时模式定义(schema-on-read) 允许你查询那些从未映射过的字段,对已经索引的数据进行查询,而无需修改 mapping 或重新索引。
除此之外,本次发布还包括:timezone 支持正式发布;LIMIT BY 原生支持分组 Top-N;lookup join 通过复用 Lucene 数据结构获得更高性能。上述每一项重点功能都提供了对应的深度解析文章,可通过下方链接进一步了解。
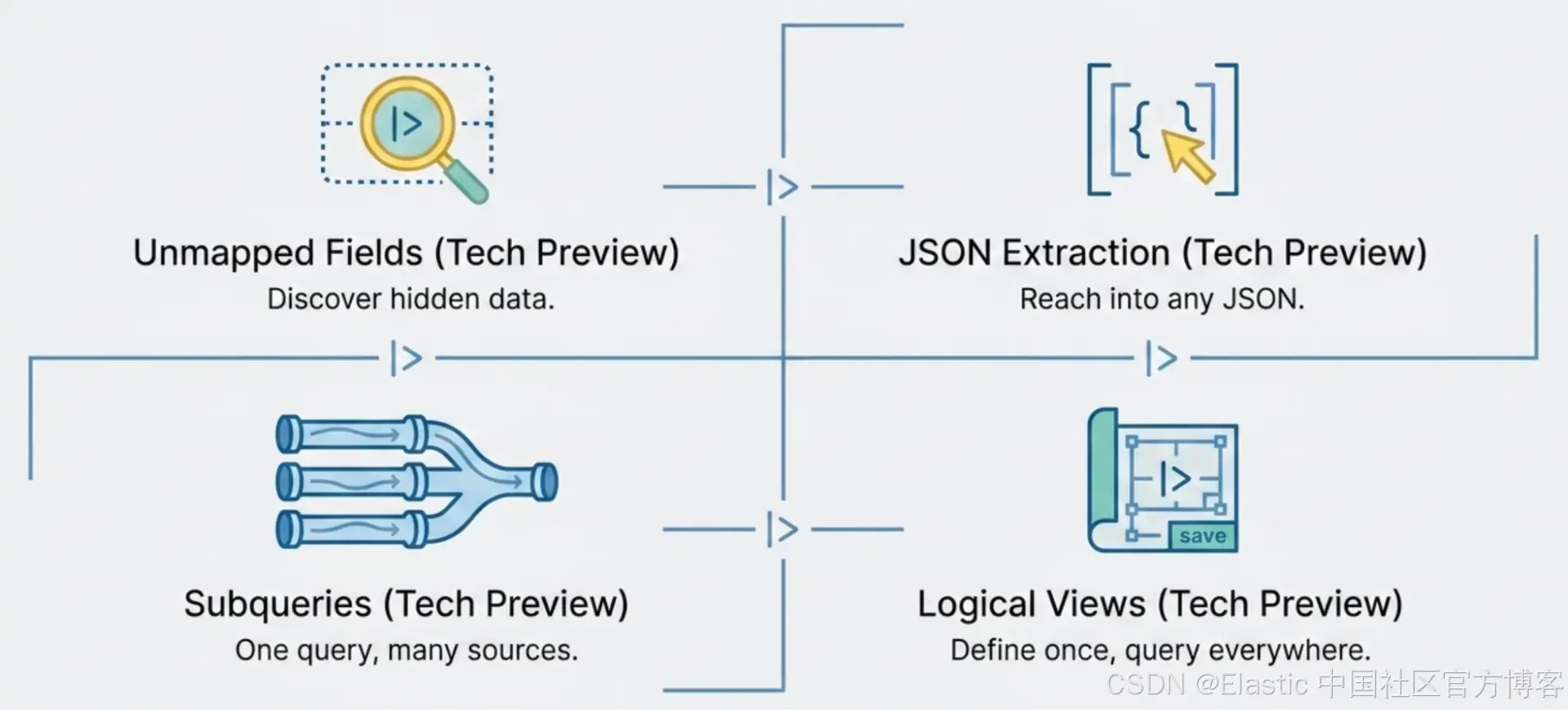
ES|QL 视图、子查询与 schema-on-read 如何组合
视图(views)、子查询(subqueries)以及 schema-on-read 被设计为可以分层组合使用。子查询让每个 index 拥有自己的 pipeline。视图则将这个子查询封装起来,使使用者只需通过一个名称来引用。schema-on-read 让这些 pipeline 可以访问那些在 mapping 中从未定义过的字段。最终结果是:一个 FROM view_name 查询即可组合多个 service,统一其 schema,并在 ingest 时未映射的字段也能被直接查询出来。后续章节会分别链接每个能力的深度解析。
逻辑视图(技术预览)
逻辑视图(Logical views) 是一种虚拟 index:它是存储在 Elasticsearch cluster 级别的查询定义,可以像真实 index 一样在任何 FROM 子句中通过名称引用。你可以通过 `_query/view` REST API 定义一次 view。所有使用该 view 的 dashboard、alert 和 ad-hoc query 都会自动应用最新的定义变更。
视图支持嵌套(nesting)、跨集群搜索,以及独立的 RBAC 权限控制。
PUT _query/view/error_triage
{
"query": """
FROM svc-gateway-*
| WHERE http.response.status_code >= 500
| KEEP @timestamp, http.response.status_code, url.path, source.ip
"""
}
FROM error_triage
| STATS error_count = COUNT(*) BY url.path
| SORT error_count DESC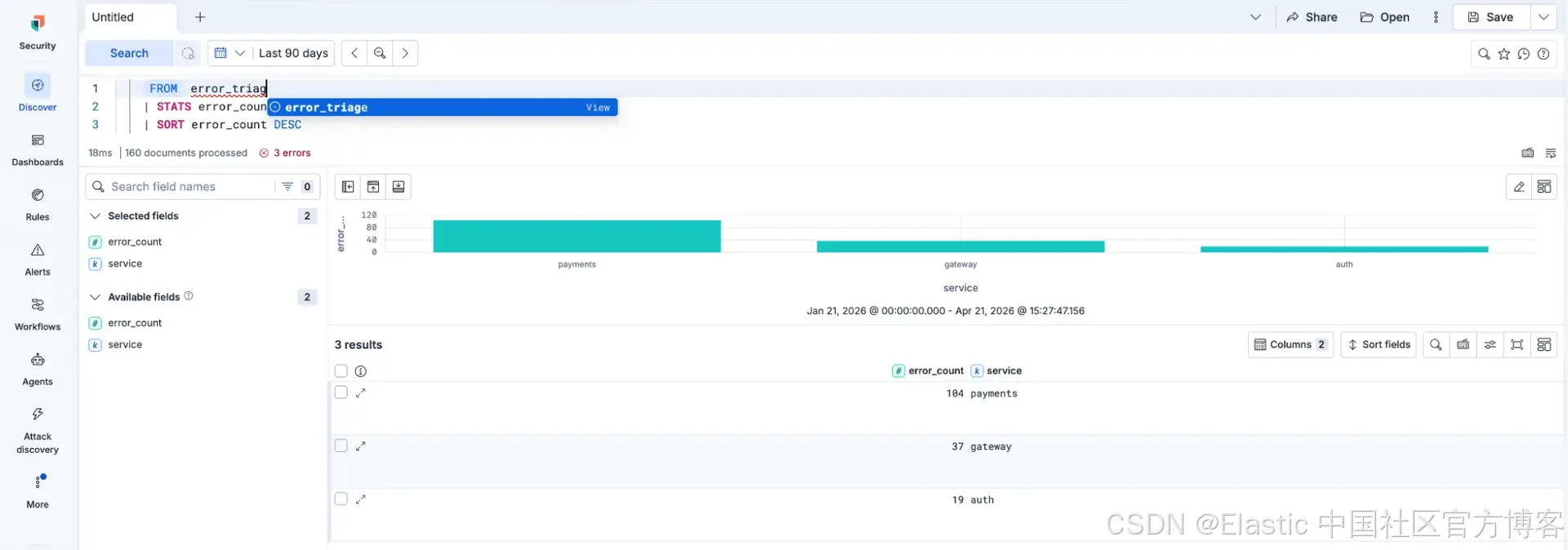
阅读完整深度解析:Elasticsearch ES|QL 视图:一个查询统领十二个仪表板
FROM 子句中的子查询(技术预览)
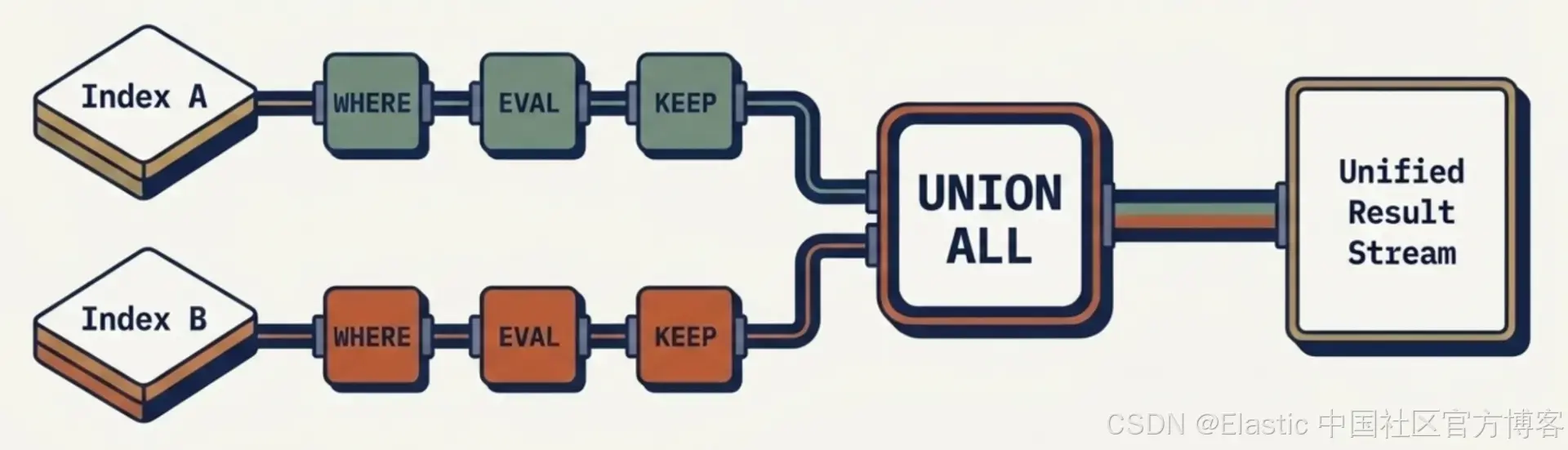
子查询 为你提供组合能力:在一个查询中合并来自多个索引的数据,即使这些索引具有不同的 schema。每个分支都有自己的 WHERE、EVAL、KEEP,优化器会将过滤条件分别下推到各自的 index 中执行。最终结果以 UNION ALL 语义进行合并。
FROM
(FROM svc-gateway-*
| WHERE http.response.status_code >= 500
| EVAL service = "gateway",
error_detail = CONCAT("HTTP ", http.response.status_code::string)
| KEEP @timestamp, service, error_detail, source.ip),
(FROM svc-payments-*
| WHERE transaction.status IN ("failed", "timeout")
| EVAL service = "payments",
error_detail = transaction.status
| KEEP @timestamp, service, error_detail, source.ip),
(FROM svc-auth-*
| WHERE event.action == "login" AND event.outcome == "failure"
| EVAL service = "auth",
error_detail = CONCAT(event.action, " ", event.outcome)
| KEEP @timestamp, service, error_detail, source.ip)
| SORT @timestamp DESC
| LIMIT 20阅读完整深度解析:三个索引走进一个 FROM 子句:Elasticsearch 中的 ES|QL 子查询
Schema-on-read:未映射字段 + JSON 提取(技术预览)
未映射字段访问 允许你查询那些从未在 mapping 中声明的字段,直接针对已写入 index 的数据进行查询,无需重新索引。SET unmapped_fields="load" 是一个战略级抽象:只需一行配置,就能让在 ingest 阶段遗漏的字段从 _source 中变为可查询字段。
JSON_EXTRACT 是更底层的工具,用于从原始 JSON 字符串或扁平化字段中进行精确提取。
SET unmapped_fields="load";
FROM otel-logs-*
| WHERE log.level IN ("error", "warn")
| STATS errors = COUNT(*), latest = MAX(@timestamp)
BY service.name, resource.cost_center
| SORT errors DESC
阅读完整深度解析:Elasticsearch ES|QL “schema on read”:你的未映射字段其实一直都在那里
时区支持(正式发布)
SET time_zone 现已正式发布,为所有 ES|QL 查询带来支持时区感知的日期/时间操作能力。你可以在 query 级别设置一次时区,之后所有 DATE_TRUNC、日期聚合以及时间戳输出都会自动反映本地时区,无需任何后处理。
它支持任意 IANA timezone 字符串。
SET time_zone="America/Los_Angeles";
FROM error_triage
| EVAL hour = DATE_TRUNC(1 hour, @timestamp)
| STATS errors = COUNT(*) BY hour, service
| SORT hour DESC输出的时间戳会包含时区偏移(例如 2026-04-09T11:00:00.000-07:00,而不是 ...T18:00:00.000Z)。没有按函数级别设置时区参数;SET time_zone 是唯一的机制。在 Kibana 中,ES|QL dashboard 面板和 Discover 查询现在可以直接基于本地营业时间生成时区感知结果,而无需任何后处理。
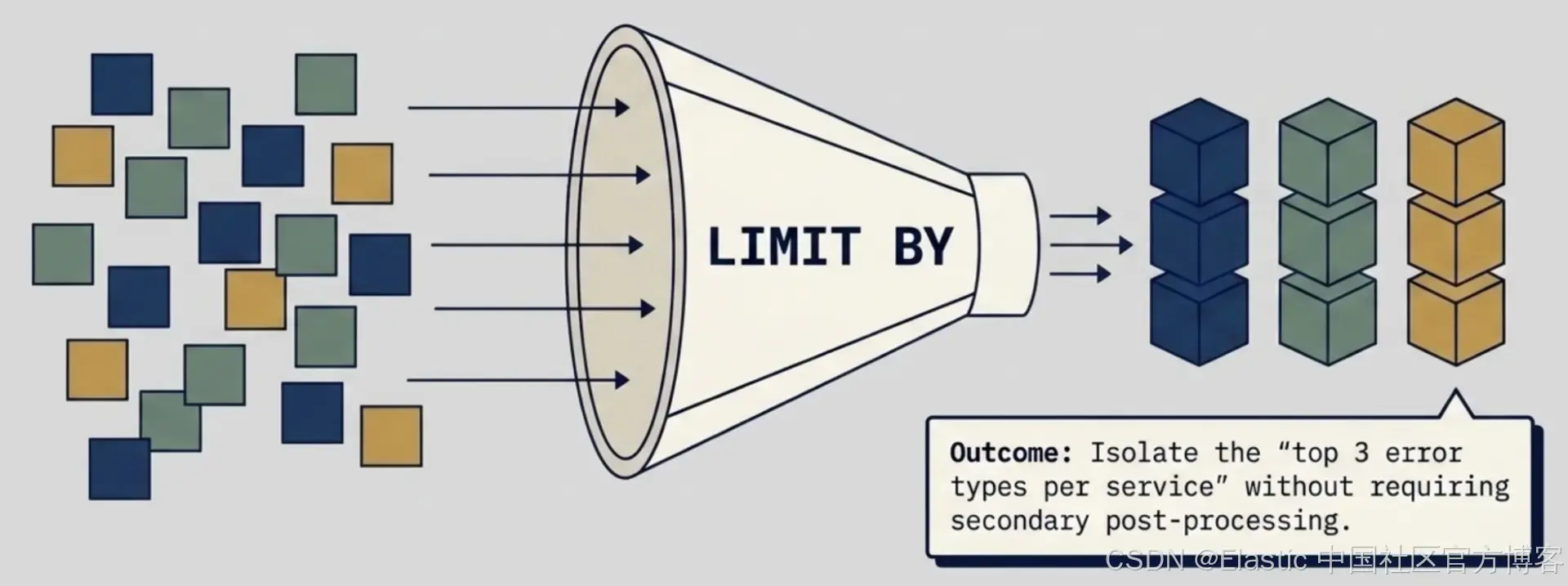
LIMIT BY:分组 Top-N(技术预览)
“每个 service 展示 top 3 error types” 这样的需求,过去需要后处理,因为 SORT 和 LIMIT 是全局生效的,只会返回整体 top N,而不是每个分组的 top N。LIMIT BY 以原生方式解决了这个问题:
FROM error_triage
| STATS cnt = COUNT(*) BY service, error_detail
| SORT cnt DESC
| LIMIT 3 BY service返回每个不同 service 值的前 3 行。数字写在 BY 之前。
ES|QL FIRST、LAST、EARLIEST 和 LATEST 聚合函数
FIRST、LAST、EARLIEST、LATEST(正式发布)返回与排序字段的最小值或最大值对应的值:
FROM svc-auth-*
| WHERE event.outcome == "failure"
| STATS first_seen = FIRST(@timestamp, @timestamp),
last_seen = LAST(@timestamp, @timestamp),
first_user = EARLIEST(user.name),
attempts = COUNT(*)
BY source.ip
| SORT attempts DESCFIRST 和 LAST 接收两个参数:value 字段和 sort 字段。EARLIEST 和 LATEST 是单参数别名,会隐式按照 @timestamp 排序,用于获取某个值在时间序列中首次或最后一次出现的结果。
ES|QL URI_PARTS、USER_AGENT 和 REGISTERED_DOMAIN 命令
URI_PARTS、USER_AGENT、REGISTERED_DOMAIN 是三个新的 pipe 命令,它们可以将单个字段展开为多个结构化输出列:
FROM svc-gateway-*
| WHERE http.response.status_code >= 400
| URI_PARTS parts = url.full
| STATS errors = COUNT(*) BY parts.domain, parts.path
| SORT errors DESC
FROM svc-auth-*
| USER_AGENT ua = user_agent.original
| STATS cnt = COUNT(*) BY ua.name, ua.version
The syntax is `| COMMAND target = source_field.
`URI_PARTS` produces `target.domain`, `target.path, target.scheme`, `target.port`, and more.
`USER_AGENT` produces `target.name`, `target.version`, `target.os.name`, etc.
`REGISTERED_DOMAIN` produces `target.registered_domain`, `target.top_level_domain`, and `target.subdomain`.ES|QL lookup join 优化与正式发布功能升级
多个功能升级为正式发布,同时 lookup join 性能得到提升。
-
VALUES(正式发布):返回分组内所有不同值,作为多值字段(multivalue field)。
-
MV_EXPAND(正式发布):将多值字段展开为多行。
-
FORK(正式发布):从同一输入创建并行执行分支,在 9.1 preview 后现已正式发布。
-
SPARKLINE(技术预览):在查询结果中内联生成 sparkline 迷你图。
-
MV_UNION、MV_DIFFERENCE、MV_INTERSECTS(技术预览):用于多值字段的集合运算。
-
_size metadata:通过
METADATA _size在FROM子句中访问文档大小信息。
Lookup join 优化
Lookup join(在 9.1 引入)获得了两项关键性能优化:
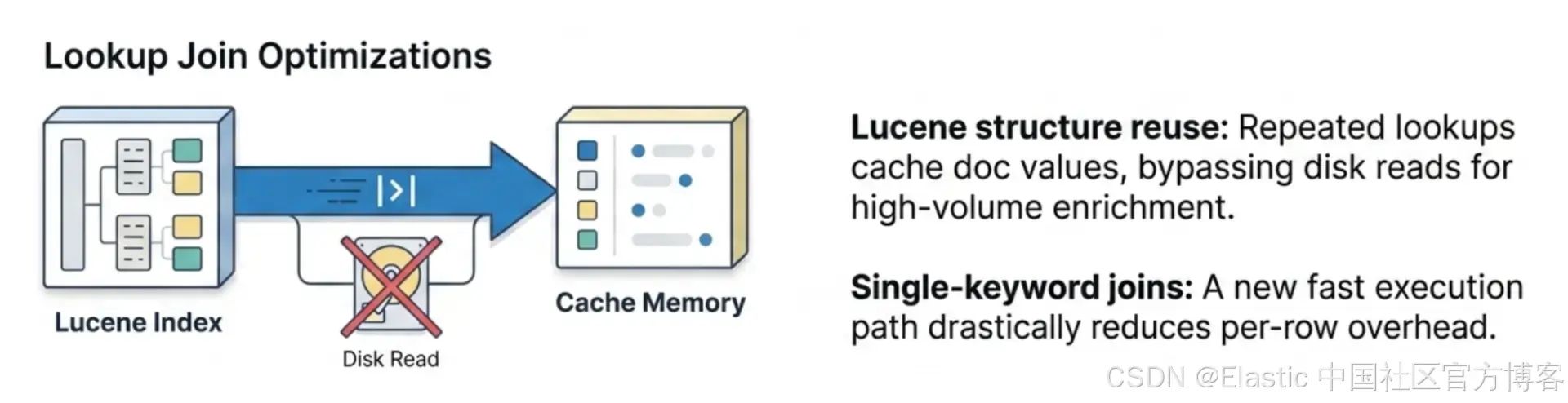
-
Lucene 结构复用(Lucene structure reuse):对同一 index 的重复 lookup 现在会在跨查询之间缓存底层 Lucene 结构(doc values 和 TermsEnum),避免重复磁盘读取。这在典型 enrichment 模式中尤其重要:大量 rows join 到一个小的 lookup index。性能提升来自于复用这些结构,而不是每次 query 重新构建。
-
单关键字 join 优化(Single-keyword join optimization):基于单个
keyword字段(最常见的 join key 类型)的 lookup join 现在使用更快的执行路径,从而降低每一行 join 的开销。
这两项优化共同使 lookup join 在高吞吐 enrichment 工作负载中更加实用。
ES|QL 时间序列支持与近似查询
本文重点介绍 query language 与 data access 能力。ES|QL 同时还新增了 时间序列支持(正式发布)(包括 TS 命令、PromQL 风格函数,以及 rate / changes / cumulative_sum),以及 近似查询,用于在大规模数据集上进行更快的探索性分析,这些内容在各自的独立文章中有详细说明。
ES|QL 路线图:materialized views、WHERE 子查询、Kibana CRUD UI
ES|QL 正在持续快速演进。未来路线图包括:
-
materialized views:预先计算一次,快速读取。对于不要求毫秒级新鲜度的高成本聚合,materialized views 可以用一定的延迟换取更高速度。
-
WHERE 子查询:
WHERE field IN (FROM other_index | ...)等相关形式,将组合能力从 FROM 扩展到过滤条件。 -
Kibana 中的 views CRUD UI:在 Discover 中提供 “Save as View” 体验,将 view 管理从 Dev Tools 中移出。
-
原生 flattened field 支持:消除对
_source上JSON_EXTRACT的依赖,解决最常见的 schema-on-read 场景。
试用
所有核心功能均已在 Elasticsearch 中以 Tech Preview 形式提供(views 在 Serverless 中尚不可用)。timezone 支持、FIRST/LAST/EARLIEST/LATEST、VALUES、MV_EXPAND、FORK 已为正式发布功能。可在 Kibana Dev Tools 或 Discover 中试用。
欢迎反馈。如果遇到问题或有功能建议,请在 GitHub 提交 ES|QL 标签 issue。
ES|QL subqueries、logical views、JSON extraction、unmapped field access、LIMIT BY、SPARKLINE、MV_UNION、MV_DIFFERENCE 和 MV_INTERSECTS 均为 Tech Preview 功能。Tech Preview 功能可能会发生变化,并且不在 GA 功能的支持 SLA 范围内。本文章中描述的功能或发布时间由 Elastic 自行决定,某些功能可能不会按计划交付或可能根本不会提供。
原文:ES|QL views, subqueries and schema-on-read in Elasticsearch - Elasticsearch Labs


















 2233
2233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










