




 本文探讨了为何HBase需要二级索引,详细解释了二级索引的原理,包括基于Coprocessor的Phoenix方案和非Coprocessor方案如ES方案。二级索引通过建立列值与行键映射,提升非rowkey字段查询效率,同时介绍了设计二级索引的考虑因素和优化策略。
本文探讨了为何HBase需要二级索引,详细解释了二级索引的原理,包括基于Coprocessor的Phoenix方案和非Coprocessor方案如ES方案。二级索引通过建立列值与行键映射,提升非rowkey字段查询效率,同时介绍了设计二级索引的考虑因素和优化策略。
为何需要HBase索引?
HBase里面只有rowkey作为一级索引, 如果要对库里的非rowkey字段进行数据检索和查询, 往往要通过MapReduce/Spark等分布式计算框架进行,硬件资源消耗和时间延迟都会比较高。
为了HBase的数据查询更高效、适应更多的场景, 诸如使用非rowkey字段检索也能做到秒级响应,或者支持各个字段进行模糊查询和多字段组合查询等, 因此需要在HBase上面构建二级索引, 以满足现实中更复杂多样的业务需求。
二级索与原理是什么?

二级索引的本质就是建立各列值与行键之间的映射关系
如(图1),当要对F:C1这列建立索引时,只需要建立F:C1各列值到其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询符合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值,图1青色部分)
其查询步骤如下:
- 根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1
- 得到RK1后就自然能根据RK1来查询C2的值了 这是构建二级索引大概思路,其他组合查询的联合索引的建立也类似。
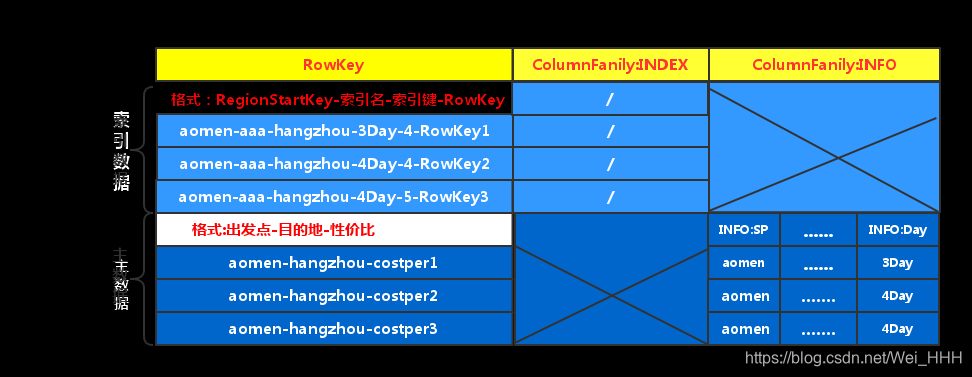 (图2) 部分数据在HBase中存储的逻辑视图
(图2) 部分数据在HBase中存储的逻辑视图
表中有两个列族,其中一个是列族INDEX,其并不存储任何的数据,仅仅是为了将索引数据与主数据分开存储(因为在HBase中同一列族的数据会被压缩在一起存储),索引数据的行键格式为:RegionStartKey-索引名-索引键-Rowkwy,其他RegionSt



















二级索引&spm=1001.2101.3001.5002&articleId=113003729&d=1&t=3&u=79afe0d6bafc47139c6148dd2f08d5b9)
 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










