




一、引言
Redis 的卓越性能,离不开底层数据结构的强力支撑。了解这些数据结构,是理解"Redis为什么这么快"这个问题的关键一环。
二、常用的5种数据类型及其底层结构
Redis常用的数据类型有string、hash、list、set、zset五种。Redis本身是一个key-value的键值对存储系统,这五种数据类型说的都是value的类型,key的类型是固定不变,永远是字符串。
2.1 string
string类型的编码方式有3种:
- int
- embstr
- raw
int的底层是C语言的long类型,如果字符串的内容全部是整数,并且在long的范围内,就会触发int编码方式。

如果字符串不满足int编码,并且该字符串的长度小于等于44字节的话,就会触发embstr编码。

如果以上两种编码方式都不满足,那么将会触发raw编码方式,它的底层结构是SDS。
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
这个就是SDS的结构,len字段表示字符串的长度,alloc字段表示分配的空间大小,flags字段用来标识类型,buf数组则是一个柔性数组。SDS的这个设计,使得string是二进制安全的。C语言的字符串,以 ‘\0’ 为字符串的结尾,这就意味着它无法存储包含 ‘\0’ 的二进制数据。然而,SDS的字符串结尾不是通过 ‘\0’ 来标识的,而是通过长度字段len来标识的,所以就算字符串中包含 ‘\0’ ,也可以安全的存储,不会被截断。
2.2 Hash
Hash存储的是键值对(field-value),底层的编码方式有两种:
- ziplist
- hashtable
ziplist的结构如下:

- zlbytes:ziplist的总长度字段。
- zltail:最后一个节点(entry)与起始位置的偏移量,方便找到最后节点。
- zllen:记录节点的数量。
- entry:节点,实际存储数据的结构。
- zlend:标识ziplist的尾部。
ziplist是一块连续的内存,它不像普通的链表,每个节点用指针来指向其他节点,因为指针是有开销的,如果某个节点存的数据量少,就会出现指针占用的空间比实际存储的数据还要多的情况。简而言之,就是空间利用率不高。
entry(节点)的3个字段:
- prevlen:前一个节点的长度,这是为了实现从后向前的遍历。
- encoding:标识当前节点存储的数据类型,整数还是字符串,并且记录字符串的长度。
- data:实际存储的数据。
这三个字段都是不定长的。如果前一个节点的长度小于254字节,prevlen就占1个字节。如果前一个节点的长度大于等于254字节,prevlen就占5个字节。
如果要往ziplist中插入节点entry的话,需要挪动数据,就好比往数组中间插入数据一样,插入位置后面的元素都要往后挪动,这是它的一个不足之处。
另一个不足体现在 连锁更新。
假设列表中有连续的节点 A, B, C…,它们的大小都在 250~253 字节之间。此时,它们的 prevlen 都只需要 1 字节 来存储。
- 现在,你在 A 前面插入了一个新节点 New,且 New 的大小是 300 字节。
- 节点 A 的 prevlen 发现前一个节点(New)长度 ≥ 254,于是 A 的 prevlen 需要从 1 字节扩展为 5 字节。
- 这导致节点 A 的总长度增加了 4 字节。
- 节点 B 发现前一个节点(A)的长度变了,B 的 prevlen 也需要扩展。
- 这种“多米诺骨牌”效应会一直向后传递,导致后续所有节点都需要重新分配内存和移动数据。
正是因为 ziplist 存在连锁更新的问题,Redis 7.0 引入了 listpack 来取代它。listpack 取消了 prevlen,改为记录“当前节点长度”和“下一个节点偏移量”,从而彻底解决了连锁更新问题,虽然牺牲了一点点内存(多了个偏移量字段),但换来了更稳定的性能。
ziplist(压缩列表)的触发条件有下面两条:
- 哈希中元素数量少于
hash-max-ziplist-entries(默认 512 个)。 - 哈希中所有键和值的长度都小于
hash-max-ziplist-value(默认 64 字节)。
这两个字段我们都是可以在Redis的配置文件中进行配置的。
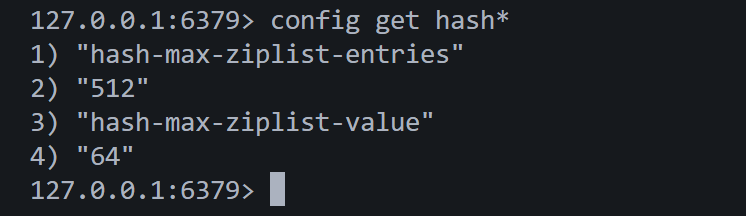

哈希中只有2个元素(一个键值对就是一个元素),少于512个,并且键和值的长度都不超过64字节,所以编码方式为ziplist。
只要上面的两个条件有一个不满足,那么将采用hashtable的编码方式。

hashtable编码方式的底层是dict(字典)。
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /* Next entry in the same hash bucket. */
void *metadata[]; /* An arbitrary number of bytes (starting at a
* pointer-aligned address) of size as returned
* by dictType's dictEntryMetadataBytes(). */
} dictEntry;
这个是dict的节点,key是字段名,v是字段值,next指向的是同一个哈希桶中的下一个节点。所以,通过这个next字段我们便可以知道,dict处理哈希冲突的方法是链地址法。
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
/* Keep small vars at end for optimal (minimal) struct padding */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */
};
ht_table[2]:两张哈希表,ht_table[0]用于平时正常读写,ht_table[1]在rehash(扩容/缩容)的时候使用。
ht_used[2]: 每张哈希表中的元素个数。ht_used[0]标识第一张哈希表中的元素个数。
rehashidx: -1表示没有进行rehash(重新hash映射),大于等于0,表示正在进行rehash的桶索引。
pauserehash: 如果大于0,表示暂停rehash。
ht_size_exp: 表示哈希表大小的指数,1<<ht_size_exp[0]表示ht_table[0]的大小,用指数替代size,节省了不少内存。
dict整体的结构示意图:

本质上,dict(字典)就是对哈希表的封装。
dict中有两张哈希表,一张用于平时的正常读写,另一张则是rehash的时候用到。
扩容
我们知道,负载因子 = used / size。当负载因子大于1的时候,就会触发扩容。
ht_table[1]会分配到旧哈希表(ht_table[0])的2倍空间。然后从rehashidx开始向后依次迁移数据。
不过,Redis并不是一次性完成数据的迁移的,因为一次性迁移大数据,是一个耗时的操作,会卡住主线程,所以Redis采用的是渐进式rehash。
所谓的渐进式rehash就是把这个耗时的迁移过程化整为零,分散到多次请求和后台任务中逐步完成。
迁移的方式有以下两种:
- 被动迁移: 每次对字典执行增、删、改、查操作时,除了执行命令本身,还会顺带将旧哈希表中的
rehashidx索引位置上的整个哈希桶迁移到新的哈希表中,然后将rehashidx加1。 - 主动迁移: Redis的后台定时任务会周期性的执行,专门分配少量时间(比如1毫秒)来主动迁移一批数据(比如100个桶)。
在进行rehash期间,新增的键值直接插入到新的哈希表中(ht_table[1])。这保证了旧的哈希表(ht_table[0])的数据量只减不增,最终能被清空。对于查找操作,会先在旧的哈希表(ht_table[0])中查找,如果没找到,再去新的哈希表中(ht_table[1])找。删除和更新操作,需要同时在两张哈希表中进行查找,然后完成相应的操作。这样能够确保两张表中的数据一致。
迁移完成后,Redis会释放掉旧的哈希表(ht_table[0])的空间。为了不改变其他代码的调用逻辑(它们默认去ht_table[0]找数据),Redis会把新的哈希表(ht_table[1])赋值给旧的哈希表(ht_table[0]),其实就是一个改变指针指向的过程。最后,将rehashidx置为-1。
缩容也是一样的过程。
2.3 list
list的底层结构从3.2版本开始,统一使用quicklist(快速列表)。
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *entry;
size_t sz; /* entry size in bytes */
unsigned int count : 16; /* count of items in listpack */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* PLAIN==1 or PACKED==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all listpacks */
unsigned long len; /* number of quicklistNodes */
signed int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
quicklist宏观上是一个双向循环链表,它的每个节点都有指向前一个节点的prev指针和指向后一个节点的next指针,而且quicklist内,还有指向头结点的head指针和指向尾节点的tail指针。
微观上,也就是具体到一个节点内部,节点内部存的其实是一个ziplist。
这种设计,保留了双向循环链表在两端插入和删除的高效性,同时有利用ziplist压缩了内存空间。

2.4 set
set,无序集合,它的底层结构有2种:
- IntSet
- Dict
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
- encoding:编码方式
- length:集合中的元素个数
- contents:柔性数组,真正存储数据的地方
触发intset的条件:
- 集合中所有元素都是整数。
- 集中中元素的数量小于
set-max-intset-entries(默认值为 512)。

当不满足上面的任何一个条件时,set的编码方式将会变成hashtable,底层结构就是dict。
2.5 zset
zset,有序集合,元素(member)按分数(score)来进行排序,底层有两种编码方式:
- ziplist
- skiplist + dict
ziplist的触发条件:
- 有序集合元素数量少于
zset-max-ziplist-entries(默认 128 个)。 - 所有元素的值和分数长度都小于
zset-max-ziplist-value(默认 64 字节)。
当不满足上面的任意一个条件时,采用第二种编码方式。

typedef struct zskiplistNode {
sds ele; // 1. 成员对象
double score; // 2. 分值
struct zskiplistNode *backward; // 3. 后退指针
struct zskiplistLevel { // 4. 层级结构
struct zskiplistNode *forward; // 4.1 前进指针
unsigned long span; // 4.2 跨度
} level[]; // 4.3 柔性数组
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 1. 头尾指针
unsigned long length; // 2. 长度
int level; // 3. 最大层级
} zskiplist;

上图就是跳表的结构,存的是score。最低层存储全量数据,然后按照一定的规则,向上增加层高,在查找数据时,从最高层开始查询。例如要找12号节点。通过上层的元素就可以过滤掉一半的元素,所以它的时间复杂度是O(log N)。
红黑树的效率也是O(log N),为什么不用红黑树?
zset这个结构,需要频繁的范围查询,跳变的最低层存储了所有元素,并通过指针连成链表,比红黑树更适合范围查询。
dict上面已经介绍过了,它存的是member -> score的映射,O(1)查分。
三、总结

欢迎批评指正!


















 3241
3241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










