




一、文章摘要
本文中,比较了两种时域结构。首先将最初为语音源分离而开发的卷积tasnet应用于音乐源分离任务。虽然ConvTasnet击败了许多现有的频域方法,但正如人类评估所显示的那样,它存在明显的artifacts。本文提出了一种新的时域模型Demucs,它具有U-Net结构和双向LSTM。
在MusDB数据集上的实验表明,通过适当的数据增强,Demucs击败了所有现有的最先进的架构,包括convt - tasnet,平均为6.3 SDR,(在150首额外的训练歌曲中达到6.8 SDR,甚至超过了bass源的IRM oracle)。使用模型量化的最新发展,Demucs可以压缩到120MB而不会损失任何精度。我们还提供了人类的评估,表明Demucs在音频的自然度方面有很大的优势。然而,它存在一些泄露问题,特别是在人声和其他源之间。
二、本文方法
2.1 Conv-Tasnet方法适配到音源分离任务
原始的conv - tasnet架构[Luo和Mesgarani, 2018]由一个学习的前端组成,该前端在以8 kHz采样的输入单音混合波形和以1 kHz采样的128通道过完整表示之间来回转换,使用卷积作为编码器和转置卷积作为解码器,两者的核大小为16,步幅为8。通过残块堆叠构成的分离网络对高维表示进行屏蔽。
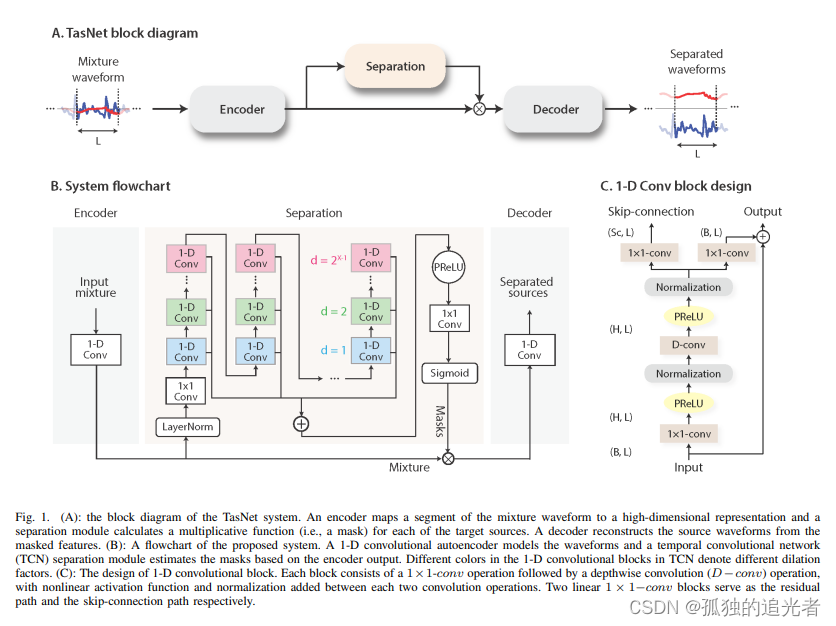
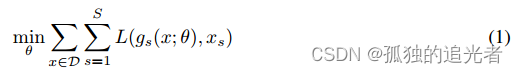
整个的分离思路按照公式(1)进行,一句话概括:最小化各个重建源加和的误差。
其中:g表示训练的模型,x表示各个源,L表示重建误差,S表示各个源的编号(假设1=bass、2=voval等),D表示训练用的数据(dataset)。
2.2 Demucs方法
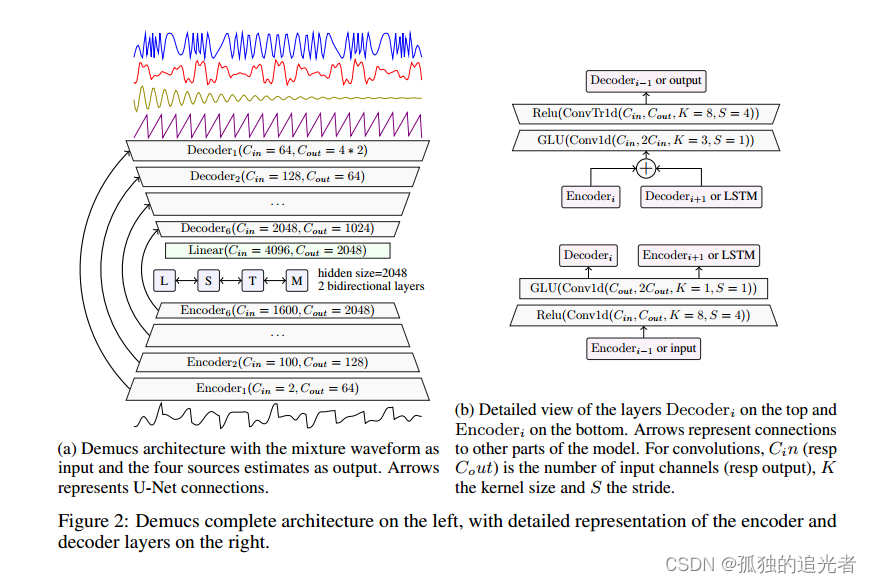
Demucs将立体声混合作为输入,并输出每个源的立体声估计(C = 2)。它是一个编码器/解码器架构,由卷积编码器、双向LSTM和卷积解码器组成,编码器和解码器通过跳跃连接相连。与图像[Karras等人,2018,2017]和声音[dsamfosez等人,2018]生成中的其他工作类似,我们没有使用批处理归一化[Ioffe和Szegedy, 2015],因为我们的早期实验表明它不利于模型性能。
三、实验结果
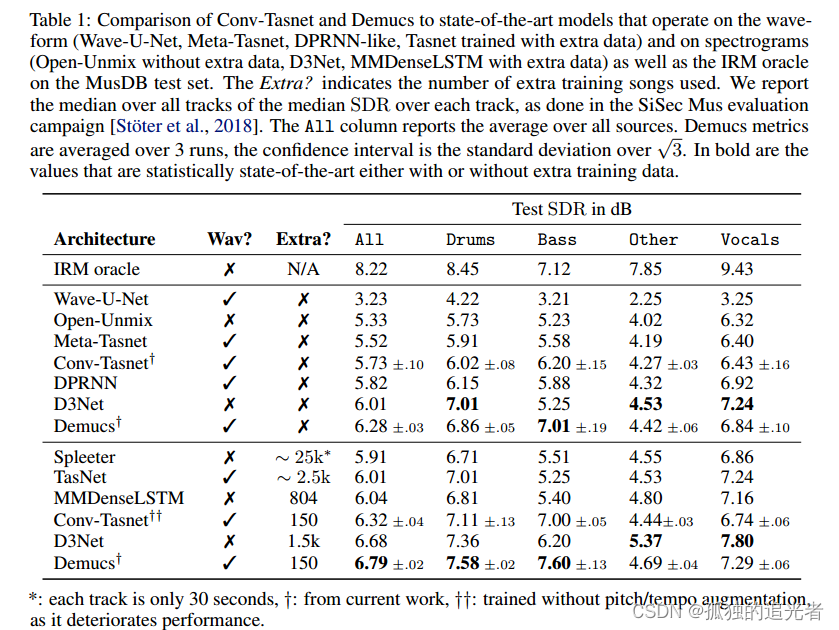
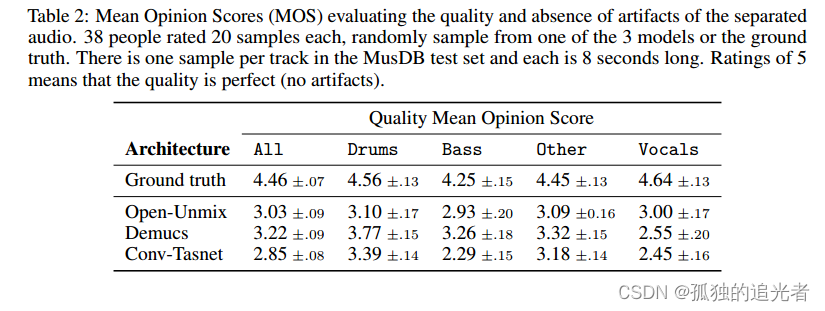
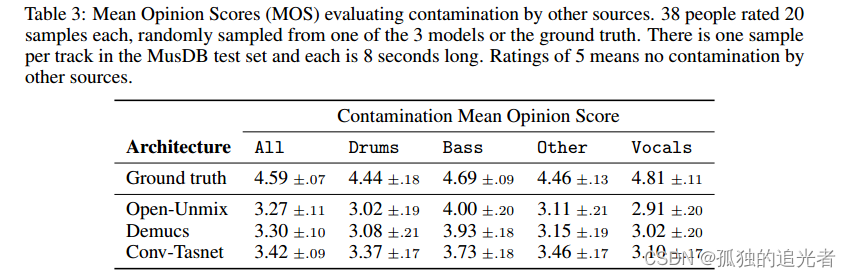
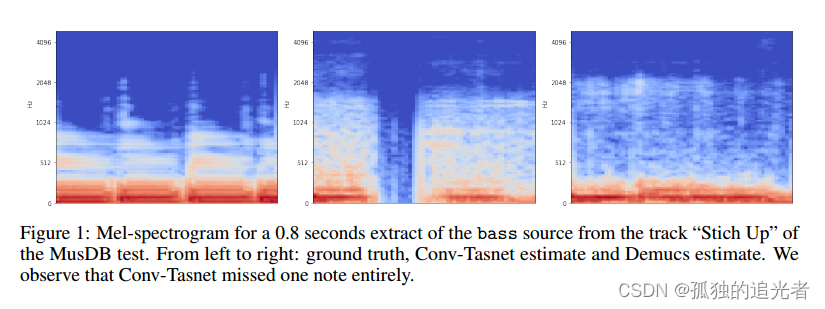
我们注意到通过convt - tasnet分离的音频上有很强的伪像,特别是对于鼓和低音源:1到2 kHz之间的静态噪声,中空乐器攻击或缺失音符,如图1所示。
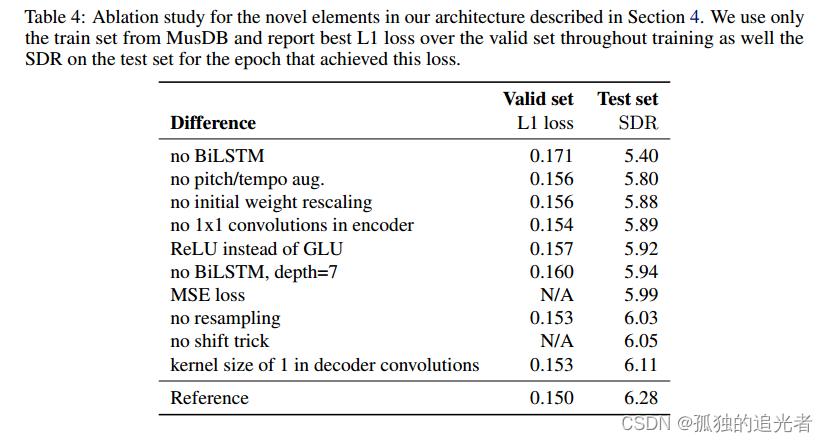
我们在波形域中试验了两种音乐源分离架构:Demucs和convt - tasnet。我们表明,通过适当的数据增强,Demucs在波形或频谱域中超过所有最先进的架构至少0.3 dB的SDR。然而,波形和谱图域模型之间没有明显的赢家,因为前者似乎在低音和鼓源中占主导地位,而后者在人声和其他源上获得最佳表现,这是通过客观指标和人类评估来衡量的。我们推测,谱图域模型在内容主要是谐波和快速变化时具有优势,而对于没有谐波的源(鼓)或具有强烈和强调的攻击机制(低音),波形域将更好地保留音乐源的结构。
在训练和架构方面,我们确认了使用音高/节奏变换增强的重要性(尽管卷积- tasnet架构似乎并没有从中受益),以及使用LSTM进行长距离依赖,以及具有1x1卷积和GLU激活的强大编码和解码层。
当使用额外的数据进行训练时,Demucs首次超过了用于低音源的IRM oracle。另一方面,Demucs仍然遭受比其他架构更大的泄漏,特别是对于人声和其他来源,我们将在未来的工作中尽量减少。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










