



 本文介绍了阿里搜索广告团队提出的一种新型粗排模型,该模型结合IF结构和FSCD特征选择方法,实现了在不牺牲效果的情况下提高系统效率。通过在阿里巴巴搜索直通车的广告场景实验,该方法在不增加额外在线计算资源的情况下,显著提升了在线效果。FSCD方法通过考虑特征复杂度和效率,实现了粗排模型的特征选择,提高了模型表达能力。
本文介绍了阿里搜索广告团队提出的一种新型粗排模型,该模型结合IF结构和FSCD特征选择方法,实现了在不牺牲效果的情况下提高系统效率。通过在阿里巴巴搜索直通车的广告场景实验,该方法在不增加额外在线计算资源的情况下,显著提升了在线效果。FSCD方法通过考虑特征复杂度和效率,实现了粗排模型的特征选择,提高了模型表达能力。
欢迎关注:阿里妈妈技术公众号
本文作者:炽兔 阿里妈妈技术团队
0 摘要
实际的搜索、推荐和广告系统中经常采用多阶段排序架构,包括召回、粗排、精排、重排等阶段。在粗排阶段,为了保证系统的效率,经常采用基于表征式(representation-focused, RF)结构的向量点积模型,这往往会对系统效果造成一定的损失。阿里搜索广告rank算法团队提出了一种新的粗排方法,可以支持复杂的交互式(interaction-focused, IF)结构,且采用提出的特征选择方法(FSCD)实现了效率和效果的更好均衡。在阿里巴巴搜索直通车的实际广告场景的实验显示,相比于传统方法,采用提出的粗排模型后系统在不增加额外在线计算资源的情况下获得了明显的效果提升。本工作已在阿里搜索广告全量上线,为阿里巴巴集团带来了显著的收益;同时工作撰写的论文也已经被SIGIR2021接收。
1 介绍
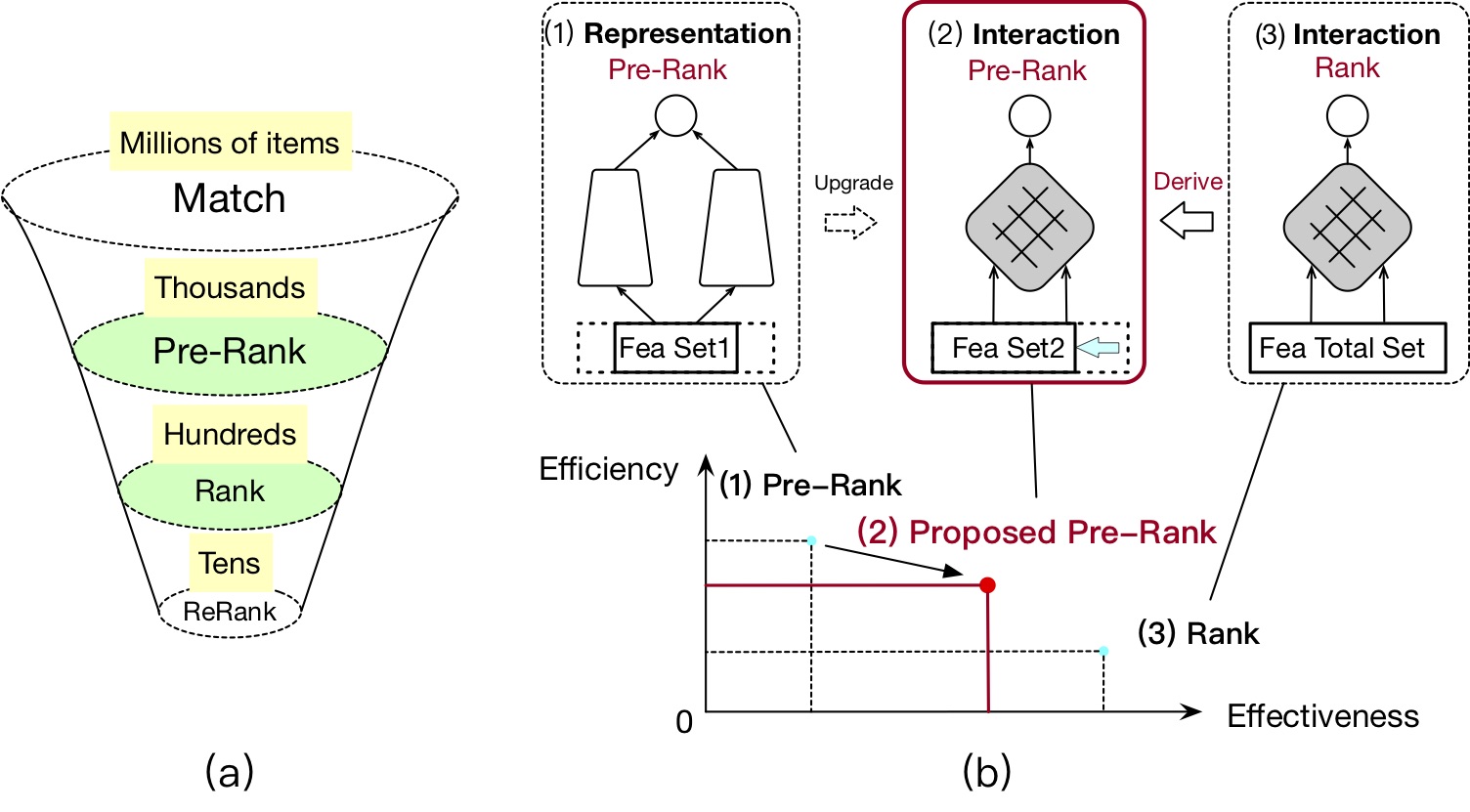
大规模的搜索引擎和推荐系统对人们日常生活中的信息搜索和推荐起到了十分重要的作用,这些系统从数以千万或亿计的大量候选中为用户挑选了合适的内容,从而满足了用户对信息的需求。在超低时延的约束下,系统不可能布设单一的复杂模型为每一个候选进行打分和排序,而通常采用多阶段的排序架构。以阿里搜索广告为例,多阶段架构通常包括召回、粗排、精排、重排等阶段(详见图1a)。在多阶段架构中,精排模型通常采用具有IF结构的大规模深度神经网络(DNN),而为了保证系统效率,粗排模型往往采用具有RF结构的简单模型。
然而,具有RF结构的简单粗排模型会存在表达能力受限的问题。目前工业界的粗排模型通常采用基于向量点积的双塔模型,它是一种典型的RF结构(详见图1b),优点是在线复杂度低,可以实现多个内容的打分,但缺点也很明显:缺少显式的内容侧交叉特征和隐式的交叉语义信息,而这些信息对效果的提升有很大的助力。具有RF结构的粗排模型过于关注效率的优化,与IF结构的模型效果差距非常大。在实际在线服务过程中,以阿里搜索广告为例,特征的生成和模型推断几乎各占用了一半的在线时延,因此同时考虑效率和效果来进行粗排模型的特征选择可以显著改善在线效率,从而为基于IF结构的粗排模型提供了可能。
我们提出了一种效率和效果均衡的粗排方案,在粗排模型效率微降的基础上大幅度增长模型效果,详见图1b。本工作的贡献主要有:1.通过继承精排模型结构,粗排阶段成功采用了IF结构的模型,解决了RF结构的效果不足的问题;2.提出了一种基于特征复杂度和variational dropout的可学习特征选择方法(FSCD),可以学到一组效率和效果都优越的特征集合提供给粗排模型进行训练;3.实验结果显示,采用提出的粗排模型后,整个系统在效率持平的情况下获得了显著的在线效果提升。本方法已经在阿里搜索广告业务中全量上线,并获得了稳定的在线收益。
2 提出的方法
我们提出的粗排模型是从精排模型中衍生而来的。两个模型都采用了IF结构,且共享了一组特征集合 S = { f 1 , f 2 , . . . , f M } S = \{f_1, f_2, ..., f_{M}\} S={f1,f2,...,fM},其中 f j f_j fj是 S S S中的第 j j j个特征域, M M M是特征域的个数。在阿里搜索广告的系统中,精排模型采用了 S S S中的所有的特征域来保证线上效果的最优;粗排模型则采用 S S S的特征域子集来减少在线的计算复杂度以及对更多的广告进行打分。将IF结构引入粗排模型的最大障碍是模型效率。模型可学习的参数通常可以包括特征embedding v \pmb{v} vvv和网络权重 w \pmb{w} www,而粗排模型的复杂度主要受embedding v \pmb{v} vvv的影响,因此选取既有效果又有效率的特征是粗排模型能够应用IF结构的关键。
2.1 粗排模型的FSCD方法
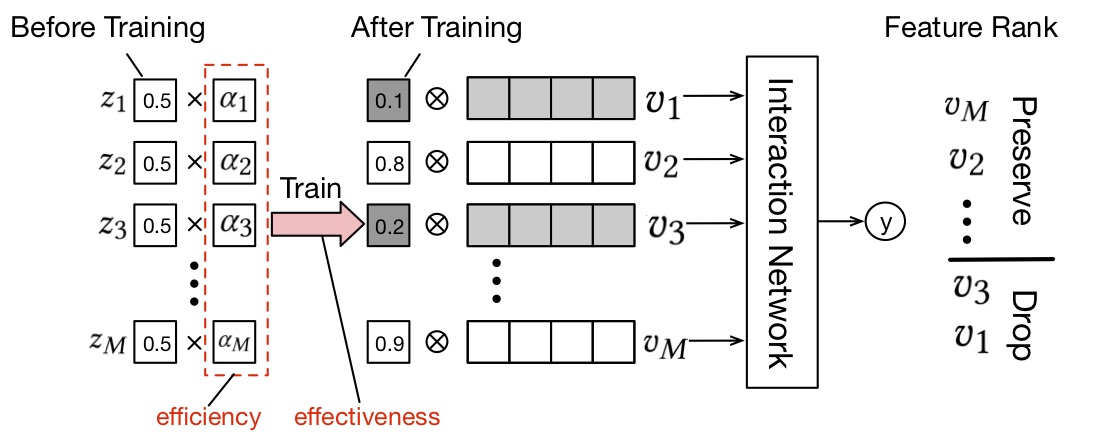
受到传统的Dropout FR方法的启发,我们提出了特征选择的FSCD方法来同时考虑特征的效率和效果,具体流程可见图2。在提出的FSCD方法中,特征的效果通过损失函数的交叉熵来进行优化,同时特征的效率通过特征维度的正则化来进行保证。FSCD方法可以通过一次端到端的训练来提取既有效果又有效率的特征集合。因此,应用这个特征集合的粗排模型的表达能力相比于基线模型可以获得显著增强。具体的推导过程如下。
为了选择出既有效果又有效率的特征集合,我们希望给每一个特征域
f
j
f_j
fj都设置一个可学习的抛弃(dropout)因子
z
j
∈
{
0
,
1
}
z_j \in \{0, 1\}
zj∈{0,1},以此来表示特征被抛弃(
z
j
=
0
z_j=0
zj=0)或者被保留(
z
j
=
1
z_j=1
zj=1)。
f
j
f_j
fj的embedding向量
v
j
v_j
vj会乘以
z
j
z_j
zj来组成新的embedding层。因子
z
j
z_j
zj满足参数为
θ
j
\theta_j
θj的伯努利分布,即
z
j
∼
B
e
r
n
(
θ
j
)
,
z_j \sim Bern(\theta_j),
zj∼Bern(θj),
其中超参
θ
j
\theta_j
θj是特征域
f
j
f_j
fj获得保留的先验概率,建模为特征复杂度
c
j
c_j
cj的函数:
θ
j
=
H
(
c
j
)
=
1
−
σ
(
c
j
)
,
c
j
=
G
(
o
j
,
e
j
,
n
j
)
\theta_j = \mathcal{H}(c_j) = 1 - \sigma (c_j), \\ c_j = \mathcal{G}(o_j, e_j, n_j)
θj=H(cj)=1−σ(cj),cj=G(oj,ej,nj)
其中
σ
(
⋅
)
\sigma(\cdot)
σ(⋅)是sigmoid函数。
θ
j
=
1
−
σ
(
c
j
)
\theta_j = 1 - \sigma (c_j)
θj=1−σ(cj)是建模
θ
j
\theta_j
θj和
c
j
c_j
cj的一种方式,在实际应用中表现不错。特征复杂度
c
j
c_j
cj衡量第
j
j
j个特征的存储和计算复杂度,包括但不限于在线计算复杂度
o
j
o_j
oj、embedding维度
e
j
e_j
ej、embedding取值的个数
n
j
n_j
nj等等。
o
j
o_j
oj会根据特征类型来进行设置(详见3.1节)。线性组合
c
j
=
γ
1
o
j
+
γ
2
e
j
+
γ
3
n
j
c_j = \gamma_1 o_j + \gamma_2 e_j + \gamma_3 n_j
cj=γ1oj+γ2ej+γ3nj是实现函数
G
\mathcal{G}
G的一种可行的方式,同时需要考虑超参
γ
1
,
2
,
3
\gamma_{1,2,3}
γ1,2,3的设置。根据上述公式可知,具有较高复杂度的特征会拥有较小的保留先验概率
θ
j
\theta_j
θj,反之亦然。
给定训练样本
D
=
{
(
x
i
,
y
i
)
∣
i
=
1
,
2
,
.
.
.
,
N
}
\mathcal{D}= \{(x_i, y_i) |i = 1,2,...,N \}
D={(xi,yi)∣i=1,2,...,N},其中
N
N
N是样本总数,可学习的特征选择损失函数为
L
(
v
,
w
,
z
)
=
−
1
N
l
o
g
P
(
D
∣
v
,
w
,
z
)
+
λ
N
(
∣
∣
w
∣
∣
2
+
∣
∣
v
∣
∣
2
)
+
∑
j
=
1
M
α
j
z
j
N
,
L(\pmb{v}, \!\pmb{w},\! \pmb{z}) \!=\! -\frac{1}{N}logP(\mathcal{D}|\pmb{v}, \pmb{w},\pmb{z}) \!+\! \!\frac{\lambda}{N} \!\!( \!||\pmb{w}||^2 \!\!+\! \! ||\pmb{v}||^2) \!+\!\! \sum_{j=1}^{M} \frac{\alpha_j z_j}{N},
L(vvv,www,zzz)=−N1logP(D∣vvv,www,zzz)+Nλ(∣∣www∣∣2+∣∣vvv∣∣2)+j=1∑MNαjzj,
其中
α
j
\alpha_j
αj是
z
j
z_j
zj的正则化权重,可以写作(详细推导过程见原文附录)
α
j
=
l
o
g
(
1
−
θ
j
)
−
l
o
g
(
θ
j
)
.
\alpha_j = log(1-\theta_j)- log(\theta_j).
αj=log(1−θj)−log(θj).
α
j
\alpha_j
αj是
θ
j
\theta_j
θj的减函数,是
c
j
c_j
cj的增函数。因此,具有较大复杂度
c
j
c_j
cj的特征在训练中会受到较大的惩罚
α
j
\alpha_j
αj,因此有更大的可能被舍弃掉。通过这种方式,FSCD方法引入了特征复杂度的建模,具笔者所知,这是传统特征选择方法所不具备的。
由于
z
j
z_j
zj满足伯努利分布,因此它是离散且不可导的,这与基于梯度下降的训练过程相违背。为了解决这个问题,伯努利分布被松弛成如下的可导函数
z
j
=
F
(
δ
j
)
=
σ
(
1
t
(
l
o
g
(
δ
j
)
−
l
o
g
(
1
−
δ
j
)
+
l
o
g
(
u
j
)
−
l
o
g
(
1
−
u
j
)
)
)
,
z_j \!= \!\mathcal{F}(\delta_j) \! = \!\sigma(\!\frac{1}{t}\!(\!log(\delta_j)-log(\!1-\delta_j\!)+log(u_j)-log(\!1-u_j\!)\!)\!),
zj=F(δj)=σ(t1(log(δj)−log(1−δj)+log(uj)−log(1−uj))),
其中
u
j
∼
U
n
i
f
o
r
m
(
0
,
1
)
u_j \sim Uniform(0,1)
uj∼Uniform(0,1)满足0-1之间的均匀分布,在训练过程中始终是随机变化的,
t
=
0.1
t=0.1
t=0.1是常数,且在阿里搜索广告的实验中表现很好。对于绝大多数的
δ
j
\delta_j
δj,
F
(
δ
j
)
\mathcal{F}(\delta_j)
F(δj)都是接近于0或1的,因此可以作为伯努利分布的连续函数近似。相比于保留先验概率
θ
j
\theta_j
θj,
δ
j
\delta_j
δj扮演了保留后验概率的角色,因此可以作为特征重要性被模型学习出来。
以上就是FSCD的特征选择方法,主要的可学习的变量有 v \pmb{v} vvv, w \pmb{w} www和 δ \pmb{\delta} δδδ,它们在训练中会同步更新。在 δ \pmb{\delta} δδδ达到收敛之后,粗排模型的特征子集就可以按照 δ j \delta_j δj从大到小进行选取。
2.2 粗排模型的微调
在完成FSCD方法的特征选择之后,不在粗排特征集合中的特征会被抛弃,粗排模型会基于FSCD方法的
v
\pmb{v}
vvv和
w
\pmb{w}
www参数进行模型初始化,从而进行微调。具体地,粗排模型会基于如下的损失函数进行训练
L
(
v
′
,
w
′
)
=
−
∑
i
=
1
N
l
o
g
p
(
y
i
∣
f
(
x
i
′
,
v
′
,
w
′
)
)
,
L(\pmb{v}',\pmb{w}') = -\sum_{i=1}^{N}logp(y_i|f(x_i', \pmb{v}', \pmb{w}')),
L(vvv′,www′)=−i=1∑Nlogp(yi∣f(xi′,vvv′,www′)),
其中
x
i
′
x_i'
xi′是包含选取特征的样本,
v
′
\pmb{v}'
vvv′和
w
′
\pmb{w}'
www′分别是选取特征相关的embedding和网络权重。
v
′
\pmb{v}'
vvv′和
w
′
\pmb{w}'
www′由
v
\pmb{v}
vvv和
w
\pmb{w}
www进行初始化,可以加速粗排模型的收敛。伯努利因子
z
\pmb{z}
zzz仅在FSCD方法中使用,而在微调过程中不再考虑。
2.3 资源复用
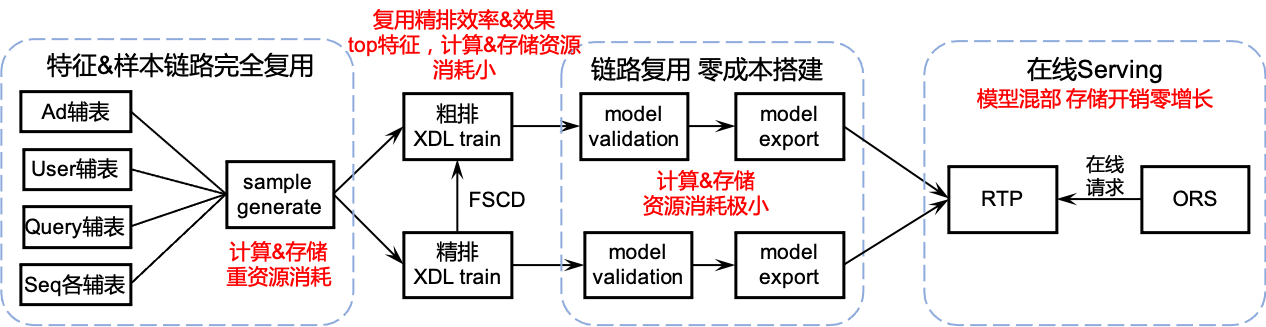
图3给出了提出的粗排模型应用于阿里搜索广告架构后的资源复用情况。由于粗排模型的特征集合是精排模型特征集合的子集,因此粗排模型的样本链路可以完全复用精排模型,无须重新生产样本,节省了大量的离线样本生成的资源。对于模型训练,粗排和精排相互独立,而由于粗排模型特征量远小于精排模型,因此训练资源的消耗也显著低于精排。对于模型校验和产出,粗排模型可以完全复用精排模型产出链路,做到零成本搭建链路。在线服务阶段采用阿里集团的RTP的打分服务,粗排模型由于体积小,可以和精排模型混部在同一个在线分组当中,无需额外存储设备,存储开销增长接近于零。综上,提出的粗排模型在离线样本产出、模型训练、模型产出、在线服务等阶段都最大程度地复用精排模型链路,整个架构呈现存储零新增、计算微增长,以及搭建成本低的特点。
3 实验
3.1 实验配置
我们的实验主要基于阿里搜索广告的在线系统。作为按照点击计费(CPC)的广告系统,阿里搜索广告主要致力于在不损失用户体验的基础上帮助广告主获取流量,同时提升平台的收入。因此主要的在线优化指标包括点击率(CTR)和千次展现的收益(RPM)。我们提出的粗排模型在实验中的基线是传统的基于向量乘积的双塔模型。在真实系统中,双塔结构上移至检索系统内部完成本地初选,粗排升级为提出的基于FSCD的IF结构模型。
粗排模型的特征集合是精排模型特征集合的子集,这是通过提出的FSCD来实现的。实验中的整体特征集合包含246个不同的特征域,根据其在线性能会分成不同的特征类型,且 o j o_j oj 的值主要受上述特征类型决定,详见表1。对于其它超参,我们采用 γ 1 = 1 \gamma_1 = 1 γ1=1, γ 2 = 1 0 − 2 \gamma_2 = 10^{-2} γ2=10−2以及 γ 3 = 1 0 − 7 \gamma_3 = 10^{-7} γ3=10−7。
| 特征类型编号 | 特征类型 | o j o_j oj |
|---|---|---|
| I | 可以直接查询embedding的简单user/query侧特征 | 0.4 |
| II | 可以直接查询embedding的简单item相关特征 | 1.5 |
| III | 需要一定计算才能获得embedding的复杂user/query侧特征 | 1.0 |
| IV | 需要一定计算才能获得embedding的复杂item相关特征 | 3.0 |
表1 特征集合中不同的特征类型以及相应的 o j o_j oj值
3.2 FSCD方法的分析
特征域会按照FSCD方法获得的 δ \pmb{\delta} δδδ进行排序。表2给出了各种特征类型在排序中的最小值、中位数以及最大值,同时对传统的Dropout FR方法、DFS方法也做了比较。由于考虑了特征的复杂度,FSCD方法在简单特征的位序要比复杂特征明显更加靠前;另一方面,只要特征足够有效,复杂特征同样有机会排到相对靠前的位置。而对于传统的两种方法,特征位序与特征类型(特征复杂度)的相关性明显不足。
| 特征类型编号 | 特征域个数 | 位序最小值 | 位序中位数 | 位序最大值 |
|---|---|---|---|---|
| I | 141 | 1/2/1 | 129/137/85 | 244/246/156 |
| II | 5 | 15/31/18 | 36/44/42 | 99/52/159 |
| III | 68 | 3/1/4 | 137/131/185 | 246/243/231 |
| IV | 32 | 7/3/8 | 108/58/229 | 178/239/246 |
表2 不同特征类型的特征位序以及分布。不同方法的位序结果按照‘/’分隔,包括Drooout FR方法、DFS方法以及提出的FSCD方法。
为了分析特征域个数 K K K对效率和效果的影响,我们用阿里搜索广告的20亿样本训练了具有不同 K K K的粗排模型,在不同方法上分别选取前 K K K在效果和效率上的指标详见表3。结果显示,相比于传统方法,提出的FSCD方法在相同 K K K的情况下AUC略有下降。然而,在线的效率是有显著的提升的。综合考虑下,我们选取FSCD方法的前100个特征作为最终的粗排特征集合。
| K | 方法 | AUC | 延时(ms) | CPU利用率(%) |
|---|---|---|---|---|
| 30 | Droup FS | 0.6910 | 4.32 | 13.26 |
| 30 | DFS | 0.6765 | 4.64 | 15.47 |
| 30 | FSCD | 0.6903(-0.007) | 2.41(-44.2%) | 9.31(-29.7%) |
| 50 | Droup FS | 0.6946 | 5.75 | 20.55 |
| 50 | DFS | 0.6788 | 5.19 | 20.57 |
| 50 | FSCD | 0.6927(-0.0019) | 3.54(-31.7%) | 12.10(-41.1%) |
| 100 | Droup FS | 0.6975 | 6.48 | 30.82 |
| 100 | DFS | 0.6962 | 6.34 | 26.11 |
| 100 | FSCD | 0.6949(-0.0026) | 4.37(-31.0%) & | 19.18(-26.5%) |
| 150 | Droup FS | 0.6985 | 7.98 | 36.35 |
| 150 | DFS | 0.6972 | 7.85 | 35.41 |
| 150 | FSCD | 0.6958(-0.0027) | 4.74(-39.6%) | 21.47(-39.3%) |
| 200 | Droup FS | 0.6983 | 8.10 | 37.26 |
| 200 | DFS | 0.6981 | 8.04 | 36.94 |
| 200 | FSCD | 0.6971(-0.0010) | 6.91(-14.0%) | 30.09(-18.5%) |
| whole(246) | / | 0.6990 | 9.02 | 40.60 |
表3 不同特征选择方法选出的前 K K K个特征域训练模型的各项指标结果(包括离线AUC、在线延时以及CPU利用率)。每个模型都基于阿里搜索广告20亿样本训练得来。
3.3 总体结果比较
表4和表5展示了提出方法的离线和在线实验结果,对比基线为基于向量点积模型。为了获得最优的在线效果,每个模型都用阿里搜索广告约2000亿条真实样本训练而来,因此离线AUC绝对值比表3中的离线AUC要大很多。表4的结果显示,我们提出的粗排模型比基于向量点积的粗排模型有显著更好的效果。对于在线效果,表5展示了阿里搜索广告真实流量下连续30天的实验效果。结果显示,提出的方法达到了效率和效果的更好的均衡,使得CTR和RPM的效果都获得了显著的提升。由于采用了IF结构,提出的方法优于传统的基于向量点积模型。
在系统的效率方面,虽然我们采用了复杂的IF结构的粗排模型,但是提出的FSCD方法优化了计算复杂度,从而使得系统的整体复杂度得到控制。因此,在线的CPU使用率与采用基于向量点积模型的CPU利用率基本持平,系统总延时有微弱上升。表5展现了峰值QPS上的相关实验结果。
| 方法 | 召回率 | 离线AUC |
|---|---|---|
| 基于向量点积模型 | 88% | 0.695 |
| 提出的模型 | 95% | 0.737 |
表4 不同方法的离线结果。每个模型都基于阿里搜索广告约2000亿样本训练得来。
| 方法 | CTR | RPM | 排序总延时(ms) | CPU利用率(%) |
|---|---|---|---|---|
| 基于向量点积模型 | / | / | 58.4 | 79 |
| 提出的模型 | +1.54% | +2.76% | 59.9 | 79 |
表5 阿里搜索广告真实流量上采用不同方法的在线效率和效果
4 结论
为了解决搜索推荐系统中,RF结构粗排模型效果不足的问题,阿里搜索广告rank算法团队提出了基于效率和效果特征选择的IF结构粗排模型。提出的粗排模型从精排结果继承而来,通过FSCD方法获取了既有效果又有效率的特征子集。离线实验证明了FSCD方法的有效性,而阿里搜索广告真实流量下的离线和在线实验证明了本方法对系统的正向作用。提出的方法已经在阿里搜索广告中全量上线并稳定运行,为整个集团增加了显著的收入。
参考文献
[1] Chun-Hao Chang, Ladislav Rampasek, and Anna Goldenberg. Dropout feature ranking for deep learning models. arXiv preprint arXiv:1712.08645, 2017.
[2] Luke Gallagher, Ruey-Cheng Chen, Roi Blanco, and J Shane Culpepper. Joint optimization of cascade ranking models. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, pages 15–23, 2019.
[3] JiafengGuo,YixingFan,LiangPang,LiuYang,QingyaoAi,HamedZamani,Chen Wu, W Bruce Croft, and Xueqi Cheng. A deep look into neural ranking models for information retrieval. Information Processing & Management, 57(6):102067, 2020.
[4] Po-SenHuang,XiaodongHe,JianfengGao,LiDeng,AlexAcero,andLarryHeck. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management, pages 2333–2338, 2013.
[5] Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144, 2016.
[6] Yifeng Li, Chih-Yu Chen, and Wyeth W Wasserman. Deep feature selection: theory and application to identify enhancers and promoters. Journal of Compu- tational Biology, 23(5):322–336, 2016.
[7] Shichen Liu, Fei Xiao, Wenwu Ou, and Luo Si. Cascade ranking for operational e-commerce search. In Proceedings of the 23rd ACM SIGKDD International Con- ference on Knowledge Discovery and Data Mining, pages 1557–1565, 2017.
[8] Xun Liu, Wei Xue, Lei Xiao, and Bo Zhang. Pbodl: Parallel bayesian online deep learning for click-through rate prediction in tencent advertising system. arXiv preprint arXiv:1707.00802, 2017.
[9] Vikas C Raykar, Balaji Krishnapuram, and Shipeng Yu. Designing efficient cascaded classifiers: tradeoff between accuracy and cost. In Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 853–860, 2010.
[10] SteffenRendle,ChristophFreudenthaler,ZenoGantner,andLarsSchmidt-Thieme. Bpr: Bayesian personalized ranking from implicit feedback. arXiv preprint arXiv:1205.2618, 2012.
[11] JizheWang,PipeiHuang,HuanZhao,ZhiboZhang,BinqiangZhao,andDikLun Lee. Billion-scale commodity embedding for e-commerce recommendation in alibaba. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 839–848. ACM, 2018.
[12] Zhe Wang, Liqin Zhao, Biye Jiang, Guorui Zhou, Xiaoqiang Zhu, and Kun Gai. Cold: Towards the next generation of pre-ranking system. arXiv preprint arXiv:2007.16122, 2020.
[13] WenjinWu,GuojunLiu,HuiYe,ChenshuangZhang,TianshuWu,DaoruiXiao, Wei Lin, and Xiaoyu Zhu. Eenmf: An end-to-end neural matching framework for e-commerce sponsored search. arXiv preprint arXiv:1812.01190, 2018.



















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










