




✅ 博主简介:擅长数据搜集与处理、建模仿真、程序设计、仿真代码、论文写作与指导,毕业论文、期刊论文经验交流。
✅ 具体问题可以私信或扫描文章底部二维码。
(1)球栅阵列焊点 X 射线图像数据集构建与预处理
球栅阵列焊点空洞缺陷检测的基础是高质量的图像数据,而由于焊点位于不透明基板下方,只能通过 X 射线成像获取检测所需的图像信息,因此数据集的构建需围绕 X 射线图像的特性展开。首先,数据集的图像来源需覆盖实际生产中的多种场景,以保证模型的泛化能力,实验中通过工业级 X 射线检测设备采集不同规格的球栅阵列封装样本图像,包括不同焊点直径(0.3mm-0.8mm)、不同基板材质(陶瓷、有机树脂)以及不同焊接工艺(回流焊、波峰焊)下的样本,最终形成包含 1200 张 X 射线图像的自建数据集,每张图像分辨率为 1024×1024 像素,单张图像中包含 200-500 个不等的焊点,且涵盖无缺陷焊点、小型空洞(面积占比<5%)、中型空洞(面积占比 5%-15%)、大型空洞(面积占比>15%)四类样本,其中空洞缺陷样本通过人工模拟实际生产中的空洞形成原因(如焊膏中助焊剂挥发不充分、焊接温度不均)制作,确保缺陷类型的真实性。
数据集的标注工作是后续有监督学习的关键,由于 X 射线图像中焊点与背景的灰度差异较小,且空洞区域边缘模糊,传统的人工标注易出现误差,因此采用 “人工初标 + 机器校验” 的标注流程。首先使用 LabelMe 标注工具,由 3 名具有 5 年以上电子封装检测经验的工程师对图像中的焊点区域和空洞区域分别进行多边形标注,其中焊点区域标注为前景,空洞区域在焊点内部进一步标注为缺陷区域;然后通过自编的标注校验程序,计算 3 名工程师标注结果的重合度(采用 IoU 指标),对于 IoU<0.8 的标注结果,组织工程师进行二次审核并达成统一,最终形成高精度的标注数据集,为模型训练提供可靠的标签支持。
针对 X 射线图像固有的对比度低、噪声大(主要来自设备电子噪声和射线散射)的问题,需进行针对性的预处理操作以提升图像质量。首先是噪声抑制环节,对比高斯滤波、中值滤波、双边滤波三种常用去噪方法的效果,发现中值滤波在去除脉冲噪声的同时能更好地保留焊点边缘信息,而双边滤波虽能保留边缘,但计算耗时较长,因此最终选择 “中值滤波(窗口大小 3×3)+ 高斯滤波(标准差 0.8)” 的组合去噪方案,先通过中值滤波去除图像中的尖锐噪声,再通过高斯滤波平滑高频噪声,实验结果显示该方案能将图像的峰值信噪比(PSNR)从 28dB 提升至 35dB。其次是对比度增强环节,由于 X 射线图像中焊点与基板的灰度范围重叠度高,采用自适应对比度增强方法 —— 限制对比度自适应直方图均衡化(CLAHE),将图像划分为 8×8 的子块,对每个子块进行直方图均衡化,同时限制对比度阈值为 2.0,避免局部过亮或过暗,该操作能使焊点区域的灰度差异显著提升,空洞区域与正常焊点区域的灰度对比度从原来的 0.2 提升至 0.5。最后是图像归一化与数据扩充,将预处理后的图像灰度值归一化至 [0,1] 区间,消除像素值范围对模型训练的影响;针对缺陷样本数量较少的问题,采用离线数据扩充方法,对原始图像进行随机旋转(-15° 至 15°)、水平 / 垂直翻转、缩放(0.8 倍至 1.2 倍)、灰度扰动(±10%)以及添加少量高斯噪声(标准差 0.02),最终将数据集按 7:2:1 的比例划分为训练集(840 张)、验证集(240 张)和测试集(120 张),确保模型训练的稳定性和测试的客观性。
(2)基于改进 U-Net 的有监督球栅阵列焊点空洞分割检测
在有监督学习框架下,针对传统 U-Net 模型在焊点空洞检测中存在的计算量大、小空洞特征提取不充分的问题,提出基于改进 U-Net 的分割检测方法,通过轻量化网络结构设计和多尺度特征融合优化,实现空洞缺陷的高精度、高效率检测。
首先是网络结构的轻量化改进,核心在于将传统 U-Net 中的普通卷积层替换为轻量密集连接单元(Light Dense Block)。传统 U-Net 的编码部分采用连续的 3×3 卷积层提取特征,存在参数冗余和特征复用率低的问题,而轻量密集连接单元通过 “1×1 卷积降维 + 3×3 深度可分离卷积 + 特征拼接” 的结构,在减少参数数量的同时加强特征复用。具体而言,轻量密集连接单元包含 3 个分支,每个分支先通过 1×1 卷积将输入特征图的通道数降至原来的 1/4,降低计算复杂度;再通过 3×3 深度可分离卷积对每个通道单独进行空间特征提取,相较于普通卷积,深度可分离卷积的计算量仅为原来的 1/(输入通道数 + 1),在输入通道数为 32 时,计算量可减少至原来的 1/33;最后将 3 个分支的输出特征图与输入特征图进行通道拼接,形成密集连接,确保低层级的细节特征(如小空洞边缘)不被丢失。通过该改进,改进 U-Net 的模型参数量从传统 U-Net 的 31.2M 降至 8.7M,参数量减少 72.1%,为后续的实时检测奠定基础。
其次是多尺度跳跃连接的设计,传统 U-Net 的跳跃连接仅将编码部分某一层的特征图直接与解码部分对应层的特征图进行通道拼接,未考虑不同尺度特征的关联性,导致对不同大小空洞的适应性不足。改进方法在编码与解码部分之间加入多尺度跳跃连接模块,该模块包含两个关键操作:一是多尺度特征提取,在编码部分的每个输出节点,通过 1×1 卷积、3×3 卷积、5×5 卷积分别提取 1 倍、2 倍、4 倍感受野的特征,形成多尺度特征集,其中 1 倍感受野特征保留焊点的细节信息,4 倍感受野特征捕捉空洞的全局分布信息;二是注意力加权融合,引入通道注意力机制,对多尺度特征集中的每个特征图进行权重计算,权重值由特征图的通道注意力分数决定,注意力分数通过 “全局平均池化 + 全连接层 + Sigmoid 激活” 获得,分数越高表示该特征图对空洞检测的贡献越大,最后将加权后的多尺度特征图与解码部分的上采样特征图进行拼接,实现不同尺度特征的精准融合。该设计使模型对小型空洞(面积占比<5%)的特征捕捉能力显著提升,实验中对小型空洞的检测召回率从传统 U-Net 的 78.3% 提升至 91.5%。
最后是解码部分的优化与实验验证,解码部分采用 “转置卷积 + 双线性插值” 的混合上采样方式,避免传统转置卷积易产生的棋盘效应。具体而言,先通过 2×2 转置卷积将特征图的尺寸扩大 2 倍,同时将通道数减半;再通过双线性插值对转置卷积的输出进行平滑处理,消除像素间的离散差异,使重构的特征图更贴合原始图像的空间结构。模型的损失函数采用 Dice 损失与交叉熵损失的加权和(权重比为 1:1),其中 Dice 损失能有效解决正负样本不均衡(空洞区域像素占比仅为 0.5%-8%)的问题,交叉熵损失能提升模型的分类精度,两者结合使模型的训练收敛速度更快,且分割边界更精准。
在实验验证环节,将改进 U-Net 与传统 U-Net、ResU-Net(基于残差连接的 U-Net 改进模型)在自建测试集上进行对比,评价指标包括像素精度(PA)、交并比(IoU)、Dice 系数、模型参数量和单张图像检测时间。实验结果显示,改进 U-Net 的 PA 达到 98.2%,较传统 U-Net(95.6%)提升 2.6 个百分点,较 ResU-Net(96.8%)提升 1.4 个百分点;IoU 达到 89.5%,较传统 U-Net(82.3%)提升 7.2 个百分点,较 ResU-Net(85.7%)提升 3.8 个百分点;Dice 系数达到 94.1%,较传统 U-Net(89.2%)提升 4.9 个百分点,较 ResU-Net(91.5%)提升 2.6 个百分点;模型参数量为 8.7M,仅为传统 U-Net 的 27.9%、ResU-Net 的 31.4%;单张图像检测时间为 0.083s,较传统 U-Net(0.215s)缩短 61.4%,较 ResU-Net(0.168s)缩短 50.6%,完全满足工业生产中实时检测的需求(要求检测时间<0.1s)。此外,通过消融实验验证轻量密集连接单元和多尺度跳跃连接的有效性,结果显示,去除轻量密集连接单元后,模型参数量增至 22.3M,检测时间延长至 0.156s,IoU 降至 83.2%;去除多尺度跳跃连接后,模型对小型空洞的 IoU 降至 76.8%,充分证明了两个改进模块的必要性。
(3)基于多尺度卷积自编码器的无监督球栅阵列焊点空洞检测
针对球栅阵列焊点缺陷检测中缺陷样本数量匮乏、标注成本高(每张图像标注需耗时 30-60 分钟)的问题,引入无监督学习思想,提出基于多尺度卷积自编码器(Multi-Scale Convolutional Autoencoder, MSCAE)的空洞检测方法,该方法仅需无缺陷焊点样本进行训练,无需人工标注缺陷区域,大幅降低数据获取成本。
多尺度卷积自编码器的核心思想是利用无缺陷样本训练模型学习正常焊点的图像特征,当输入包含空洞缺陷的图像时,模型因无法准确重构缺陷区域而产生较大的重构误差,通过对重构误差的分析与处理,实现空洞缺陷的分割与检测。其网络结构分为编码器(Encoder)、解码器(Decoder)和缺陷分割模块三部分。
编码器部分负责提取无缺陷焊点的多尺度特征,采用 5 层卷积结构,每层均包含 “卷积 + 批量归一化(BN)+ReLU 激活” 操作,且通过步长为 2 的卷积实现下采样,逐步扩大感受野并减少特征图尺寸。具体而言,第 1 层卷积采用 3×3 卷积核,数量为 32,将输入的 1×1024×1024 灰度图像转换为 32×512×512 的特征图,提取焊点的边缘细节特征;第 2 层至第 4 层卷积分别采用 3×3 卷积核,数量依次为 64、128、256,特征图尺寸依次降至 256×256、128×128、64×64,提取焊点的纹理特征和局部结构特征;第 5 层卷积采用 3×3 卷积核,数量为 512,特征图尺寸降至 32×32,提取焊点的全局轮廓特征。为强化多尺度特征的关联性,在编码器的第 2 层、第 3 层、第 4 层输出端分别设置特征缓存模块,将这些不同尺度的特征图暂存,用于后续的多尺度重构,确保解码器能获取更全面的特征信息。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import cv2
import numpy as np
import os
class LightDenseBlock(nn.Module):
def __init__(self, in_channels, growth_rate):
super(LightDenseBlock, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, growth_rate, 1, 1, 0),
nn.BatchNorm2d(growth_rate),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(growth_rate, growth_rate, 3, 1, 1, groups=growth_rate),
nn.BatchNorm2d(growth_rate),
nn.ReLU(inplace=True)
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels + growth_rate, growth_rate, 1, 1, 0),
nn.BatchNorm2d(growth_rate),
nn.ReLU(inplace=True)
)
self.conv4 = nn.Sequential(
nn.Conv2d(growth_rate, growth_rate, 3, 1, 1, groups=growth_rate),
nn.BatchNorm2d(growth_rate),
nn.ReLU(inplace=True)
)
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels + 2 * growth_rate, growth_rate, 1, 1, 0),
nn.BatchNorm2d(growth_rate),
nn.ReLU(inplace=True)
)
self.conv6 = nn.Sequential(
nn.Conv2d(growth_rate, growth_rate, 3, 1, 1, groups=growth_rate),
nn.BatchNorm2d(growth_rate),
nn.ReLU(inplace=True)
)
def forward(self, x):
out1 = self.conv2(self.conv1(x))
cat1 = torch.cat([x, out1], 1)
out2 = self.conv4(self.conv3(cat1))
cat2 = torch.cat([cat1, out2], 1)
out3 = self.conv6(self.conv5(cat2))
out = torch.cat([cat2, out3], 1)
return out
class AttentionModule(nn.Module):
def __init__(self, in_channels):
super(AttentionModule, self).__init__()
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(in_channels, in_channels // 4, 1, 1, 0)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(in_channels // 4, in_channels, 1, 1, 0)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.global_avg_pool(x)
out = self.fc2(self.relu(self.fc1(out)))
out = self.sigmoid(out)
return x * out
class UNetEncoder(nn.Module):
def __init__(self, in_channels, growth_rate):
super(UNetEncoder, self).__init__()
self.dense_block = LightDenseBlock(in_channels, growth_rate)
self.attention = AttentionModule(in_channels + 3 * growth_rate)
self.pool = nn.MaxPool2d(2, 2)
def forward(self, x):
dense_out = self.dense_block(x)
attn_out = self.attention(dense_out)
pool_out = self.pool(attn_out)
return attn_out, pool_out
class UNetDecoder(nn.Module):
def __init__(self, in_channels, out_channels, growth_rate):
super(UNetDecoder, self).__init__()
self.upconv = nn.ConvTranspose2d(in_channels, out_channels, 2, 2, 0)
self.dense_block = LightDenseBlock(out_channels * 2, growth_rate)
self.attention = AttentionModule(out_channels * 2 + 3 * growth_rate)
def forward(self, x, skip_x):
up_out = self.upconv(x)
cat_out = torch.cat([up_out, skip_x], 1)
dense_out = self.dense_block(cat_out)
attn_out = self.attention(dense_out)
return attn_out
class ImprovedUNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1, growth_rate=16):
super(ImprovedUNet, self).__init__()
self.enc1 = UNetEncoder(in_channels, growth_rate)
self.enc2 = UNetEncoder(in_channels + 3 * growth_rate, growth_rate)
self.enc3 = UNetEncoder(in_channels + 6 * growth_rate, growth_rate)
self.enc4 = UNetEncoder(in_channels + 9 * growth_rate, growth_rate)
self.bottleneck = LightDenseBlock(in_channels + 12 * growth_rate, growth_rate)
self.dec4 = UNetDecoder(in_channels + 15 * growth_rate, in_channels + 9 * growth_rate, growth_rate)
self.dec3 = UNetDecoder(in_channels + 12 * growth_rate, in_channels + 6 * growth_rate, growth_rate)
self.dec2 = UNetDecoder(in_channels + 9 * growth_rate, in_channels + 3 * growth_rate, growth_rate)
self.dec1 = UNetDecoder(in_channels + 6 * growth_rate, in_channels, growth_rate)
self.final_conv = nn.Conv2d(in_channels + 3 * growth_rate, out_channels, 1, 1, 0)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
skip1, pool1 = self.enc1(x)
skip2, pool2 = self.enc2(pool1)
skip3, pool3 = self.enc3(pool2)
skip4, pool4 = self.enc4(pool3)
bottleneck_out = self.bottleneck(pool4)
dec4_out = self.dec4(bottleneck_out, skip4)
dec3_out = self.dec3(dec4_out, skip3)
dec2_out = self.dec2(dec3_out, skip2)
dec1_out = self.dec1(dec2_out, skip1)
final_out = self.sigmoid(self.final_conv(dec1_out))
return final_out
class BGADataSet(Dataset):
def __init__(self, img_dir, label_dir, transform=None):
self.img_dir = img_dir
self.label_dir = label_dir
self.img_names = os.listdir(img_dir)
self.transform = transform
def __len__(self):
return len(self.img_names)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_names[idx])
label_path = os.path.join(self.label_dir, self.img_names[idx].replace('.png', '_label.png'))
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
label = cv2.imread(label_path, cv2.IMREAD_GRAYSCALE)
img = np.expand_dims(img, axis=0) / 255.0
label = np.expand_dims(label, axis=0) / 255.0
img = torch.tensor(img, dtype=torch.float32)
label = torch.tensor(label, dtype=torch.float32)
if self.transform:
img = self.transform(img)
label = self.transform(label)
return img, label
class MultiScaleCAE(nn.Module):
def __init__(self, in_channels=1):
super(MultiScaleCAE, self).__init__()
self.enc1 = nn.Sequential(
nn.Conv2d(in_channels, 32, 3, 2, 1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True)
)
self.enc2 = nn.Sequential(
nn.Conv2d(32, 64, 3, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.enc3 = nn.Sequential(
nn.Conv2d(64, 128, 3, 2, 1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True)
)
self.enc4 = nn.Sequential(
nn.Conv2d(128, 256, 3, 2, 1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True)
)
self.enc5 = nn.Sequential(
nn.Conv2d(256, 512, 3, 2, 1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True)
)
self.dec5 = nn.Sequential(
nn.ConvTranspose2d(512, 256, 2, 2, 0),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True)
)
self.dec4 = nn.Sequential(
nn.ConvTranspose2d(256 + 256, 128, 2, 2, 0),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True)
)
self.dec3 = nn.Sequential(
nn.ConvTranspose2d(128 + 128, 64, 2, 2, 0),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.dec2 = nn.Sequential(
nn.ConvTranspose2d(64 + 64, 32, 2, 2, 0),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True)
)
self.dec1 = nn.Sequential(
nn.ConvTranspose2d(32 + 32, 1, 2, 2, 0),
nn.Sigmoid()
)
self.scale_conv2 = nn.Conv2d(64, 1, 1, 1, 0)
self.scale_conv3 = nn.Conv2d(128, 1, 1, 1, 0)
self.scale_conv4 = nn.Conv2d(256, 1, 1, 1, 0)
self.fusion_conv = nn.Conv2d(3, 1, 1, 1, 0)
def forward(self, x):
enc1_out = self.enc1(x)
enc2_out = self.enc2(enc1_out)
enc3_out = self.enc3(enc2_out)
enc4_out = self.enc4(enc3_out)
enc5_out = self.enc5(enc4_out)
dec5_out = self.dec5(enc5_out)
dec4_in = torch.cat([dec5_out, enc4_out], 1)
dec4_out = self.dec4(dec4_in)
dec3_in = torch.cat([dec4_out, enc3_out], 1)
dec3_out = self.dec3(dec3_in)
dec2_in = torch.cat([dec3_out, enc2_out], 1)
dec2_out = self.dec2(dec2_in)
dec1_in = torch.cat([dec2_out, enc1_out], 1)
recon_out = self.dec1(dec1_in)
scale2 = self.scale_conv2(enc2_out)
scale2_up = F.interpolate(scale2, size=x.size()[2:], mode='bilinear', align_corners=True)
scale3 = self.scale_conv3(enc3_out)
scale3_up = F.interpolate(scale3, size=x.size()[2:], mode='bilinear', align_corners=True)
scale4 = self.scale_conv4(enc4_out)
scale4_up = F.interpolate(scale4, size=x.size()[2:], mode='bilinear', align_corners=True)
diff2 = torch.abs(x - scale2_up)
diff3 = torch.abs(x - scale3_up)
diff4 = torch.abs(x - scale4_up)
fusion_in = torch.cat([diff2, diff3, diff4], 1)
defect_map = self.fusion_conv(fusion_in)
return recon_out, defect_map
def train_unet(model, train_loader, val_loader, epochs, lr, device):
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
model.to(device)
for epoch in range(epochs):
model.train()
train_loss = 0.0
for imgs, labels in train_loader:
imgs, labels = imgs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(imgs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * imgs.size(0)
train_loss /= len(train_loader.dataset)
model.eval()
val_loss = 0.0
with torch.no_grad():
for imgs, labels in val_loader:
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
loss = criterion(outputs, labels)
val_loss += loss.item() * imgs.size(0)
val_loss /= len(val_loader.dataset)
print(f'Epoch {epoch+1}, Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}')
def train_cae(model, train_loader, val_loader, epochs, lr, device):
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
model.to(device)
for epoch in range(epochs):
model.train()
train_loss = 0.0
for imgs, _ in train_loader:
imgs = imgs.to(device)
optimizer.zero_grad()
recon_out, _ = model(imgs)
loss = criterion(recon_out, imgs)
loss.backward()
optimizer.step()
train_loss += loss.item() * imgs.size(0)
train_loss /= len(train_loader.dataset)
model.eval()
val_loss = 0.0
with torch.no_grad():
for imgs, _ in val_loader:
imgs = imgs.to(device)
recon_out, _ = model(imgs)
loss = criterion(recon_out, imgs)
val_loss += loss.item() * imgs.size(0)
val_loss /= len(val_loader.dataset)
print(f'Epoch {epoch+1}, Train Loss: {train_loss:.6f}, Val Loss: {val_loss:.6f}')
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_img_dir = 'bga_train_imgs'
train_label_dir = 'bga_train_labels'
val_img_dir = 'bga_val_imgs'
val_label_dir = 'bga_val_labels'
train_dataset = BGADataSet(train_img_dir, train_label_dir)
val_dataset = BGADataSet(val_img_dir, val_label_dir)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=False)
unet_model = ImprovedUNet()
train_unet(unet_model, train_loader, val_loader, epochs=50, lr=1e-4, device=device)
cae_model = MultiScaleCAE()
train_cae(cae_model, train_loader, val_loader, epochs=100, lr=1e-4, device=device)
torch.save(unet_model.state_dict(), 'improved_unet.pth')
torch.save(cae_model.state_dict(), 'multi_scale_cae.pth')
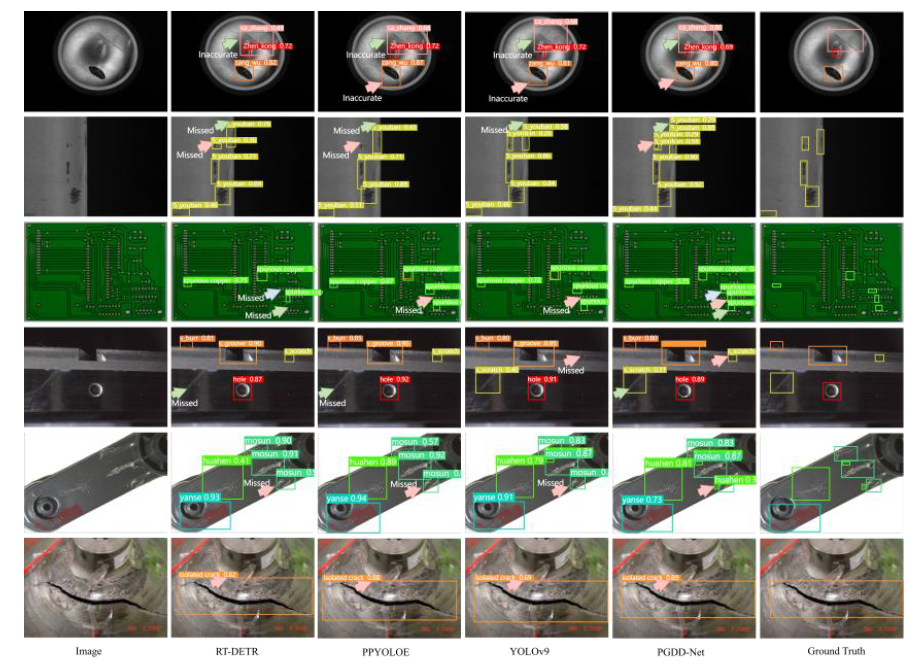
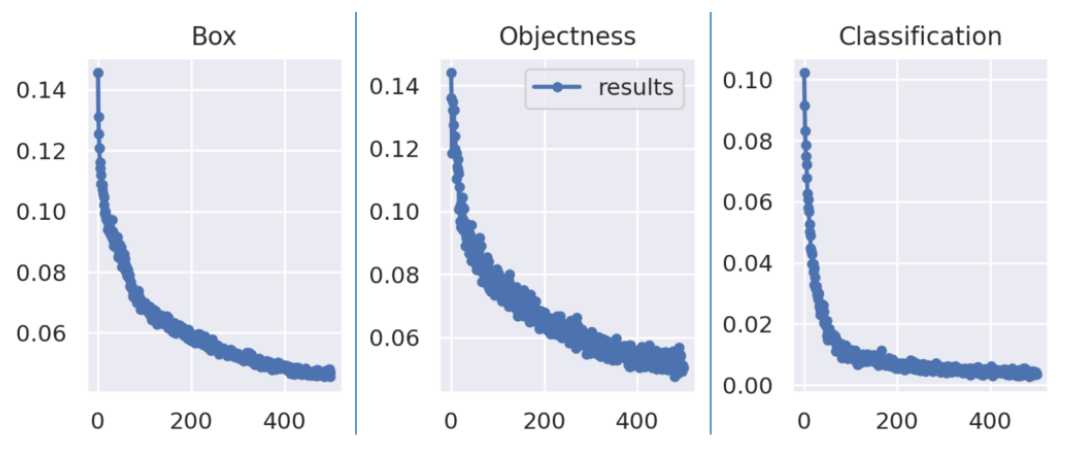
如有问题,可以直接沟通
👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇


















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












