



目前 AI 辅助编程里有两大难点:
1. 对第三方包的使用,大模型往往容易记忆错误,或者混淆版本,亦或者根本就不知道这个包的存在(语料太少)。
2. 无法很好的记忆和理解项目。
今天我们重点探讨的事第一个问题。首先,我们决定重写大量第三方库,比如我们开发了一套byzer-llm库,用于取代 langchain等编程库。不知不觉,我们已经在另外一个维度做AI辅助编程了
简单说下,为什么 langchain 之类的不适合大模型使用,而 byzer-llm 却适合大模型使用呢。 根子在于 langchain 是给设计的,需要大量“记忆”。 比如渲染一个 prompt, langchain定义了一个模块叫 PromptTemplate, 然后执行可能又定义了一个模块XXX, 这些都只能依靠“记忆”或者“文档”,但是因为这些模块的抽象层次都过高,导致实际上无论对人和对模型都有很大的负担,人只能查找每一个模块的完整使用例子才能使用,而大模型也要精准的记忆每一个模块。而一个langchain多大几百个甚至几千个模块。这对大模型几乎是不可能的事情。
而byzerllm 则没有这种几百个上千个只能靠记忆才会使用的模块,大模型只要理解一个概念即可完成prompt管理,和大模型沟通等能力:
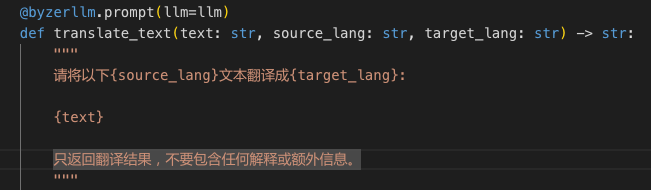
比如 tranlate_text 函数,你是可以直接执行的,执行的代码就是doc_string, doc里面是jinjia 2语法,参数会渲染doc,然后大模型执行这些渲染后的doc 然后返回结果。基本几句话就能说清楚,你说清楚了,大模型就会使用。
最后就是,无论我们的包是否是专门给大模型开发方便大模型使用的,还是已经存在的第三方包,或者语言,我们提供了一个统一的路口,方便用户使用,也就是LLM 友好包机制。
当你要使用某个库/包或者语言的时候,可以勾选上。接下来,我们会提供两个示例用来演示如何使用 auto-coder.web 的 LLM 包友好机制。
auto-coder.web 开发 moonbit
moonbit 是国内的一个具有后发优势的编程语言项目,目前发展迅速。我们通过包友好机制内置了对应的支持。我们来一起看下开发流程。
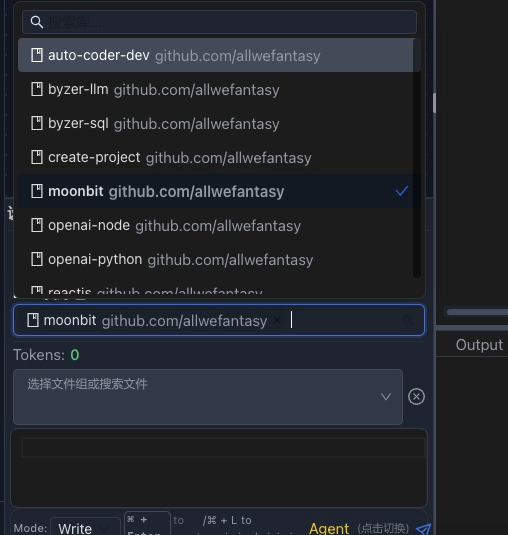
在聊天面板中选择LLM友好包:
在下拉框中选择 moonbit
选择编码模型。我们先点选
然后在下拉框中选择 sonnet 4:
现在我们可以正式开始开发了,去创建一个moonbit 项目:
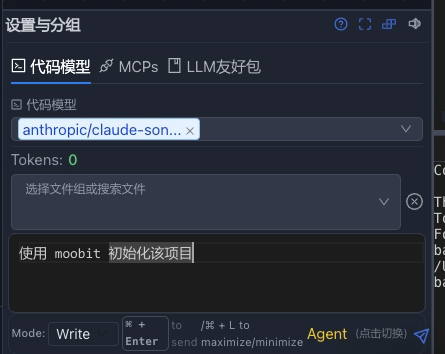
接着系统会自动下载,安装 moobit ,并且初始化项目,并且运行编译和测试代码。用户基本可以零基础,不看文档即可开发和使用moonbit 应用。
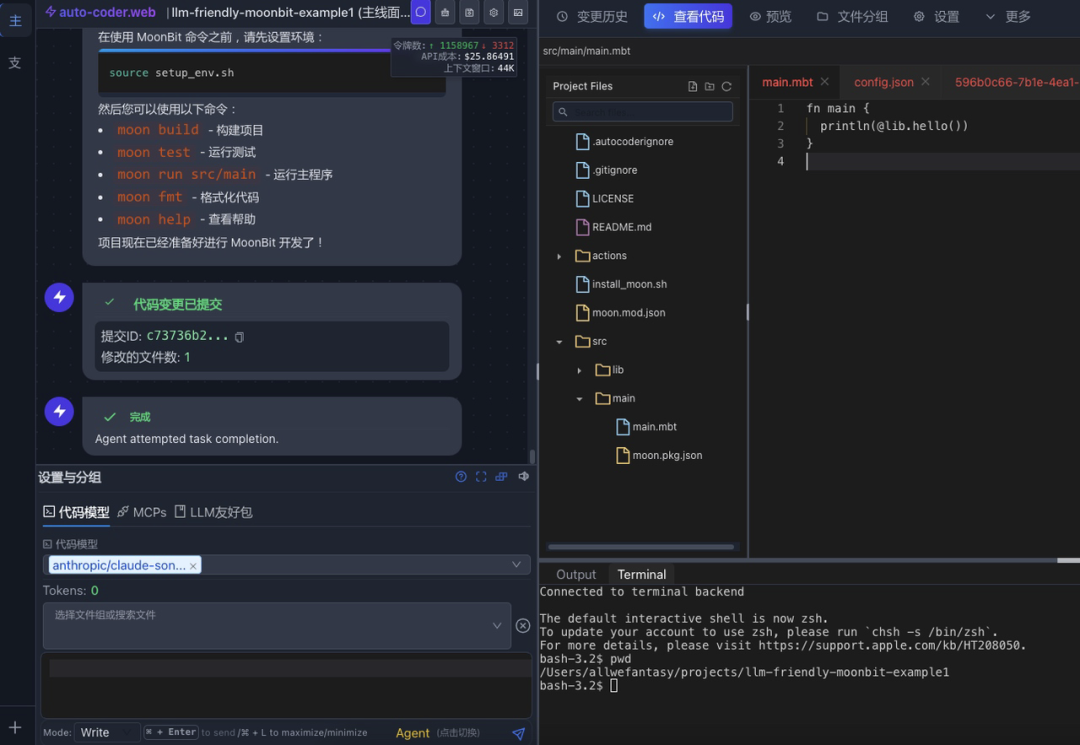
完整案例详情可以访问: https://uelng8wukz.feishu.cn/wiki/Jnhjwn0ojivc2Dk2xtxc1di4nwd?fromScene=spaceOverview
接着我们来看如何开发一个基于大模型的类Google翻译服务。操作和前面一致:
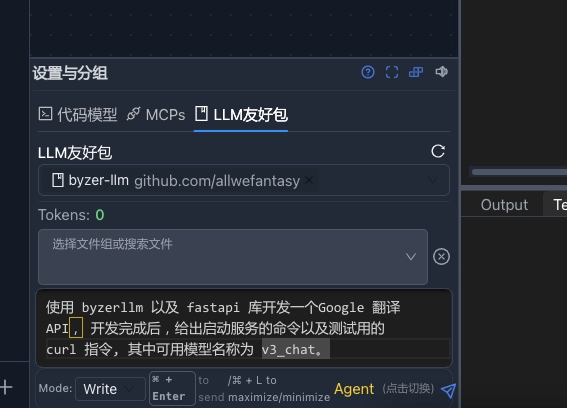
我们使用的是 v3-0324,等一会就开发完成:
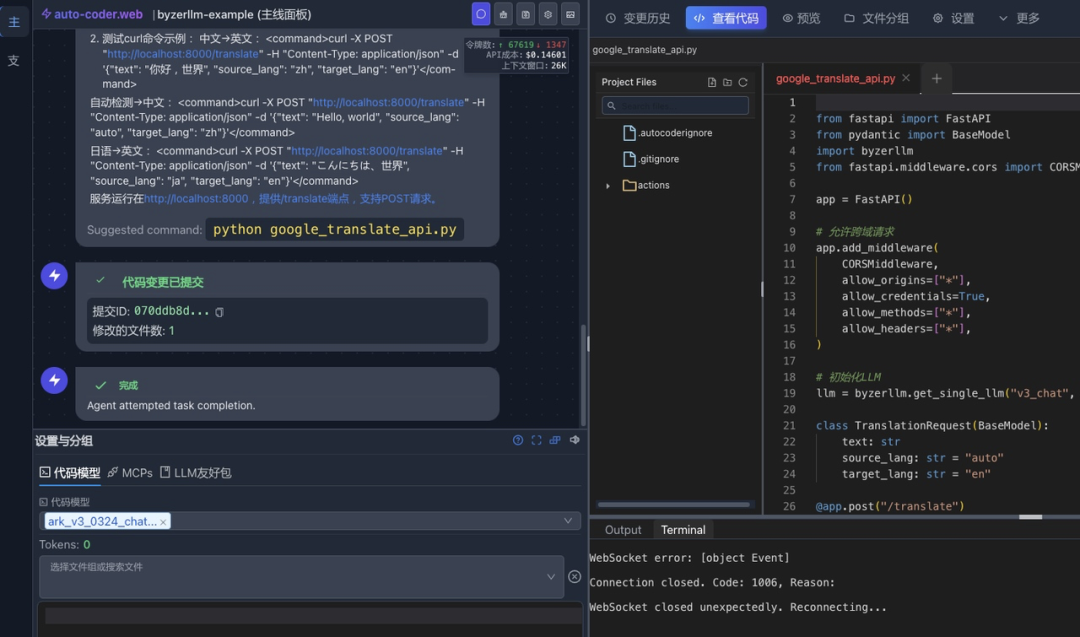
现在可以启动开发的 Google 翻译服务API:
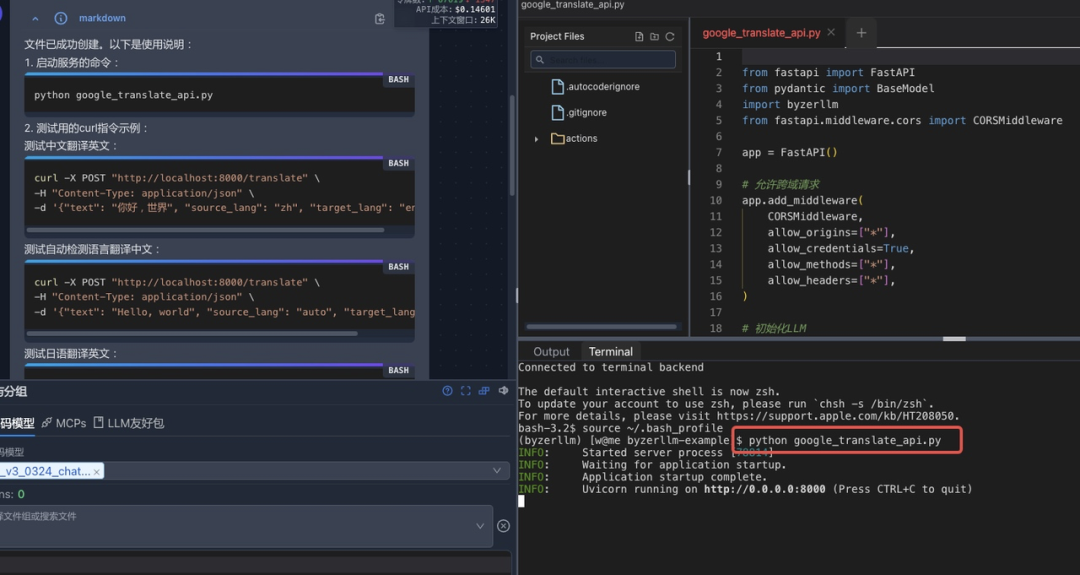
运行测试命令:
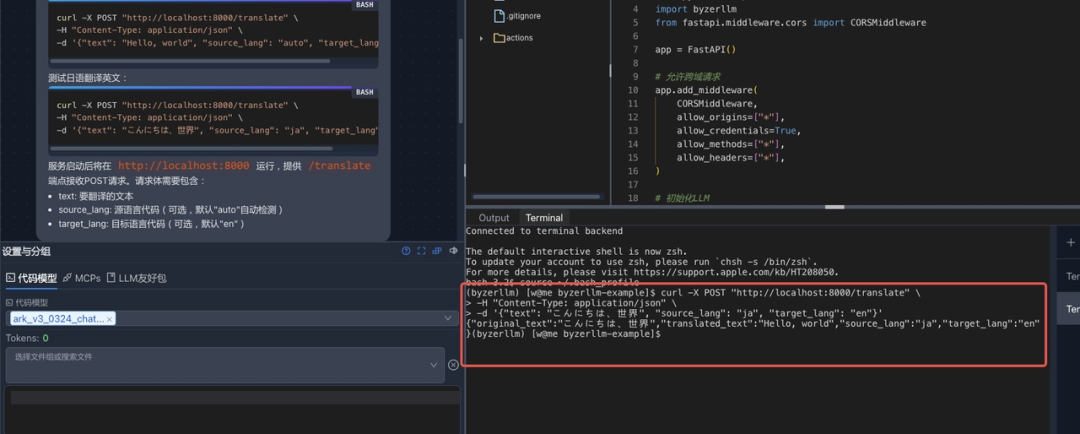
完美。用户几乎零基础就可以开发一个基于大模型的应用,不要写prompt,不需要关注应用如何和大模型交互。
详细开发流程以及结果可以查看:
https://uelng8wukz.feishu.cn/wiki/Z8qjwLuREig1ywkgmJFc8cJ9nrh?fromScene=spaceOverview
最后,你也可以把自己的新项目提交到 auto-coder 社区的 LLM友好包项目里。具体参看:
https://uelng8wukz.feishu.cn/wiki/CP5pwpxTSipiIOkJPwPcTWBFnHe?fromScene=spaceOverview
你也可以点击原文链接获得更多信息。

















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










