




 本文介绍了一种使用Python脚本来自动清理浏览器中失效书签的方法。通过对收藏夹的HTML文件进行解析,利用正则表达式提取网址,再通过网络请求检查链接是否可用,最后将有效的书签写回新的HTML文件,实现书签的批量更新和清理。
本文介绍了一种使用Python脚本来自动清理浏览器中失效书签的方法。通过对收藏夹的HTML文件进行解析,利用正则表达式提取网址,再通过网络请求检查链接是否可用,最后将有效的书签写回新的HTML文件,实现书签的批量更新和清理。
失效的书签们
我们日常浏览网站的时候,时不时会遇到些新奇的东西( 你懂的.jpg ),于是我们就默默的点了个收藏或者加书签。然而当我们面对成百上千的书签和收藏夹的时候,总会头疼不已……
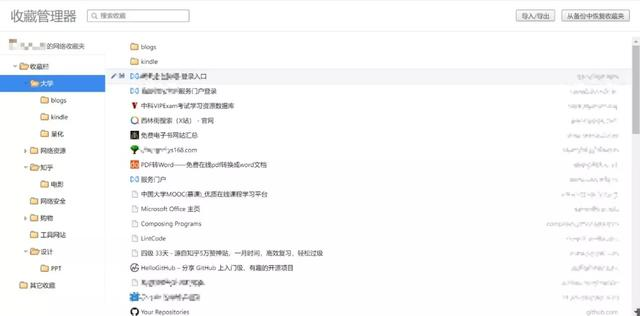
尤其是昨天还在更新的程序设计博客,今天就挂了永不更新。或者是昨天看的起劲的电影网站,今天直接404。失效页面这么多,每次我打开才知道失效了,并且需要手动删除,这能是一个程序员干的事情吗?
可是无论是Google浏览器还是国内浏览器,最多也就提供一个对于收藏夹的备份服务,那只能Python走起了。
Python支持的收藏夹文件格式
对于收藏夹提供的支持很少,主要还是因为收藏夹藏在浏览器里面,我们只能手动导出htm文件进行管理

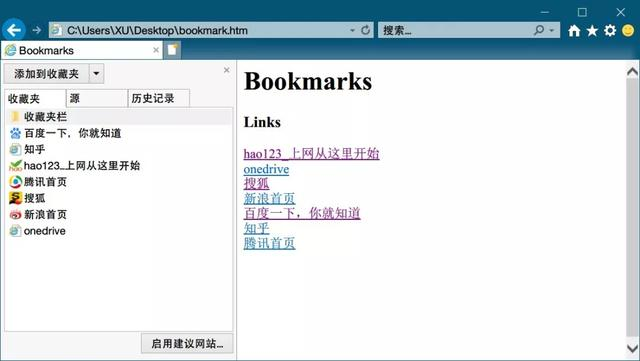
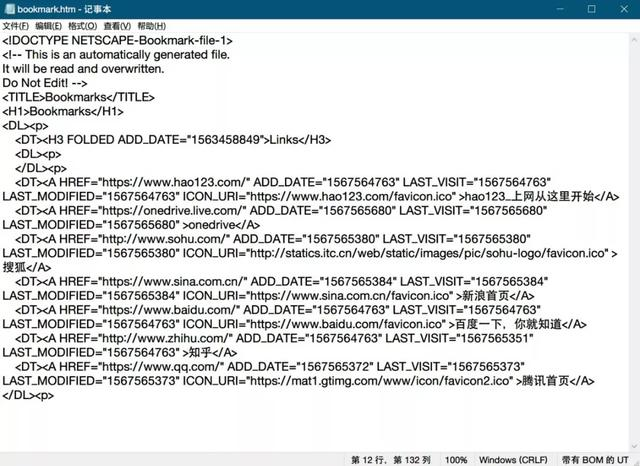
内容比较简单,对前端没什么了解的我,也可以很明显看出其中的树形结构和内在逻辑。
固定格式 网址 固定格式 页面名 固定格式
很简单的想到了正则匹配,其中有两个子串。提取出来再挨个访问,看看哪个失效了,就删除,就能获得清理后的收藏夹了。
读取收藏夹文件
path="C:\\Users\\XU\\Desktop"fname="bookmarks.html"os.chdir(path)bookmarks_f=open(fname,"r+",encoding='UTF-8')booklists=bookmarks_f.readlines()bookmarks_f.close()
因为对于前端的不熟悉,这个导出的收藏夹可以抽象的分成
- 结构代码
- 保存网页书签的关键代码
其中结构代码我们不能动,要原封不动的保留,而保存网页书签的关键代码,我们要提取内容并且进行判断保留和删除。
所以这里采用readlines函数,每行读取,单独判断。
正则匹配
pattern=r'HREF="(.*?)".*?>(.*?)</A>'whilelen(booklists)>0:bookmark=booklists.pop(0)detail=re.search(pattern,bookmark)
如果是关键代码:提取出的子串在 detail.group(1) 和 detail.group(2) 里面
而如果是结构代码:detail == None
访问页面
importrequestsr=requests.get(detail.group(1),timeout=500)
编代码尝试之后发现会有这四种情况
- r.status_code == requests.codes.ok
- r.status_code==404
- r.status_code!=404 && 无法访问 (可能是屏蔽爬虫,建议保留)
- requests.exceptions.ConnectionError
类似知乎、简书基本都反爬了,所以简单的get还不能有效访问,细节不值得大费周章,直接保留就好。而error,直接用try抛出异常就好,不然程序会停止运行。
添加逻辑后:
whilelen(booklists)>0:bookmark=booklists.pop(0)detail=re.search(pattern,bookmark)ifdetail:#print(detail.group(1)+"----"+detail.group(2))try:#访问r=requests.get(detail.group(1),timeout=500)#如果可则添加ifr.status_code==requests.codes.ok:new_lists.append(bookmark)print("ok------保留:"+detail.group(1)+""+detail.group(2))else:if(r.status_code==404):print("不可访问删除:"+detail.group(1)+""+detail.group(2)+'错误码'+str(r.status_code))else:print("其他原因保留:"+detail.group(1)+""+detail.group(2)+'错误码'+str(r.status_code))new_lists.append(bookmark)except:print("不可访问删除:"+detail.group(1)+""+detail.group(2))#new_lists.append(bookmark)else:#没匹配到是结构语句new_lists.append(bookmark)
程序执行情况
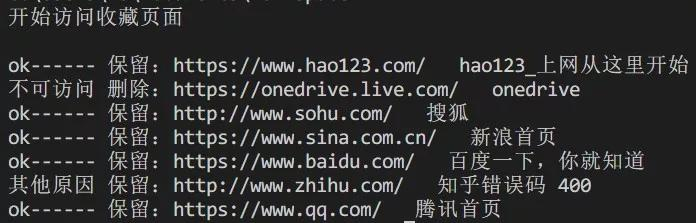
导出htm
bookmarks_f=open('new_'+fname,"w+",encoding='UTF-8')bookmarks_f.writelines(new_lists)bookmarks_f.close()
导入浏览器
实际应用于我的浏览器
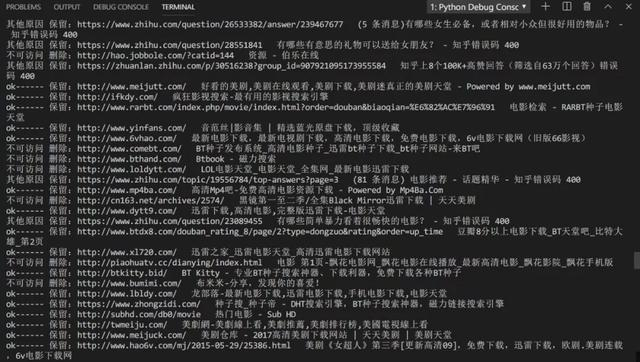
确实有很多电影网都失效了,通过Python能够一键清理其中无法访问的书签。人生苦短,Python 的确可以让生活更高效~


















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










