




前情提要
之前我们学习了大名鼎鼎的transformer,并且理解了他的核心各种Attention,现在我们一起来看一下BEVFormer,了解了前面那些基础知识,再来看BEVFormer简直太简单。比学习SLAM那些理论公式啥的可简单多了。
还记得之前我们学习过的Deformable Attention吗?BEV Former就是使用的它!如果忘记了可以看我之前的文章为什么要使用Deformable Attention?
BEVFormer要解决什么问题?
问题一:LSS 这类「深度驱动 BEV 方案」存在致命复合误差
我们前面学习过传统获得BEV特征的方法LSS,它先给每个像素预测一组离散深度分布,把 2D 像素升维成 3D 射线点,再全部投影、加权累加生成 BEV 特征。这样的缺点有以下几个方面:
- 强依赖深度预测精度,误差层层叠加
深度估不准 → 3D 空间坐标偏移 → Splat 投影到错误 BEV 栅格 → BEV 特征彻底失真;远距离物体、低矮障碍物深度极易出错,直接漏检 / 误检。 - 离散深度带来量化误差
LSS 必须手动设定有限深度区间(比如 5~40m 分 8 档),真实物体深度不在离散档位时,加权权重失真,远处物体特征稀疏、定位差。 - 前向投影造成 BEV 栅格空洞
图像像素是 “由近到远锥形射线”,远处 BEV 栅格很难分到足够像素特征,大片区域特征缺失,分割、远距离检测效果差。 - 多相机融合割裂
6 路相机各自独立 Lift-Splat,各自生成局部 BEV 再简单拼接,没有全局联合对齐,相机重叠区域特征冲突。
我们来看BEVFormer 怎么解决的。
抛弃显式深度预测,改用反向查询范式:
它提前定义了全覆盖地面的 BEV 栅格 Query,根据相机内外参算出栅格理论成像位置,再用 Deformable Attention 自适应在多相机图像采样特征;
不需要预测像素深度,从根源消除深度带来的连锁误差,每个 BEV 栅格都会主动去图像捞特征,不会出现栅格空洞。
问题二:传统纯视觉 BEV无法有效利用时序历史信息,动态场景感知拉胯
之前的方法都是一帧图像只处理当前画面,没有利用历史信息;
动态场景下感知较差,比如我们动态物体被遮挡了就会产生漏检。
而BEVFormer的时序自注意力模块可以有效利用历史信息,可以在当前时刻BEV栅格位置去历史时刻中查询特征,也就是说他可以把历史信息融合到当前时刻,如果某辆车在当前时刻被遮挡了,但是他知道历史时刻是有辆车在那个地方的,他可以学习到那辆车的速度,估计他的运动轨迹,即使当前时刻看不到了,也能知道他大概去了什么位置。所以BEVFormer构建的BEV空间特征时空更加一致。
问题三:传统全局 Cross-Attention 算力爆炸
这一点其实就是Deformable Attention的功劳,之前我们也研习过,这里就不多讲了,大概意思就是传统的全局交叉注意力,BEV栅格里的每一个query都要和所有图片的每个像素去做Attention,复杂度大到爆!BEV 栅格 16384 个,单路图像上万像素,6 相机计算量上亿次!然而,99% 图像像素和当前 BEV 栅格无关,大量无效全局匹配,算力浪费严重。
所以就用到了Deformable Attention:每个 BEV Query 只在图像局部采样固定 K 个关键点(K=4/8),结合相机几何先验给出采样基准点,仅局部微调偏移,兼顾精度与实时性。
问题四:多相机跨视角特征对齐困难,缺少强几何先验引导
传统的Query- based方案仅用纯数据驱动学习图像采样位置,没有利用相机标定(内参、外参)几何先验,也就是网络从零学习 BEV 到图像的映射,收敛慢、训练难度高;而且标定误差、车辆颠簸、物体高度变化带来投影错位,模型也无法自适应修正。
而BEVFormer每个 BEV 栅格的世界坐标,通过内外参先验反向投影得到图像基准参考点;网络仅学习微小偏移修正标定 / 抖动误差,几何先验大幅降低学习难度;一次性同步遍历全部 6 路环视相机,全局联合采样融合多视角信息,解决相机重叠区域冲突。
也就是说它利用上了我们已知的标定参数这种先验信息,相当于直接知道了每个query大概去图像哪个位置去查找特征,而不是漫无目的地硬学。还有之前的LSS方案都是每个图像单独做LSS然后再去融合成BEV特征,这样可能视角重叠的地方融合较差,而BEVFormer是主动去每个相机图像上去查自己想要的信息,而且可学习偏移可以自动修正几何误差,全局对齐,鲁棒性更强。
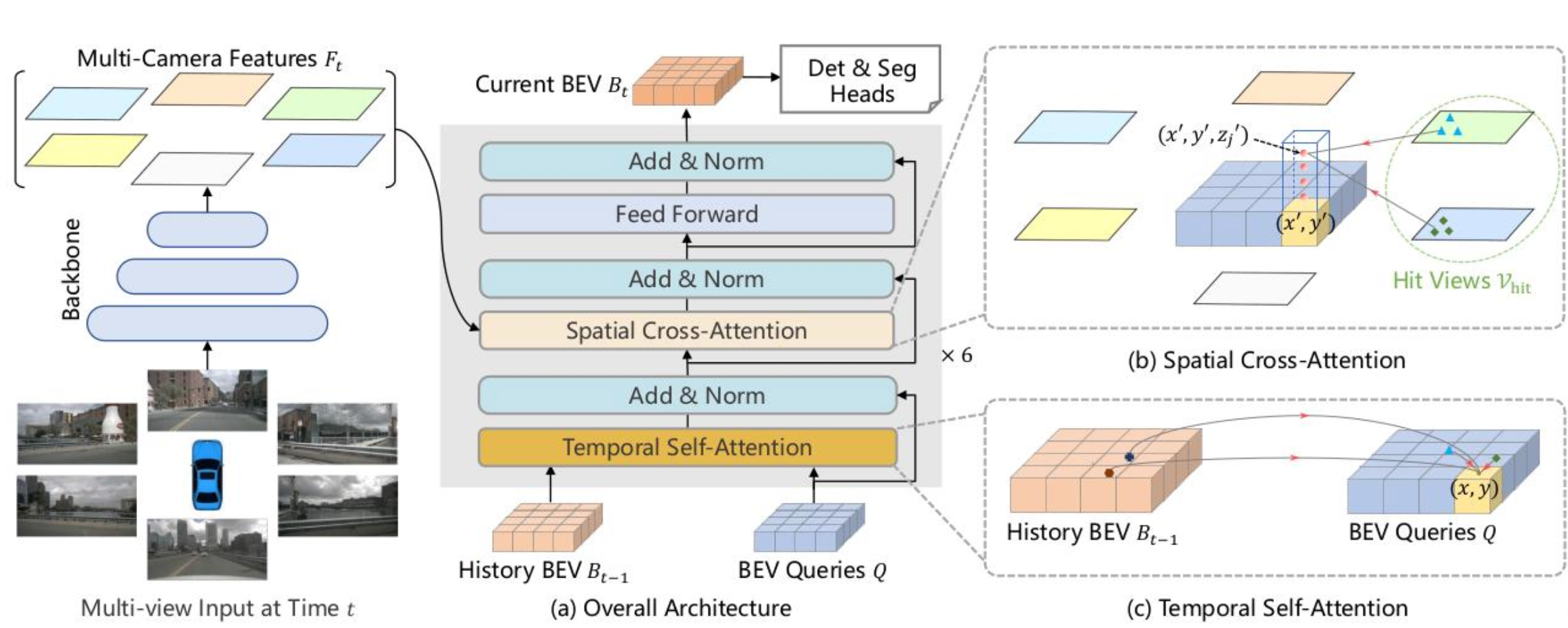
BEVFormer整体架构
这个图我们可以看的很明白,主要是分三个模块。
模块一:输入预处理 Backbone + FPN(图像特征提取)
- 环视 6 路相机图像(前、前左、前右、后、后左、后右),附带相机标定参数(内参 K、外参 T 相机 - 世界变换矩阵),是空间交叉注意力机制几何投影的核心先验。
- 网络结构:Backbone:ResNet101-DCN(带可变形卷积,提升物体特征提取;Neck:FPN 多尺度特征融合。
- 每路相机输出统一通道 256 的多尺度特征图集合 ( F t = F t 1 , F t 2 , . . . , F t 6 ) (F_t={F_t^1,F_t^2,...,F_t^6}) (Ft=Ft1,Ft2,...,Ft6),送入后续Spatial Cross-Attention作为 KV 数据源。
这里有个比较关键的点:
图像特征只作为 KV,不会向下层传递,仅在空间交叉注意力机制内部临时采样使用。也就是说,这些图像特征会缓存下来,为每一层的空间交叉注意力模块提供输入!当前时刻算完这些KV会被更新为新提取的图像特征!
模块二:核心载体 Grid-shaped BEV Queries
- 定义与超参
一组全局可学习网格参数,形状 [ H b e v × W b e v , d m o d e l ] [H_{bev}×W_{bev}, d_{model}] [Hbev×Wbev,dmodel]
空间范围:自车周围[−51.2m, 51.2m]
分辨率:0.8m / 栅格
网格尺寸: H b e v = W b e v H_{bev}=W_{bev} Hbev=Wbev=128,总 Query 数量128×128=16384
特征维度: d m o d e l = 256 d_{model}=256 dmodel=256 - 物理含义
每一个 Query 索引 ( i , j ) (i,j) (i,j)唯一对应地面 BEV 平面一个固定栅格的世界坐标 ( X w , Y w ) (X_w,Y_w) (Xw,Yw),自带可学习位置编码注入空间位置信息。
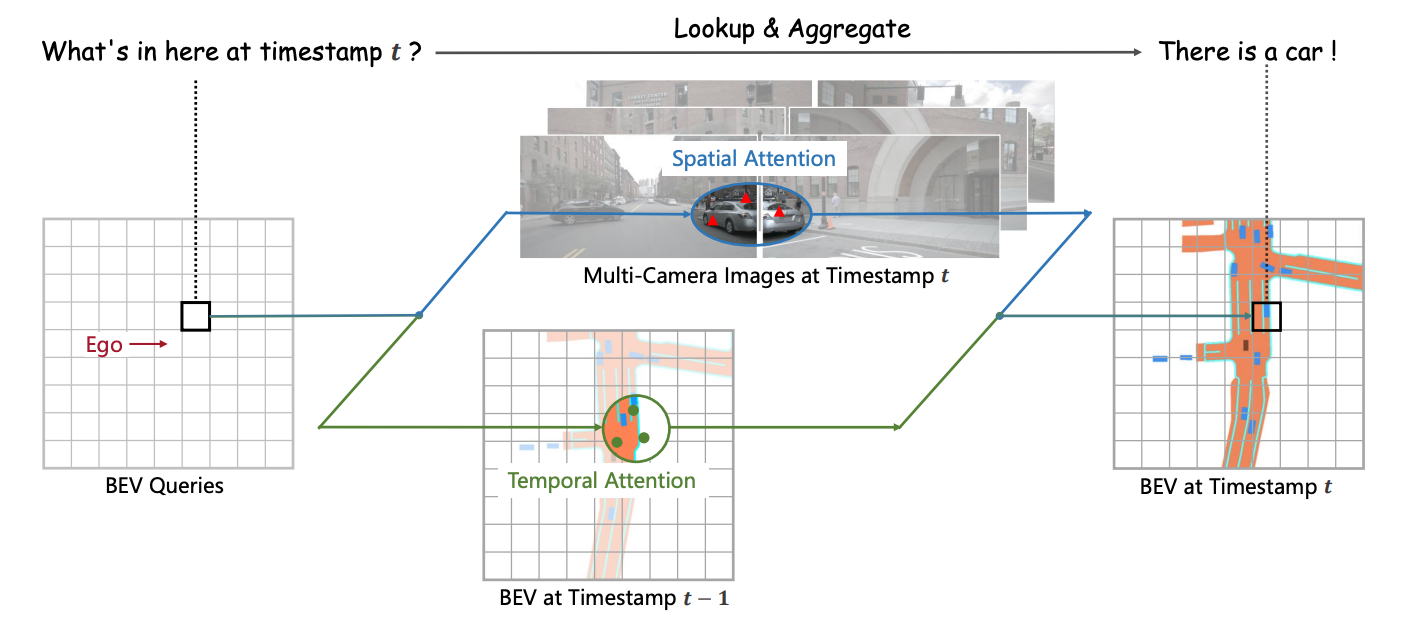
可以这样理解,这个图里的最左边那个栅格图里每个栅格里存的就是query!每个query有个栅格图里索引也对应着世界系的坐标。
模块三:核心 6 层堆叠时空 Transformer Encoder
每层两个注意力全部基于我们之前学习的Deformable Attention可变形注意力!
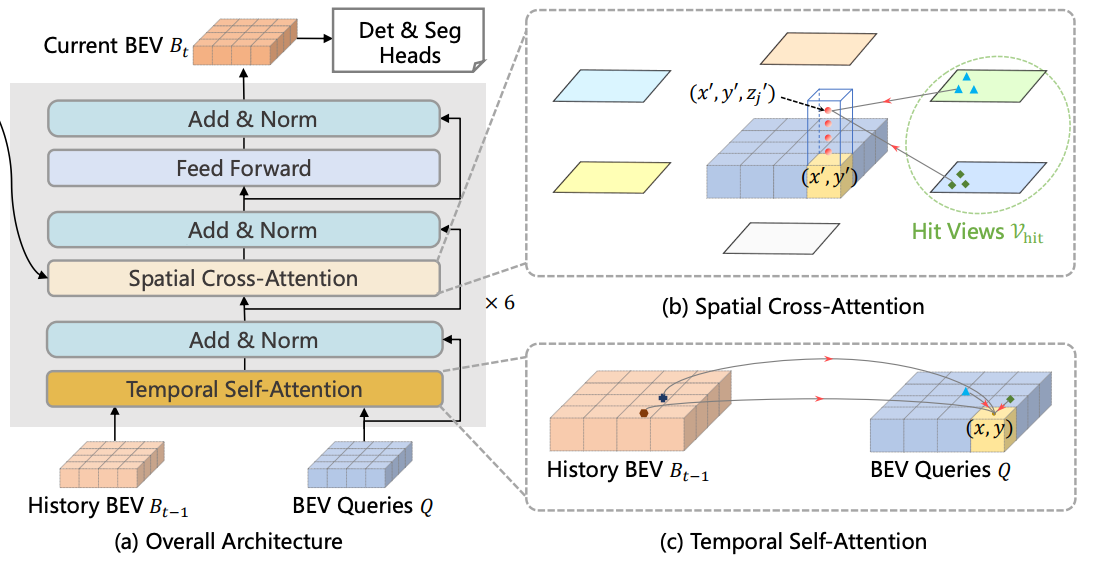
这块咱们分开来学习:
这里还是来回顾一下Deformable Attention,大体来说就是输入一个query,基于这个query会接两个全连接网络分别预测偏移量和权重;还有两个输入,参考点以及BEV特征(KV)。我们会在参考点附近根据偏移量在BEV特征里拿局部特征(KV),然后结合预测的权重计算出新的query。
好,我们可以来看时序自注意力和空间的交叉注意力是怎么回事了。
注意:事实上,BEVFormer也是先做时序的自注意力,在做空间的交叉注意力的!大家可以思考一下为什么这么设计?!
时序自注意力模块
先来看时序自注意力模块:
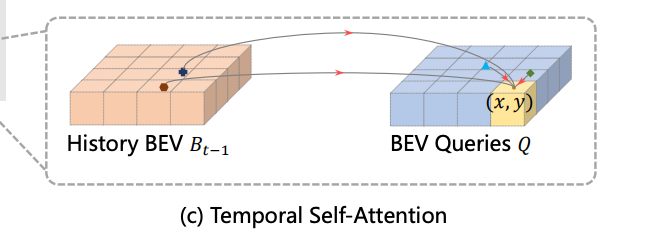
我们先来明确一下这里面的QKV到底怎么对应。
Query就是当前层输入 BEV Query
(
Q
i
n
)
(Q_{in})
(Qin);
KV 数据源:上一帧对齐后的完整历史 BEV 特征
(
B
t
−
1
)
(B_{t-1})
(Bt−1)
为什么叫Self-Attention?就是因为他是在历史的BEV特征里去查找信息的,(同空间拓扑、同维度特征图)。
好,我们带入Deformable Attention框架,有个query,有个BEV特征,还有个参考点,这里的参考点直接取当前 BEV Query 对应的地面栅格归一化坐标作为采样基准(归一化到 [0,1] 的平面坐标,它是索引换算出的自车局部世界坐标再归一);这就齐活了,流程就是基于这个query预测偏移和权重,然后在参考点附近找特征,然后结合权重输出新的query传入下面的空间交叉注意力模块。
空间交叉注意力模块
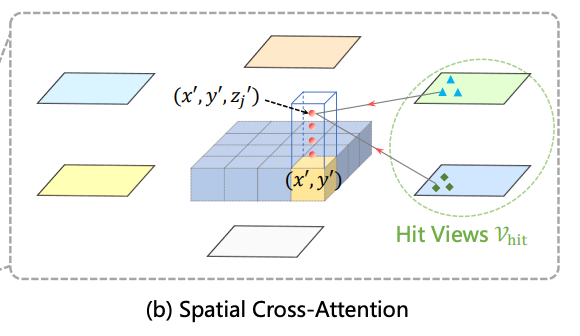
同样,我们先来明确一下这里面的QKV到底怎么对应。
Query就是上面时序自注意力模块输出的BEV Query;
KV 数据源:当前帧 6 路相机 2D 图像特征
(
F
t
)
(F_t)
(Ft)
这里为什么叫Cross-Attention了呢?就是因为他是在从图像提取的BEV特征里去查找信息的,(不同空间拓扑、不同维度特征图)。
好,我们也能带入Deformable Attention框架,有个query,有个BEV特征,还有个参考点,这里的参考点获取就不一样了,这里可以根据相机的内外参从BEV空间投影到图像坐标系了;这就又齐活了,流程就是基于这个query预测偏移和权重,然后在参考点附近找特征,然后结合权重输出新的query传入下一层。
结语
好了,BEVFormer整体架构就简单理解完了,其实就是三块,一个是backbone提图像特征,然后就是时序自注意力机制获得当前时刻BEV空间栅格里的query,然后在基于这个query去每个图像提取的特征中去做空间交叉注意力,然后反复串联6次输出最后新的query当作当前帧的BEV query!




















 1546
1546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












