




 超级会员免费看
超级会员免费看
 MINILLM是一种新的知识蒸馏方法,用于从大型语言模型(LLM)中提取知识,以训练更小的模型。它通过反向Kullback-Leibler散度(KLD)来优化,避免学生模型高估教师分布的低概率区域。MINILLM通过策略梯度优化、教师混合采样和长度归一化来提高训练效果,适用于不同大小的模型。实验表明,MINILLM在指令跟随任务中优于标准KD方法,具有更低的曝光偏差、更好的校准和长文本生成性能。
MINILLM是一种新的知识蒸馏方法,用于从大型语言模型(LLM)中提取知识,以训练更小的模型。它通过反向Kullback-Leibler散度(KLD)来优化,避免学生模型高估教师分布的低概率区域。MINILLM通过策略梯度优化、教师混合采样和长度归一化来提高训练效果,适用于不同大小的模型。实验表明,MINILLM在指令跟随任务中优于标准KD方法,具有更低的曝光偏差、更好的校准和长文本生成性能。
这是大模型系列模型的文章,针对《Knowledge Distillation of Large Language Models》的翻译。
大模型的知识蒸馏
摘要
知识蒸馏(KD)是一种很有前途的技术,可以减少大型语言模型(LLM)的高计算需求。然而,以前的KD方法主要应用于白盒分类模型或训练小模型来模仿像ChatGPT这样的黑盒模型API。如何有效地从白盒生成LLM中提取知识仍有待探索,随着LLM的蓬勃发展,这一点变得越来越重要。在这项工作中,我们提出了MINILLM,它从生成的较大语言模型中提取较小的语言模型。我们首先将标准KD方法中的前向Kullback-Leibler散度(KLD)目标替换为更适合生成语言模型上的KD的反向KLD,以防止学生模型高估教师分布的低概率区域。然后,我们推导出一种有效的优化方法来学习这个目标。在指令跟随设置中的大量实验表明,MINILLM模型生成更精确的响应,具有更高的整体质量、更低的曝光偏差、更好的校准和更高的长文本生成性能。我们的方法也适用于具有120M到13B参数的不同模型族。我们将在https://aka.ms/MiniLLM发布我们的代码和模型检查点。
1 引言
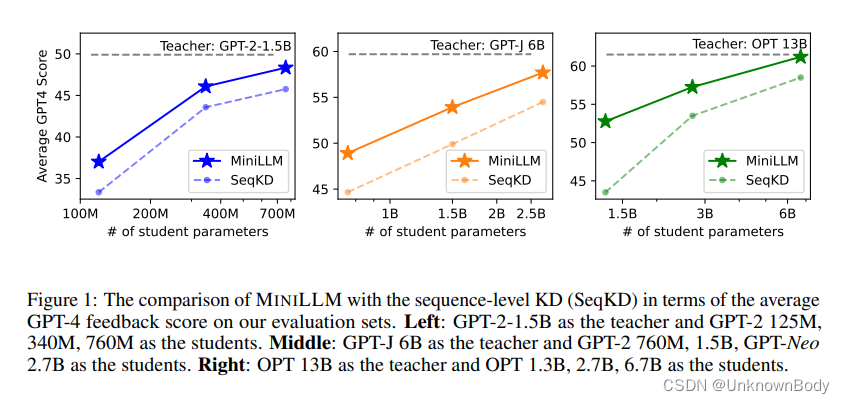
随着大型语言模型(LLM; H Z D + HZD^+

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












