



Python 数据管线自动化:从 ETL 编排到异常自愈的工程实践
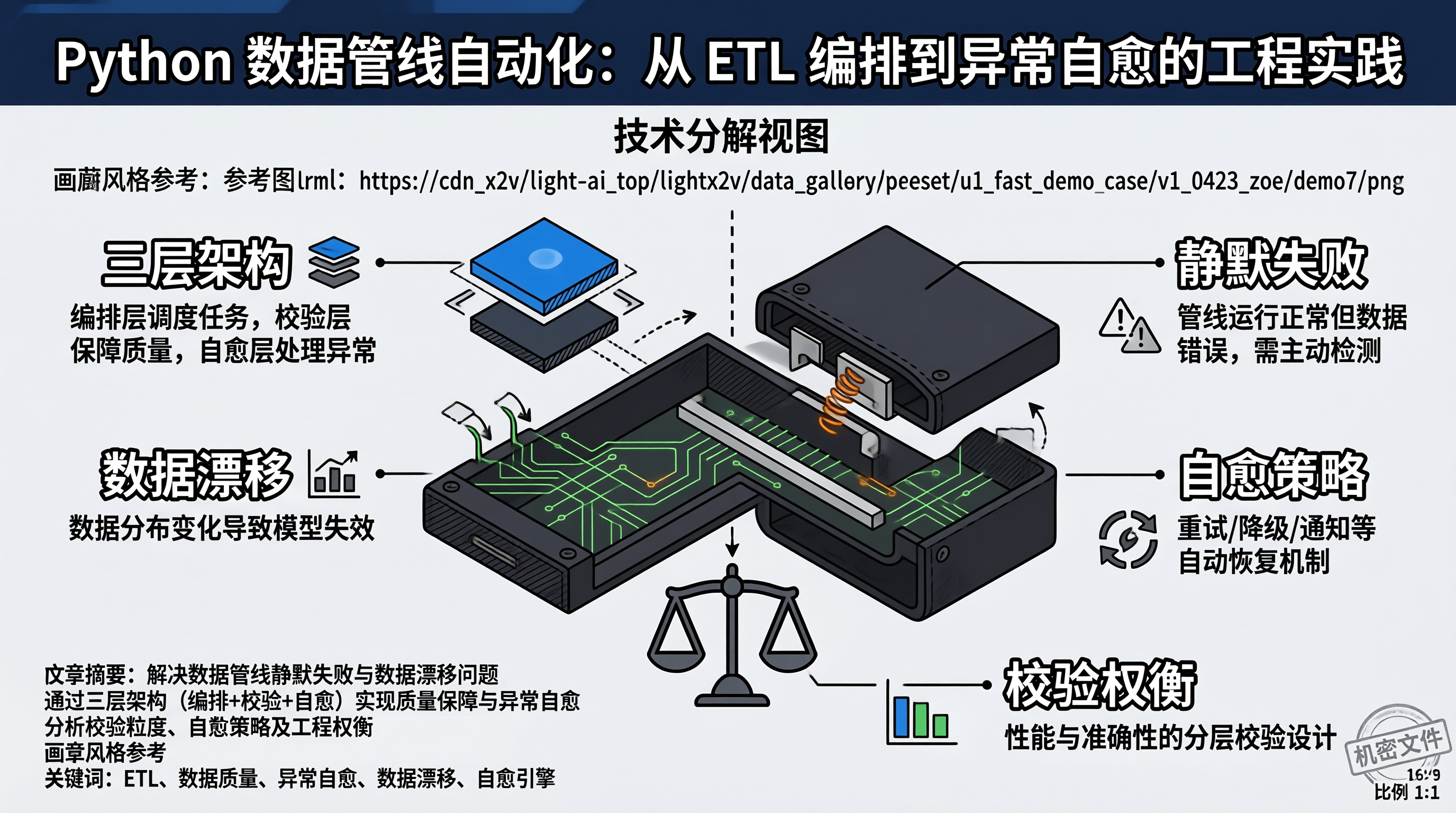
一、数据管线的运维困境:静默失败与数据漂移
数据管线(Data Pipeline)是连接数据源与业务系统的核心基础设施,但它的运维难度远超预期。最棘手的问题不是管线崩溃——崩溃至少有告警——而是静默失败:管线正常运行,但产出的数据是错的。例如,上游 API 响应格式变更导致解析逻辑跳过了部分字段,管线不报错,但数据缺失了 30%。这种问题通常在业务方发现报表异常后才被追溯,修复周期长达数天。
另一个常见问题是数据漂移(Data Drift):数据源的统计特征随时间变化,导致下游模型或规则失效。例如用户画像数据中年龄分布从 25-35 岁偏移到 18-25 岁,原有的推荐规则不再适用。数据漂移不会触发任何错误,但会持续产出低质量结果。
二、数据管线的架构设计与质量保障
现代数据管线采用"编排 + 校验 + 自愈"三层架构。编排层负责任务调度和依赖管理,校验层负责数据质量检查,自愈层负责异常恢复。
flowchart TB
SRC[数据源] --> EXTRACT[抽取 Extract]
EXTRACT --> |原始数据| VALIDATE_IN[输入校验 Schema/统计]
VALIDATE_IN --> TRANSFORM[转换 Transform]
TRANSFORM --> VALIDATE_OUT[输出校验 完整性/一致性]
VALIDATE_OUT --> LOAD[加载 Load]
LOAD --> MONITOR[监控告警]
VALIDATE_IN --> |校验失败| SELF_HEAL[自愈引擎]
VALIDATE_OUT --> |校验失败| SELF_HEAL
SELF_HEAL --> |重试/降级/通知| EXTRACT
subgraph 编排层
EXTRACT
TRANSFORM
LOAD
end
subgraph 校验层
VALIDATE_IN
VALIDATE_OUT
end
subgraph 自愈层
SELF_HEAL
end
校验层的核心是数据质量规则(Data Quality Rules),分为三类:Schema 校验(字段名、类型、必填性)、统计校验(均值、分位数、唯一值数量)和业务校验(跨表一致性、时序连续性)。每类规则有对应的阈值,超出阈值触发告警或阻断。
三、数据管线编排与质量校验实现
import time
import hashlib
from dataclasses import dataclass, field
from typing import Any, Callable
from enum import Enum
class CheckLevel(Enum):
WARN = "warn" # 告警但不阻断
BLOCK = "block" # 阻断管线
@dataclass
class QualityRule:
"""数据质量规则"""
name: str
check_fn: Callable[[Any], bool]
level: CheckLevel = CheckLevel.WARN
description: str = ""
@dataclass
class CheckResult:
rule_name: str
passed: bool
level: CheckLevel
message: str = ""
class DataQualityChecker:
"""数据质量校验器"""
def __init__(self):
self.rules: list[QualityRule] = []
def add_rule(self, rule: QualityRule) -> None:
self.rules.append(rule)
def check(self, data: Any) -> list[CheckResult]:
"""执行所有质量规则,返回检查结果"""
results = []
for rule in self.rules:
try:
passed = rule.check_fn(data)
results.append(CheckResult(
rule_name=rule.name,
passed=passed,
level=rule.level,
message="" if passed else f"规则 {rule.name} 未通过",
))
except Exception as e:
results.append(CheckResult(
rule_name=rule.name,
passed=False,
level=CheckLevel.BLOCK,
message=f"规则执行异常:{e}",
))
return results
def should_block(self, results: list[CheckResult]) -> bool:
"""判断是否有阻断级规则未通过"""
return any(not r.passed and r.level == CheckLevel.BLOCK for r in results)
class HealAction(Enum):
RETRY = "retry" # 重试当前步骤
SKIP = "skip" # 跳过当前批次
FALLBACK = "fallback" # 使用降级数据源
NOTIFY = "notify" # 仅通知人工介入
@dataclass
class HealStrategy:
"""自愈策略"""
action: HealAction
max_retries: int = 3
retry_delay: float = 5.0 # 重试间隔(秒)
fallback_fn: Callable | None = None
class SelfHealEngine:
"""自愈引擎"""
def __init__(self):
self.strategies: dict[str, HealStrategy] = {}
def register(self, step_name: str, strategy: HealStrategy) -> None:
self.strategies[step_name] = strategy
def heal(self, step_name: str, error: Exception) -> HealAction:
"""根据错误类型选择自愈策略"""
strategy = self.strategies.get(step_name)
if not strategy:
return HealAction.NOTIFY
if strategy.action == HealAction.RETRY:
return HealAction.RETRY
elif strategy.action == HealAction.FALLBACK and strategy.fallback_fn:
return HealAction.FALLBACK
else:
return HealAction.NOTIFY
class PipelineStep:
"""管线步骤"""
def __init__(
self,
name: str,
fn: Callable,
checker: DataQualityChecker | None = None,
):
self.name = name
self.fn = fn
self.checker = checker
def execute(self, data: Any) -> tuple[Any, list[CheckResult]]:
result = self.fn(data)
checks = []
if self.checker:
checks = self.checker.check(result)
return result, checks
class DataPipeline:
"""数据管线编排器"""
def __init__(
self,
name: str,
heal_engine: SelfHealEngine | None = None,
):
self.name = name
self.steps: list[PipelineStep] = []
self.heal_engine = heal_engine
def add_step(self, step: PipelineStep) -> None:
self.steps.append(step)
def run(self, initial_data: Any) -> dict:
"""执行管线,含质量校验和自愈"""
data = initial_data
all_checks: list[CheckResult] = []
for step in self.steps:
# 执行步骤
result, checks = step.execute(data)
all_checks.extend(checks)
# 检查是否有阻断级失败
if any(not c.passed and c.level == CheckLevel.BLOCK for c in checks):
if self.heal_engine:
action = self.heal_engine.heal(step.name, RuntimeError("质量校验阻断"))
if action == HealAction.RETRY:
# 重试逻辑
for attempt in range(3):
result, checks = step.execute(data)
if not any(
not c.passed and c.level == CheckLevel.BLOCK
for c in checks
):
break
time.sleep(5.0)
# 重试后仍失败,记录并中断
if any(not c.passed and c.level == CheckLevel.BLOCK for c in checks):
return {
"status": "failed",
"failed_step": step.name,
"checks": all_checks,
}
data = result
return {
"status": "success",
"checks": all_checks,
"data_hash": hashlib.md5(str(data).encode()).hexdigest()[:8],
}
四、数据管线工程的 Trade-offs 分析
校验粒度与性能的权衡:统计校验(均值、分位数)需要全量扫描数据,对大数据集耗时显著。建议分层校验:Schema 校验全量执行,统计校验采样执行(1% 采样率),业务校验按需执行。采样校验会漏掉小概率异常,但性能提升 100 倍。
自愈策略的风险:重试可能加重数据源负担(特别是对限流 API),降级数据源可能引入数据不一致。自愈不是万能药,每次自愈都应该记录日志并触发告警,让运维人员知道系统在"带病运行"。
编排器的选型:自研编排器灵活但维护成本高,Airflow/Prefect/Dagster 等开源方案功能完善但学习曲线陡。对于 10 个步骤以内的简单管线,自研足够;超过 20 个步骤、需要复杂依赖管理时,建议使用成熟方案。
数据血缘追踪的缺失:上述实现没有追踪数据的来源和变换路径,出问题时难以溯源。生产环境需要记录每个步骤的输入输出元数据,构建数据血缘图。这增加了存储成本,但对排障效率的提升是数量级的。
五、总结
数据管线的核心挑战不是 ETL 逻辑本身,而是质量保障和异常自愈。三层架构(编排 + 校验 + 自愈)通过质量规则拦截静默失败,通过自愈策略处理临时故障。校验粒度需要在准确性和性能之间权衡,自愈策略需要控制风险边界。建议从 Schema 校验和重试自愈起步,验证效果后再逐步引入统计校验和降级策略。数据血缘追踪虽然增加了复杂度,但对长期运维至关重要。


















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










