




Redis7.0.15源码分析–数据结构分析
Redis的值主要有5种数据类型,分别是String(字符串)、List(列表)、Hash(哈希)、Set(集合)、ZSet(有序集合),本章主要研究这五种数据类型的使用及底层实现。
在redis里有一个核心对象——redisObject,上面提到的5种数据类型都可以用redisObject来表示。
redisObject定义
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
字段解析:
- type: 表示当前数据的数据类型(就是String(字符串)、List(列表)、Hash(哈希)、Set(集合)、ZSet(有序集合)这几个数据类型)
- encoding:表示当前的编码类型,这里的编码类型也是Redis内部实现的,在7.0.15的版本里总共有12种编码类型,不过目前有3种类型已经废弃
- lru:淘汰策略,默认是LRU 模式,还有一种LFU 模式。
- LRU模式:存储对象的最近访问时间戳(精度为秒),但为了节省内存,实际存储的是相对于全局时钟
lru_clock的相对时间(取模后的值)。通过比较对象的lru时间与全局时钟,可以估算对象的闲置时间,淘汰最久未使用的键。 - LFU模式:LFU模式将24 bits 分为两部分,淘汰访问频率最低的键。
- 低8位:存储访问频率,范围 0~255。
- 高16位:存储最后一次访问时间(分钟级时间戳),用于衰减频率(避免长期不访问的对象频率值过高)。
- LRU模式:存储对象的最近访问时间戳(精度为秒),但为了节省内存,实际存储的是相对于全局时钟
- refcount:引用次数
- *ptr:指向真正存放数据的内存空间
在redis里不同的数据类型的表达都是由对象结构(redisObject)里数据类型和与对应的编码类型组成。不同的数据类型对应若干编码类型。
type记录了对象保存值的数据类型,type的值为:
#define OBJ_STRING 0 /* String object. 字符串 */
#define OBJ_LIST 1 /* List object. 列表 */
#define OBJ_SET 2 /* Set object. 集合 */
#define OBJ_ZSET 3 /* Sorted set object. 有序集合 */
#define OBJ_HASH 4 /* Hash object. 哈希 */
encoding记录了对象保存的值的编码,encoding的值为:
#define OBJ_ENCODING_RAW 0 /* Raw representation 原始表示 */
#define OBJ_ENCODING_INT 1 /* Encoded as integer 编码为整数 */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table 编码为哈希表 */
#define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. 已弃用 */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. 已弃用 */
#define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. 已弃用 */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset 编码为整数合集 */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist 编码为跳表 */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding 嵌入式SDS字符串编码 */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks 编码为列表包的链表 */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks 编码为列表包的基数树 */
#define OBJ_ENCODING_LISTPACK 11 /* Encoded as a listpack 编码为紧凑列表 */
redisObject、type与encoding的关系如下图:
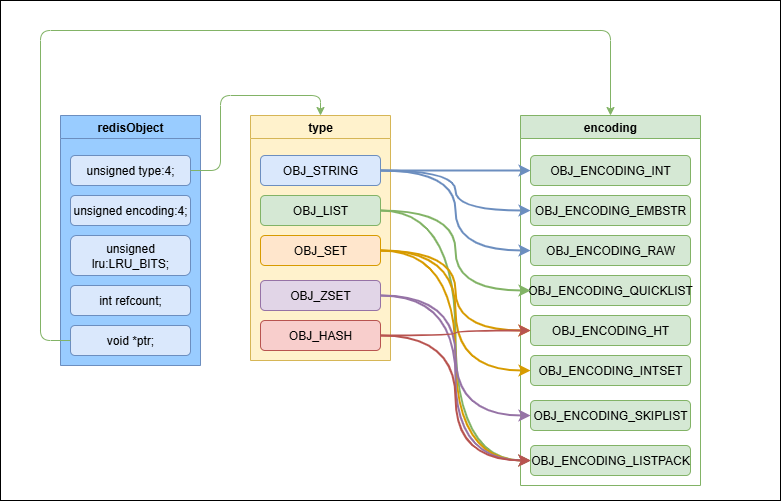
核心数据结构
SDS数据结构
Redis在设计字符串时并没有使用C的字符串表示(C的字符串是以\0结尾的字符数组),而是自己构建了一种简单动态字符串的抽象类型。在Redis中包含字符串的键值对底层都是SDS实现的。
核心设计思想:多态Header
在redis-7.0.15的版本里,Redis 为了极致优化内存,为不同长度的字符串设计了不同的 Header 结构(sdshdr5, sdshdr8, sdshdr16, sdshdr32, sdshdr64)。Header 越小,存储非常短的字符串时开销就越小。sdshdr5已经不再使用,所以我们主要关注后四种。
-
结构体定义解析
struct __attribute__ ((__packed__)) sdshdr8 {/*__attribute__ ((__packed__)):告诉编译器不要进行内存对齐优化。这确保了结构体成员在内存中是紧密排列的,方便我们通过计算偏*/ uint8_t len; /*已使用的字符串长度*/ uint8_t alloc; /*总分配容量*/ unsigned char flags; /*标识Header类型,用低3位标识当前SDS的Header 固定1字节不管是sdshdr8还是sdshdr64*/ char buf[];/*数组,存放字符串内容 它有一个关键特性:结构体 SDS Header 和字符数组 buf的内存是连续分配的*/ };/*sdshdr16, sdshdr32, sdshdr64 结构相同,只是 len和 alloc的位数更大,能管理更长的字符串*/ struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; uint16_t alloc; unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; uint32_t alloc; unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; uint64_t alloc; unsigned char flags; char buf[]; }; -
关键宏定义解析
#define SDS_TYPE_5 0 // 000 #define SDS_TYPE_8 1 // 001 #define SDS_TYPE_16 2 // 010 #define SDS_TYPE_32 3 // 011 #define SDS_TYPE_64 4 // 100 以上是Header的标识 #define SDS_TYPE_MASK 7 // 二进制 00000111 取低3位 用于与标识做&运算来识别标识 #define SDS_TYPE_BITS 3 // 类型标识占用的位数
上面的定义了 flags字段中表示类型的位掩码和值。
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
这是最关键的宏! 它的作用是:通过指向 buf的指针 s,找到其对应 Header 的起始地址。
(s):是buf数组的起始指针。sizeof(struct sdshdr##T):是相应 Header 结构的大小(例如sdshdr8是len(1) + alloc(1) + flags(1) = 3字节)。(s) - (sizeof(struct sdshdr##T)):指针向前移动 Header 大小的距离,这样就定位到了 Header 的开始位置。((struct sdshdr##T *) (...)):将计算出的地址强制转换为对应的 Header 结构体指针。
注:## 符号为连接符用于连接sdshdr和T,T是传入的变量,如果传入的T为8,则sdshdr##T等于sdshdr8
内存布局与 SDS_HDR宏操作示意图
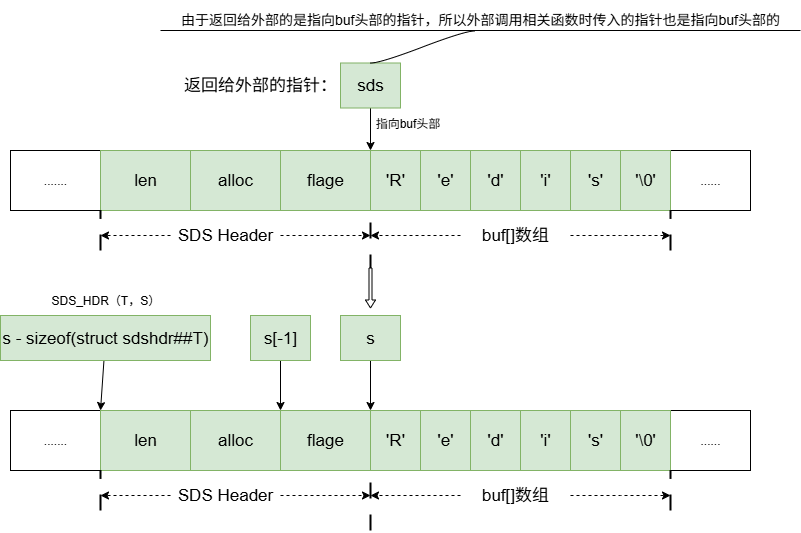
如图,调用者持有的指针 s指向 buf。要访问 Header,只需将指针 s向前移动 Header 大小的字节数即可。由于buf是一个柔性数组在sizeof计算中是不占空间的。所以能通过sizeof(struct sdshdr##T)计算出buf前面的头部大小
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
这个宏是 SDS_HDR的变体,它声明了一个变量 sh 并指向计算出的 Header 地址,方便后续使用。
函数解析
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
return 0;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
return sh->alloc - sh->len;
}
}
return 0;
}
static inline void sdssetlen(sds s, size_t newlen) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
{
unsigned char *fp = ((unsigned char*)s)-1;
*fp = SDS_TYPE_5 | (newlen << SDS_TYPE_BITS);
}
break;
case SDS_TYPE_8:
SDS_HDR(8,s)->len = newlen;
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->len = newlen;
break;
case SDS_TYPE_32:
SDS_HDR(32,s)->len = newlen;
break;
case SDS_TYPE_64:
SDS_HDR(64,s)->len = newlen;
break;
}
}
static inline void sdsinclen(sds s, size_t inc) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
{
unsigned char *fp = ((unsigned char*)s)-1;
unsigned char newlen = SDS_TYPE_5_LEN(flags)+inc;
*fp = SDS_TYPE_5 | (newlen << SDS_TYPE_BITS);
}
break;
case SDS_TYPE_8:
SDS_HDR(8,s)->len += inc;
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->len += inc;
break;
case SDS_TYPE_32:
SDS_HDR(32,s)->len += inc;
break;
case SDS_TYPE_64:
SDS_HDR(64,s)->len += inc;
break;
}
}
/* sdsalloc() = sdsavail() + sdslen() */
static inline size_t sdsalloc(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->alloc;
case SDS_TYPE_16:
return SDS_HDR(16,s)->alloc;
case SDS_TYPE_32:
return SDS_HDR(32,s)->alloc;
case SDS_TYPE_64:
return SDS_HDR(64,s)->alloc;
}
return 0;
}
static inline void sdssetalloc(sds s, size_t newlen) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
/* Nothing to do, this type has no total allocation info. */
break;
case SDS_TYPE_8:
SDS_HDR(8,s)->alloc = newlen;
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->alloc = newlen;
break;
case SDS_TYPE_32:
SDS_HDR(32,s)->alloc = newlen;
break;
case SDS_TYPE_64:
SDS_HDR(64,s)->alloc = newlen;
break;
}
}
在上面的函数中可以发现,第一行都是unsigned char flags = s[-1]; s是 buf的指针,s[-1]就是向前移动 1 字节,这正好访问到了 flags字段。
每个函数内的switch的每个选项除了宏的第一个参数不同其他操作都一样。用于每个函数都调用了宏,那么我们需要知道这些宏是怎么运行的就拿SDS_HDR(8,s)举例:
SDS_HDR(8,s)其实就是(struct sdshdr8 *)((s)-(sizeof(struct sdshdr8))),也就是指向s的Header的头部。
具体可以参考上面的内存布局示意图。
所以sdslen函数就是 sdshdrXX->len 获取使用长度
sdsavail函数就是 sdshdrXX->alloc-sdshdrXX->len 获取当前剩余长度
sdssetlen函数就是 sdshdrXX->len = newlen 设置使用长度
sdsinclen函数就是 sdshdrXX->len += inc 增加使用长度
sdsalloc函数就是 sdshdrXX->alloc 获取总长度
sdssetalloc函数就是 sdshdrXX->alloc = newlen 设置新的总长度
构造函数
构造函数有:sdsnewlen,sdsnew,sdsempty,sdsdup,sdsfromlonglong。分别是以不同的方式(空、从C字符串、从二进制数据、从长整型)创建SDS
sds sdsnewlen(const void *init, size_t initlen) {
return _sdsnewlen(init, initlen, 0);
}
/* Create a new sds string starting from a null terminated C string. */
sds sdsnew(const char *init) {
size_t initlen = (init == NULL) ? 0 : strlen(init);
return sdsnewlen(init, initlen);
}
/* Create an empty (zero length) sds string. Even in this case the string
* always has an implicit null term. */
sds sdsempty(void) {
return sdsnewlen("",0);
}
/* Duplicate an sds string. */
sds sdsdup(const sds s) {
return sdsnewlen(s, sdslen(s));
}
/* Create an sds string from a long long value. It is much faster than:
*
* sdscatprintf(sdsempty(),"%lld\n", value);
*/
sds sdsfromlonglong(long long value) {
char buf[SDS_LLSTR_SIZE];
int len = sdsll2str(buf,value);
return sdsnewlen(buf,len);
}
从以上内容可以看到除了sdsnewlen函数,其他函数最后都是调用了sdsnewlen,而sdsnewlen又调用了_sdsnewlen函数。所以实际上SDS的构造函数其实就是调用_sdsnewlen实现的。
sds _sdsnewlen(const void *init, size_t initlen, int trymalloc) {
void *sh;
sds s;
char type = sdsReqType(initlen);//根据初始长度 initlen,选择一个能容纳它的、最节省空间的 Header 类型
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;//如果分配到SDS_TYPE_5则升级为SDS_TYPE_8
int hdrlen = sdsHdrSize(type);//计算选定类型的 Header 结构体本身的大小
unsigned char *fp;
size_t usable;
assert(initlen + hdrlen + 1 > initlen); //捕获尺寸溢出(size_t overflow),防止分配异常巨大的内存
sh = trymalloc?
/*为 SDS 分配一块连续的内存,这块内存要能容纳 Header、初始数据和一个结尾的 '\0'。同时,它们还会通过 &usable参数“告 诉”调用者这块内存的实际可用大小*/
s_trymalloc_usable(hdrlen+initlen+1, &usable) ://分配失败则安静地返回 NULL
s_malloc_usable(hdrlen+initlen+1, &usable);//分配内存失败则进程直接崩溃
if (sh == NULL) return NULL;//分配失败返回NULL
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
memset(sh, 0, hdrlen+initlen+1);
s = (char*)sh+hdrlen;//计算返回给用户的 sds指针,它指向分配的内存块之后 hdrlen字节的位置,即 buf字段的起始处
fp = ((unsigned char*)s)-1;//找到 flags字段的指针
usable = usable-hdrlen-1;//计算 buf数组实际可用的空间,总分配大小 - Header大小 - 1字节的'\0'。
if (usable > sdsTypeMaxSize(type))
usable = sdsTypeMaxSize(type);
switch(type) {//根据类型进行初始化
case SDS_TYPE_5: {//将类型和长度一起压缩到 flags字段(*fp)中:*fp = type | (initlen << SDS_TYPE_BITS);。
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
/*8-64操作一致
*SDS_HDR_VAR(T,s):根据类型 T和指针 s,获取到 Header 结构体的指针 sh。
*sh->len = initlen;:设置已使用的长度。
*sh->alloc = usable;:设置总分配容量(可用于追加的空间)。
**fp = type;:在固定的位置设置类型标识。
*/
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);//
sh->len = initlen;
sh->alloc = usable;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = usable;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = usable;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = usable;
*fp = type;
break;
}
}
if (initlen && init)//如果调用者提供了初始数据,则将其复制到 buf中
memcpy(s, init, initlen);
s[initlen] = '\0';//在 buf的末尾写入 '\0'。这保证了 SDS 可以当作传统的 C 字符串使用,确保兼容性
return s;
}
大致流程如上图,详细解释可以看代码注释
修改函数
追加操作:sdscatlen,sdscat,sdscatsds,sdscatprintf,sdscatfmt,sdscatrepr。其中sdscatlen是核心函数其他的函数基本都是调用的sdscatlen完成的追加操作(sdscatprintf除外)
sds sdscatlen(sds s, const void *t, size_t len) {//s:目标SDS字符串;*t:要追加的数据源;len:要追加的数据长度
size_t curlen = sdslen(s);//获取s的长度
s = sdsMakeRoomFor(s,len);//检查内存是否足够,不足则扩容
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);//追加数据
sdssetlen(s, curlen+len);//更新长度
s[curlen+len] = '\0';
return s;
}
其实sdscatfmt函数和sdscatrepr函数虽然是调用sdscatlen做数据添加,但是都有自己先做数据处理。这里不过多赘述,想了解的可以去看看源码。
覆盖操作:sdscpylen,sdscpy。sdscpy其实也是调用的sdscpylen,这里只看sdscpylen。
sds sdscpylen(sds s, const char *t, size_t len) {
if (sdsalloc(s) < len) {
s = sdsMakeRoomFor(s,len-sdslen(s));//检查内存是否足够,不足则扩容
if (s == NULL) return NULL;
}
memcpy(s, t, len);//数据覆盖
s[len] = '\0';//尾部追加/0
sdssetlen(s, len);//更新长度
return s;
}
裁剪操作:sdstrim(移除首尾指定字符), sdsrange(保留指定区间), sdssubstr(提取子串)。这里需要了解sdstrim和sdssubstr函数,sdsrange函数是通过sdssubstr实现的。
sds sdstrim(sds s, const char *cset) {
char *end, *sp, *ep;
size_t len;
sp = s;//头指针,指向buf头部
ep = end = s+sdslen(s)-1;//尾指针,指向buf尾部
while(sp <= end && strchr(cset, *sp)) sp++;//找到第一个不需要被修剪的字符的位置
while(ep > sp && strchr(cset, *ep)) ep--;//找到最后一个不需要被修剪的字符的位置
len = (ep-sp)+1;// 计算新子串的长度
if (s != sp) memmove(s, sp, len);// 如果起始位置变了,需要移动数据
s[len] = '\0';//在新的子串末尾(偏移量为 len的位置)写入空终止符 '\0'
sdssetlen(s,len);//更新长度
return s;
}
void sdssubstr(sds s, size_t start, size_t len) {
//s:目标 SDS 字符串;start:要提取的子串的起始索引;len:要提取的子串的长度
size_t oldlen = sdslen(s);
if (start >= oldlen) start = len = 0;//处理起始位置越界的情况
if (len > oldlen-start) len = oldlen-start;//处理要求长度越界的情况
if (len) memmove(s, s+start, len);//如果len不为0,则将从start开始到len的内存复制到s头部
s[len] = 0;//在新的子串末尾(偏移量为 len的位置)写入空终止符 '\0',效果等同于s[len] = '\0';
sdssetlen(s,len);//更新长度
}
清空操作:sdsclear(惰性清空,设置len=0)
void sdsclear(sds s) {
sdssetlen(s, 0);
s[0] = '\0';
}
大小写转换:sdstolower,sdstoupper
/* Apply tolower() to every character of the sds string 's'. */
void sdstolower(sds s) {
size_t len = sdslen(s), j;
//遍历SDS 字符串 s,将其中的所有大写字母字符转换为小写字母
for (j = 0; j < len; j++) s[j] = tolower(s[j]);
}
/* Apply toupper() to every character of the sds string 's'. */
void sdstoupper(sds s) {
size_t len = sdslen(s), j;
//遍历SDS 字符串 s,将其中的所有小写字母字符转换为大写字母
for (j = 0; j < len; j++) s[j] = toupper(s[j]);
}
空间调整:sdsRemoveFreeSpace(移除空闲空间), sdsIncrLen(手动增加长度,与sdsMakeRoomFor配合使用),sdsMakeRoomFor(检查空间,不够则进行空间预分配(扩容策略:小于1MB则加倍,大于1MB则每次加1MB))
sds sdsRemoveFreeSpace(sds s, int would_regrow) {
return sdsResize(s, sdslen(s), would_regrow);
}
sds sdsResize(sds s, size_t size, int would_regrow) {//调整 SDS 的预分配空间(alloc),可能会改变其底层 Header 类 型,并可能截断字符串。
void *sh, *newsh;
/*获取当前SDS的所有信息*/
char type, oldtype = s[-1] & SDS_TYPE_MASK;//从flags中提取当前Header类型
int hdrlen, oldhdrlen = sdsHdrSize(oldtype);//计算当前Header大小
size_t len = sdslen(s);//当前字符串实际长度
sh = (char*)s-oldhdrlen;// 找到当前Header的起始地址
if (sdsalloc(s) == size) return s;//分配容量与原目标的size相同,直接返回就行
/*安全截断,如果目标容量小于当前字符串长度,则需要将字符串截断到新的长度,否则 memcpy时会溢出*/
if (size < len) len = size;
type = sdsReqType(size);//计算出size最适合的类型
if (would_regrow) {
// 预期会增长则不用SDS_TYPE_5,以为SDS_TYPE_5,因为其没有 alloc字段,无法记录预分配空间,不利于后续增长。
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
}
hdrlen = sdsHdrSize(type);// 计算新Header的大小
//性能优化决策:只有在特定情况下,才使用 realloc,否则就使用 malloc+ memcpy+ free。
//使用 realloc条件:1、类型相同(realloc可以在原内存块上直接扩展或缩小,Header结构没变)
//2、新类型更小,且不是SDS_TYPE_5。虽然Header结构变了但新的Header更小。可以利用缩小后空出来的前面的空间来存放新的Header
int use_realloc = (oldtype==type || (type < oldtype && type > SDS_TYPE_8));
size_t newlen = use_realloc ? oldhdrlen+size+1 : hdrlen+size+1;
if (use_realloc) {
int alloc_already_optimal = 0;
#if defined(USE_JEMALLOC)
alloc_already_optimal = (je_nallocx(newlen, 0) == zmalloc_size(sh));
#endif
if (!alloc_already_optimal) {
newsh = s_realloc(sh, newlen);//则调用s_realloc。如果成功,newsh可能是原地址(原地调整),也可能是一个新地址
if (newsh == NULL) return NULL;
s = (char*)newsh+oldhdrlen;//重新计算s指针,因为Header类型没变,所以偏移量oldhdrlen也没变
}
} else {
newsh = s_malloc(newlen);// 分配新内存
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len);// 只复制字符串数据部分
s_free(sh);// 释放旧内存
s = (char*)newsh+hdrlen;// 计算新sds指针
s[-1] = type;// 设置新flags字段
}
s[len] = 0;// 确保字符串以'\0'结尾
sdssetlen(s, len);// 设置新的字符串长度
sdssetalloc(s, size);// 设置新的分配容量
return s;
}
void sdsIncrLen(sds s, ssize_t incr) {//s:SDS字符串指针;incr:长度增量(可正可负,正数时表示增加字符串长度,负数反之)
unsigned char flags = s[-1];
size_t len;
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
unsigned char *fp = ((unsigned char*)s)-1;// 指向 flags
unsigned char oldlen = SDS_TYPE_5_LEN(flags);// 提取旧长度
//安全检查,增加长度时剩余空间必须足够容纳新增的长度。减少长度时当前长度必须足够被截断(不能减到负数)
assert((incr > 0 && oldlen+incr < 32) || (incr < 0 && oldlen >= (unsigned int)(-incr)));
*fp = SDS_TYPE_5 | ((oldlen+incr) << SDS_TYPE_BITS);// 更新 flags
len = oldlen+incr;
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);// 获取 Header 指针 sh
assert((incr >= 0 && sh->alloc-sh->len >= incr) || (incr < 0 && sh->len >= (unsigned int)(-incr)));
len = (sh->len += incr);// 直接更新 len
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
assert((incr >= 0 && sh->alloc-sh->len >= incr) || (incr < 0 && sh->len >= (unsigned int)(-incr)));
len = (sh->len += incr);
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
assert((incr >= 0 && sh->alloc-sh->len >= (unsigned int)incr) || (incr < 0 && sh->len >= (unsigned int)(-incr)));
len = (sh->len += incr);
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
assert((incr >= 0 && sh->alloc-sh->len >= (uint64_t)incr) || (incr < 0 && sh->len >= (uint64_t)(-incr)));
len = (sh->len += incr);
break;
}
default: len = 0; /* Just to avoid compilation warnings. */
}
s[len] = '\0';// 确保字符串以'\0'结尾
}
sds sdsMakeRoomForNonGreedy(sds s, size_t addlen) {
return _sdsMakeRoomFor(s, addlen, 0);
}
sds _sdsMakeRoomFor(sds s, size_t addlen, int greedy) {
void *sh, *newsh;
size_t avail = sdsavail(s);// 当前可用空间(alloc - len)
size_t len, newlen, reqlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;// 从flags字节提取当前类型
int hdrlen;
size_t usable;
if (avail >= addlen) return s;//当前可用空间足够,直接返回原字符串
len = sdslen(s);// 当前字符串长度
sh = (char*)s-sdsHdrSize(oldtype);// 找到header起始位置
reqlen = newlen = (len+addlen);// 最小所需长度
assert(newlen > len); // 防止size_t溢出
// 贪婪预分配策略
if (greedy == 1) {
if (newlen < SDS_MAX_PREALLOC)// 默认SDS_MAX_PREALLOC=1MB
newlen *= 2;// 小字符串:双倍分配
else
newlen += SDS_MAX_PREALLOC;// 大字符串:固定增加1MB
}
type = sdsReqType(newlen); // 根据长度确定合适的数据类型
if (type == SDS_TYPE_5) type = SDS_TYPE_8;// 避免使用type5(无空闲空间记录)
hdrlen = sdsHdrSize(type);// 新header长度
assert(hdrlen + newlen + 1 > reqlen); // 溢出检查
if (oldtype==type) {
// 类型没变:直接realloc
newsh = s_realloc_usable(sh, hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;// 更新数据指针
} else {
// 类型改变:必须重新malloc+拷贝
newsh = s_malloc_usable(hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);// 拷贝数据(含'\0')
s_free(sh); // 释放旧内存
s = (char*)newsh+hdrlen; // 更新数据指针
s[-1] = type; // 设置新flags
sdssetlen(s, len); // 保持长度不变
}
usable = usable-hdrlen-1; // 实际可用数据空间(减去header和null终止符)
if (usable > sdsTypeMaxSize(type))
usable = sdsTypeMaxSize(type);// 不超过类型最大容量
sdssetalloc(s, usable); // 记录分配的空间大小
return s;
}
总结
这里只分析了部分API,其他的一些如分割、连接、映射替换等API未进行分析,但其本质都是在操作SDS的内存结构。
通过分析这些API,可以总结出SDS的几个工作机制:
1、兼容性
- 对于使用者来说,sds就是一个char*,可以传递给所有接受C字符串的函数
- 实现是通过在buf末尾添加\0’
2、自动扩容
- 所有修改函数(比如如sdscatlen)内部都会间接调用sdsMakeRoomFor
- sdsMakeRoomFor会检查剩余空间(avail),如果不够,会进行空间预分配(扩容策略:小于1MB则加倍,大于1MB则每次加1MB)。
3、二进制安全
- 所有API都是基于len属性来判断字符串长度,而不是通过’\0’判断。
- 提供了len版本的函数(如sdsnewlen, sdscatlen)来操作任意的二进制数据。
字符串对象的内部编码方式
字符串对象的内部编码方式主要有 三种。Redis 会根据字符串值的特性,自动选择最节省内存和高效的编码方式。这三种编码发送分别是:OBJ_ENCODING_EMBSTR (嵌入式字符串)、OBJ_ENCODING_RAW (简单动态字符串,SDS)、OBJ_ENCODING_INT (整数编码)。其中比较难的就是SDS,在上文已经详细讲过了。
下面说一下什么情况会使用不同的编码方式:
创建对象:
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);//长度小于44则调用该函数
else
return createRawStringObject(ptr,len);//否则调用该函数
}
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
//创建redisObject对象并声明一个连续的内存空间
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
//设置redisObject对象的属性
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
o->ptr = sh+1;// 数据指针:跳过SDS头,指向字符串数据
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
//SDS设置,已经在SDS的buf里放入数据
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
robj *createRawStringObject(const char *ptr, size_t len) {
//创建redisObject对象,传入的第二个参数为创建的SDS
return createObject(OBJ_STRING, sdsnewlen(ptr,len));
}
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return o;
}
下面是用于优化函数:
robj *tryObjectEncoding(robj *o) {
long value;
sds s = o->ptr;
size_t len;
//检查对象,确保对象类型是字符串
serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);
if (!sdsEncodedObject(o)) return o;// 如果不是SDS编码(已经是INT编码),直接返回
if (o->refcount > 1) return o;// 如果对象被多个地方引用,修改它会影响其他引用者,直接返回
len = sdslen(s);// 获取字符串实际长度
/*len <= 20:整数字符串不会很长(long类型最大值约20位),这是一个快速预检查,避免对长字符串进行无用的解析
*string2l(s,len,&value):核心检查。尝试将 SDS 字符串 s解析为一个 long类型的整数 value。如果解析成功,说明这个字符串表 示的是一个整数。
*/
if (len <= 20 && string2l(s,len,&value)) {
if ((server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS)
{
//对于小整数,无需创建新对象,直接引用预创建好的全局对象,极大节省内存
decrRefCount(o);// 减少原对象的引用计数
incrRefCount(shared.integers[value]);// 增加共享整数对象的引用计数
return shared.integers[value];// 返回共享对象
} else {
if (o->encoding == OBJ_ENCODING_RAW) {
sdsfree(o->ptr);// 释放原来的SDS内存
o->encoding = OBJ_ENCODING_INT;// 更改编码方式
o->ptr = (void*) value;// 核心:将整数值直接存储在ptr中!
return o;
} else if (o->encoding == OBJ_ENCODING_EMBSTR) {
decrRefCount(o);// 释放整个EMBSTR对象(连续内存块)
return createStringObjectFromLongLongForValue(value);// 创建新的INT编码对象
}
}
}
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {// 长度是否≤44字节?
robj *emb;
if (o->encoding == OBJ_ENCODING_EMBSTR) return o;// 已经是,则返回
emb = createEmbeddedStringObject(s,sdslen(s));// 创建新的EMBSTR对象
decrRefCount(o);// 释放旧对象
return emb;// 返回新对象
}
trimStringObjectIfNeeded(o);// 如果SDS预分配空间过大,尝试释放多余空间
return o;// 返回原对象(可能被修剪过的)
}
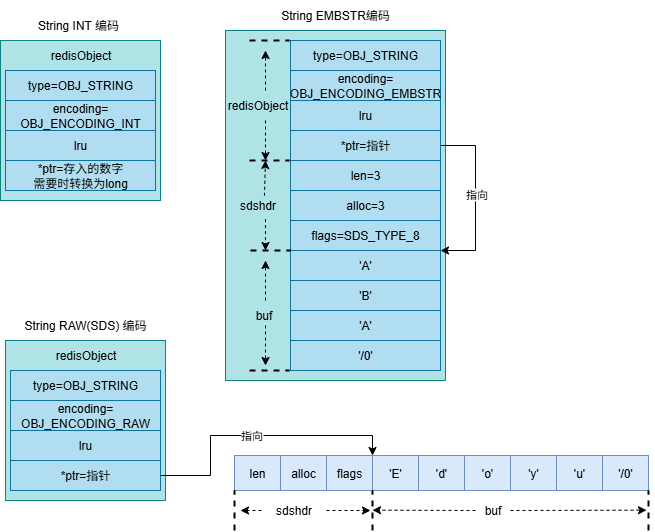
三种编码的数据结构如上图
Hanshtable数据结构
用于实现其哈希类型,同时也是整个 Redis 数据库的底层实现基础(所有键值对都存储在一个全局的字典中)。Redis 的哈希表实现非常高效,采用了经典的链式哈希结构,并辅以渐进式 rehash 策略来解决扩容/缩容时的性能问题。
核心设计思想:渐进式rehash
当哈希表的负载因子(load factor = used / size)达到一定阈值时(比如 > 1),为了维持 O(1) 时间复杂度的性能,必须进行扩容(resize)。传统的做法是一次性完成所有键的重哈希(Rehash),这在数据量巨大时会导致单次操作耗时极长,阻塞整个服务。
在redis里,用两个哈希表来进行渐进式rehash,这两个哈希表是ht[0]和ht[1],一般来说,是在ht[0]放置数据。
触发扩容:当ht[0]满足扩容条件时,Redis会为ht[1]分配一块更大的空间。
设置标志:将rehashidx设置为0,表示重哈希过程开始。
分而治之:在后续的每次增、删、改、查等对字典的操作中,Redis 除了完成指定的操作外,还会“顺便”将 ht[0]哈希桶在 rehashidx索引上的所有键值对重新计算哈希值,迁移到 ht[1] 中
移动索引:迁移完一个桶后,rehashidx加 1,指向下一个需要迁移的桶。
完成重哈希:当 ht[0]的所有桶都被迁移完毕后,rehashidx被重置为 -1。释放 ht[0]的空间,将 ht[1]设置为新的 ht[0],并在 ht[1]位置创建一个新的空白哈希表,为下一次重哈希做准备。
-
关键结构体:
typedef struct dictEntry {//字典条目,用于存储具体的键值对 void *key;//键指针 union {//值,通过联合体实现对多种类型的支持 void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next;//指向同一个哈希桶的下一个条目,通过next指针实现链式哈希(同一桶的条目形成链表)。 void *metadata[];//元数据,可选元素,柔性数组 } dictEntry; typedef struct dict dict; typedef struct dictType {//操作函数集 uint64_t (*hashFunction)(const void *key);// 哈希函数 void *(*keyDup)(dict *d, const void *key);// 键复制函数 void *(*valDup)(dict *d, const void *obj);// 值复制函数 int (*keyCompare)(dict *d, const void *key1, const void *key2);// 键比较函数 void (*keyDestructor)(dict *d, void *key);// 键销毁函数 void (*valDestructor)(dict *d, void *obj);// 值销毁函数 int (*expandAllowed)(size_t moreMem, double usedRatio);// 扩容条件检查函数,通过该函数决定是否允许扩容 size_t (*dictEntryMetadataBytes)(dict *d);// 返回条目元数据大小,用于设置元数据大小 } dictType; #define DICTHT_SIZE(exp) ((exp) == -1 ? 0 : (unsigned long)1<<(exp))//哈希表容量 #define DICTHT_SIZE_MASK(exp) ((exp) == -1 ? 0 : (DICTHT_SIZE(exp))-1)//哈希表掩码,用于计算桶索引 struct dict { dictType *type;//指向操作函数集 dictEntry **ht_table[2];// 两个哈希表(用于渐进式 rehash) unsigned long ht_used[2];// 两个哈希表的条目数量,用来表示每个哈希表分别有多少个键值对 long rehashidx; // rehash 进度索引(-1 表示未进行) int16_t pauserehash; // rehash 暂停标志(>0 暂停) signed char ht_size_exp[2]; // 哈希表大小指数(size = 1<<exp),用来表示每个哈希表分别有多少个哈希桶 }; typedef struct dictIterator { dict *d;// 迭代的字典 long index;// 当前桶索引 int table, safe;// table:当前哈希表(0 或 1);safe:安全模式标志(1=安全,0=非安全) dictEntry *entry, *nextEntry;// 当前条目和下一个条目 unsigned long long fingerprint;// 非安全迭代器的指纹(校验修改) } dictIterator;
内存结构分析
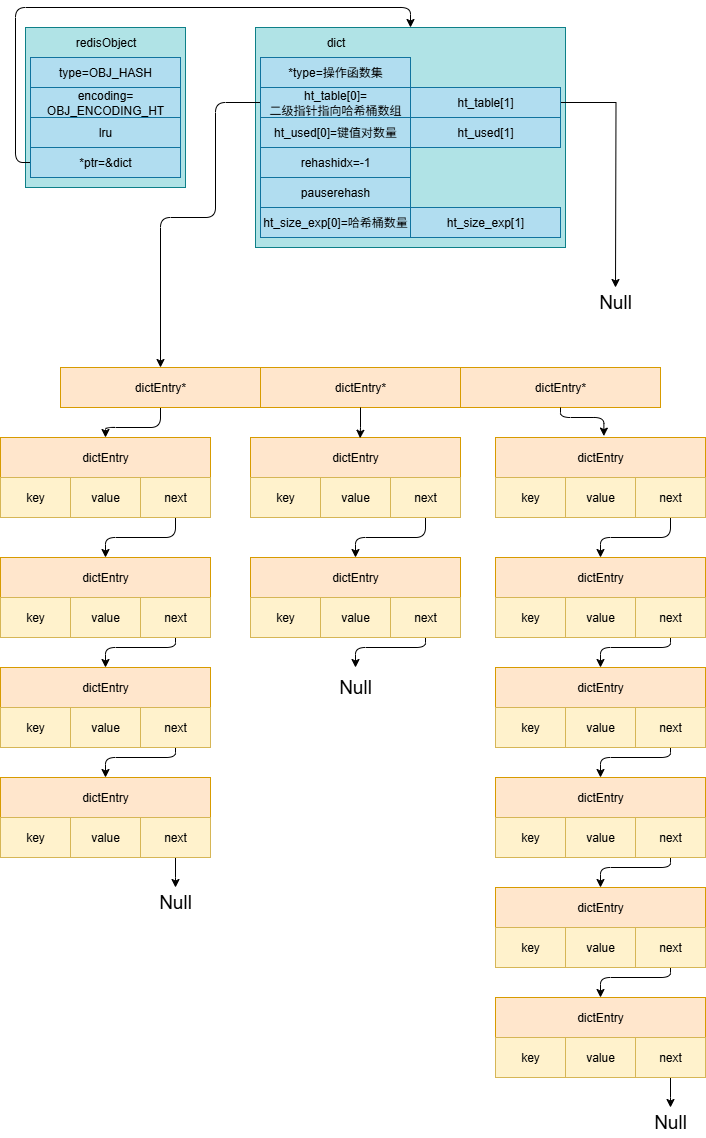
一般情况下ht_table[1]都是指向空的,只有在进行渐进式rehash时,才会给ht_table[1]分配内存,在渐进式rehash结束之后会将ht_table[1]设置为新的ht_table[0],并在ht_table[1]上重新创建一个空白的哈希表
这个图里其实夸张了,一般情况一个哈希桶里只有一个元素,只有在出现哈希冲突时才会有存放多个元素。
以上图为例,ht_size_exp[0]=2 (ht_table[0]指向的数组里有3个成员(0、1、2),每个成员都指向一个哈希桶的头部成员),ht_used[0]=12 (所有的哈希桶内总共有12个键值对)
dictEntry内的成员应该还有一个metadata,但是该成员属于可选元素,就没有画在图里。
单从该内存结构来看是好像就是数组嵌套链表,好像并没有涉及到哈希。Redis 字典如何通过 “数组 + 链表” 发挥哈希优势呢?
-
以 “查找 key = “name” 的值” 为例
-
Redis 会先对 key 执行两步操作
- 计算哈希值:通过dictType里的哈希函数对“name”计算一个整数哈希值。(例如 h = 123456)
- 计算桶索引:用哈希值对“哈希桶数组的容量”取模(实际是通过位运算 h&(容量-1),以为容量是2的幂,所以该位运算总能与取模的数值相同),得到桶索引。(例如 12345&(15)=8,即桶索引为8)
- 这一步是 “哈希优势” 的核心 ——无论总数据量有多大,都能通过一次计算直接定位到目标桶,时间复杂度 O (1)。
-
定位到哈希桶数组中的目标桶(O(1),数组优势)
- 通过第一步得到的桶索引(如 8),直接访问哈希桶数组的第 8 个元素(ht_table[0][8]),这是一个 dictEntry* 指针,指向该桶的第一个键值对节点。
- 数组的 “随机访问” 特性保证了这一步也是 O (1)——通过索引直接定位内存地址,无需遍历数组。
-
在桶内的链表查找目标key(O(n),n是桶内数据量,通常很小)
- 得到桶的头指针后,只需遍历该桶内的链表
- 这一步的时间复杂度是 O (k),但 k 通常非常小
-
函数解析
dict *dictCreate(dictType *type)
{
dict *d = zmalloc(sizeof(*d));//申请内存空间
_dictInit(d,type);//初始化dict
return d;
}
int _dictInit(dict *d, dictType *type)
{
_dictReset(d, 0);//初始化第一个哈希桶数组相关数据
_dictReset(d, 1);//初始化第二个哈希桶数组相关数据
d->type = type;
d->rehashidx = -1;
d->pauserehash = 0;
return DICT_OK;
}
static void _dictReset(dict *d, int htidx)
{//初始化哈希桶数组相关数据
d->ht_table[htidx] = NULL;
d->ht_size_exp[htidx] = -1;
d->ht_used[htidx] = 0;
}
dictCreate用于创建一个新的空字典。你必须传入一个定义了这个字典键值对操作行为的 dictType
int dictAdd(dict *d, void *key, void *val)//添加新条目
{
dictEntry *entry = dictAddRaw(d,key,NULL);//如果键不存在则添加新条目,存在则返回NULL
if (!entry) return DICT_ERR;//键已存在,添加失败
dictSetVal(d, entry, val);//为新创建的条目设置值,dictSetVal是宏定义,该宏的操作取决于dictType定义的valDup函数
return DICT_OK;
}
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
int htidx;
/*dictIsRehashing(d)检查d是否这种进行rehash,如果正在进行则通过 _dictRehashStep(d)迁移一个桶的条目从ht_table[0]到 ht_table[1] 渐进式 rehashing 确保操作平滑,避免性能抖动 */
if (dictIsRehashing(d)) _dictRehashStep(d);
/*dictHashKey(d,key):调用字典的哈希函数计算键的哈希值;
*_dictKeyIndex(d, key, hash, existing):根据哈希值计算桶索引,并在桶内查找键是否存在,如果存在则返回-1,并通过 existing返回已存在条目;不存在则返回目标桶索引*/
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;//键存在,返回NULL
htidx = dictIsRehashing(d) ? 1 : 0;//根据是否在进行rehash判断新条目添加到那个哈希表
//分配内存,并初始化元数据
size_t metasize = dictMetadataSize(d);
entry = zmalloc(sizeof(*entry) + metasize);
if (metasize > 0) {
memset(dictMetadata(entry), 0, metasize);
}
//将新条目添加到哈希表的指定桶中,并更新计数
entry->next = d->ht_table[htidx][index];//新条目的 next指向桶的当前头条目(链表头部插入)
d->ht_table[htidx][index] = entry;//桶的头指针更新为新条目
d->ht_used[htidx]++;//增加目标哈希表的条目数量
//将键关联到新条目 dictSetKey是宏定义,该宏的操作取决于dictType定义的keyDup函数
dictSetKey(d, entry, key);
return entry;
}
以上源码是添加键值对时代码,在添加键值对时需要创建新的条目并将键和值添加的条目中。创建条目的内容主要在dictAddRaw函数中,在dictAddRaw中能明显看到多处使用dictIsRehashing(d)来判断当前dict是否处于rehash状态以此来进行渐进式rehash。
dictEntry *dictFind(dict *d, const void *key)//查找指定键对应的条目
{
dictEntry *he;
uint64_t h, idx, table;
if (dictSize(d) == 0) return NULL; //空字典,直接返回NULL
if (dictIsRehashing(d)) _dictRehashStep(d);//与dictAddRaw函数里的操作相同用于渐进式rehash
h = dictHashKey(d, key);//计算键的哈希值
for (table = 0; table <= 1; table++) {//在可能存在的两个哈希表里查找键
idx = h & DICTHT_SIZE_MASK(d->ht_size_exp[table]);//确定键所在的桶
he = d->ht_table[table][idx];//获取桶的头指针
while(he) {//遍历链表,比较指针是否相等,如果不相等,则调用dictCompareKeys进行深度比较
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;//如果不在rehash状态这表1应该为空,直接返回NULL
}
return NULL;
}
dictAddRaw主要用于查找键对应的条目
int dictDelete(dict *ht, const void *key) {//从字典中删除一个键值对
return dictGenericDelete(ht,key,0) ? DICT_OK : DICT_ERR;//删除条目
}
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
uint64_t h, idx;
dictEntry *he, *prevHe;
int table;
/* dict is empty */
if (dictSize(d) == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d);//见到好几次了,跟之前的功能相同
h = dictHashKey(d, key);//计算哈希值
//这里面有部分内容和之前的dictFind函数一样,就不过多赘述了,没注释的可以参考之前dictFind的注释
for (table = 0; table <= 1; table++) {
idx = h & DICTHT_SIZE_MASK(d->ht_size_exp[table]);
he = d->ht_table[table][idx];
prevHe = NULL;//prevHe用于记录前驱节点
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
/* Unlink the element from the list */
if (prevHe)
prevHe->next = he->next;//更新前驱节点
else
d->ht_table[table][idx] = he->next;//删除节点为头节点,将头指针设置为当前节点的下一个节点
if (!nofree) {
//根据nofree标志决定内存处理 nofree=0:调用 dictFreeUnlinkedEntry释放内存 否则保留内存
dictFreeUnlinkedEntry(d, he);
}
d->ht_used[table]--;//更新条目数量
return he;
}
prevHe = he;//更新前驱节点
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return NULL; //没找到
}
dictDelete函数是从字典中删除一个键值对,并调用相应的析构函数释放键和值。这是最基础的删除操作
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, *existing, auxentry;
/*dictAddRaw这个函数在之前添加新条目的函数dictAdd见过,只不过dictAdd里填的第三个参数为NULL。所以这里的区别就在这第三个 参数,因为dictAddRaw里会先查找键是否存在,如果不存在就创建新条目,第三个参数就是在键存在用于接收已存在的键的*/
entry = dictAddRaw(d,key,&existing);
if (entry) {//entry不为NULL时表示是新建的条目,直接为新条目设置value就行
dictSetVal(d, entry, val);
return 1;
}
//entry为NULL则是existing接收的条目,所以下面给existing对应的条目更新value
auxentry = *existing;
dictSetVal(d, existing, val);
dictFreeVal(d, &auxentry);
return 0;
}
dictReplace如果键不存在则添加(如同 dictAdd),如果键存在则替换其值(并释放旧值)
dictIterator *dictGetIterator(dict *d)
{
dictIterator *iter = zmalloc(sizeof(*iter));// 分配迭代器内存
// 初始化迭代器状态
iter->d = d; // 指向要遍历的字典
iter->table = 0; // 当前遍历的哈希表索引(0或1)
iter->index = -1; // 当前桶索引(初始为-1)
iter->safe = 0; // 安全模式标志(0=非安全)
iter->entry = NULL; // 当前条目指针
iter->nextEntry = NULL;// 下一个条目指针(用于安全删除)
return iter;
}
dictIterator *dictGetSafeIterator(dict *d) {
dictIterator *i = dictGetIterator(d); // 创建基础迭代器
i->safe = 1; // 设置为安全模式
return i;
}
dictEntry *dictNext(dictIterator *iter)
{
while (1) {
if (iter->entry == NULL) {
//当前链表已遍历完,需要切换到下一个桶
//第一次迭代前的初始化
if (iter->index == -1 && iter->table == 0) {
if (iter->safe)
dictPauseRehashing(iter->d);// 安全模式:暂停rehashing
else
iter->fingerprint = dictFingerprint(iter->d);// 非安全模式:记录字典指纹
}
// 移动到下一个桶
iter->index++;
// 检查当前哈希表是否遍历完
if (iter->index >= (long) DICTHT_SIZE(iter->d->ht_size_exp[iter->table])) {
// 如果正在rehashing且当前是表0,切换到表1
if (dictIsRehashing(iter->d) && iter->table == 0) {
iter->table++;
iter->index = 0;
} else {
break;// 遍历结束
}
}
// 获取新桶的头条目
iter->entry = iter->d->ht_table[iter->table][iter->index];
} else {
// 继续当前桶的下一个条目
iter->entry = iter->nextEntry;
}
// 如果找到有效条目
if (iter->entry) {
// 保存下一个条目的指针(因为用户可能删除当前条目)
iter->nextEntry = iter->entry->next;
return iter->entry;// 返回当前条目
}
}
return NULL;// 遍历结束
}
dictNext通过迭代器遍历所有条目,需要注意的是如果想遍历完所有条目得循环调用dictNext,因为他每次只返回一个条目
void dictRelease(dict *d)
{
_dictClear(d,0,NULL);
_dictClear(d,1,NULL);
zfree(d);
}
int _dictClear(dict *d, int htidx, void(callback)(dict*)) {
unsigned long i;
//遍历所有桶,并且在条目数<=0时停止遍历
for (i = 0; i < DICTHT_SIZE(d->ht_size_exp[htidx]) && d->ht_used[htidx] > 0; i++) {
dictEntry *he, *nextHe;
//没遍历65535次调用一次callback(目前不知道callback是干嘛的)
if (callback && (i & 65535) == 0) callback(d);
if ((he = d->ht_table[htidx][i]) == NULL) continue;//跳过空桶
while(he) {
nextHe = he->next; // 保存下一个条目指针
dictFreeKey(d, he); // 释放键
dictFreeVal(d, he); // 释放值
zfree(he); // 释放条目结构
d->ht_used[htidx]--; // 更新已用计数
he = nextHe; // 移动到下一个
}
}
//释放哈希表数组
zfree(d->ht_table[htidx]);
//重置哈希表状态
_dictReset(d, htidx);
return DICT_OK; /* never fails */
}
dictRelease函数会销毁整个字典,释放所有内存。与 dictCreate配对使用,是生命周期管理的核心。
int dictRehash(dict *d, int n) {
int empty_visits = n*10; // 最多访问的空桶数量,避免在遇到大量空桶时浪费时间
unsigned long s0 = DICTHT_SIZE(d->ht_size_exp[0]);// 表0大小
unsigned long s1 = DICTHT_SIZE(d->ht_size_exp[1]);// 表1大小
/* 检查是否允许rehash */
if (dict_can_resize == DICT_RESIZE_FORBID || !dictIsRehashing(d)) return 0;
/* 避免不必要的rehash */
if (dict_can_resize == DICT_RESIZE_AVOID &&
((s1 > s0 && s1 / s0 < dict_force_resize_ratio) || /*检查新旧表大小比例是否超过阈值,避免在大小相近的表间进行 低效迁移*/
(s1 < s0 && s0 / s1 < dict_force_resize_ratio)))
{
return 0;
}
while(n-- && d->ht_used[0] != 0) {
dictEntry *de, *nextde;
//确保rehashidx有效
assert(DICTHT_SIZE(d->ht_size_exp[0]) > (unsigned long)d->rehashidx);
//跳过空桶
while(d->ht_table[0][d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
//获取当前桶链表
de = d->ht_table[0][d->rehashidx];
//迁移整个桶的条目
while(de) {
uint64_t h;
nextde = de->next;
//计算在新表中的索引
h = dictHashKey(d, de->key) & DICTHT_SIZE_MASK(d->ht_size_exp[1]);
//插入到新表头部
de->next = d->ht_table[1][h];
d->ht_table[1][h] = de;
//更新计数器
d->ht_used[0]--;
d->ht_used[1]++;
de = nextde;
}
//清空旧桶
d->ht_table[0][d->rehashidx] = NULL;
d->rehashidx++;
}
/* 检查是否完成整个rehash*/
if (d->ht_used[0] == 0) {
zfree(d->ht_table[0]);//释放表内存
//将新表设置为表0
d->ht_table[0] = d->ht_table[1];
d->ht_used[0] = d->ht_used[1];
d->ht_size_exp[0] = d->ht_size_exp[1];
//重置表1
_dictReset(d, 1);
d->rehashidx = -1;//标记rehash完成
return 0;
}
/* More to rehash... */
return 1;
}
这个函数是字典实现中渐进式 rehash的核心机制,用于逐步将条目从旧哈希表迁移到新哈希表。
根据前面的源码分析,可以发现在增删改查的操作函数中都有这样一段代码 if (dictIsRehashing(d)) _dictRehashStep(d);,这段代码其实就是检查当前释放在进行渐进式rehash,如果在进行就调用_dictRehashStep()函数。而在_dictRehashStep()函数里就是调用了dictRehash()函数,并且传入的第二个参数为1,表示迁移一个桶的数据。
在redis中Hash类型是有两种编码方式的,只看一个Hanshtable的数据结构是不够的,这里就要引入另一个数据结构----Listpack
以及redis是怎么确定使用Hanshtable还是Listpack的。关于编码方式的确定,可以参考以下流程图
Listpack 数据结构
Redis 中的 Listpack 是一种紧凑的、内存高效的、用于存储序列化数据(通常是字符串或整数)的数据结构。它是在 Redis 7.0 版本中引入的,主要是为了替代旧的 ziplist编码,成为小型列表(List)、哈希(Hash)、有序集合(Sorted Set)等数据类型在元素数量较少或元素本身较小时使用的数据结构。
Listpack 的目标是解决 ziplist的一个主要痛点:级联更新
Listpack 如何解决级联更新问题?
- 在旧的 ziplist中,每个条目存储的是前一个条目的长度(prevlen)和当前节点的数据(encoding)。而prevlen的大小是变动的,如果前一个条目的长度小于254字节时prevlen用 1 字节存储,如果大于254字节时prevlen用 5 字节存储。而当prevlen由1字节转换为5字节时,可能导致当前条目大小从小于254字节变为大于254字节,从而导致下一个条目的prevlen也由1字节转换为5字节,在极端情况下可能会形成连锁反应(级联更新)。这在最坏情况下可能导致 O(N) 的复杂度。
- 在 listpack中,每个条目只存储它自身的长度(放在条目末尾)。当修改一个条目时:
- 如果新条目的总长度(编码+内容+自身长度字段)小于或等于旧条目的总长度,并且有足够的空间(可能涉及覆盖写入),那么可以直接在原地修改。后续条目完全不受影响,因为它们存储的是自己的长度,而不是前一个的长度。
- 如果新条目更大,无法在原地容纳,则需要分配新的空间,复制整个 Listpack(或从修改点开始的部分)。虽然这也有成本,但不会像 ziplist 那样产生级联更新。最坏情况是 O(N),但平均情况通常更好,且避免了级联更新的最坏场景。
Listpack内存结构
-
关键结构体
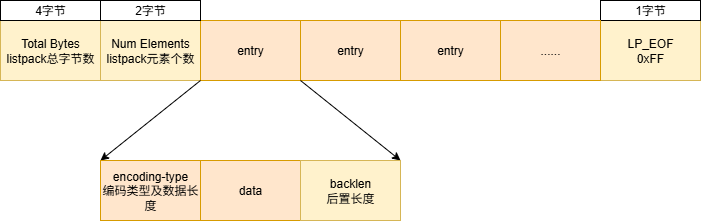
typedef struct { unsigned char *sval;//字符串值指针 uint32_t slen; //字符串长度 long long lval; //整数值 } listpackEntry;与前面几个数据结构不同的是,listpack.h中的结构体,并不能分析出listpack具体的内存结构,我们得配合其他函数来分析
#define lpSetTotalBytes(p,v) do { \ (p)[0] = (v)&0xff; \ (p)[1] = ((v)>>8)&0xff; \ (p)[2] = ((v)>>16)&0xff; \ (p)[3] = ((v)>>24)&0xff; \ } while(0) #define lpSetNumElements(p,v) do { \ (p)[4] = (v)&0xff; \ (p)[5] = ((v)>>8)&0xff; \ } while(0) unsigned char *lpNew(size_t capacity) { unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1); if (lp == NULL) return NULL; lpSetTotalBytes(lp,LP_HDR_SIZE+1); lpSetNumElements(lp,0); lp[LP_HDR_SIZE] = LP_EOF; return lp; }**lpNew()**这个函数是用来创建一个新的listpack的,通过这个函数能看到listpack大致的内存结构
lpNew内第一行就声明了一个内存空间,那这个内存空间有多大呢?
capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1 ---->最少都是LP_HDR_SIZE+1,LP_HDR_SIZE是宏定义在listpack.h中被定义为6,所以这里声明的内存空间最小是7字节。
那么这7字节是干嘛的呢?
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0);
源码里在声明内存空间之后就这两个宏,这是他对声明但是内存空间的使用
lpSetTotalBytes是在内存空间的前4个字节插入数据,这4个字节存储的是当前listpack的字节长度(小端序存储)
lpSetNumElements是在内存空间5、6字节插入数据,在两个字节存储的是listpack的元素个数(小端序存储);
然后再在listpack末尾写入LP_EOF(也是宏 #define LP_EOF 0xFF),表示结束。

现在我们知道了listpack的同步和尾部结构,但是中间存储的具体的元素结构函数不清楚。
通过lpInsert()继续数据添加时可以看到元素具体的内存结构
unsigned char *lpInsert( unsigned char *lp, // 指向listpack的指针 unsigned char *elestr, // 字符串元素指针(NULL表示非字符串) unsigned char *eleint, // 整数元素指针(NULL表示非整数) uint32_t size, // 字符串长度或整数编码长度 unsigned char *p, // 当前元素位置(操作基准点) int where, // 操作位置:LP_BEFORE/LP_AFTER/LP_REPLACE unsigned char **newp // 输出参数:新元素位置 ) { unsigned char intenc[LP_MAX_INT_ENCODING_LEN]; unsigned char backlen[LP_MAX_BACKLEN_SIZE]; uint64_t enclen; //删除操作检测,如果传入的元素都为空,视为删除操作 int delete = (elestr == NULL && eleint == NULL); if (delete) where = LP_REPLACE; //统一在元素前操作,如果操作位置不是元素前,则向后条一个元素然后设置为LP_BEFORE if (where == LP_AFTER) { p = lpSkip(p); where = LP_BEFORE; ASSERT_INTEGRITY(lp, p);//检查完整性 } //保存位置偏移量 unsigned long poff = p-lp; //判断数据类型是int还是字符串 int enctype; if (elestr) { //如果是字符串类型,尝试转换成整数编码 enctype = lpEncodeGetType(elestr,size,intenc,&enclen); if (enctype == LP_ENCODING_INT) eleint = intenc; } else if (eleint) { //整数直接处理 enctype = LP_ENCODING_INT; enclen = size; } else { enctype = -1; enclen = 0; } //反向长度计算,反向长度(backlen)用于支持反向遍历 unsigned long backlen_size = (!delete) ? lpEncodeBacklen(backlen,enclen) : 0; //计算原listpack的空间大小 uint64_t old_listpack_bytes = lpGetTotalBytes(lp); uint32_t replaced_len = 0; if (where == LP_REPLACE) {//如果是更新 //计算需要被替换的元素的总长度 replaced_len = lpCurrentEncodedSizeUnsafe(p); replaced_len += lpEncodeBacklen(NULL,replaced_len); ASSERT_INTEGRITY_LEN(lp, p, replaced_len); } //新空间=原空间+新元素大小(enclen + backlen_size)-被替换元素大小大小 uint64_t new_listpack_bytes = old_listpack_bytes + enclen + backlen_size - replaced_len; //超过4GB限制,直接返回NULL。Redis 限制 listpack 最大为 4GB if (new_listpack_bytes > UINT32_MAX) return NULL; //获取目标位置 unsigned char *dst = lp + poff; //检查是否需要扩容,如果需要则进行扩容 if (new_listpack_bytes > old_listpack_bytes && new_listpack_bytes > lp_malloc_size(lp)) { if ((lp = lp_realloc(lp,new_listpack_bytes)) == NULL) return NULL; dst = lp + poff;//重新分配内存空间后,更新指针。 } //数据移动 if (where == LP_BEFORE) { // |<---------------------------old_listpack_bytes----------------------------->| // |<---head--->|<-entry->|<-entry->|<-entry->|<-entry->|<-entry->|<-entry->|END| // |<-------------poff------------->|<-------old_listpack_bytes-poff----------->| // dst->| //memmove后 // |<-----------------------------------new_listpack_bytes------------------------------->| // |<---head--->|<-entry->|<-entry->|<--new-->|<-entry->|<-entry->|<-entry->|<-entry->|END| // |<-------------poff------------->| |<-------old_listpack_bytes-poff----------->| // dst+enclen+backlen_size->| //就是插入一个新元素大小的空白字段,方便后续新元素写入 memmove(dst+enclen+backlen_size,dst,old_listpack_bytes-poff); } else { //前面是新增元素,这里是替换元素,其实本质是相同的。删除操作也是在这里操作,逻辑就是将要删除的元素替换为0长度元素 long lendiff = (enclen+backlen_size)-replaced_len; memmove(dst+replaced_len+lendiff, dst+replaced_len, old_listpack_bytes-poff-replaced_len); } //缩容,空间缩小时先移动数据再缩容 if (new_listpack_bytes < old_listpack_bytes) { if ((lp = lp_realloc(lp,new_listpack_bytes)) == NULL) return NULL; dst = lp + poff; } //更新新元素位置 if (newp) { *newp = dst; if (delete && dst[0] == LP_EOF) *newp = NULL; } if (!delete) { if (enctype == LP_ENCODING_INT) { //整数直接进行内存拷贝 memcpy(dst,eleint,enclen); } else { //字符串使用lpEncodeString()函数进行编码拷贝工作 lpEncodeString(dst,elestr,size); } //尾部添加反向长度 dst += enclen; memcpy(dst,backlen,backlen_size); dst += backlen_size; } //元素数量更新 if (where != LP_REPLACE || delete) { uint32_t num_elements = lpGetNumElements(lp); if (num_elements != LP_HDR_NUMELE_UNKNOWN) { if (!delete) lpSetNumElements(lp,num_elements+1); else lpSetNumElements(lp,num_elements-1); } } //总字节数更新 lpSetTotalBytes(lp,new_listpack_bytes); #if 0 /* 强制内存重分配以检测指针更新错误 */ unsigned char *oldlp = lp;// 1. 保存原始指针 lp = lp_malloc(new_listpack_bytes);// 2. 强制重新分配内存 memcpy(lp,oldlp,new_listpack_bytes);// 3. 复制数据到新内存 if (newp) { // 4. 修正返回的新元素指针 unsigned long offset = (*newp)-oldlp; *newp = lp + offset; } // 5. 污染原始内存 memset(oldlp,'A',new_listpack_bytes); lp_free(oldlp);// 6. 释放原始内存 #endif return lp; }通过分析该函数会发现,listpack元素的内存结构好像还是不明晰。确实,因为他的结构布置封装在函数里了,这里只是做了调用,但是设置新空间的大小时,还是能看出一些端倪。
uint64_t new_listpack_bytes = old_listpack_bytes + enclen + backlen_size - replaced_len;
通过这行代码可以看出新的内存大小=原内存大小(old_listpack_bytes )+enclen + backlen_size-被替换元素大小。
所以enclen + backlen_size应该就是一个元素的内存大小,由此可见listpack元素的内存结构可能分为两部分。
我们可以看一下enclen 和backlen_size是在什么地方赋值的,以此来确定listpack元素的内存结构。
if (elestr) { //如果是字符串类型,尝试转换成整数编码 enctype = lpEncodeGetType(elestr,size,intenc,&enclen); if (enctype == LP_ENCODING_INT) eleint = intenc; } else if (eleint) { //整数直接处理 enctype = LP_ENCODING_INT; enclen = size; } else { enctype = -1; enclen = 0; }enclen的赋值主要在这个地方,如果是字符串类型这通过lpEncodeGetType()传递enclen的指针进去获取长度;如果是整数类型则直接赋予传入的长度;如果elestr和eleint都没有值这表示当前为删除操作,所以enclen,表示当前为0长度元素。
tatic inline int lpEncodeGetType(unsigned char *ele, uint32_t size, unsigned char *intenc, uint64_t *enclen) { int64_t v; if (lpStringToInt64((const char*)ele, size, &v)) {//才是将字符串转换为整数 lpEncodeIntegerGetType(v, intenc, enclen);//如果能转换则进行整数编码 return LP_ENCODING_INT; } else { if (size < 64) *enclen = 1+size;//size为传入的字符串长度,如果size不超过64位(即1字节)+1字节用来记录长度 else if (size < 4096) *enclen = 2+size;//同上 else *enclen = 5+(uint64_t)size; return LP_ENCODING_STRING; } } //整数编码 //主要是将V传递给intenc,通过intenc指针将值传递出去。 //并且会在intenc前面添加标识符,表示当前使用的内存空间 //会根据v的值判断当前需要的空间给enclen赋值 static inline void lpEncodeIntegerGetType(int64_t v, unsigned char *intenc, uint64_t *enclen) { if (v >= 0 && v <= 127) { /* Single byte 0-127 integer. */ intenc[0] = v; *enclen = 1; } else if (v >= -4096 && v <= 4095) { /* 13 bit integer. */ if (v < 0) v = ((int64_t)1<<13)+v; intenc[0] = (v>>8)|LP_ENCODING_13BIT_INT; intenc[1] = v&0xff; *enclen = 2; } else if (v >= -32768 && v <= 32767) { /* 16 bit integer. */ if (v < 0) v = ((int64_t)1<<16)+v; intenc[0] = LP_ENCODING_16BIT_INT; intenc[1] = v&0xff; intenc[2] = v>>8; *enclen = 3; } else if (v >= -8388608 && v <= 8388607) { /* 24 bit integer. */ if (v < 0) v = ((int64_t)1<<24)+v; intenc[0] = LP_ENCODING_24BIT_INT; intenc[1] = v&0xff; intenc[2] = (v>>8)&0xff; intenc[3] = v>>16; *enclen = 4; } else if (v >= -2147483648 && v <= 2147483647) { /* 32 bit integer. */ if (v < 0) v = ((int64_t)1<<32)+v; intenc[0] = LP_ENCODING_32BIT_INT; intenc[1] = v&0xff; intenc[2] = (v>>8)&0xff; intenc[3] = (v>>16)&0xff; intenc[4] = v>>24; *enclen = 5; } else { /* 64 bit integer. */ uint64_t uv = v; intenc[0] = LP_ENCODING_64BIT_INT; intenc[1] = uv&0xff; intenc[2] = (uv>>8)&0xff; intenc[3] = (uv>>16)&0xff; intenc[4] = (uv>>24)&0xff; intenc[5] = (uv>>32)&0xff; intenc[6] = (uv>>40)&0xff; intenc[7] = (uv>>48)&0xff; intenc[8] = uv>>56; *enclen = 9; } }通过上面的内容可以看到,其实enclen是两个内容的长度,enclen头部会存放当前元素的编码方案(包括数据长度)和具体的数据内容。
由此我们可以得到listpack元素的内存结构:
那listpack的编码类型有那些,后置长度又是怎么设置的呢?
编码类型主要需要看listpack.c前面的宏定义
#define LP_ENCODING_7BIT_UINT 0
#define LP_ENCODING_7BIT_UINT_MASK 0x80
#define LP_ENCODING_IS_7BIT_UINT(byte) (((byte)&LP_ENCODING_7BIT_UINT_MASK)==LP_ENCODING_7BIT_UINT)
#define LP_ENCODING_7BIT_UINT_ENTRY_SIZE 2
#define LP_ENCODING_13BIT_INT 0xC0
#define LP_ENCODING_13BIT_INT_MASK 0xE0
#define LP_ENCODING_IS_13BIT_INT(byte) (((byte)&LP_ENCODING_13BIT_INT_MASK)==LP_ENCODING_13BIT_INT)
#define LP_ENCODING_13BIT_INT_ENTRY_SIZE 3
#define LP_ENCODING_16BIT_INT 0xF1
#define LP_ENCODING_16BIT_INT_MASK 0xFF
#define LP_ENCODING_IS_16BIT_INT(byte) (((byte)&LP_ENCODING_16BIT_INT_MASK)==LP_ENCODING_16BIT_INT)
#define LP_ENCODING_16BIT_INT_ENTRY_SIZE 4
#define LP_ENCODING_24BIT_INT 0xF2
#define LP_ENCODING_24BIT_INT_MASK 0xFF
#define LP_ENCODING_IS_24BIT_INT(byte) (((byte)&LP_ENCODING_24BIT_INT_MASK)==LP_ENCODING_24BIT_INT)
#define LP_ENCODING_24BIT_INT_ENTRY_SIZE 5
#define LP_ENCODING_32BIT_INT 0xF3
#define LP_ENCODING_32BIT_INT_MASK 0xFF
#define LP_ENCODING_IS_32BIT_INT(byte) (((byte)&LP_ENCODING_32BIT_INT_MASK)==LP_ENCODING_32BIT_INT)
#define LP_ENCODING_32BIT_INT_ENTRY_SIZE 6
#define LP_ENCODING_64BIT_INT 0xF4
#define LP_ENCODING_64BIT_INT_MASK 0xFF
#define LP_ENCODING_IS_64BIT_INT(byte) (((byte)&LP_ENCODING_64BIT_INT_MASK)==LP_ENCODING_64BIT_INT)
#define LP_ENCODING_64BIT_INT_ENTRY_SIZE 10
/*----------------------------------下面是字符串编码,上面是整数编码----------------------------------*/
#define LP_ENCODING_6BIT_STR 0x80
#define LP_ENCODING_6BIT_STR_MASK 0xC0
#define LP_ENCODING_IS_6BIT_STR(byte) (((byte)&LP_ENCODING_6BIT_STR_MASK)==LP_ENCODING_6BIT_STR)
#define LP_ENCODING_12BIT_STR 0xE0
#define LP_ENCODING_12BIT_STR_MASK 0xF0
#define LP_ENCODING_IS_12BIT_STR(byte) (((byte)&LP_ENCODING_12BIT_STR_MASK)==LP_ENCODING_12BIT_STR)
#define LP_ENCODING_32BIT_STR 0xF0
#define LP_ENCODING_32BIT_STR_MASK 0xFF
#define LP_ENCODING_IS_32BIT_STR(byte) (((byte)&LP_ENCODING_32BIT_STR_MASK)==LP_ENCODING_32BIT_STR)
我把宏的定义顺序调整了一下,源码是按空间占用排序。
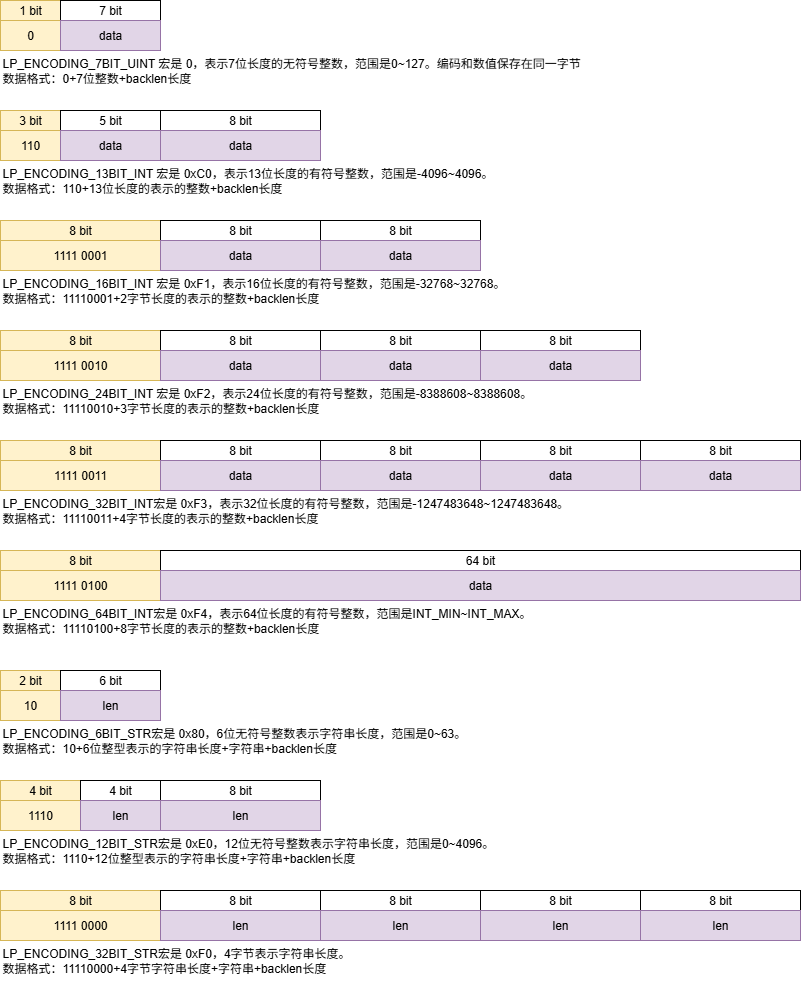
这里可以很明显的看到整数编码和字符串编码的区别。整数编码的编码字节本身就包含了整数类型和部分/全部值信息,后续字节(如果有)直接存储整数的剩余部分。没有单独存储长度字段。
而字符串编码的编码字节主要存储字符串的长度信息,实际字符串内容存储在长度信息之后。
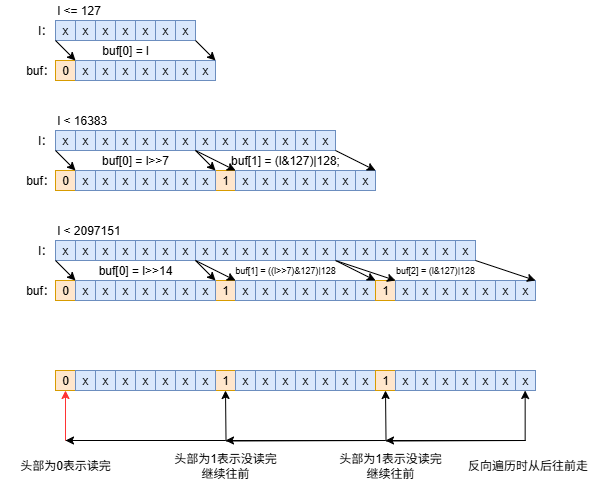
现在就还剩一个后置长度还没有分析。后置长度其实主要是为了方便反向遍历。在反向遍历读取需要确定什么时候把后置长度读完。所以在给后置长度赋值时也需要进行编码
//在lpInsert函数中给获取后置长度的长度时调用了lpEncodeBacklen函数,下面是lpEncodeBacklen函数的内容
static inline unsigned long lpEncodeBacklen(unsigned char *buf, uint64_t l) {
//l是enclen,也就是当前元素长度(包括前置的编码类型)
//具体的编码看下面的图吧
if (l <= 127) {
if (buf) buf[0] = l;
return 1;
} else if (l < 16383) {
if (buf) {
buf[0] = l>>7;
buf[1] = (l&127)|128;
}
return 2;
} else if (l < 2097151) {
if (buf) {
buf[0] = l>>14;
buf[1] = ((l>>7)&127)|128;
buf[2] = (l&127)|128;
}
return 3;
} else if (l < 268435455) {
if (buf) {
buf[0] = l>>21;
buf[1] = ((l>>14)&127)|128;
buf[2] = ((l>>7)&127)|128;
buf[3] = (l&127)|128;
}
return 4;
} else {
if (buf) {
buf[0] = l>>28;
buf[1] = ((l>>21)&127)|128;
buf[2] = ((l>>14)&127)|128;
buf[3] = ((l>>7)&127)|128;
buf[4] = (l&127)|128;
}
return 5;
}
}
后面几个的编码方式是一样的,就不重复画了。
函数里有很多((l>>7x)&127)|128;的语句,(l>>7x)&127其实就是拿7位数据,|128就是7位数据前面加个1;
最后一个图是,在解码backlen时进行的操作
函数解析
Listpack的一些关键函数其实之前在分析内存结构的时候已经讲了,比如创建Listpack就是lpNew函数在做。lpInsert函数负责插入、更新、删除。
现在还剩查找、遍历操作的函数没分析,这里主要分析查找、遍历函数
unsigned char *lpFirst(unsigned char *lp) {//获取 listpack 的第一个元素指针
unsigned char *p = lp + LP_HDR_SIZE; // 跳过 listpack 头部(总字节数+元素数量)指向第一个元素
if (p[0] == LP_EOF) return NULL;// 检查是否到达结束符(空 listpack)
lpAssertValidEntry(lp, lpBytes(lp), p);// 验证元素有效性(调试用)
return p;// 返回第一个元素的指针
}
unsigned char *lpLast(unsigned char *lp) {//获取 listpack 的最后一个元素指针
unsigned char *p = lp+lpGetTotalBytes(lp)-1; // 定位到 listpack 末尾(结束符 LP_EOF 的位置)
return lpPrev(lp,p); // 通过反向遍历找到最后一个元素
}
unsigned char *lpNext(unsigned char *lp, unsigned char *p) {//获取当前元素的下一个元素指针
assert(p);// 确保输入指针有效
p = lpSkip(p);// 跳过当前元素(编码+数据+后置长度)
if (p[0] == LP_EOF) return NULL;// 检查是否到达结束符
lpAssertValidEntry(lp, lpBytes(lp), p);// 验证元素有效性
return p;// 返回下一个元素指针
}
unsigned char *lpPrev(unsigned char *lp, unsigned char *p) {//获取当前元素的前一个元素指针
assert(p);// 确保输入指针有效
if (p-lp == LP_HDR_SIZE) return NULL;// 检查是否已在第一个元素(头部之后)
p--;// 后退1字节到后置长度字段的末尾
// 解码后置长度值(当前元素的总长度)
uint64_t prevlen = lpDecodeBacklen(p);
// 计算后置长度字段自身占用的字节数
prevlen += lpEncodeBacklen(NULL,prevlen);
// 向前跳转「元素总长度」字节,定位到前一个元素起始位置,-1 补偿上一步的后退操作
p -= prevlen-1;
lpAssertValidEntry(lp, lpBytes(lp), p);
return p;
}
//按索引查找元素(支持负数反向索引)
unsigned char *lpSeek(unsigned char *lp, long index) {
int forward = 1; // 遍历方向标志(1=正向,0=反向)
//获取元素总数
uint32_t numele = lpGetNumElements(lp);
// 已知元素数量的优化路径
if (numele != LP_HDR_NUMELE_UNKNOWN) {
// 处理负索引(从末尾倒数)
if (index < 0) index = (long)numele+index;
if (index < 0) return NULL;// 索引越界检查
if (index >= (long)numele) return NULL;
// 如果索引在后半部分,使用反向遍历更高效
if (index > (long)numele/2) {
forward = 0;
index -= numele;// 转换为负索引(如 index=3, numele=5 → index=-2)
}
} else {// 未知元素数量的情况
// 负索引直接使用反向遍历
if (index < 0) forward = 0;
}
// 正向遍历(从头开始)
if (forward) {
unsigned char *ele = lpFirst(lp);
while (index > 0 && ele) {
ele = lpNext(lp,ele);
index--;
}
return ele;
} else {// 反向遍历(从尾开始)
unsigned char *ele = lpLast(lp);
while (index < -1 && ele) {
ele = lpPrev(lp,ele);
index++;
}
return ele;
}
}
//解码元素值(返回字符串指针或设置整数值)
unsigned char *lpGet(unsigned char *p, int64_t *count, unsigned char *intbuf) {
// 实际实现会解析编码头,判断元素类型:
// - 字符串:返回字符串指针,长度存入 count
// - 整数:将整数值存入 count,返回 NULL
return lpGetWithSize(p, count, intbuf, NULL);
}
//值获取接口
unsigned char *lpGetValue(unsigned char *p, unsigned int *slen, long long *lval) {
unsigned char *vstr;
int64_t ele_len;// 临时存储长度/整数值
// 调用 lpGet 解析元素
vstr = lpGet(p, &ele_len, NULL);
// 处理结果
if (vstr) {
*slen = ele_len;// 字符串长度
} else {
*lval = ele_len;// 整数值
}
return vstr;// 字符串返回指针,整数返回 NULL
}
通过以上函数不难看出,listpack内部其实并没有独立的按值查找的函数。lpSeek函数是按位置(索引) 定位元素的函数。所以如果需要按值查找,需要先使用lpSeek或 lpFirst/lpNext/lpLast/lpPrev定位到元素然后用lpGet 解码元素的值,然后在应用层将解码后的值与目标值进行比较。
listpack内部的遍历和查找,因为内部元素前后都有相关的长度信息,正向遍历会用头部的编码计算元素的编码字节和数据存储字节长度,然后计算backlen的字节长度,通过指针移动的方式往后遍历;反向遍历则比较简单,解码backlen之后计算出当前元素占用的字节大小,往前移动对应的字节数,就是上一个元素。
Quicklist数据结构
Quicklist(快速列表)是 Redis 用于实现 List(列表)数据类型的默认底层数据结构。 它的本质是一个双向链表,但这个链表的每个节点本身不是一个简单的元素,而是一个listpack(原先是ziplist,但是在redis7.0版本之后ziplist已经被listpack取代了)。
Quicklist 的设计思想是:在双向链表的修改效率与压缩列表的内存效率之间取得最佳平衡,它是一种经典的 “空间换时间” 和 “时间换空间” 权衡下的混合型数据结构。
-
混合结构:链表框架+压缩列表内容
- 这是最根本的思想。Quicklist 不是一个全新的底层结构,而是一个组织者和协调者。
- 链表框架 (宏观结构): 使用一个双向链表作为框架。这使得在头部和尾部的节点插入和删除操作时间复杂度为 O(1),完美继承了链表的修改优势。
- 压缩列表内容 : 每个链表节点内部并不直接存储数据,而是包含一个listpack。这使得在单个节点内,可以紧凑地存储多个元素,消除了传统链表每个元素都需要两个指针的巨大内存开销,继承了压缩列表的内存优势。
-
关键结构体
-
//列表节点 typedef struct quicklistNode { struct quicklistNode *prev; // 指向前驱节点的指针 struct quicklistNode *next; // 指向后继节点的指针 unsigned char *entry; // 指向实际数据的指针(listpack 或压缩数据) size_t sz; // 节点数据的总大小(字节数) // 位域字段(节省内存) unsigned int count : 16; // 节点内存储的元素数量(最大 65535) unsigned int encoding : 2; // 编码类型:0-未压缩,1-LZF压缩 unsigned int container : 2; // 容器类型:1-ziplist,2-listpack unsigned int recompress : 1; // 临时解压标志(访问后需重新压缩) unsigned int attempted_compress : 1; // 压缩尝试标志(测试用) unsigned int dont_compress : 1;// 禁止压缩标志(如小数据节点) unsigned int extra : 9; // 保留位(未来扩展) } quicklistNode; typedef struct quicklist { quicklistNode *head; // 指向链表头节点 quicklistNode *tail; // 指向链表尾节点 unsigned long count; // 所有节点中元素的总数 unsigned long len; // 节点数量(链表长度) // 位域字段(配置参数) signed int fill : QL_FILL_BITS;// 节点大小限制 unsigned int compress : QL_COMP_BITS; // 压缩深度 //正数:每个节点最多包含的元素个数(如 512) //负数:每个节点最大字节数(如 -1=4KB, -2=8KB) unsigned int bookmark_count: QL_BM_BITS;// 书签数量 quicklistBookmark bookmarks[];// 书签数组 } quicklist; typedef struct quicklistLZF { size_t sz; // 压缩后的数据大小 char compressed[]; // LZF压缩数据(柔性数组) } quicklistLZF;
-
内存结构分析
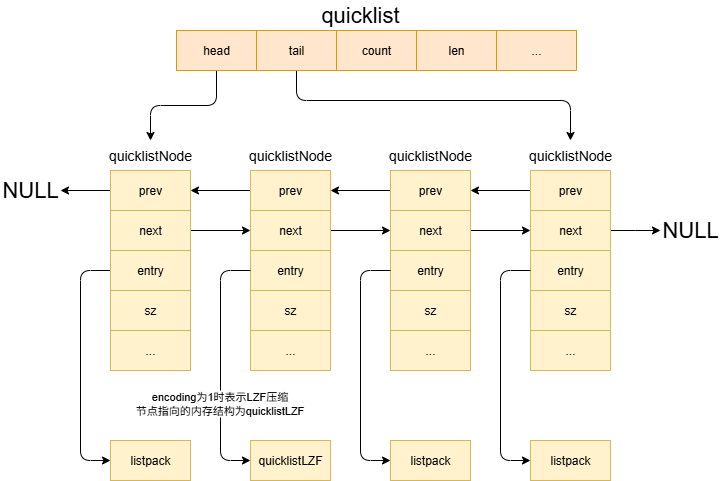
通过上面的结构体可以大致分析出quicklist的内存结构,对外是一个双向链表可以进行快速的节点操作。实际的数据存储是用listpack进行高密度的存储,并且还可以根据需要使用LZF进行数据压缩。
函数解析
创建与销毁函数
//创建quicklist
quicklist *quicklistCreate(void) {
//分配内存空间
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
//初始化成员变量
quicklist->head = quicklist->tail = NULL;// 头和尾指针都设为 NULL (空列表)
quicklist->len = 0; // 节点数量为 0
quicklist->count = 0; // 元素总数为 0
quicklist->compress = 0; // 压缩深度为 0 (表示不压缩)
quicklist->fill = -2; // 填充因子设为 -2 (特殊值,通常由配置决定,-2表示每个节点最多为8KB)
quicklist->bookmark_count = 0; // 书签数量为 0 (用于迭代优化)
return quicklist; // 返回新创建的quicklist
}
//销毁quicklist
void quicklistRelease(quicklist *quicklist) {
// 准备遍历变量
unsigned long len;
quicklistNode *current, *next;
// 从头部开始遍历
current = quicklist->head;// 获取第一个节点
len = quicklist->len; // 获取节点总数
// 循环遍历并销毁所有节点
while (len--) {// 循环次数 = 节点数量
// 保存下一个节点的指针 (避免释放后丢失)
next = current->next;
// 释放当前节点存储的数据
zfree(current->entry);
// 更新 quicklist 的总元素计数
quicklist->count -= current->count;
// 释放当前节点结构体本身
zfree(current);
// 更新 quicklist 的节点计数
quicklist->len--;
// 移动到下一个节点
current = next;
}
// 清理书签 (如果有),释放书签相关资源
quicklistBookmarksClear(quicklist);
zfree(quicklist);// 释放 quicklist 结构体本身
}
- quicklistCreate: 创建一个新的、空的快速列表。它初始化了所有必要的字段,为添加元素做好准备。
- quicklistRelease: 彻底销毁一个快速列表及其所有内容。它负责安全地遍历所有节点,释放节点内存储的数据(listpack/ziplist 或压缩数据块),释放节点结构体本身,清理辅助结构(书签),最后释放列表结构体。
插入操作函数
/* 在快速列表头部插入新元素 */
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head; // 保存原始头节点指针
// 处理超大元素特殊情况
if (unlikely(isLargeElement(sz))) {
// 创建独立节点存储大元素,插入在头节点之前
__quicklistInsertPlainNode(quicklist, quicklist->head, value, sz, 0);
return 1;// 头节点已改变,返回1
}
// 常规元素插入
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
// 情况1:头节点还有空间
// 在头节点的listpack头部插入新元素
quicklist->head->entry = lpPrepend(quicklist->head->entry, value, sz);
// 更新头节点的大小信息
quicklistNodeUpdateSz(quicklist->head);
} else {
// 情况2:头节点已满
// 创建新节点
quicklistNode *node = quicklistCreateNode();
// 创建新listpack并在头部插入元素
node->entry = lpPrepend(lpNew(0), value, sz);
// 更新新节点的大小信息
quicklistNodeUpdateSz(node);
// 将新节点插入到当前头节点之前
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
// 更新列表和节点的元素计数
quicklist->count++; // 列表总元素数+1
quicklist->head->count++; // 头节点元素数+1
// 返回头节点是否改变(新节点成为头节点)
return (orig_head != quicklist->head);
}
/* 在快速列表尾部插入新元素,具体操作与头部插入元素非常相似这里就不做注释了 */
int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_tail = quicklist->tail;
if (unlikely(isLargeElement(sz))) {
__quicklistInsertPlainNode(quicklist, quicklist->tail, value, sz, 1);
return 1;
}
if (likely(
_quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
quicklist->tail->entry = lpAppend(quicklist->tail->entry, value, sz);
quicklistNodeUpdateSz(quicklist->tail);
} else {
quicklistNode *node = quicklistCreateNode();
node->entry = lpAppend(lpNew(0), value, sz);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeAfter(quicklist, quicklist->tail, node);
}
quicklist->count++;
quicklist->tail->count++;
return (orig_tail != quicklist->tail);
}
/* 在指定元素前插入新元素 */
void quicklistInsertBefore(quicklistIter *iter, quicklistEntry *entry,
void *value, const size_t sz)
{
// 调用内部插入函数,0表示在指定元素前插入
_quicklistInsert(iter, entry, value, sz, 0);
}
/* 在指定元素后插入新元素 */
void quicklistInsertAfter(quicklistIter *iter, quicklistEntry *entry,
void *value, const size_t sz)
{
// 调用内部插入函数,1表示在指定元素后插入
_quicklistInsert(iter, entry, value, sz, 1);
}
这边就不展开源码了,具体流程直接看下面的图吧
删除操作函数
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry) {
// 保存当前节点的前后节点指针
quicklistNode *prev = entry->node->prev;
quicklistNode *next = entry->node->next;
// 执行实际删除操作
int deleted_node = quicklistDelIndex((quicklist *)entry->quicklist,
entry->node, &entry->zi);
// 重置迭代器的当前元素指针
iter->zi = NULL;
// 如果整个节点被删除,更新迭代器位置
if (deleted_node) {
if (iter->direction == AL_START_HEAD) {
iter->current = next; // 从头遍历:移动到下一个节点
iter->offset = 0; // 重置为节点开头
} else if (iter->direction == AL_START_TAIL) {
iter->current = prev; // 从尾遍历:移动到前一个节点
iter->offset = -1; // 重置为节点末尾
}
}
}
int quicklistPop(quicklist *quicklist, int where, unsigned char **data,
size_t *sz, long long *slong) {
unsigned char *vstr;
size_t vlen;
long long vlong;
// 检查空列表
if (quicklist->count == 0)
return 0;
// 调用通用弹出函数
int ret = quicklistPopCustom(quicklist, where, &vstr, &vlen, &vlong,
_quicklistSaver);
// 设置返回参数
if (data)
*data = vstr;
if (slong)
*slong = vlong;
if (sz)
*sz = vlen;
return ret;
}
int quicklistDelRange(quicklist *quicklist, const long start,
const long count) {
// 检查无效范围
if (count <= 0)
return 0;
// 计算实际要删除的数量
unsigned long extent = count;
if (start >= 0 && extent > (quicklist->count - start)) {
extent = quicklist->count - start;// 限制不超过列表尾部
} else if (start < 0 && extent > (unsigned long)(-start)) {
extent = -start; // 限制不超过列表头部
}
// 获取起始位置的迭代器
quicklistIter *iter = quicklistGetIteratorAtIdx(quicklist, AL_START_TAIL, start);
if (!iter)
return 0;
D("Quicklist delete request for start %ld, count %ld, extent: %ld", start,
count, extent);
// 保存起始节点和偏移量
quicklistNode *node = iter->current;
long offset = iter->offset;
quicklistReleaseIterator(iter);
// 循环删除指定数量的元素
while (extent) {
quicklistNode *next = node->next;
unsigned long del;
int delete_entire_node = 0;
// 计算本次删除数量
if (offset == 0 && extent >= node->count) {
delete_entire_node = 1;// 删除整个节点
del = node->count;
} else if (offset >= 0 && extent + offset >= node->count) {
del = node->count - offset;// 删除节点剩余部分
} else if (offset < 0) {
del = -offset;// 从尾部开始删除
if (del > extent)
del = extent;
} else {
del = extent;// 删除部分元素
}
D("[%ld]: asking to del: %ld because offset: %d; (ENTIRE NODE: %d), "
"node count: %u",
extent, del, offset, delete_entire_node, node->count);
// 执行删除操作
if (delete_entire_node || QL_NODE_IS_PLAIN(node)) {
__quicklistDelNode(quicklist, node);// 删除整个节点
} else {
quicklistDecompressNodeForUse(node);// 解压节点
node->entry = lpDeleteRange(node->entry, offset, del);// 删除范围元素
quicklistNodeUpdateSz(node);// 更新节点大小
node->count -= del; // 更新节点元素计数
quicklist->count -= del; // 更新列表总计数
quicklistDeleteIfEmpty(quicklist, node); // 检查并删除空节点
if (node)
quicklistRecompressOnly(node); // 重新压缩节点
}
// 更新剩余删除数量
extent -= del;
node = next;
offset = 0;// 后续节点从开头删除
}
return 1;
}
查找与遍历函数
//创建迭代器
quicklistIter *quicklistGetIterator(quicklist *quicklist, int direction) {
//分配迭代器内存
quicklistIter *iter;
iter = zmalloc(sizeof(*iter));
// 设置起始位置
if (direction == AL_START_HEAD) {// 从头开始
iter->current = quicklist->head;
iter->offset = 0; // 指向第一个元素
} else if (direction == AL_START_TAIL) { // 从尾开始
iter->current = quicklist->tail;
iter->offset = -1; // 指向最后一个元素
}
iter->direction = direction; // 保存遍历方向
iter->quicklist = quicklist; // 关联的quicklist
iter->zi = NULL; // 当前元素指针初始化为NULL
return iter;
}
//通过迭代器遍历函数
int quicklistNext(quicklistIter *iter, quicklistEntry *entry) {
// 初始化entry结构
initEntry(entry);
if (!iter) {
D("Returning because no iter!");
return 0;
}
// 设置entry的快速列表和当前节点
entry->quicklist = iter->quicklist;
entry->node = iter->current;
// 如果当前节点为空,说明遍历结束
if (!iter->current) {
D("Returning because current node is NULL");
return 0;
}
// 对于listpack节点,根据方向获取下一个元素
unsigned char *(*nextFn)(unsigned char *, unsigned char *) = NULL;
int offset_update = 0;
// 判断当前节点是否为普通节点(非listpack编码,即只有一个元素)
int plain = QL_NODE_IS_PLAIN(iter->current);
// 如果当前节点还没有开始遍历(zi为NULL),则初始化
if (!iter->zi) { // 首次访问节点
quicklistDecompressNodeForUse(iter->current); // 解压节点(如果需要)
if (unlikely(plain))
// 如果是普通节点,直接使用节点的entry
iter->zi = iter->current->entry;
else
// 否则,在listpack中定位到偏移量iter->offset处的元素
iter->zi = lpSeek(iter->current->entry, iter->offset);
} else if (unlikely(plain)) {
// 如果已经是普通节点,那么只有一个元素,已经处理过,将zi置为NULL
iter->zi = NULL;
} else {
// 根据方向选择下一个元素的函数
if (iter->direction == AL_START_HEAD) {
nextFn = lpNext; // 正向:下一个元素
offset_update = 1; // 偏移量增加
} else if (iter->direction == AL_START_TAIL) {
nextFn = lpPrev; // 反向:上一个元素
offset_update = -1;// 偏移量减少
}
// 获取下一个元素
iter->zi = nextFn(iter->current->entry, iter->zi);
iter->offset += offset_update;
}
// 设置entry中的当前元素指针和偏移量
entry->zi = iter->zi;
entry->offset = iter->offset;
// 如果当前元素指针不为空
if (iter->zi) {
if (unlikely(plain)) {
// 普通节点:直接返回整个节点的值
entry->value = entry->node->entry;
entry->sz = entry->node->sz;
return 1;
}
// 否则,从listpack元素中获取值
unsigned int sz = 0;
// 获取元素的值(可能是字符串或整数)
entry->value = lpGetValue(entry->zi, &sz, &entry->longval);
entry->sz = sz;
return 1;
} else {
// 当前节点没有更多元素,压缩当前节点(如果是压缩节点)
quicklistCompress(iter->quicklist, iter->current);
// 移动到下一个节点
if (iter->direction == AL_START_HEAD) {
// 正向:移动到下一个节点
D("Jumping to start of next node");
iter->current = iter->current->next;
iter->offset = 0;// 新节点从第一个元素开始
} else if (iter->direction == AL_START_TAIL) {
// 反向:移动到上一个节点
D("Jumping to end of previous node");
iter->current = iter->current->prev;
iter->offset = -1;// 新节点从最后一个元素开始
}
iter->zi = NULL;// 重置当前元素指针
// 递归调用,继续获取下一个元素
return quicklistNext(iter, entry);
}
}
quicklist的查找和遍历操作主要通过,quicklistIter和quicklistEntry两个结构体配合完成,quicklistIter是quicklist的迭代器,quicklistEntry是元素条目结构体。
quicklistIter负责负责管理遍历的 “状态”,包括当前遍历位置、方向、所属的 quicklist 等,
quicklistEntry负责保存 “当前遍历到的元素” 的具体信息(如元素的指针、长度、所在的 listpack 等)。
Intset数据结构
Redis的IntSet(整数集合)是一种用于存储整数值的高效数据结构,特别适用于当集合只包含整数且元素数量较少时。Intset的主要特点是内存紧凑,支持整数类型升级(当添加更大范围的整数时自动升级存储类型),并且保持元素有序。
Intset相对来说比较简单,不管是内存结构还是对应的函数都是如此。这里就简单分析一下内存结构,如果对Intset的函数感兴趣可以自己根据源码进行分析。
-
关键结构体:
typedef struct intset { uint32_t encoding;//编码方式,决定元素类型 uint32_t length; //元素个数 int8_t contents[];//存储实际元素,按升序排列 } intset; //encoding的几种编码方式 #define INTSET_ENC_INT16 (sizeof(int16_t))//存储 int16_t 类型整数 #define INTSET_ENC_INT32 (sizeof(int32_t))//存储 int32_t 类型整数 #define INTSET_ENC_INT64 (sizeof(int64_t))//存储 int64_t 类型整数
内存结构分析
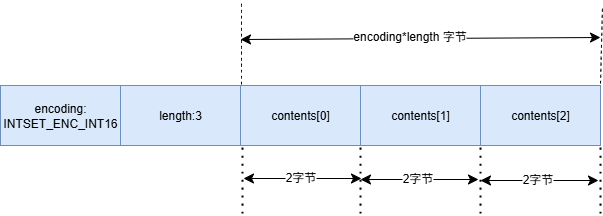
Skiplist数据结构
在Redis中Skiplist是zset(有序集合)的基础数据结构。跳跃表是一种有序的、概率平衡的数据结构,它通过维护多个层次的链表来实现快速查找,其效率可以媲美平衡树。
Skiplist首先它是一个list,实际上它是在有序链表的基础上发展起来的。
普通的有序链表就是所有元素已递增或递减方式有序排列的数据结构,其中每个节点又有指向下一个节点的next指针,最后一个节点的next指针指向NULL

如图,如果我们需要查找某一个元素,需要进行遍历,最差的情况需要把这个链表都遍历一遍,时间复杂度为O(N)。而有序链表的插入、修改和删除操作都需要先找到合适的位置再修改next指针,而修改操作基本不消耗时间,所以有序链表相关操作的耗时主要在查找元素上。
假如我们每相邻两个节点增加一个指针指向下下节点,如下图

新增的指针会形成一个新的链表。当我们要查找46时,如果通过新增的上层链表查询,遍历的次数只有原来的一半
利用同样的方式,我们可以在上层新产生的链表上,继续新增第三层。如下图:
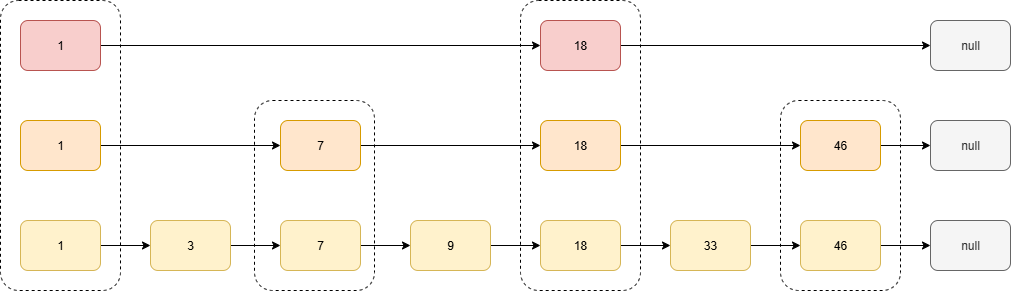
这时候如果再去找46,通过最上层只能找到18,然后通过比对会发现18<46,此时就会去下一层找,在下一层能找到46,所以他的查找顺序为:第三层1->第三层18->第二层18->第二层46。这种多层链表是典型的空间换时间。
skiplist就是受这种多层链表的想法启发设计的。
按上面的生成链表的方式,上面每一层链表的节点数是下面的节点个数的一半,这样查找的过程跟二分查找十分相似,这让查找的时间复杂度降到O(logN)。
但是上面的这种多层链表结构,如果新插入(或删除)一个节点之后会打乱相邻两次链表的节点数2:1的对应关系。如果想维持就得重新调整节点层级。
为了避免这个问题skiplist的每个节点的层级数随机层级。至于怎么随机,后面再详细讲解。
-
关键结构体
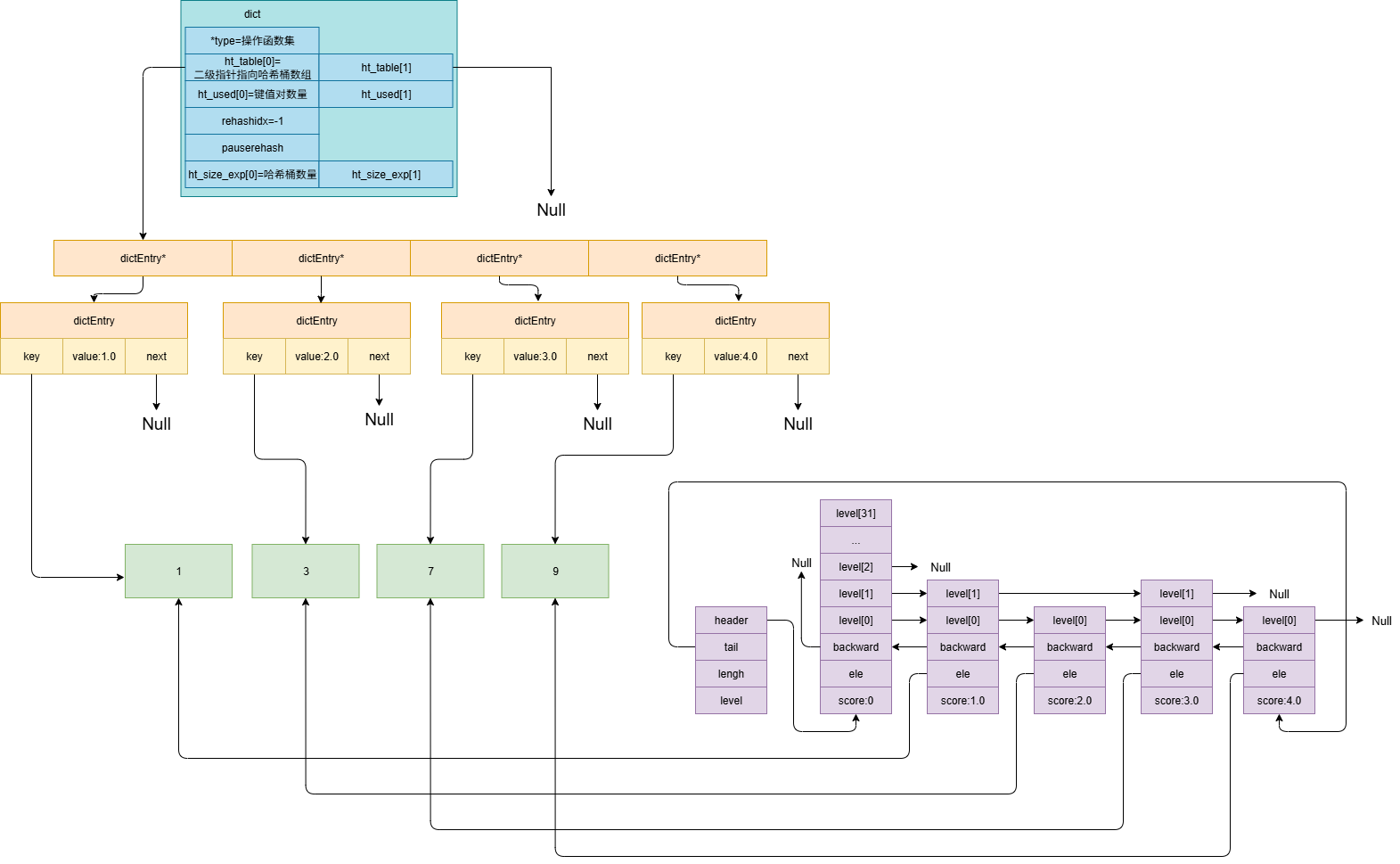
typedef struct zskiplistNode { sds ele;// 存储的元素内容 double score; //元素的分数(用于排序) struct zskiplistNode *backward;// 后向指针(指向前一个节点,用于双向遍历) struct zskiplistLevel { struct zskiplistNode *forward;// 前向指针(指向同一层的下一个节点) unsigned long span;// 当前节点到forward节点的跨度(距离) } level[];// 柔性数组,表示节点的多层索引 } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail;// 头节点和尾节点 unsigned long length; // 跳表节点总数 int level; // 当前跳表的最大层数 } zskiplist; typedef struct zset { dict *dict; // 哈希表,存储元素到分数的映射(ele -> score) zskiplist *zsl; // 跳表,按分数排序存储元素(ele + score) } zset;
光看这几个结构体,会发现zset里有两个结构体指针,一个是哈希表,一个现在分析的跳表的。那具体的数据要分别存储两遍吗?当然不是,在 Redis 的 zset(有序集合)实现中,元素(ele)和分数(score)的实际数据并不会存储两遍,而是通过 指针共享 和 结构设计 避免内存浪费。
内存结构分析
1、数据存储的共享机制
- dict(哈希表):
- 存储 ele -> score的映射,其中 ele是键(key),score是值(value)。
- ele的存储:哈希表的键直接指向跳表节点中的 ele,两者共享同一份字符串内存(SDS 结构)
- score的存储:哈希表的值(score)是 double类型,直接存储数值(不涉及指针)
- 存储 ele -> score的映射,其中 ele是键(key),score是值(value)。
- zsl(跳表)
- 跳表节点 zskiplistNode中同样包含 ele和 score
- ele:直接使用哈希表中 ele的指针(同一份 SDS 字符串)。
- score:存储与哈希表中相同的 double值(数值复制,但 double仅占 8 字节,开销小)
- 跳表节点 zskiplistNode中同样包含 ele和 score
关键点:
- ele(元素内容)只存一份,通过指针共享(哈希表和跳表节点指向同一个 SDS 字符串)。
- score(分数)存两份,但 double是小型基础类型,内存占用可忽略。
下面是具体的内存结构:
函数分析
创建函数
#define ZSKIPLIST_MAXLEVEL 32
//创建跳跃表节点
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
// 分配节点内存
zskiplistNode *zn = zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
// 设置节点属性
zn->score = score; // 节点分值(排序依据)
zn->ele = ele; // 节点存储的实际数据(SDS字符串)
return zn;
}
//创建跳跃表结构
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
// 分配跳表结构内存
zsl = zmalloc(sizeof(*zsl));
// 初始化跳表属性
zsl->level = 1; // 当前最大层数(初始为1)
zsl->length = 0; // 节点数量(不含头节点)
// 创建头节点(特殊节点,不存储实际数据), 直接创建最大层级32层,ZSKIPLIST_MAXLEVEL=32
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
// 初始化头节点的各层指针
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL; // 初始无后续节点
zsl->header->level[j].span = 0; // 初始跨度为0
}
// 设置后向指针
zsl->header->backward = NULL; // 头节点无前驱
zsl->tail = NULL; // 初始无尾节点
return zsl;
}
Redis在创建跳表时,会直接创建一个头节点,该头节点会创建最大层级也就是32层。并且不会存储实际数据。
zslCreateNode负责创建单个节点,节点包含一个柔性数组,数组长度由节点层数决定。zslCreate负责创建整个跳表结构,包括初始化跳表元数据和一个头节点(头节点拥有最大层数,但初始时每一层都指向NULL)。
插入函数
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
// update[]: 记录每层的前驱节点(插入位置)
// rank[]: 记录每层前驱节点的累积跨度(用于计算排名)
// x: 当前遍历节点
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned long rank[ZSKIPLIST_MAXLEVEL];
int i, level;
// 确保分值有效
serverAssert(!isnan(score));
// 从头节点开始遍历
x = zsl->header;
// 步骤1: 从最高层向最底层遍历,查找插入位置
for (i = zsl->level-1; i >= 0; i--) {
// 初始化当前层级的rank值:
// 如果是最高层,rank初始为0
// 否则继承上一层的rank值(因为是从高层向低层遍历)
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 在当前层级向右遍历,直到找到合适的插入位置:
// 1. 下一个节点存在
// 2. 下一个节点的分值小于目标分值
// 3. 或者分值相同但元素字典序小于目标元素
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
// 累加当前层级的跨度值
rank[i] += x->level[i].span;
// 移动到下一个节点
x = x->level[i].forward;
}
// 记录当前层的前驱节点
update[i] = x;
}
// 步骤2: 为新节点生成随机层数
level = zslRandomLevel();
// 步骤3: 如果新层数超过当前最大层数,需要扩展层级
if (level > zsl->level) {
// 从当前最大层数开始,直到新层数
for (i = zsl->level; i < level; i++) {
rank[i] = 0; // 初始化新增层的rank为0
update[i] = zsl->header;// 新增层的前驱节点为头节点
update[i]->level[i].span = zsl->length; // 头节点到NULL的跨度为整个跳表长度
}
// 更新跳表的最大层数
zsl->level = level;
}
// 步骤4: 创建新节点
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
// 更新前向指针:
// 新节点的forward指向原前驱节点的forward
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
// 更新跨度:
// 新节点的跨度 = 原前驱跨度 - (底层rank - 当前层rank)
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
// 步骤6: 更新未涉及层的跨度
// 对于新节点未达到的层,增加前驱节点的跨度(因为新增了一个节点)
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 步骤7: 更新后退指针(维护双向链表)
// 设置新节点的后退指针:
// 如果前驱是头节点,则backward为NULL
// 否则指向update[0](即最底层的前驱节点)
x->backward = (update[0] == zsl->header) ? NULL : update[0];
// 更新后继节点的后退指针:
if (x->level[0].forward)
// 如果新节点有后继,设置其后继的backward指向新节点
x->level[0].forward->backward = x;
else
// 否则新节点是尾节点,更新跳表的tail指针
zsl->tail = x;
// 步骤8: 更新跳表状态
zsl->length++;
return x; // 返回新插入的节点
}
/* 随机生成节点层数(基于幂次定律) */
int zslRandomLevel(void) {
// 计算概率阈值:ZSKIPLIST_P * RAND_MAX
// Redis默认ZSKIPLIST_P=0.25
static const int threshold = ZSKIPLIST_P*RAND_MAX;
// 初始层数为1
int level = 1;
// 循环:有25%的概率增加一层
//random()会返回一个0-1的随机数,该随机数如果小于0.25则层级+1
while (random() < threshold)
level += 1;
// 确保层数不超过最大层数(32)
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
前面提到的随机层级就是通过zslRandomLevel()函数创建。在新增节点时会调用zslRandomLevel函数给新节点设置随机节点。
删除函数
//节点删除函数
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
// 步骤1: 更新各层前驱节点的指针和跨度
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
// 情况1: 前驱节点直接指向待删除节点
// 合并跨度: 前驱节点跨度 = 原跨度 + x节点的跨度 - 1
update[i]->level[i].span += x->level[i].span - 1;
// 更新指针: 跳过x节点,直接连接x的下一个节点
update[i]->level[i].forward = x->level[i].forward;
} else {
// 情况2: 前驱节点不直接指向x(x不在该层)
// 只需将前驱节点的跨度减1(因为删除了一个在它后面的节点)
update[i]->level[i].span -= 1;
}
}
// 步骤2: 更新后退指针(维护双向链表)
if (x->level[0].forward) {
// 如果x有后继节点,更新其后继节点的backward指针
x->level[0].forward->backward = x->backward;
} else {
// 如果x是尾节点,更新跳表的尾指针
zsl->tail = x->backward;
}
// 步骤3: 调整跳表层数(如果最高层变为空)
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;// 降低跳表的最大层数
zsl->length--;// 步骤4: 更新跳表长度
}
查找函数
//查找范围内第一个节点
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range) {
zskiplistNode *x;
int i;
// 步骤1: 检查整个跳表是否有节点在范围内
if (!zslIsInRange(zsl,range)) return NULL;
// 步骤2: 从头节点开始
x = zsl->header;
// 步骤3: 从最高层向最底层遍历
for (i = zsl->level-1; i >= 0; i--) {
// 向右遍历,直到找到大于等于范围最小值的节点
while (x->level[i].forward &&
!zslValueGteMin(x->level[i].forward->score,range))
x = x->level[i].forward;
}
// 步骤4: 移动到最底层的下一个节点(即第一个候选节点)
x = x->level[0].forward;
serverAssert(x != NULL);// 确保节点存在
// 步骤5: 验证节点是否在范围内(最大值边界)
if (!zslValueLteMax(x->score,range)) return NULL;
return x;
}
unsigned long zslGetRank(zskiplist *zsl, double score, sds ele) {
zskiplistNode *x;
unsigned long rank = 0;// 初始化排名为0
int i;
// 从头节点开始遍历
x = zsl->header;
// 步骤1: 从最高层向最底层遍历
for (i = zsl->level-1; i >= 0; i--) {
// 在当前层级向右遍历
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) <= 0))) {
// 累加当前层级的跨度值
rank += x->level[i].span;
// 移动到下一个节点
x = x->level[i].forward;
}
// 步骤2: 检查当前节点是否匹配目标
if (x->ele && x->score == score && sdscmp(x->ele,ele) == 0) {
return rank;// 返回计算出的排名
}
}
return 0;// 未找到目标节点
}
总结
- redisObject 是 Redis 所有数据类型的统一载体,通过 type 标识数据类型、encoding 标识内部编码,实现同一类型的多态存储,平衡性能和内存效率;
- SDS 替代 C 字符串,以多态 Header 适配不同长度字符串优化内存,兼具 C 字符串兼容性、自动扩容(小字符串加倍 / 大字符串增 1MB)、二进制安全(靠 len 标识长度)特性;
- String 对象依值特性自动选编码:整数(≤20 位)用 INT 编码存整数到 ptr,短字符串(≤44 字节)用 EMBSTR 实现连续内存分配,长字符串用 RAW 分开分配;
- HashTable 靠链式哈希解决冲突,通过渐进式 rehash 分批次迁移数据,避免扩容 / 缩容时的性能波动,支撑 Hash 类型与全局键值对存储
- Listpack:Redis7.0 后替代 Ziplist,解决级联更新痛点,内存结构含前 4 字节总长度、5-6 字节元素数、尾部 EOF,元素分整数(编码含类型 + 值,无单独长度)与字符串(编码存长度 + 内容),还通过 backlen 字段支持反向遍历。
- Quicklist:是 List 类型默认底层结构,本质是 “双向链表 + Listpack 节点” 的混合结构 —— 双向链表框架保障两端 O (1) 操作,每个节点包裹 Listpack 实现紧凑存储,支持 LZF 压缩,元素插入 / 删除时会判断节点容量,满则新建节点,大元素则单独建节点,平衡内存效率和操作性能。
- Intset:Set 类型的紧凑编码(适用于全整数、少数量场景),结构含 encoding(存 int16/32/64 类型)、length(元素个数)、contents(有序整数数组)。
- Skiplist:ZSet 类型核心结构,与 HashTable 协同工作 ——Skiplist(跳表)按分数有序存储元素,通过随机层级(25% 概率升层,最大 32 层)实现 O (logN) 范围查询,节点含 forward 指针(同层下一个节点)与 span(节点跨度);HashTable 映射元素到分数,实现 O (1) 获取分数,两者共享元素 SDS 内存(避免重复存储)。
本篇主要分析Redis中5种数据类型的底层内存结构,学习其中设计的精妙之处。对于一些函数的解析主要用注释进行,而且不少函数其实没有提到,不过这些函数都是基于不太类型的内存结构进行操作的,弄懂了内存结构再去看那些函数就会变得简单。


















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










