




过去一年,大家讨论 Agent 时最常问的是:模型够不够聪明?能不能写代码?能不能自动调工具?
但真正把 Agent 放到企业里跑一段时间后,另一个问题会很快冒出来:它到底花了多少钱?
Chatbot 的成本相对容易理解:用户问一句,模型答一句。Agent 不一样。它会规划、检索、调用工具、观察结果、修正计划、继续执行,最后还可能让 evaluator 再判断一次有没有完成。一次看似普通的任务,背后可能变成十几次模型调用。
这也是最近行业里“Agent FinOps”开始变得重要的原因。强模型能力越来越强,但也越来越适合被放在“关键路径”上,而不是所有请求都默认调用。企业需要的不是一个更贵的默认模型,而是一套能控制成本、延迟和稳定性的 Agent Runtime。
1. 为什么 Agent 比 Chatbot 更容易烧钱
Agent 的 token 成本不是线性的。
一个普通聊天请求通常是:
用户输入 -> 模型回复
但一个能执行任务的 Agent 往往是:
用户目标 -> 生成计划 -> 调工具 -> 读结果 -> 再推理 -> 再调工具 -> 评估完成度 -> 继续或停止
如果再加上企业场景里常见的知识库、审批、审计、多 Agent 分工、长上下文和多渠道入口,成本会继续放大。
更麻烦的是,Agent 的消耗经常发生在“后台”。用户看到的只是一个回答,但运行时可能已经完成了多轮中间推理。开发者如果只看最终输出,很难判断:
- 哪一步最耗 token;
- 哪个模型被实际调用;
- fallback 后是不是用了更贵的模型;
- 工具失败导致的重试有没有反复烧钱;
- 长任务是不是已经超出预算。
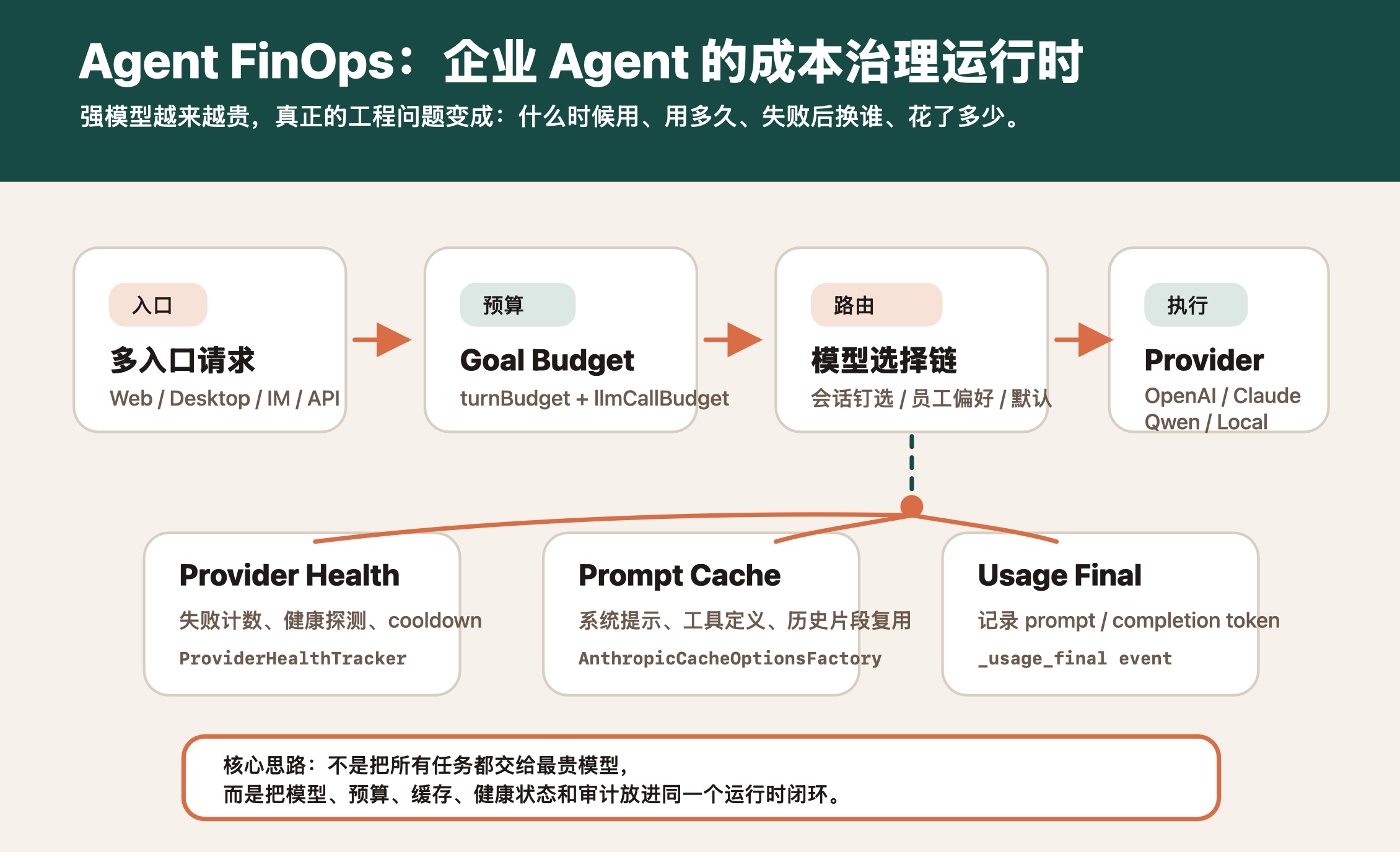
所以企业 Agent 的第一性问题不是“接入最强模型”,而是:把模型调用变成可路由、可计量、可降级、可停止的运行时行为。
2. 成本治理不是简单限额,而是运行时策略
很多系统会把成本治理理解成“给用户设置一个 token 上限”。这当然有用,但不够。
Agent 的成本治理至少要包含五层:
| 层次 | 解决的问题 |
|---|---|
| 模型池 | 不把所有任务绑死到一个供应商 |
| 模型路由 | 低价值任务用便宜模型,高价值任务再上强模型 |
| 健康检查 | provider 出错时不要每轮都重试 |
| 预算控制 | 长任务有 turn budget 和 LLM call budget |
| 用量归因 | 最终知道谁用了多少 token、用了哪个模型 |
这五层合起来,才像一个 Agent FinOps 的雏形。

3. 从 MateClaw 源码看:模型路由已经不是“配置项”
MateClaw 的模型系统不是只在配置文件里写一个 modelName。
从文档和源码可以看到,它把模型拆成了 provider 和 model config 两层:
- provider 代表供应商,比如 OpenAI、Anthropic、DashScope、Ollama、LM Studio 等;
- model config 代表具体模型、分组、能力、最大输出、温度等;
- embedding、vision、chat 等模型类型都进入统一配置体系;
- 不同员工可以有自己的 provider preference;
- 会话级 ModelSelector 又可以覆盖员工或全局默认模型。
这意味着模型选择不是一次性静态配置,而是运行时决策链:
会话钉选模型
-> 员工自己的模型覆盖
-> 全局默认模型
-> 员工 provider 偏好链
-> 能力门禁和 fallback
这个设计对成本治理很关键。因为企业里并不是每个 Agent、每类任务、每次会话都值得使用最贵模型。
比如:
- FAQ、格式化、分类、摘要,可以走快模型或本地模型;
- 代码库级改造、复杂架构判断、关键审批前复核,才走强推理模型;
- 图片、文档、语音等多模态任务,先根据能力路由,而不是盲目报错;
- 某个 provider 限流或故障时,运行时自动切到下一个可用模型。
这就是“模型路由”从配置项变成 FinOps 策略的地方。
4. ProviderHealthTracker:不要让坏 provider 反复消耗预算
成本治理还有一个容易被忽略的点:失败也会花钱,失败还会花时间。
如果一个 provider 的 API key 失效、余额不足、网络抖动、持续 5xx,而系统每次请求都先撞它一下,再 fallback 到下一个模型,那么用户每轮都要等一次失败,Agent 每轮都要消耗一次重试预算。
MateClaw 在 ProviderHealthTracker 里做了一个很朴素但有效的机制:
- 每个 provider 记录连续失败次数;
- 达到阈值后进入 cooldown;
- cooldown 期间 fallback 链直接跳过它;
- 一旦成功调用,失败计数归零,并清除 cooldown;
- 当前实现是进程内状态,适合桌面端和单节点部署,后续可以扩展成数据库级健康表。
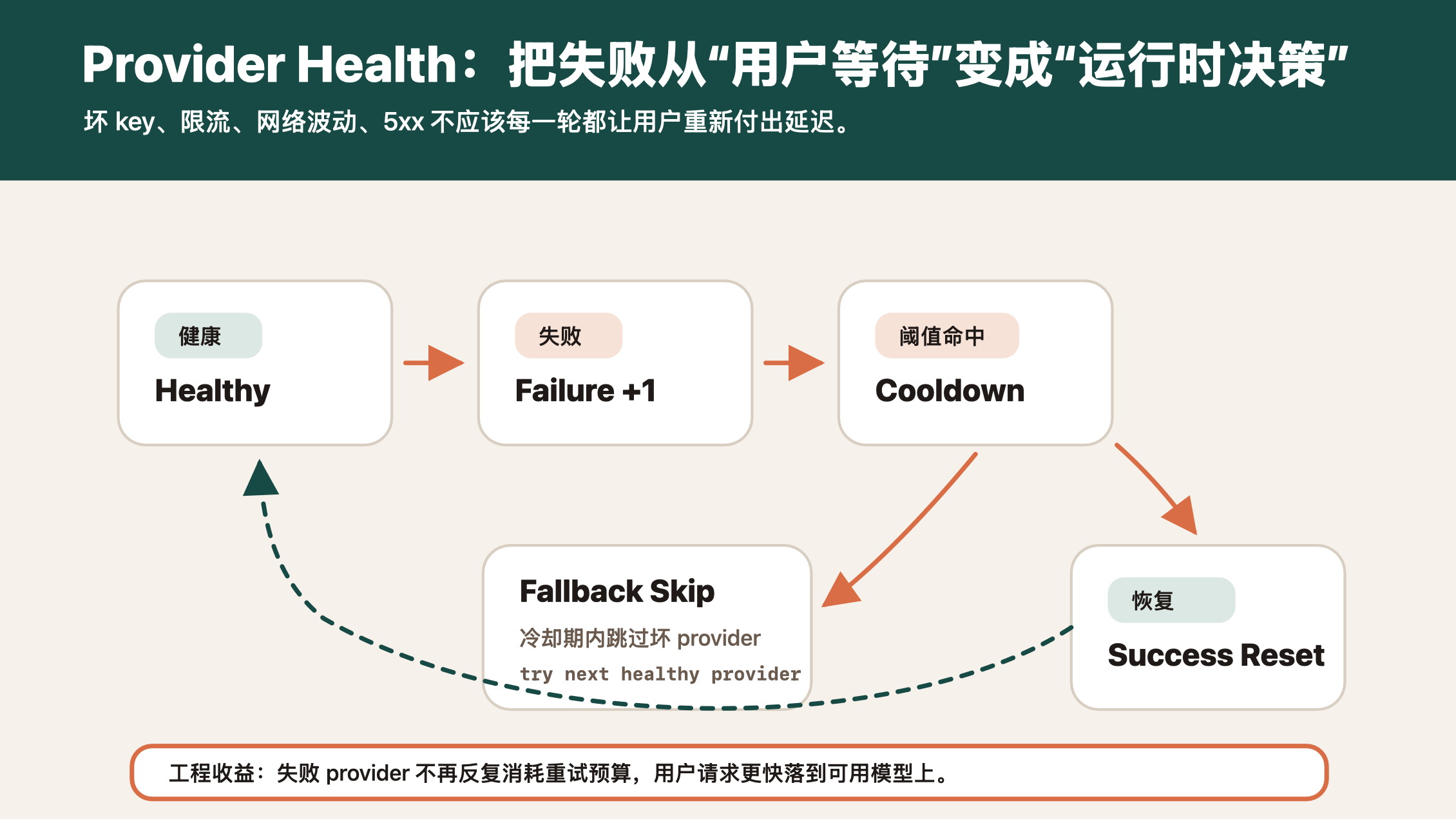
这个逻辑听起来不复杂,但它解决的是 Agent Runtime 的真实问题:不要把系统故障变成每个用户请求的固定税。
5. Goal Budget:长任务必须能停下来
Agent 最容易失控的地方不是回答问题,而是长任务。
比如用户说:
帮我把项目部署到线上,修复所有构建问题,补文档,最后告诉我结果。
这个任务不是一轮能结束的。Agent 可能要查配置、改文件、跑测试、处理错误、再查日志、再修复。此时如果没有预算,系统就只能靠“希望它别跑太久”。
MateClaw 的 Goal 系统里有两个关键预算:
turnBudget:最多允许多少轮;llmCallBudget:最多允许多少次 LLM 调用。
当满足下面条件时,目标会进入 exhausted 状态:
turnsUsed >= turnBudget
或
agentLlmCallsUsed + evalLlmCallsUsed >= llmCallBudget
这个设计很适合企业长任务:Agent 可以自动推进,但不能无限推进;可以自我评估,但评估本身也算预算;预算耗尽后,需要人决定加预算、恢复目标,还是放弃目标。
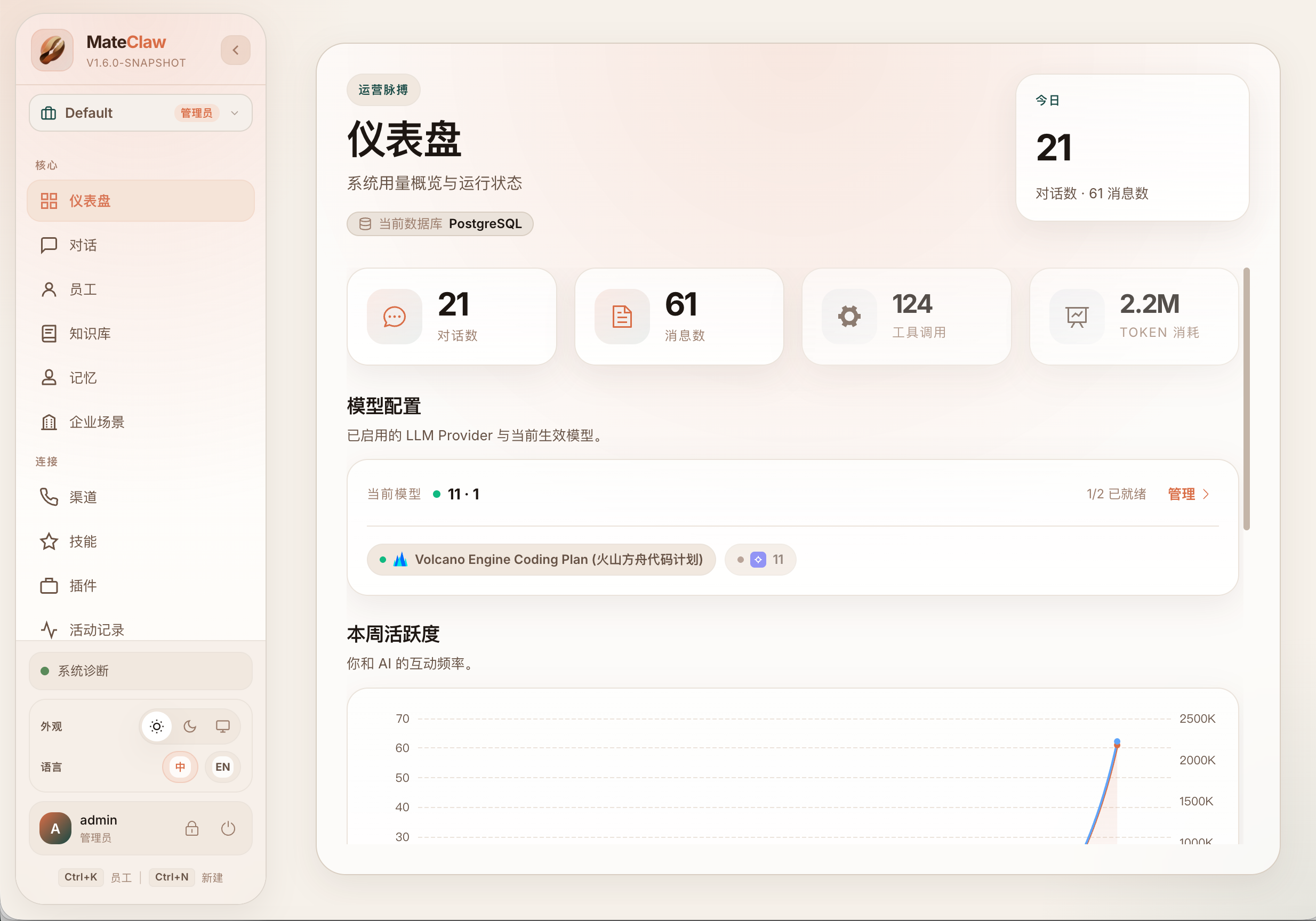
6. Usage Final:没有归因,就没有 FinOps
成本治理不能只靠“感觉省钱”。
MateClaw 的聊天结构化流里有一个 _usage_final 事件,用来在流结束时返回 token 用量统计。服务端同步路径也会收集这个事件,把 prompt tokens、completion tokens、runtime model name、runtime provider id 一起拿到。
这件事的意义是:一次 Agent 运行结束后,不只是知道“回答了什么”,还知道“是谁回答的、花了多少 token”。
有了这层数据,后面才能继续做:
- 按 workspace 统计用量;
- 按员工统计用量;
- 按 provider 统计成本;
- 发现某些工具链特别耗 token;
- 找出 fallback 后实际使用的模型;
- 对高成本任务单独做审计或审批。
如果一个 Agent 平台没有用量归因,它就很难走向生产环境。因为财务、运维、研发负责人最后都会问同一个问题:这套系统到底怎么花钱?
7. Prompt Cache:省钱不只靠换便宜模型
另一个成本治理点是缓存。
Agent 的 system prompt、角色设定、工具定义、长上下文片段,往往在多轮任务里反复出现。如果每次都完整重新计费,长任务成本会非常高。
MateClaw 在 Anthropic 兼容端点上已经接入 prompt cache 的配置能力。源码里的 AnthropicCacheOptionsFactory 会把 MateClaw 的缓存配置翻译成 Spring AI 的 AnthropicCacheOptions,并支持:
- system-only 缓存;
- system + tools + conversation history 缓存;
- 5 分钟或 1 小时 TTL;
- 根据最小 prompt 长度决定是否启用缓存。
这类缓存对企业 Agent 很实用。因为企业 Agent 的提示词通常比个人聊天更重:角色、权限、工具目录、知识库说明、审批策略、工作区信息都会注入上下文。能缓存这些稳定部分,就能减少重复消耗。
8. 这不是“少用 AI”,而是让 AI 进入工程管理
我认为 Agent FinOps 的核心不是抠 token,而是把 AI 调用纳入工程管理。
过去我们管理数据库连接池、HTTP 超时、任务队列、熔断降级、缓存命中率。现在 Agent Runtime 也需要类似能力:
- 模型池:谁可用;
- 模型路由:谁适合;
- 健康追踪:谁暂时别用;
- 预算控制:最多跑多久;
- 用量事件:到底花了多少;
- prompt cache:哪些上下文不用重复付费;
- 审批审计:高风险工具调用不能只靠模型自觉。
MateClaw 的价值不在于“又接了一个模型”,而在于它把这些能力放进 Java 企业栈里,用 Spring Boot、Spring AI Alibaba、MyBatis Plus、Flyway、Actuator 等更熟悉的工程方式组织起来。
这对企业团队很现实:真正落地 Agent,不只是 demo 能跑,而是能在已有系统里部署、配置、审计、升级、治理。
9. 一个可落地的企业 Agent 成本治理方案
如果要把这个思路落到企业内部,我会建议这样设计:
-
任务分级
把任务分成低成本、默认、高价值三类。摘要、分类、格式化不要默认上最贵模型;长代码任务、架构判断、关键审批才上强模型。
-
员工分配模型偏好
不同数字员工配置不同 provider preference。客服员工可以偏快模型,研发员工可以偏强推理模型,知识库维护员工可以偏 embedding 和长上下文模型。
-
Goal 必须带预算
所有长任务都要求设置
turnBudget和llmCallBudget。允许 Agent 自动推进,但不能无限推进。 -
启用健康追踪和 fallback
provider 失败后进入 cooldown,避免每轮重复撞坏服务。fallback 也要记录实际运行模型,不能只看默认配置。
-
保留 usage 事件
每次运行结束都保存 token、provider、model、workspace、agent、conversation 等字段,为后续报表和审计做准备。
-
把缓存当成默认能力
对长 prompt、工具定义、知识库说明、角色设定启用 prompt cache。不要等成本失控后再补。
10. 总结
强模型会继续变强,也会继续变贵。Agent 的价值不在于每一步都使用最强模型,而在于能把强模型放到真正需要它的位置。
企业需要的是一种新的运行时能力:既能让 Agent 规划和执行,又能控制预算、追踪用量、处理故障、缓存上下文、审计行为。
从这个角度看,MateClaw 更像一个 Java 企业栈里的 Agent Runtime。它把模型路由、provider failover、Goal budget、prompt cache、usage final、工具治理和多入口整合在一起,为企业自部署 Agent 提供了一个更接近生产环境的底座。
摘要
企业 AI 正从“尽量多用最强模型”进入成本治理阶段。本文结合近期 token 成本、coding agent 监控和企业限额趋势,分析 Agent 为什么比 Chatbot 更烧钱,并从 MateClaw 的模型池、failover、health tracker、Goal budget、usage 统计和 prompt cache 看 Agent FinOps 的工程实现思路。
关键词
Agent FinOps、AI Agent 成本治理、Token 成本、模型路由、MateClaw、Provider Health、Failover、Cooldown、Goal Budget、Prompt Cache、AI Agent Observability、企业 AI 治理
项目地址
- MateClaw GitHub:https://github.com/matevip/mateclaw
- MateClaw 文档:https://claw.mate.vip/docs
- MateClaw 在线演示:https://claw-demo.mate.vip
参考资料
- Dynatrace AI coding agent monitoring:https://www.dynatrace.com/news/blog/dynatrace-expands-ai-coding-agent-monitoring/
- Microsoft Build 2026 安全与代码 Agent 治理:https://www.microsoft.com/en-us/security/blog/2026/06/02/microsoft-build-2026-securing-code-agents-and-models-across-the-development-lifecycle/
- MateClaw 模型文档:https://claw.mate.vip/docs/zh/models
- MateClaw Goal 文档:https://claw.mate.vip/docs/zh/goals



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










