




上一节《【Django 022】中间件Middleware(一):Django中间件本质和处理流程详解》中,我们了解了中间件的本质和执行逻辑,这一节就来自己动手制作一个用来反爬虫的中间件。
我是T型人小付,一位坚持终身学习的互联网从业者。喜欢我的博客欢迎在csdn上关注我,如果有问题欢迎在底下的评论区交流,谢谢。
爬虫
爬虫,就是一段伪装成浏览器,对网站发起请求获得网站资源的程序。例如爬取某求职网站的薪水统计,征婚交友网站的美女资料,或者某电子书网站的电子书等等。因为快速高效,爬虫可以帮助我们自动完成很多在线搜索统计的工作。
但是做为服务器,因为爬虫程序的频繁请求,可能造成负载过高,甚至宕机的后果。所以服务端运维通常会对自己的网站加入很多反爬机制。
爬虫与反爬一直是大家津津乐道的话题。今天咱们就来看看如何实现自己的一个反爬小程序,知己知彼,百战不殆。
反爬和频率控制
如果一个爬虫程序频繁对服务器进行请求,会对服务器性能造成极大冲击。所以如果发现某个用户或者某个ip访问极为频繁,基本可以判定其为爬虫,从而对其行为进行一些限制。
这里模仿前面《【Django 013】Django2.2会话技术之Session》中去创建登录页面和个人主页,结合《【Django 021】Django2.2利用装饰器和cache底层API两种方式实现Redis缓存原理和操作详解》对每个sessionid记录访问个人主页时间戳来达到限制用户频繁访问的目的。
正常登录逻辑
- 访问
login/页面,如果session已经存在,跳转到homepage/,否则进入登入页面。提交登陆表单后创建session并进入homepage/,如果用户名为空则一直重定向回login/ - 如果session已经存在,直接访问
homepage/可以成功,否则重定向到login/ - 主页的
logout/会flush当前用户的session,重定向到login/重新登陆
三个路由规则和view函数如下
path('login/', views.login, name='login'),
path('homepage/', views.homepage, name='homepage'),
path('logout/', views.logout, name='logout'),
def login(request):
if request.method == 'GET':
name = request.session.get('username', 0)
if name:
response = HttpResponseRedirect(reverse('app:homepage'))
else:
response = render(request, 'login.html')
return response
elif request.method == 'POST':
name = request.POST.get('name', 0)
if name:
response = HttpResponseRedirect(reverse('app:homepage'))
request.session['username'] = name
else:
response = HttpResponseRedirect(reverse('app:login'))
return response
def homepage(request):
name = request.session.get('username', 0)
if name:
response = render(request, 'homepage.html', context={'name': name})
else:
response = HttpResponseRedirect(reverse('app:login'))
return response
def logout(request):
request.session.flush()
return HttpResponseRedirect(reverse('app:login'))
login页面h5如下,这里的csrf_token是防跨站攻击的,也是Django自带的安全中间件,下一节再详细讲csrf的原理
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Login</title>
</head>
<body>
<form action="{% url 'app:login' %}" method="post">
{% csrf_token %}
<label for="name">Name: </label><input type="text" id="name" name="name" placeholder="Your name">
<input type="submit">
</form>
</body>
</html>
homepage页面h5如下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Homepage</title>
</head>
<body>
<h2>Hi {{ name }}, These are all your photos and videos</h2>
<a href="{% url 'app:logout' %}">Logout</a>
</body>
</html>
基本逻辑完成以后,下面开始本节的重点,频率限制。
假设一个爬虫,已经模拟了用户登录,获取了session,开始疯狂爬取登录用户才能获取的资源。这时候就可以针对该用户做一些操作了。
10秒只能访问一次
频率限制的逻辑如下。
用户在访问本项目任何url前,中间件会去检查是否存在sessionid对应的username的值,如果存在说明session已经被创建,进入频率限制的逻辑。如果不存在(可能是cookie没带sessionid,或者是session过期),则中间件跳过不处理。
如果session存在,中间件去cache中查找该session对应的cache是否存在,没有则创建,过期时间10秒,如果有则返回ttl,直接提示用户等待。
中间件实现如下
class Test1(MiddlewareMixin):
def process_request(self, request):
name = request.session.get('username', 0)
if name:
cache = caches['my_redis_cache']
if cache.get(name):
ttl = cache.ttl(name)
response = HttpResponse('Hi {}, please wait for another {} seconds to visit'.format(name,str(ttl)))
return response
else:
cache.set(name, name, timeout=10)
这里利用之前配置的redis做cache,以用户的name做为key,name做为value,过期时间为10秒。如果key已经存在,返回ttl提示给用户。
如果出现 ‘WSGIRequest’ object has no attribute ‘session’ 的报错,试着将自定义的中间件放在settings中列表的最后
效果如下
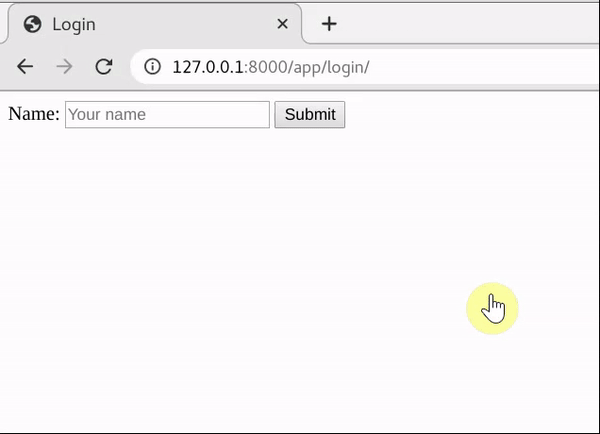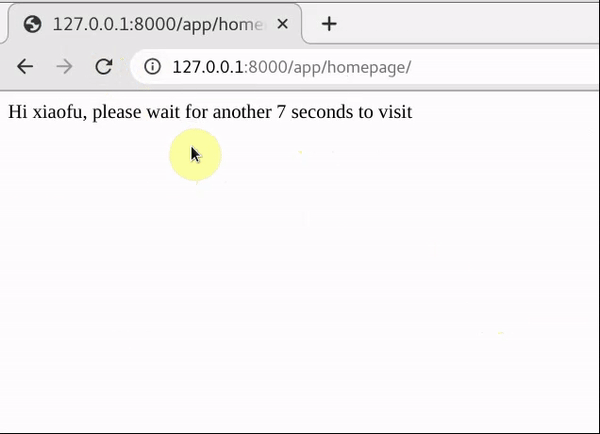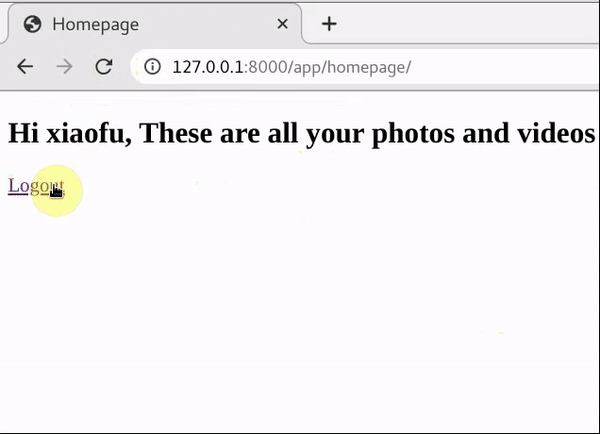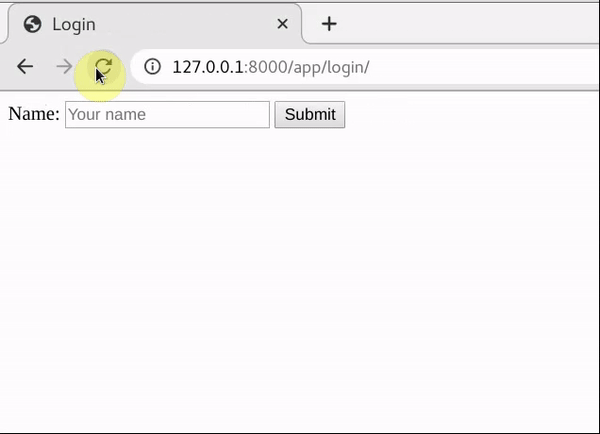
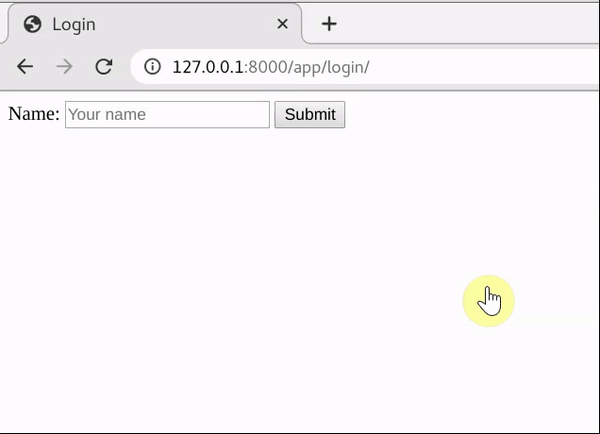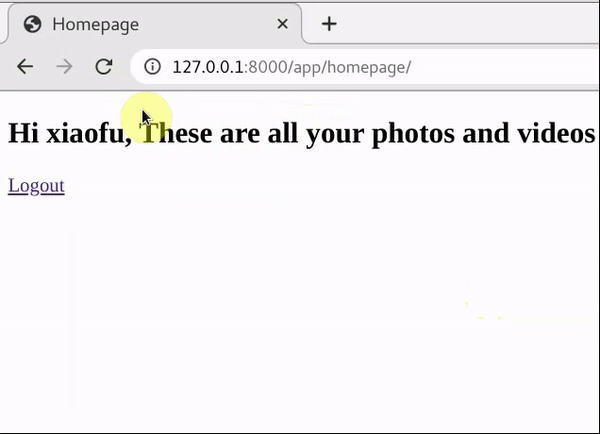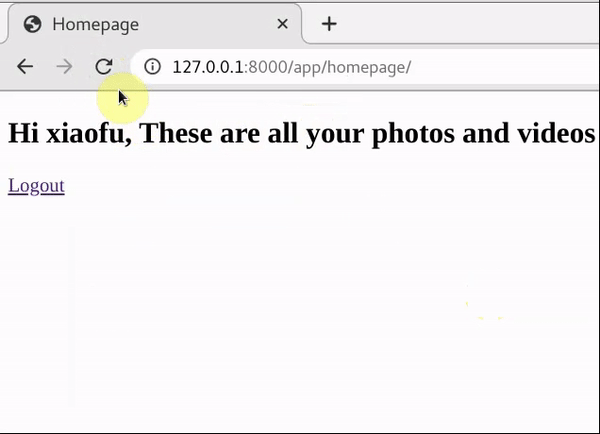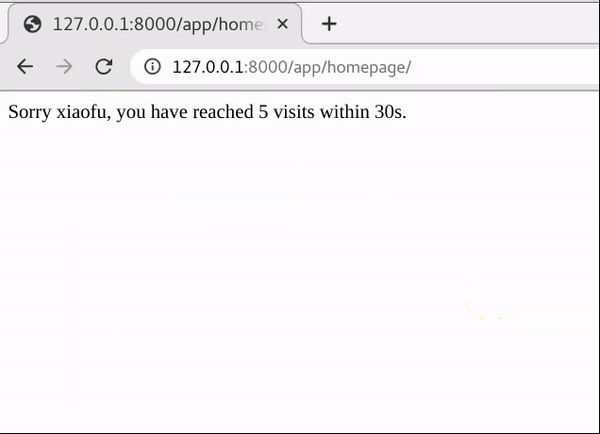
30秒只能访问五次
如果更进一步,想要实现动态时间限制,其逻辑如下。
同样是通过session的值做为key来存储cache,不过不同的是,这里cache的value是一个list。每次用户携带sessionid成功访问,都在list里面插入当前的时间。同时每次访问的时候,清除距现在操作30秒的时间戳,然后计算剩余时间戳的个数。如果个数操作5,则本次操作失败。
中间件实现如下
class Test1(MiddlewareMixin):
def process_request(self, request):
name = request.session.get('username', 0)
if name:
cache = caches['my_redis_cache']
timestamps = cache.get_or_set(name, default=[], timeout=30)
for item in timestamps:
if time.time() - item > 30:
timestamps.remove(item)
if len(timestamps) > 5:
return HttpResponse('Sorry {}, you have reached 5 visits within 30s.'.format(name))
else:
timestamps.append(time.time())
cache.set(name, timestamps, 30)
这里利用cache的get_or_set方法可以在cache不存在的时候set一个默认值以及过期时间。
效果如下
封ip操作
除了前面两种限制频率的操作,还可以更进一步,直接将某个频繁访问的用户的cache过期时间改为1天,而且cache存在情况下不能访问,这样就达到了将用户封ip一天的目的。
因为与前面两种方式代码大同小异,这里就不写了,大家可以自己练习一下。
总结
通过写了两个简单的反爬小程序,我们巩固了中间件的执行逻辑。下一节就一起去看看Django自带的csrf中间件是怎么样的。

















:结合session和cache实现反爬虫中间件图文详解&spm=1001.2101.3001.5002&articleId=105522867&d=1&t=3&u=5f0334eb16044d4e943632ed16680fee)
 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










