



在做简历上传功能时,我低估了一个场景:扫描件 PDF——用户从 scanner 或微信保存的 PDF,肉眼看正常,文本层却是空的。此时 pdf-parse 一类库几乎抽不出字,用户却认为「我上传没问题」。
下面是我们在线上用的 分层提取 + OCR 回退 思路,供同类文档上传场景参考。
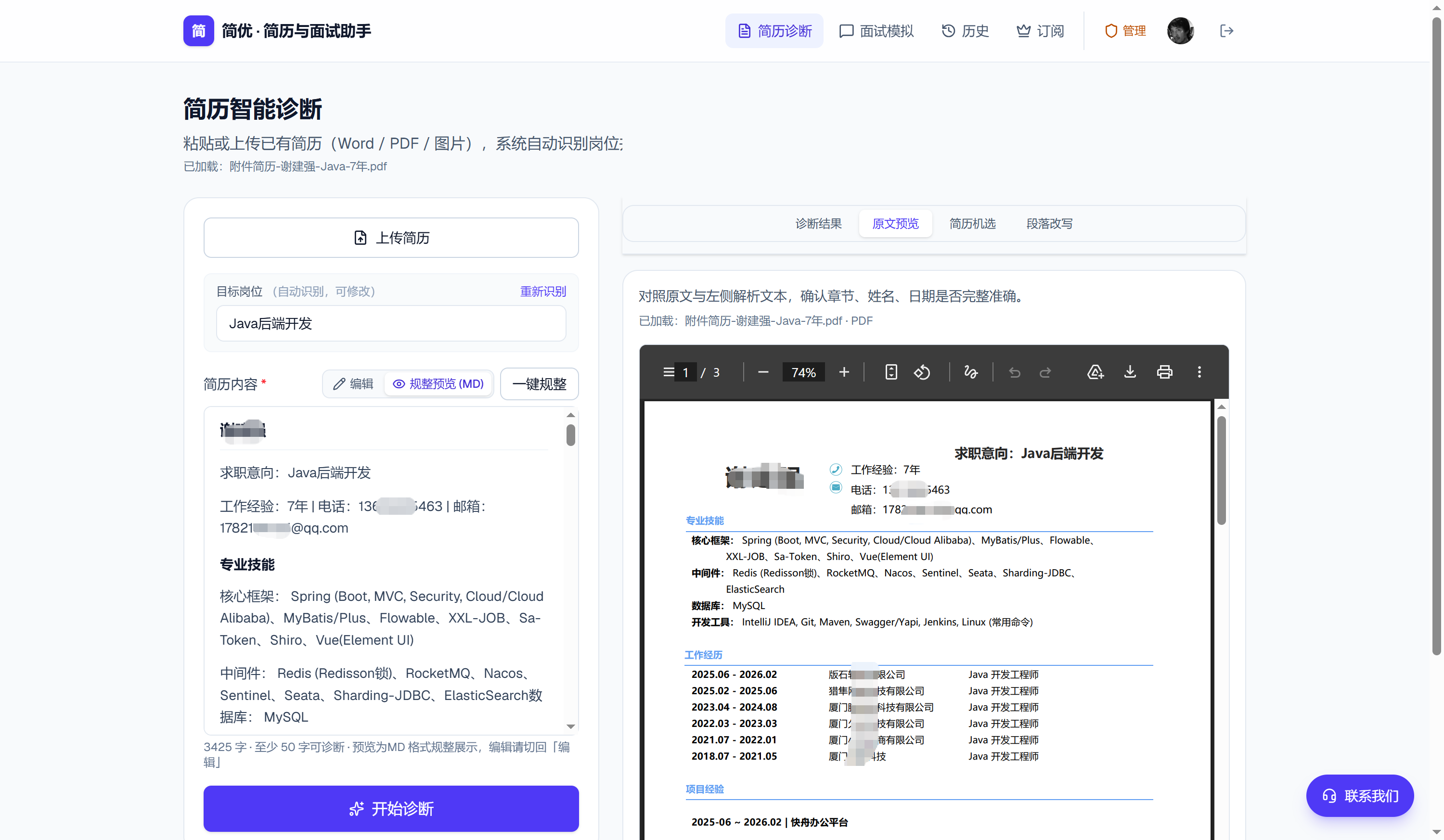
1. 先判断:有没有可提取的文本层?
流程第一步不是 OCR,而是 尽量便宜地拿文本:
- 优先 Poppler pdftotext(结构化参数:行阈值、单元格分隔)
- 回退 pdf-parse 多种提取模式
- 统计「有效字符数」(去空白后),低于阈值(如 80 字)→ 判定为扫描件
这样能避免对可复制 PDF 做昂贵的 OCR。
2. 扫描件:渲染 → OCR → 规整
判定为扫描件后:
PDF Buffer
→ pdftoppm / pdf-to-img(按页渲染,DPI 建议 300 左右)
→ 图像预处理(灰度、对比度、锐化、小图放大)
→ Tesseract(chi_sim+eng,PSM 3/11/6 择优)
→ 文本后处理(去乱码行、拆粘连章节)
→ 简历规整(章节换行、列表符、经历行)
→ 规则诊断 / AI 分析
PSM 说明(简版):
3:全自动分页,适合整页简历11:稀疏文本,适合 bullet 列表6:单块文本,部分模板反而更好
可对同一页跑多种 PSM,用 质量评分(有效字符比 + 章节词命中)选最优,而不是写死一种。
3. 工程踩坑(真实遇到过)
| 坑 | 现象 | 处理 |
|---|---|---|
| Docker 缺语言包 | OCR 全乱码 | 镜像预装 chi_sim、eng |
| 多页 OCR 超时 | 用户以为卡死 | 限最大页数 + 流式进度 |
| Nginx 60s 断连 | 上传到一半失败 | 调 proxy_read_timeout;OCR 阶段发 keepalive |
| 双栏 Word 模板 | 左栏技能与右栏经历串行 | 宽图分列 OCR + 后处理去噪(另文详述) |
| DPI 过低 | 小字号中文漏字 | 150 → 300,小图再放大 |
4. 进度与体验
OCR 单页可能 20~40 秒,整份 90 秒不罕见。不要只给一个 spinner。
我们采用 NDJSON 流式响应,步骤例如:extract → ocr → normalize → done,每步推送进度百分比与人话文案(「正在识别扫描版文字…」)。OCR 阶段长时间无业务输出时,额外发 心跳行,避免代理认为连接空闲而断开。
5. 代码结构(示意)
不必照搬,关键是 阶段可观测:
// 伪代码:上传解析入口
async function parseResumeDocument(buffer, fileName) {
onStep("extract");
const textLayer = await tryExtractText(buffer);
if (hasEnoughText(textLayer)) {
onStep("normalize");
return format(textLayer);
}
onStep("ocr");
const ocrText = await ocrPdfPages(buffer); // poppler render + tesseract
onStep("normalize");
return format(cleanupOcr(ocrText));
}
6. 结论
- 扫描 PDF 在中文求职场景里 不是边缘 case,是常态之一
- 后端要能 自动回退 OCR,并在 UI 上 让用户等得明白
- OCR 之后还要 规整 + 人工校对,尤其双栏模板
我们在产品 锦图简历 里按上述链路实现简历上传(Word / 可复制 PDF / 扫描 PDF / 图片)。若你也在做文档类 ToC 工具,欢迎评论区交流 Poppler 与 Tesseract 在容器里的打包方式。


















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










