



 本文详细介绍了如何使用Apache Flume将日志数据采集并发送到Kafka中,通过配置实现数据源到多个主题的分发。展示了具体的Flume配置参数及Kafka消费者消费情况。
本文详细介绍了如何使用Apache Flume将日志数据采集并发送到Kafka中,通过配置实现数据源到多个主题的分发。展示了具体的Flume配置参数及Kafka消费者消费情况。
1 官网内容
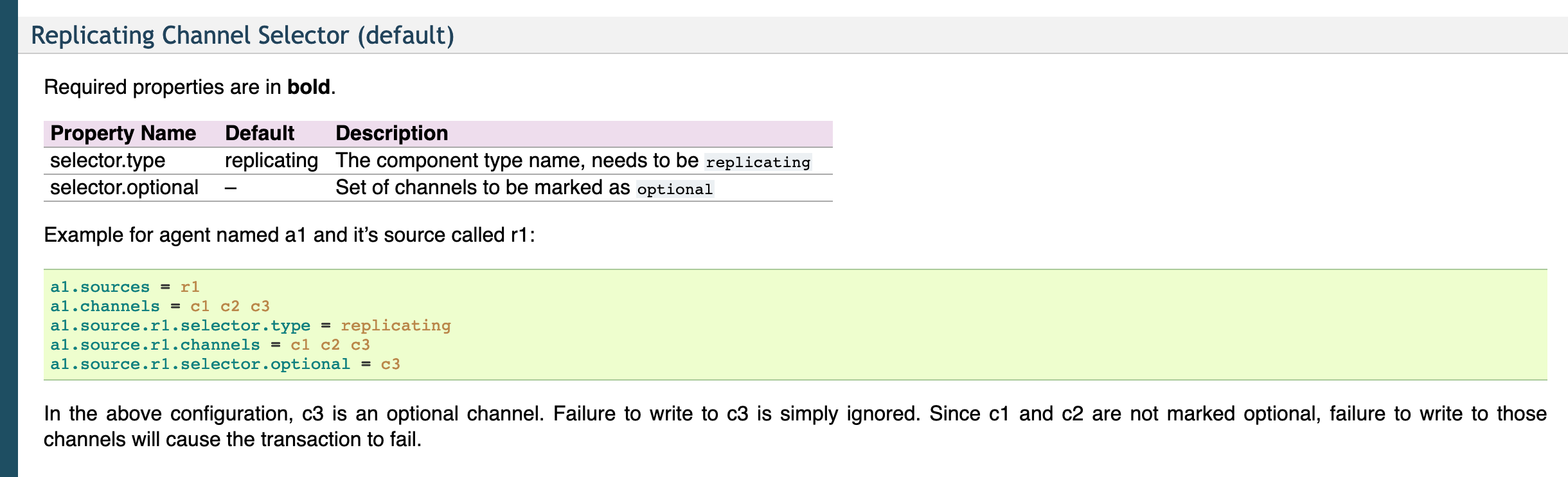
上面的配置是r1获取到的内容会同时复制到c1 c2 c3 三个channel里面
2 详细配置信息
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /tmp/logs/cmcc.log
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = cmcc1
a1.sinks.k1.brokerList = hdp1:9092,hdp2:9092,hdp3:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.topic = cmcc2
a1.sinks.k2.brokerList = hdp1:9092,hdp2:9092,hdp3:9092
a1.sinks.k2.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.topic = cmcc2
a1.sinks.k2.brokerList = hdp1:9092,hdp2:9092,hdp3:9092
a1.sinks.k2.requiredAcks = 1
a1.sinks.k2.batchSize = 20
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /tmp/flume/checkpoint
a1.channels.c2.dataDirs = /tmp/flume/data
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
# set channel for sinks
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
# #
a1.sources.r1.selector.type = replicating
#
3 查看消费情况
topic cmcc1的消费情况
kafka-console-consumer.sh --zookeeper hdp1:2181,hdp2:2181,hdp3:2181/kafka1.1.0 --topic cmcc1 --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
hello
world
java
scala
hadoop
zhangjin
xxxx
yyyy
hello
world
java
scala
hadoop
zhangjin
xxxx
yyyy
hello
world
java
scala
hadoop
zhangjin
xxxx
yyyy
zhangjin
xxxx
yyyy
topic cmcc2的消费情况
/tmp/logs]#kafka-console-consumer.sh --zookeeper hdp1:2181,hdp2:2181,hdp3:2181/kafka1.1.0 --topic cmcc2 --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
hello
world
java
scala
hadoop
zhangjin
xxxx
yyyy
hello
world
java
scala
hadoop
zhangjin
xxxx
yyyy
hello
world
java
scala
hadoop
zhangjin
xxxx
yyyy
hello
world
java
scala
hadoop
zhangjin
xxxx
yyyy
hello
world
java
scala
hadoop
zhangjin
xxxx
yyyy
zhangjin
xxxx
yyyy
4 查看tail的文件内容
hello
world
java
scala
hadoop
zhangjin
xxxx
yyyy
zhangjin
xxxx
yyyy
4 总结
应该是启动了两次的原因,实际上是把文件重复两次的发送到了每个sink里面,实现了实验要求



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










