





 超级会员免费看
超级会员免费看


文章核心内容与创新点总结
一、主要内容
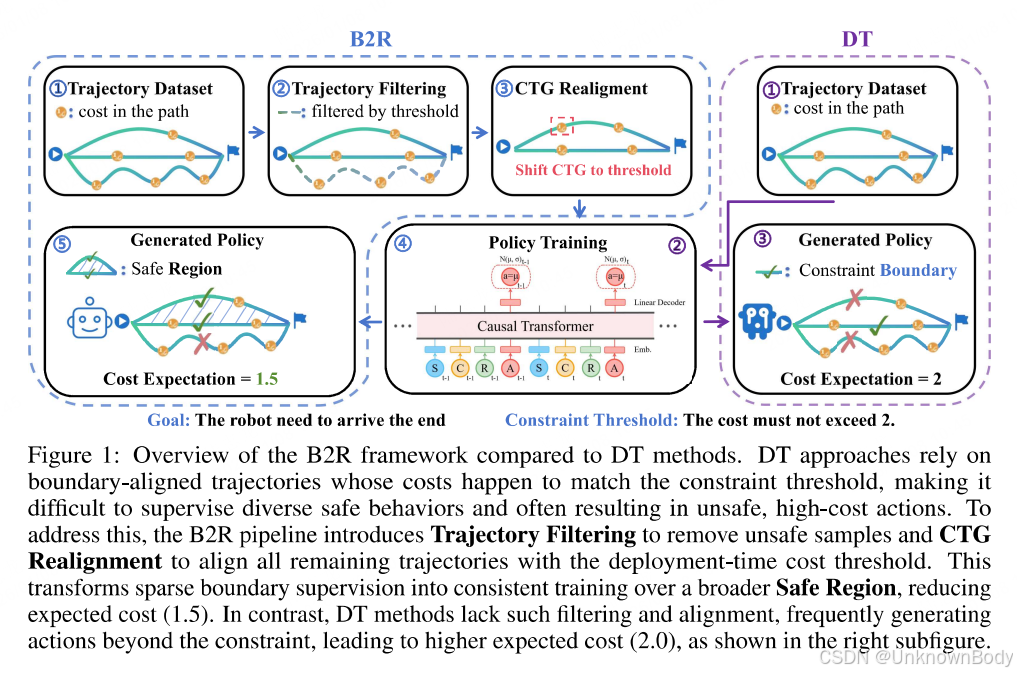
本文聚焦离线安全强化学习(Offline Safe RL) 问题,目标是从静态数据集学习满足预定义安全约束的策略,适用于自动驾驶、机器人等安全敏感场景。现有基于序列模型的方法(如决策Transformer)将“未来回报(RTG)”和“未来成本(CTG)”视为对称输入token,忽略了二者本质差异:RTG是灵活的性能目标,CTG是刚性的安全边界,这种对称处理导致策略在分布外成本轨迹下难以可靠满足安全约束。
为此,本文提出Boundary-to-Region(B2R)框架,通过三大核心组件解决该问题:
- 轨迹过滤(Trajectory Filtering):移除数据集中不满足安全阈值的轨迹,构建纯安全数据集;
- CTG重对齐(CTG Realignment):将所有安全轨迹的CTG统一校准到部署时的安全预算阈值,将稀疏的边界监督转化为密集的区域监督;
- 旋转位置编码(RoPE):增强对时间动态的建模,支持安全区域内的充分探索。
在38个安全关键任务(DSRL基准)的实验中,B2R在35个任务中满足安全约束,同时实现优于基线方法的回报性能,验证了其在平衡

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 1968
1968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












