





 超级会员免费看
超级会员免费看

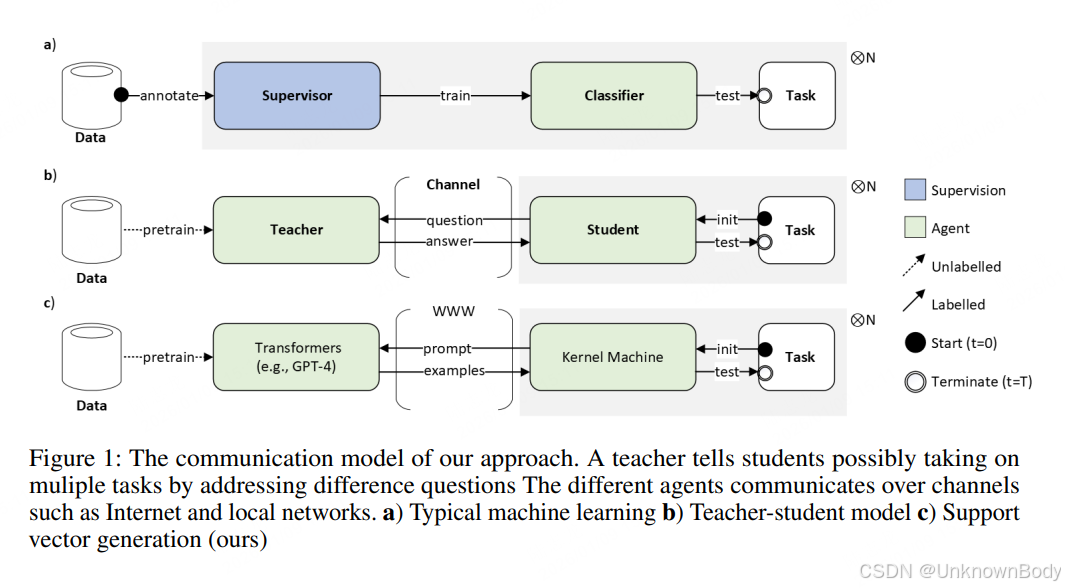
文章核心总结与翻译
一、主要内容
本文提出了一种名为支持向量生成(SVG) 的核方法框架,旨在将冻结的预训练语言模型(PLMs)转化为可解释、无需训练的分类器,适用于零样本和少样本学习场景。其核心逻辑是通过在语言模型诱导的再生核希尔伯特空间(RKHS)中,结合Metropolis-Hastings采样与支持向量机(SVM)优化,生成最多32个自然语言句子作为显式支持向量,分类决策基于这些支持向量的加权组合,同时提供可解释的决策依据。
文章通过理论分析证明,SVG在支持向量范围内最小化经验 hinge 损失,且泛化界与语言模型规模无关。在GLUE基准测试中,仅使用CPU(无GPU加速)的SVG实现,在多个零样本任务上准确率达到或超过基于提示学习的基线模型,训练时间每任务不足3分钟,推理速度具备竞争力,为计算资源受限场景下的高效、可解释NLP系统提供了可行路径。
二、创新点
- 理论创新:形式化定义了PLM诱导的语言核,证明SVG的泛化界由支持向量数量决定(而非模型参数规模),解决了传统PLM决策过程不透明、泛化界依赖模型大小的问题。
- 方法创新:提出两阶段无训练流程——通过Metropolis-Hastings采样生成决策边界附近的候选句子,再通过SVM对

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












