

文章目录
1.测试目标
Doirs官方提供了使用JDBC插入数据的性能测试结果,该测试使用了TPC-H的LINEITEM表作为数据集,使用DataX的txtfilereader读取文本类型的数据集并通过mysqlwriter将数据集写入Doris。以下将实现此测试过程,实际检验Doris在服务器上的插入性能。整理内容包括使用TPC-H工具生成测试所需数据集的方法,DataX的配置及使用方法,最终完成测试。
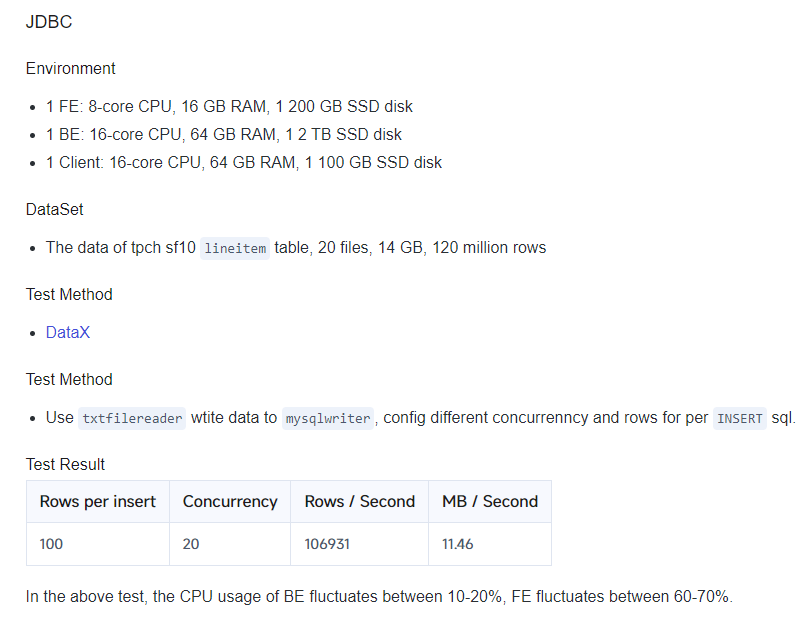
Doris官方提供的性能测试结果
名词解释
-
tpch:TPC的全称是Transaction Processing Performance Council,即事务处理性能委员会。是一个非盈利性组织,致力于开发以数据为中心的基准程序标准规范,并向行业提供客观、可验证的数据,用以评估和比较不同系统的性能。TPC制定了多种基准测试标准,TPC-E是其中的一种,它的数据库设计由8张表组成。
-
sf10:sf是Scale Factor的简写,默认为1。其作用以LINEITEM表的行数举例来说,待生成数据集的目标行数等于SF*6,000,000,sf10则代表将生成6000万行数据。此参数也可理解为生成指定数量GB的数据集,sf10则代表TPC-H的8张数据表,它们待生成的数据集文件总占用磁盘空间为10GB。sf后跟的数值官方文档上是有要求的(如下截图),但实测不按其要求单独使用LINEITEM表也可正常生成数据。

-
lineitem:TPC-H测试共提供了8张数据表,LINEITEM表是其中一张,共有16个字段,后面会有建表语句。
-
20 files:TPC-H工具生成的单表数据集是可以拆分的,通过TPC-H生成了20个拆分好的LINEITEM数据集。用于DataX并发读取。
-
14G:总数据集的磁盘占用数,当sf指定为1时,实测LINEITEM约占空间700多M,14G是sf20生成的数据集大小。
-
120 million rows:当sf指定为1时,LINEITEM约有600万行,1.2亿行是sf20生成的数据集大约行数。
-
DataX:是阿里云DataWorks数据集成的开源版本,实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
2.使用TPC-H工具准备数据集
2.1.下载
访问地址:https://www.tpc.org/tpc_documents_current_versions/current_specifications5.asp
选择TPC-H对应的Source Code进行下载,当前下载的版本是V3.0.1。
下载的压缩包解压后,可在解压根目录中找到说明书"specification.pdf"文件。
2.2.安装
进入解压根目录后执行如下操作
# TPC-H默认的数据库选项中没有MySQL,需进行补充
$ vi dbgen/tpcd.h
# 加入如下内容
#ifdef MYSQL
#define GEN_QUERY_PLAN ""
#define START_TRAN "START TRANSACTION"
#define END_TRAN "COMMIT"
#define SET_OUTPUT ""
#define SET_ROWCOUNT "limit %d;\n"
#define SET_DBASE "use %s;\n"
#endif
# 将makefile.suite复制为makefile
$ cp dbgen/makefile.suite dbgen/makefile
# 修改makefile文件
$ vi dbgen/makefile
# 修改如下配置项
################
## CHANGE NAME OF ANSI COMPILER HERE
################
CC = gcc
# Current values for DATABASE are: INFORMIX, DB2, TDAT (Teradata)
# SQLSERVER, SYBASE, ORACLE, VECTORWISE
# Current values for MACHINE are: ATT, DOS, HP, IBM, ICL, MVS,
# SGI, SUN, U2200, VMS, LINUX, WIN32
# Current values for WORKLOAD are: TPCH
DATABASE= MYSQL
MACHINE = LINUX
WORKLOAD = TPCH
# 进入dbgen目录
$ cd dbgen
# 编译,执行编译前需安装gcc
$ make
2.3.数据集生成
2.3.1.简单数据集生成示例
# 数据集生成示例,执行以下命令将生成1G的数据集
$ ./dbgen -vf -s 1
# 清空已生成过的数据集文件
$ rm -f *.tbl*
# 查询生成的数据集文件
$ du -sh *.tbl*
执行完后输出情况如下,可见共输出8张数据表的数据,共1G
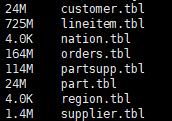
查询.tbl数据集文件可知,它实际上是文本文件,一行代表一条记录内容,各字段值使用"|"隔开。
2.3.2.指定表数据集生成示例
# 只生成lineitem表的数据集示例
$ ./dbgen -vf -T L -s 1
执行完后输出情况如下

2.3.3.数据集拆分生成示例
# 拆分输出数据集为多部分,用来Doris的并发插入测试。
# -v:启用详细模式的输出信息
# -f:覆盖已存在文件
# -T:仅输出指定表,L代表LINEITEM表
# -s:即Scale Factor (SF)
# -C:将输出数据集拆分成n部分,n为后面跟着的数字值
# -S:当数据集进行拆分输出时,当前输出哪一个部分
# 以下命令的执行结果是指定生成LINEITEM表6000000*20行的数据集,拆分20个部分,当前生成第一部分
# 执行后生成了700多MB的lineitem.tbl.1文件,若将-S的参数值改为2则将生成lineitem.tbl.2文件,直至依次改成20,完成20个数据集文件的准备
$ ./dbgen -vf -T L -s 20 -C 20 -S 1
# 创建data-set目录,用于存放所有生成的数据集
$ mkdir data-set
# 将所有生成的数据集文件移入data-set目录
$ mv *.tbl* ./data-set
2.3.4.Doris创建LINEITEM数据表
在解压根目录下的dbgen目录中包含如下两个数据库相关信息文件,分别是:
- dss.ddl:包括创建表的相关语句信息
- dss.ri:包括创建主键、外键索引相关语句信息
根据上面的数据库表结构信息,整理Doris建表语句如下:
CREATE TABLE LINEITEM
(
L_ORDERKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATETIME NOT NULL,
L_COMMITDATE DATETIME NOT NULL,
L_RECEIPTDATE DATETIME NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
UNIQUE KEY(L_ORDERKEY,L_LINENUMBER)
DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 1
PROPERTIES ('replication_num' = '1');
使用上述语句在Doris创建表后完成数据集所有准备工作。
3.DataX配置与使用
3.1.程序包下载及准备
# 下载DataX
# 官方地址:https://github.com/alibaba/DataX/blob/master/userGuid.md
$ wget https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202309/datax.tar.gz
# 解压缩
$ tar -zxvf datax.tar.gz
# 进入datax目录
$ cd datax
# 执行自检脚本
$ python bin/datax.py job/job.json
3.2.数据同步任务配置文件编辑
# 创建数据同步任务配置文件
$ touch job/textToMysqlJob.json
数据同步任务配置文件
注意
- txtfilereader的path及mysqlwriter的数据库连接地址、用户、密码需要根据实际进行配置。
- txtfilereader中支持的数据类型仅包括STRING, LONG, BOOLEAN, DOUBLE, DATE。
- txtfilereader中的column的index指.tbl数据集文件每行使用"|"分隔符的第几部分,从0开始。要与mysqlwriter的column数组中的字段名对应起来。
{
"job": {
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
"path": ["/解压根路径/dbgen/data-set"],
"encoding": "UTF-8",
"column": [
{
"index": 0,
"type": "long"
},
{
"index": 1,
"type": "long"
},
{
"index": 2,
"type": "long"
},
{
"index": 3,
"type": "long"
},
{
"index": 4,
"type": "double"
},
{
"index": 5,
"type": "double"
},
{
"index": 6,
"type": "double"
},
{
"index": 7,
"type": "double"
},
{
"index": 8,
"type": "string"
},
{
"index": 9,
"type": "string"
},
{
"index": 10,
"type": "date",
"format": "yyyy-MM-dd"
},
{
"index": 11,
"type": "date",
"format": "yyyy-MM-dd"
},
{
"index": 12,
"type": "date",
"format": "yyyy-MM-dd"
},
{
"index": 13,
"type": "string"
},
{
"index": 14,
"type": "string"
},
{
"index": 15,
"type": "string"
}
],
"fieldDelimiter": "|"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "用户名",
"password": "密码",
"column": ["L_ORDERKEY", "L_PARTKEY", "L_SUPPKEY", "L_LINENUMBER", "L_QUANTITY", "L_EXTENDEDPRICE", "L_DISCOUNT", "L_TAX", "L_RETURNFLAG", "L_LINESTATUS", "L_SHIPDATE", "L_COMMITDATE", "L_RECEIPTDATE", "L_SHIPINSTRUCT", "L_SHIPMODE", "L_COMMENT"],
"connection": [{
"jdbcUrl": "jdbc:mysql://serverAddress/dbName?useServerPrepStmts=true&cachePrepStmts=true&rewriteBatchedStatements=true&sessionVariables=group_commit=async_mode",
"table": ["LINEITEM"]
}],
"batchSize": 100,
"preSql": [""],
"session": []
}
}
}
],
"setting": {
"speed": {
"channel": 20
}
}
}
}
3.3.执行数据同步(性能测试)
$ python bin/datax.py job/textToMysqlJob.json















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










