



SBM 与社区检测:从信息论阈值到算法极限
导读:随机块模型(Stochastic Block Model, SBM)是网络科学中研究社区检测的"标准模型"。本文以 Emmanuel Abbe 的综述《Community Detection and Stochastic Block Models》(2017/2023)为骨架,系统梳理 SBM 社区检测的三大恢复层级——精确恢复(Exact Recovery)、弱恢复(Weak Recovery)与部分恢复(Partial Recovery)——各自对应的信息论阈值与算法可达性。我们将看到:Chernoff–Hellinger 阈值刻画精确恢复的物理边界,Kesten–Stigum 阈值划定弱恢复的相变点,而部分恢复则呈现 SNR–互信息的最优权衡。SDP、谱方法、置信传播及其线性化版本,在不同阈值边界上各显神通。
一、引言:为什么 SBM 是社区检测的"标准模型"
随机块模型(SBM)由 Holland 等人于 1983 年提出,它将网络中的社区结构抽象为一个随机图生成过程:每个节点被赋予一个隐藏的社区标签,边的存在概率仅依赖于其两端节点的社区归属。尽管 SBM 对真实网络的建模存在简化(例如忽略了度分布的异质性),但它提供了一个可控的数学环境,使得我们能够精确回答:
- 信息论极限:在什么参数范围内,社区结构在原理上可被恢复?
- 计算极限:在什么范围内,存在多项式时间算法可以达到信息论最优?
- 统计-计算鸿沟(Statistical-Computational Gap):是否存在信息论可恢复但计算不可行的参数区域?
这些问题使 SBM 成为研究高维统计推断中"相变现象"(phase transitions)的理想试验场。正如 Abbe 在其综述中所言,SBM “提供了一个肥沃的土壤,用于研究网络和数据科学中出现的统计与计算权衡”。
1.1 模型定义
一般 SBM:记为 S B M ( n , p , Q / n ) SBM(n, p, Q/n) SBM(n,p,Q/n),其中:
- n n n 为节点数;
- p ∈ ( 0 , 1 ) k p \in (0,1)^k p∈(0,1)k, ∥ p ∥ 1 = 1 \|p\|_1 = 1 ∥p∥1=1,为各社区的先验概率;
- Q ∈ ( 0 , ∞ ) k × k Q \in (0,\infty)^{k \times k} Q∈(0,∞)k×k 为对称的连接强度矩阵,社区 i i i 与 j j j 之间的边概率为 min ( 1 , Q i j / n ) \min(1, Q_{ij}/n) min(1,Qij/n)。
对称 SBM(SSBM): k k k 个等大小社区, p i = 1 / k p_i = 1/k pi=1/k, Q i i = a Q_{ii} = a Qii=a, Q i j = b Q_{ij} = b Qij=b( i ≠ j i \neq j i=j)。边概率为 a / n a/n a/n(社区内)和 b / n b/n b/n(社区间)。
1.2 三大恢复层级
社区检测问题根据恢复精度要求,可分为三个层级:
| 恢复层级 | 定义 | 适用度体制 |
|---|---|---|
| 精确恢复(Exact Recovery) | 以概率 1 − o ( 1 ) 1-o(1) 1−o(1) 正确恢复所有节点的社区标签 | 对数度: a , b = Θ ( log n ) a,b = \Theta(\log n) a,b=Θ(logn) |
| 弱恢复(Weak Recovery / Detection) | 以概率 1 − o ( 1 ) 1-o(1) 1−o(1) 恢复的标签与真实标签的相关性严格优于随机猜测 | 常数度: a , b = O ( 1 ) a,b = O(1) a,b=O(1) |
| 部分恢复(Partial Recovery) | 恢复一定比例(非全部)的节点标签,允许一定错误率 | 常数度或缓慢发散度 |
二、精确恢复:Chernoff–Hellinger 阈值
2.1 信息论阈值
在精确恢复问题中,图的平均度随 n n n 对数增长( a , b = Θ ( log n ) a,b = \Theta(\log n) a,b=Θ(logn))。Abbe 和 Sandon(2015)证明了一个令人惊讶的结果:精确恢复的信息论阈值完全由一对社区之间的 Chernoff–Hellinger(CH)散度 决定。
定理(Abbe & Sandon, 2015):对于 S B M ( n , p , ln ( n ) Q / n ) SBM(n, p, \ln(n)Q/n) SBM(n,p,ln(n)Q/n),精确恢复可解当且仅当
I + ( p , Q ) : = min 1 ≤ i < j ≤ k D + ( ( diag ( p ) Q ) i ∥ ( diag ( p ) Q ) j ) > 1 I_+(p, Q) := \min_{1 \leq i < j \leq k} D_+((\text{diag}(p)Q)_i \| (\text{diag}(p)Q)_j) > 1 I+(p,Q):=1≤i<j≤kminD+((diag(p)Q)i∥(diag(p)Q)j)>1
其中 CH 散度定义为:
D + ( μ ∥ ν ) : = max t ∈ [ 0 , 1 ] ∑ x ν ( x ) f t ( μ ( x ) ν ( x ) ) , f t ( y ) : = 1 − t + t y − y t D_+(\mu \| \nu) := \max_{t \in [0,1]} \sum_x \nu(x) f_t\left(\frac{\mu(x)}{\nu(x)}\right), \quad f_t(y) := 1 - t + ty - y^t D+(μ∥ν):=t∈[0,1]maxx∑ν(x)ft(ν(x)μ(x)),ft(y):=1−t+ty−yt
直观理解: D + D_+ D+ 度量了两个社区"连接剖面"(connection profile)之间的差异。当 D + > 1 D_+ > 1 D+>1 时,社区间的统计差异足够大,使得在 n → ∞ n \to \infty n→∞ 极限下可以无错地区分所有节点;当 D + < 1 D_+ < 1 D+<1 时,即使拥有无限计算资源,精确恢复也是不可能的。
2.2 对称情形的简化
对于对称 SBM( k k k 个社区, p i = 1 / k p_i = 1/k pi=1/k, Q i i = a Q_{ii} = a Qii=a, Q i j = b Q_{ij} = b Qij=b),CH 散度在 t = 1 / 2 t = 1/2 t=1/2 处取最大值,退化为 Hellinger 散度,阈值简化为:
1 k ( a − b ) 2 > 1 \frac{1}{k}(\sqrt{a} - \sqrt{b})^2 > 1 k1(a−b)2>1
特别地,对于两社区情形( k = 2 k=2 k=2):
( a − b ) 2 > 2 ⟺ ∣ a − b ∣ > 2 (\sqrt{a} - \sqrt{b})^2 > 2 \quad \Longleftrightarrow \quad |\sqrt{a} - \sqrt{b}| > \sqrt{2} (a−b)2>2⟺∣a−b∣>2
这与 Abbe, Bandeira 和 Hall(2016)早期得到的阈值一致。
2.3 算法可达性
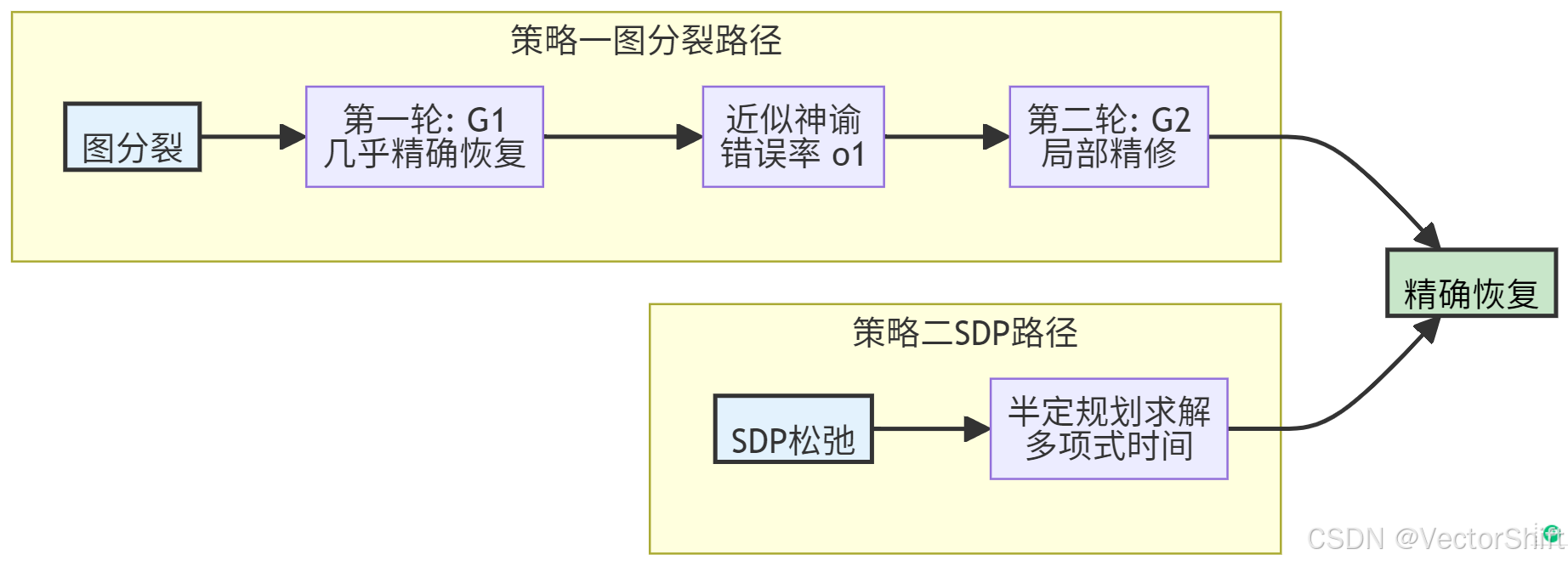
值得注意的是,精确恢复的阈值不仅是信息论的,也是计算可达的。Abbe 和 Sandon(2015)提出了基于图分裂(graph splitting)的两轮算法:
- 第一轮:将图的边以概率 γ = log log ( n ) / log ( n ) \gamma = \log\log(n)/\log(n) γ=loglog(n)/log(n) 分配到 G 1 G_1 G1,剩余分配到 G 2 G_2 G2。 G 1 G_1 G1 的度为 log log ( n ) \log\log(n) loglog(n),在此发散度下可用简单算法实现"几乎精确恢复"(almost exact recovery,即错误率为 o ( 1 ) o(1) o(1))。
- 第二轮:利用 G 1 G_1 G1 得到的几乎精确标签作为"近似神谕"(almost-exact genie),在 G 2 G_2 G2 上对每个节点进行局部 refine,达到精确恢复。
此外,谱方法也可以达到该阈值。在半定规划(SDP)方面,研究表明 SDP 松弛在精确恢复阈值处是紧的,提供了多项式时间的最优算法。
三、弱恢复:Kesten–Stigum 阈值
3.1 从树重建到图检测
在常数度体制( a , b = O ( 1 ) a,b = O(1) a,b=O(1))下,精确恢复是不可能的(因为存在线性数量的孤立节点),但"弱恢复"——即恢复的标签与真实标签有正相关——仍然有意义。这一问题的研究受到了统计物理的深刻启发。
Decelle, Krzakala, Moore 和 Zdeborová(2011)的开创性论文基于腔方法(cavity method)和置信传播(Belief Propagation, BP)提出了以下猜想:
DKMZ 猜想:对于 k k k 个对称社区,定义信噪比 S N R : = ( a − b ) 2 k ( a + ( k − 1 ) b ) SNR := \frac{(a-b)^2}{k(a+(k-1)b)} SNR:=k(a+(k−1)b)(a−b)2。
- 对所有 k k k,当 S N R > 1 SNR > 1 SNR>1(即 Kesten–Stigum 阈值)时,存在高效算法实现弱恢复;
- 对 k ≤ 4 k \leq 4 k≤4,当 S N R < 1 SNR < 1 SNR<1 时,弱恢复在信息论上是不可能的;
- 对 k ≥ 5 k \geq 5 k≥5,存在 S N R < 1 SNR < 1 SNR<1 的区域,弱恢复信息论上可能但计算上困难。
3.2 Kesten–Stigum 阈值
KS 阈值 S N R = 1 SNR = 1 SNR=1 等价于:
( a − b ) 2 k ( a + ( k − 1 ) b ) = 1 ⟺ ( a − b ) 2 = k ( a + ( k − 1 ) b ) \frac{(a-b)^2}{k(a+(k-1)b)} = 1 \quad \Longleftrightarrow \quad (a-b)^2 = k(a+(k-1)b) k(a+(k−1)b)(a−b)2=1⟺(a−b)2=k(a+(k−1)b)
对于两社区情形( k = 2 k=2 k=2),这简化为 ( a − b ) 2 > 2 ( a + b ) (a-b)^2 > 2(a+b) (a−b)2>2(a+b)。
KS 阈值的深层含义来自树上的广播过程(broadcast process on trees)。在 SBM 的局部邻域中,图的分布近似于一个 Galton-Watson 树,而社区标签的传播类似于树上的马尔可夫广播过程。Kesten 和 Stigum(1966)证明了:在树上,当且仅当 d λ 2 > 1 d\lambda^2 > 1 dλ2>1( d d d 为平均度, λ \lambda λ 为广播信道的第二特征值)时,根节点的标签可以从叶子节点的信息中重建。SBM 中的 S N R SNR SNR 正好对应于这一条件。
3.3 算法进展:谱救赎
DKMZ 猜想的正向部分(高效算法在 S N R > 1 SNR > 1 SNR>1 时可达)在 2014-2015 年间被多项工作证明:
1. 非回溯矩阵(Nonbacktracking Matrix)
Krzakala 等人(2013)提出了"谱救赎"(spectral redemption)猜想:非回溯矩阵(记为 B B B)的谱可以克服传统邻接矩阵在稀疏图上的谱退化问题。 B B B 是一个 2 m × 2 m 2m \times 2m 2m×2m 的矩阵( m m m 为边数),索引为图的有向边, B ( i → j ) , ( k → l ) = 1 j = k 1 i ≠ l B_{(i\to j), (k\to l)} = \mathbb{1}_{j=k}\mathbb{1}_{i\neq l} B(i→j),(k→l)=1j=k1i=l。
Bordenave, Lelarge 和 Massoulié(2015)严格证明了:对于两社区对称 SBM,当 ( a − b ) 2 > 2 ( a + b ) (a-b)^2 > 2(a+b) (a−b)2>2(a+b) 时, B B B 的第二特征值从"Bulk"中分离出来,其对应的特征向量携带社区信息,从而实现了弱恢复。
2. 自回避行走(Self-avoiding Walks)
Massoulié(2014)提出了基于自回避行走计数的谱方法,同样达到了 KS 阈值,但计算复杂度为 O ( n 1 + ϵ ) O(n^{1+\epsilon}) O(n1+ϵ)。
3. 线性化置信传播(Linearized BP)
置信传播(BP)在 SBM 上的不动点方程可以线性化,得到与谱方法等价的算法。Abbe 和 Sandon(2015)提出了无环置信传播(Acyclic Belief Propagation, ABP),并证明其在一般 SBM 上达到 KS 阈值,时间复杂度为 O ( n log n ) O(n \log n) O(nlogn)。
3.4 信息论不可能性
Mossel, Neeman 和 Sly(2015)证明了对于两社区情形,当 ( a − b ) 2 ≤ 2 ( a + b ) (a-b)^2 \leq 2(a+b) (a−b)2≤2(a+b) 时,弱恢复在信息论上是不可能的——即没有任何算法(即使计算时间无限)可以做得比随机猜测更好。他们的证明基于将 SBM 与 Erdős-Rényi 随机图耦合,展示了两个模型在此区域是相邻的(contiguous)。
最近,Mossel, Sly 和 Sohn(2023)进一步证明了对 k = 3 , 4 k=3,4 k=3,4 社区,当平均度足够大时,KS 阈值也是信息论紧的,解决了 DKMZ 猜想的剩余部分。
四、部分恢复:SNR–失真的最优权衡
4.1 问题设定
部分恢复介于弱恢复和精确恢复之间,要求在允许一定比例错误的前提下,尽可能多地恢复节点标签。在常数度体制下,SNR 定义为:
S N R : = ( a − b ) 2 k ( a + ( k − 1 ) b ) = O ( 1 ) SNR := \frac{(a-b)^2}{k(a+(k-1)b)} = O(1) SNR:=k(a+(k−1)b)(a−b)2=O(1)
这一体制下,最优的"失真-信噪比"(distortion-SNR)权衡是核心问题。
4.2 最优失真与树广播
Mossel, Neeman 和 Sly(2013)证明了一个深刻的结果:当 SNR 足够大时,SBM 中部分恢复的最优错误率由树上的广播问题决定。具体来说,考虑一个无限 d d d-正则树,根节点标签通过信道 P ( σ c h i l d ∣ σ p a r e n t ) P(\sigma_{child} | \sigma_{parent}) P(σchild∣σparent) 广播到叶子。当树的深度趋于无穷时,叶子节点包含的关于根节点标签的信息量决定了 SBM 中可恢复的最优比例。
这一结果将图上的推断问题与树上的重建问题联系起来,体现了 SBM 的局部-全局对应(local-to-global correspondence)。
4.3 互信息与 MMSE
Deshpande, Abbe 和 Montanari(2015)以及 Mossel 和 Xu(2015)在有限 SNR 且度缓慢发散的体制下,给出了互信息 I ( X ; G ) / n I(X; G)/n I(X;G)/n 的渐近表达式,以及最小均方误差(MMSE)的精确公式。
对于两社区对称 SBM,当 a , b → ∞ a,b \to \infty a,b→∞ 且 S N R = ( a − b ) 2 2 ( a + b ) SNR = \frac{(a-b)^2}{2(a+b)} SNR=2(a+b)(a−b)2 固定时,归一化互信息的极限存在,且 MMSE 可以通过固定点方程计算。这一结果与尖峰维格纳模型(spiked Wigner model)的推断理论密切相关。
4.4 部分恢复的算法
在部分恢复体制下,多种算法可以接近最优权衡:
- 谱方法:Yun 和 Proutière(2014)以及 Chin 等人(2015)的谱算法达到了 C exp ( − S N R / 2 ) C \exp(-SNR/2) Cexp(−SNR/2) 的错误率。
- BP 及其变体:在已知模型参数时,BP 可以接近最优的失真-SNR 权衡。
- 图幂运算(Graph Powering):Abbe, Boix-Adserà, Ralli 和 Sandon(2020)提出了图幂运算方法,通过对图的邻接矩阵进行幂运算来增强社区信号,提高谱方法的鲁棒性。
五、信息-计算鸿沟:当统计可行遇上计算困难
5.1 四社区之谜
DKMZ 猜想最引人注目的部分是:当社区数 k ≥ 4 k \geq 4 k≥4 时,可能存在一个信息-计算鸿沟(information-computation gap)——即在 KS 阈值之下、某个信息论阈值之上的区域,弱恢复在原理上是可能的,但没有任何已知的多项式时间算法可以实现。
Abbe 和 Sandon(2015, 2018)证明了这一猜想的正向部分:对于 k ≥ 4 k \geq 4 k≥4 的对称 SBM,存在非高效算法可以在 S N R < 1 SNR < 1 SNR<1 时实现弱恢复。具体来说,他们通过采样一个"典型聚类"(typical clustering)——即具有正确边比例的非高效算法——展示了信息论恢复的可能性。
Banks, Moore 等人(2016)进一步刻画了信息论阈值随 k k k 增长的标度行为:当 a = 0 a = 0 a=0 时,KS 阈值要求 b ≳ k 2 b \gtrsim k^2 b≳k2,而信息论阈值仅要求 b ≳ k log k b \gtrsim k \log k b≳klogk,鸿沟随 k k k 增大而扩大。
5.2 低阶多项式困难性证据
虽然严格证明计算困难性超出了现有复杂度理论的能力,但 低阶多项式方法(low-degree polynomial method)为计算鸿沟提供了有力证据。Hopkins 和 Steurer(2017)以及后续工作表明,在 KS 阈值之下,低阶多项式无法检测社区结构,而这类方法可以近似大多数已知的多项式时间算法(包括谱方法和 AMP)。
最近,Sohn 和 Wein(2025)进一步证明了在 q ≪ n q \ll \sqrt{n} q≪n 时,SBM 恢复在低阶意义下是困难的。
5.3 三社区与四社区的精确相变
Mossel, Sly 和 Sohn(2023)的最新工作精确刻画了 k = 3 , 4 k=3,4 k=3,4 时的相变:对于足够大的平均度 d d d,当 d λ 2 ≤ 1 d\lambda^2 \leq 1 dλ2≤1 时,弱恢复在信息论上是不可能的。这意味着对于 k = 3 , 4 k=3,4 k=3,4,不存在信息-计算鸿沟——KS 阈值就是信息论阈值。
然而,对于 k = 4 k=4 k=4 且 λ < 0 \lambda < 0 λ<0(反铁磁情形),存在一个临界度 d ∗ d^* d∗:当 d < d ∗ d < d^* d<d∗ 时,KS 阈值不是紧的,信息论恢复可以在 d λ 2 < 1 d\lambda^2 < 1 dλ2<1 时实现;当 d > d ∗ d > d^* d>d∗ 时,KS 阈值恢复紧性。对于 k ≥ 5 k \geq 5 k≥5,KS 阈值在铁磁和反铁磁区域都不是紧的。
六、算法工具箱:从谱方法到图幂运算
6.1 半定规划(SDP)
SDP 通过将离散的社区分配问题松弛为半定规划问题,提供了天然的鲁棒性。对于精确恢复,SDP 在 CH 阈值处是紧的。对于弱恢复,Montanari 和 Sen(2016)的 SDP 方法随着平均度增加而接近 KS 阈值。
SDP 的优势在于对对抗性扰动的鲁棒性:Makarychev 等人(2016)证明了 SDP 可以容忍 o ( n ) o(n) o(n) 条对抗边的添加。
6.2 非回溯谱方法
非回溯矩阵 B B B 的核心优势在于:在稀疏随机图中, B B B 的谱行为比邻接矩阵更"干净"——其特征值分布在一个半径为 ρ ( B ) \sqrt{\rho(B)} ρ(B) 的圆盘内,而社区信号对应的特征值位于圆盘之外。
Bordenave, Lelarge 和 Massoulié(2015)的严格分析表明:对于一般 SBM(不一定对称),当第二特征值 ∣ λ 2 ∣ |\lambda_2| ∣λ2∣ 满足某些条件时,非回溯方法可以检测社区。
Bethe Hessian 是另一种对称化的替代方案,由 Saade 等人(2014)提出,同样可以达到 KS 阈值。
6.3 图幂运算与谱鲁棒性
图幂运算(Graph Powering)是近年来提高谱方法鲁棒性的重要技术。Abbe 等人(2020)提出了通过对邻接矩阵进行幂运算 A ( ℓ ) A^{(\ell)} A(ℓ)(其中 A i j ( ℓ ) A^{(\ell)}_{ij} Aij(ℓ) 表示长度恰好为 ℓ \ell ℓ 的路径数)来增强社区信号。当 ℓ ∼ κ log n \ell \sim \kappa \log n ℓ∼κlogn 时,图幂运算可以:
- 放大信号:社区内路径数与社区间路径数的差距随 ℓ \ell ℓ 指数增长;
- 抑制噪声:随机图中的短环被有效控制;
- 提高鲁棒性:对对抗性添加的小团(cliques)不敏感。
6.4 算法阈值对照表
| 算法 | 精确恢复 | 弱恢复 | 部分恢复 | 鲁棒性 |
|---|---|---|---|---|
| SDP | 达到 CH 阈值 | 接近 KS 阈值(大 d d d) | 次优 | 强(对抗 o ( n ) o(n) o(n) 边) |
| 非回溯谱 | 不适用(常数度) | 达到 KS 阈值( k = 2 k=2 k=2) | 良好 | 弱(对小团敏感) |
| 线性化 BP | 不适用 | 达到 KS 阈值(一般 k k k) | 接近最优 | 中等 |
| 图幂运算 | 不适用 | 达到 KS 阈值 | 良好 | 强 |
| 两轮算法 | 达到 CH 阈值 | 不适用 | 不适用 | 中等 |
七、开放问题与未来方向
尽管 SBM 社区检测的理论已相当成熟,仍有若干核心问题待解:
7.1 部分恢复的精确极限
在常数度体制下,对于任意有限 SNR,部分恢复的最优失真-SNR 权衡仍是开放问题。Mossel 等人(2013)的结果仅在 SNR 足够大时成立。对于有限 SNR, I ( X ; G ) / n I(X;G)/n I(X;G)/n 的极限是否存在?其表达式如何?这些问题在 disassortative 情形( λ < 0 \lambda < 0 λ<0)已有部分进展,但 assortative 情形( λ > 0 \lambda > 0 λ>0)仍待解决。
7.2 信息-计算鸿沟的严格化
对于 k ≥ 5 k \geq 5 k≥5,虽然低阶多项式方法提供了计算困难的证据,但严格的计算下界(例如基于平均情形复杂度假设如 planted clique 假设的归约)仍然缺失。能否证明在 KS 阈值之下,某种标准的计算复杂性假设蕴含社区检测的困难性?
7.3 超越 SBM
真实网络往往偏离 SBM 的理想假设:度分布异质性(degree-corrected SBM)、重叠社区(overlapping communities)、动态网络、带节点属性的网络(contextual SBM)等。如何将 SBM 的阈值理论推广到这些更现实的模型?
7.4 学习 SBM 参数
在未知参数 ( p , Q ) (p, Q) (p,Q) 的情况下,能否在达到恢复阈值的同时高效学习这些参数?对于精确恢复,参数学习相对简单;但对于弱恢复,参数估计与社区检测的耦合带来了新的挑战。
八、总结:物理边界与算法对照
SBM 社区检测的研究揭示了一个优美的理论图景:
-
精确恢复的物理边界由 Chernoff–Hellinger 散度 刻画, D + > 1 D_+ > 1 D+>1 是充要条件,且该阈值可被高效算法达到。
-
弱恢复的相变点由 Kesten–Stigum 阈值 S N R = 1 SNR = 1 SNR=1 决定。对于 k = 2 , 3 k=2,3 k=2,3 以及 k = 4 k=4 k=4(大 d d d 时),这是信息论紧的;对于 k ≥ 5 k \geq 5 k≥5,信息论阈值严格低于 KS 阈值,产生信息-计算鸿沟。
-
部分恢复呈现 SNR-失真最优权衡,大 SNR 时由树上广播问题决定极限。
-
算法层面:SDP 提供鲁棒的最优解;非回溯谱方法和线性化 BP 在 KS 阈值处实现弱恢复;图幂运算增强了谱方法的鲁棒性;两轮算法通过"局部到全局放大"实现精确恢复。
参考文献
-
Abbe, E. (2017/2023). Community Detection and Stochastic Block Models: Recent Developments. Journal of Machine Learning Research, 18(1), 6446-6531. arXiv:1703.10146
-
Abbe, E., & Sandon, C. (2015). Community detection in general stochastic block models: Fundamental limits and efficient algorithms for recovery. FOCS 2015.
-
Abbe, E., & Sandon, C. (2018). Proof of the achievability conjectures for the general stochastic block model. Communications on Pure and Applied Mathematics, 71(7), 1334-1406.
-
Abbe, E., Bandeira, A. S., & Hall, G. (2016). Exact recovery in the stochastic block model. IEEE Transactions on Information Theory, 62(1), 471-487.
-
Abbe, E., Boix-Adserà, E., Ralli, P., & Sandon, C. (2020). Graph powering and spectral robustness. SIAM Journal on Mathematics of Data Science, 2(1), 132-157.
-
Bordenave, C., Lelarge, M., & Massoulié, L. (2015). Non-backtracking spectrum of random graphs: Community detection and non-regular Ramanujan graphs. FOCS 2015.
-
Decelle, A., Krzakala, F., Moore, C., & Zdeborová, L. (2011). Asymptotic analysis of the stochastic block model for modular networks and its algorithmic applications. Physical Review E, 84(6), 066106.
-
Deshpande, Y., Abbe, E., & Montanari, A. (2015). Asymptotic mutual information for the two-groups stochastic block model. arXiv:1507.08685.
-
Krzakala, F., Moore, C., Mossel, E., Neeman, J., Sly, A., Zdeborová, L., & Zhang, P. (2013). Spectral redemption in clustering sparse networks. PNAS, 110(52), 20935-20940.
-
Massoulié, L. (2014). Community detection thresholds and the weak Ramanujan property. STOC 2014.
-
Mossel, E., Neeman, J., & Sly, A. (2015). Reconstruction and estimation in the planted partition model. Probability Theory and Related Fields, 162(3-4), 431-461.
-
Mossel, E., Neeman, J., & Sly, A. (2018). A proof of the block model threshold conjecture. Combinatorica, 38(3), 665-708.
-
Mossel, E., Sly, A., & Sohn, Y. (2023). Exact phase transitions for stochastic block models and reconstruction on trees. STOC 2023.
-
Banks, J., Moore, C., Vershynin, R., Verzelen, N., & Xu, J. (2016). Information-theoretic bounds and phase transitions in clustering, sparse PCA, and submatrix localization. arXiv:1607.05222.
-
Hopkins, S. B., & Steurer, D. (2017). Bayesian estimation from few samples: community detection and related problems. arXiv:1710.00264.
后记:SBM 的研究展示了理论计算机科学、概率论、统计物理和信息论之间的深刻联系。从 DKMZ(2011)的物理猜想到 Abbe & Sandon(2015-2018)的严格证明,从 Mossel-Neeman-Sly 的树上重建到 Bordenave-Lelarge-Massoulié 的谱救赎,这一领域在过去十年中经历了爆炸式的发展。对于从业者而言,理解这些阈值不仅具有理论意义——当你面对一个真实的社区检测问题时,计算 CH 散度或 SNR 可以告诉你:这个问题在原理上是否可解?需要多强的算法?这正是"物理边界"思维的价值所在。



















】SBM 与社区检测:从信息论阈值到算法极限&spm=1001.2101.3001.5002&articleId=162517792&d=1&t=3&u=2fb89c90cc1a4287ae920ea35188c7fb)
 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












