




第一部分 准备工作
在软件开发过程中,程序员会使用一些调试工具,以便高效地找出软件中存在的错误。在逆向分析领域,分析者也要利用相关工具分析软件行为,验证分析结果。
本书第一部分将介绍几款常用的逆向分析辅助工具和软件。
“工欲善其事,必先利其器。”在软件逆向工程中,一个好的工具能够极大地提高软件逆向分析效率。本章将介绍编译环境的安装以及软件逆向分析中常用工具的使用方式。本书使用的所有编译环境和工具的工作环境都运行于Windows 10系统。
1.1 安装Visual Studio 2019
Visual Studio(简称VS)是微软公司开发的工具包产品,是目前最流行的Windows平台应用程序集成开发环境(IDE),最新版本为Visual Studio 2019,本书所有VS程序都使用Visual Studio 2019编译。
1. 安装
VS的官方下载地址为https://visualstudio.microsoft.com/zh-hans/downloads/,下载页面如图1-1所示。
图1-1 Visual Studio 2019下载页面
下载需要安装的版本,之后运行Visual Studio Installer,选择需要安装的组件,如图1-2所示。
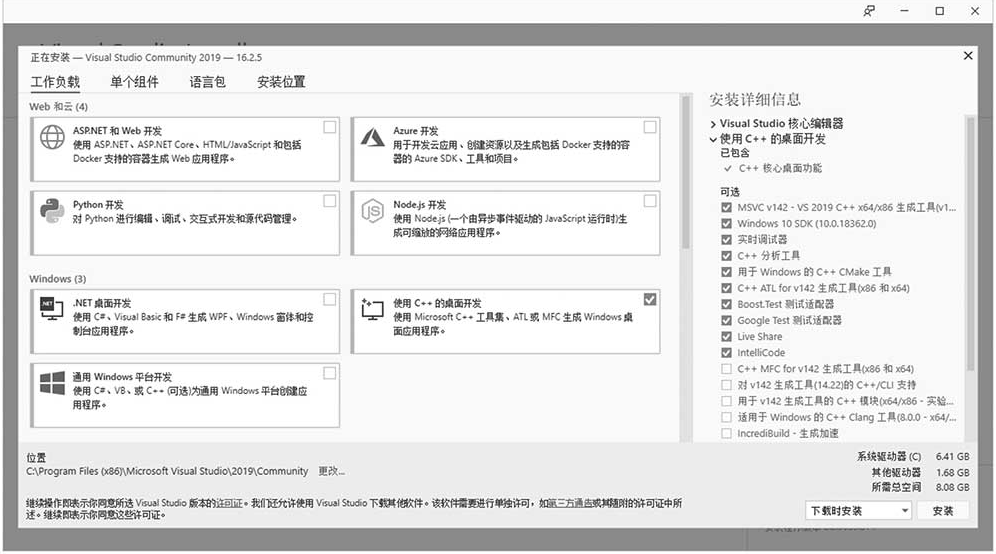
图1-2 Visual Studio 2019安装界面
2. 编译
启动Visual Studio 2019,点击“配置新项目”,选择应用程序类型,输入项目名称、位置,之后单击“创建”,如图1-3所示。
图1-3 Visual Studio 2019创建项目
单击菜单“生成解决方案”(快捷键Ctrl+Shift+B)完成程序的编译,单击“调试”→“开始执行”(快捷键Ctrl+F5)完成程序的运行。生成的可执行文件32位程序在项目根目录的Debug或Release目录下,64位程序在项目根目录的x64/Debug/或x64/Release目录下。也可以打开反汇编窗口点击“调试”→“窗口”→“反汇编”(快捷键Ctrl+Alt+D),跟踪调试源码与反汇编对应情况,VS Debug/Release程序都支持调试与反汇编,如图1-4所示。
笔记-------------------------------start
// F:\learnDisassembly\chapter01\1_1\hello.cpp
#include <stdio.h>
int main()
{
printf("Hello World!\n");
}VS2019 Debug_x86 反汇编:
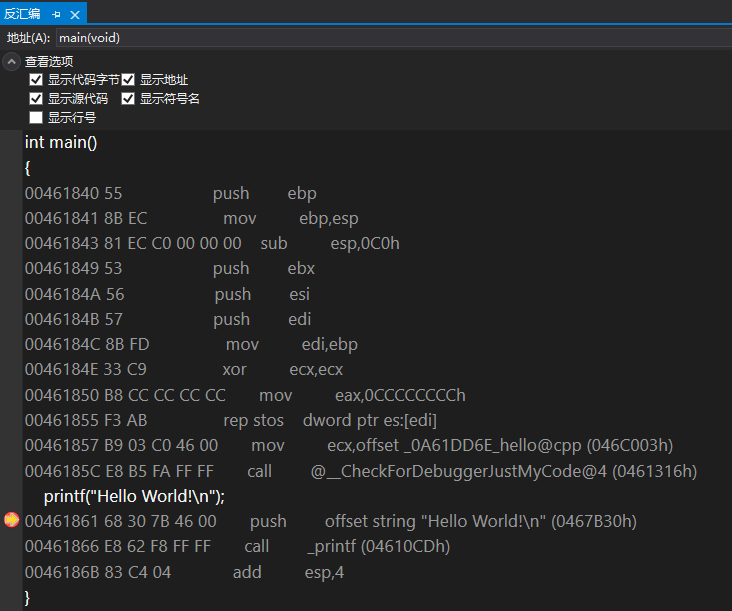
笔记-------------------------------end
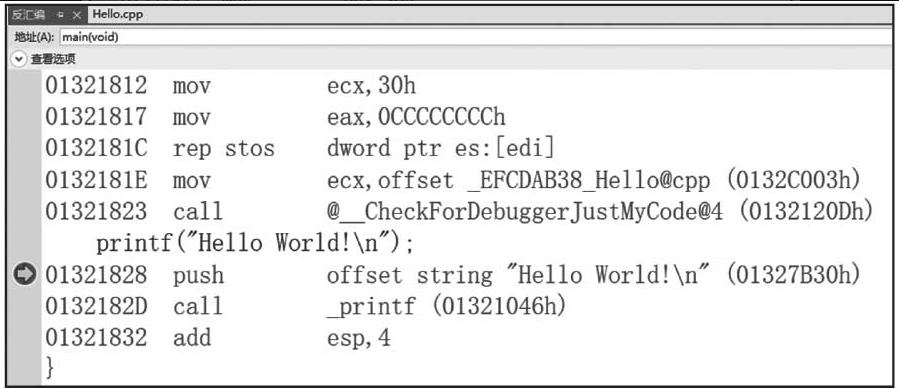
图1-4 Visual Studio 2019反汇编调试
VS编译选项设置如图1-5所示。
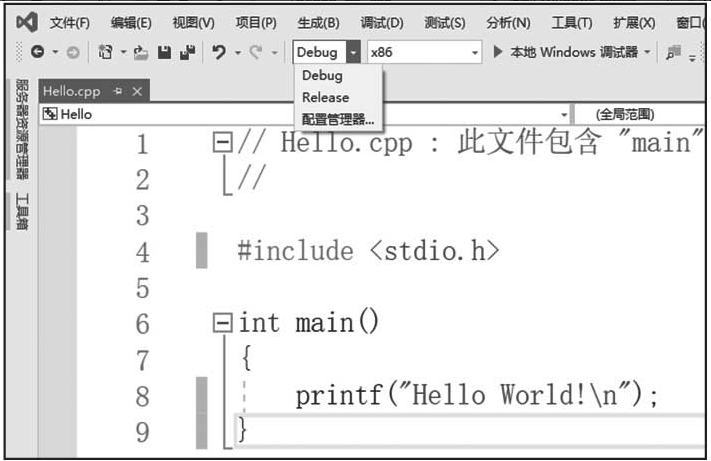
图1-5 Visual Studio 2019编译选项
Debug:调试版,编译器默认不对生成的汇编代码做优化。
Release:发布版,编译器默认对生成的汇编代码做优化,可设置为01优化(最小文件优化)或02优化(最快执行速度优化)。如无设置,Release版默认使用02优化选项。本书如无特别说明,Release版使用02优化。优化设置如图1-6所示。
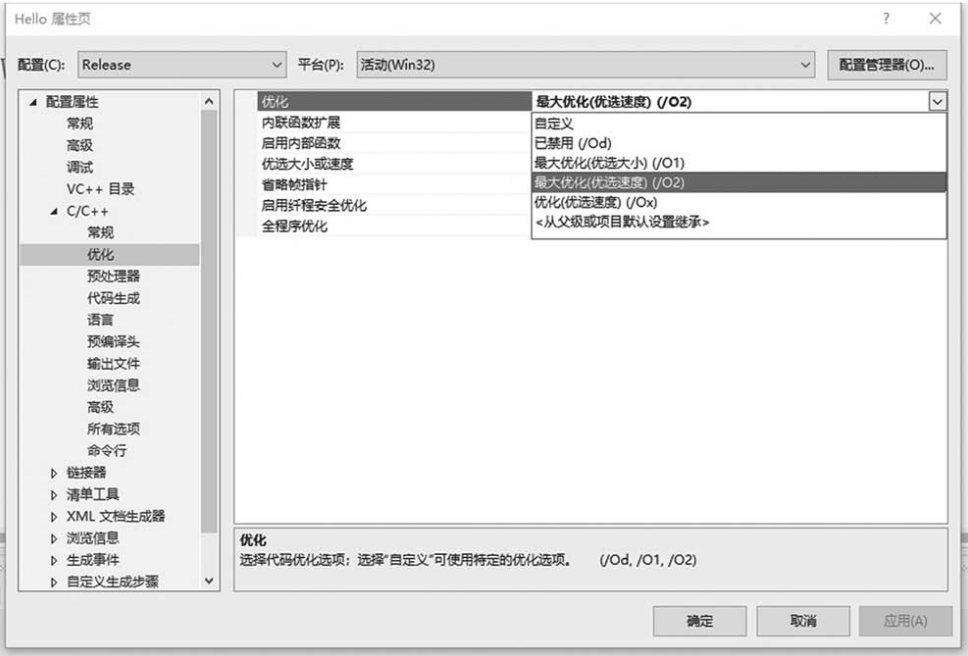
图1-6 Visual Studio 2019优化选项
x86:编译32位应用程序。
x64:编译64位应用程序。
3. 使用命令行编译
VS也提供命令行工具编译程序,使用命令行可以很方便地编译没有VS项目文件(.sln)的程序,例如一些开源源码。VS命令行工具界面如图1-7所示,说明如下。
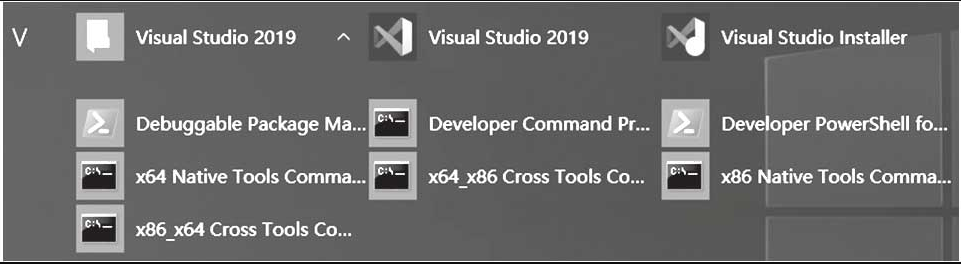
图1-7 Visual Studio 2019命令行工具
x64 Native Tools Command Prompt for VS 2019:编译64位程序命令行。
x64_x86 Cross Tools Command Prompt for VS 2019:编译兼容32位程序命令行。
x86 Native Tools Command Prompt for VS 2019:编译32位程序命令行。
x86_x64 Cross Tools Command Prompt for VS 2019:编译兼容64位程序命令行。使用命令编译32位Debug/Release程序,运行命令行x86 Native Tools Command Prompt for VS 2019,输入以下命令编译程序。
cd <源码目录>
cl /O2 /Fe:Hello.exe Hello.cpp
/02表示编译Release版,如果不写/02则默认为Debug版。/Fe指定生成的可执行文件名称。编译过程如图1-8所示。
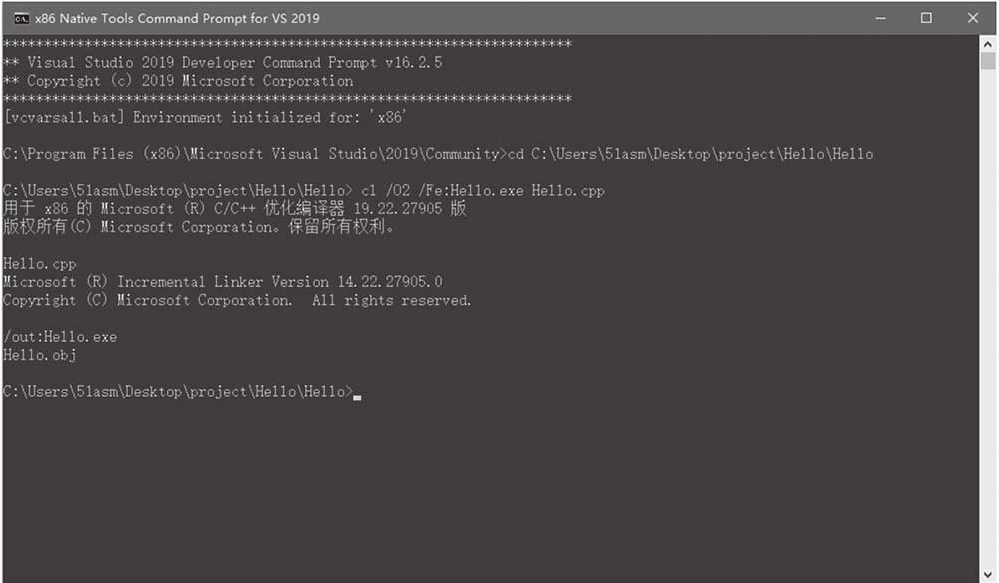
图1-8 Visual Studio 2019命令行编译32位程序
使用命令编译64位Debug/Release程序,运行命令行x64 Native Tools Command Prompt for VS 2019,输入以下命令编译程序。
cd <源码目录>
cl /O2 /Fe:Hello.exe Hello.cpp
编译过程如图1-9所示。
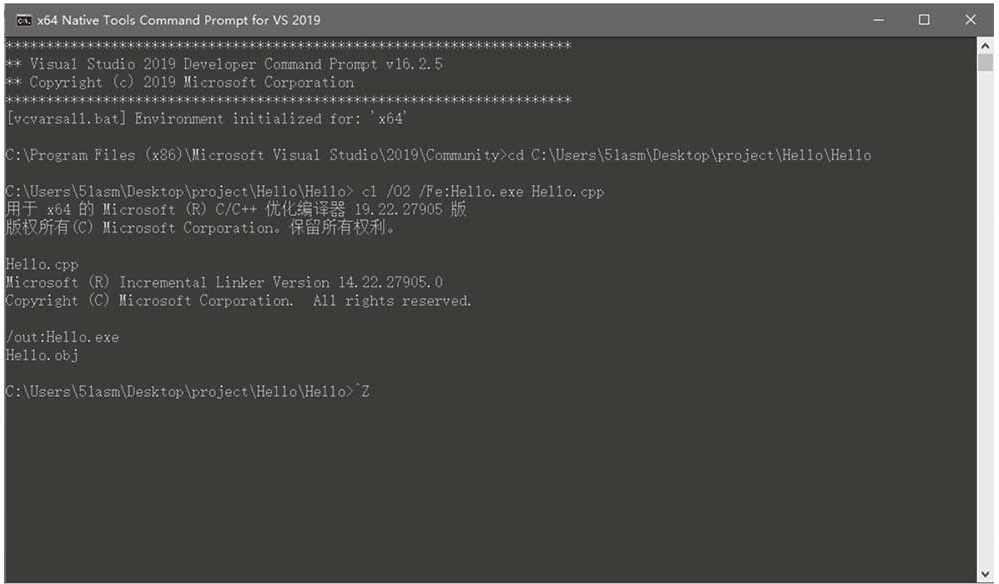
图1-9 Visual Studio 2019命令行编译64位程序
1.2 安装GCC
GCC(GNU Compiler Collection,GNU编译器套件)是由GNU开发的支持C/C++的编译器。它是以GPL许可证发行的自由软件,是一个跨平台的编译器,现已被大部分操作系统(如Windows、Linux、macOS等)采纳为标准编译器。在软件逆向工程中,经常会遇见使用GCC编译的应用程序。在Windows上安装GCC可以选择安装Cygwin或者MinGW-w64,本节将介绍MinGW-w64的安装。
1. 下载安装MinGW-w64
MinGW-w64的官方地址为http://mingw-w64.org,下载地址为https://sourceforge.net/projects/mingw-w64/files/mingw-w64/mingw-w64-release/,下载页面如图1-10所示。
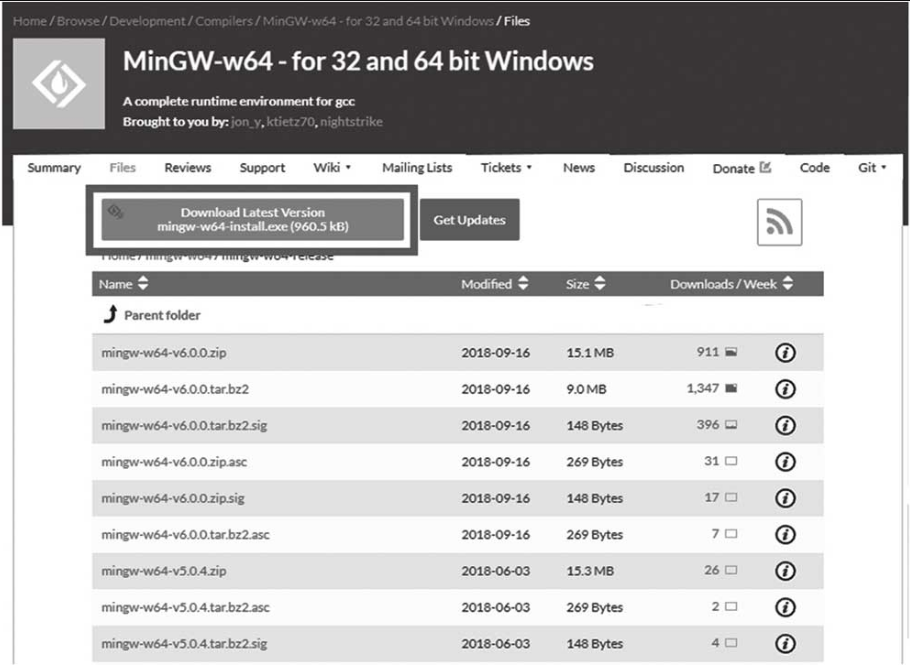
图1-10 MinGW-w64下载
单击Download进行下载,下载完成后运行mingw-w64-install.exe,按照图1-11所示选择安装设置。安装设置说明如下。
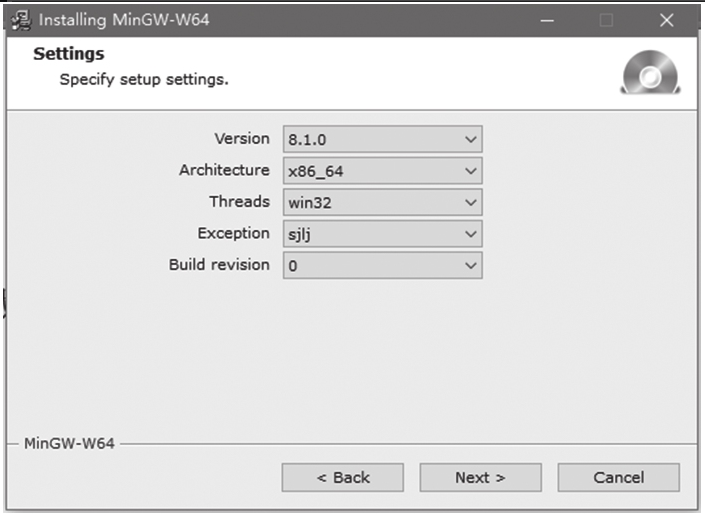
图1-11 MinGW-w64安装选项
Version:编译器版本,选择最新版8.1.0。
Architecture:CPU,选择x86-64。
Threads:线程API,选择win32。
Exception:异常处理库,选择sjlj库,它可以同时支持32位和64位程序的异常处理。
Build revision:默认项。
设置安装路径,单击Next直到安装完成,如图1-12所示。
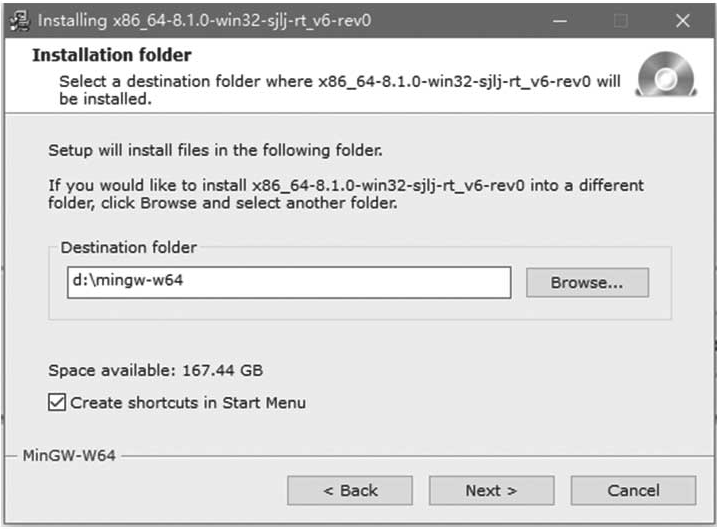
图1-12 MinGW-w64安装
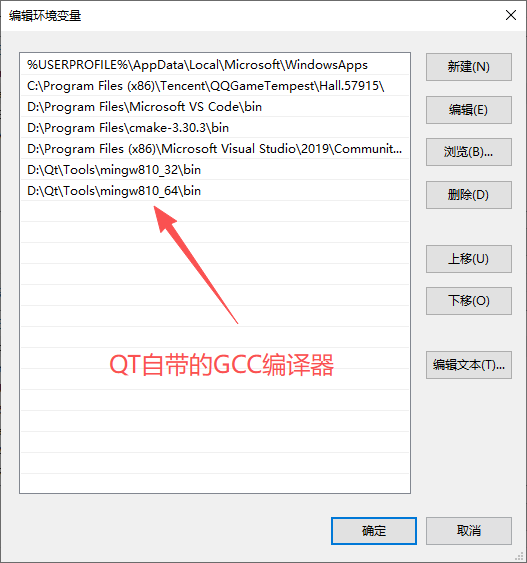
2. 配置环境变量
将MinGW-w64的bin目录设为环境变量,鼠标右键选中桌面“此电脑”→“系统”→“高级系统设置”→“环境变量”,如图1-13所示。
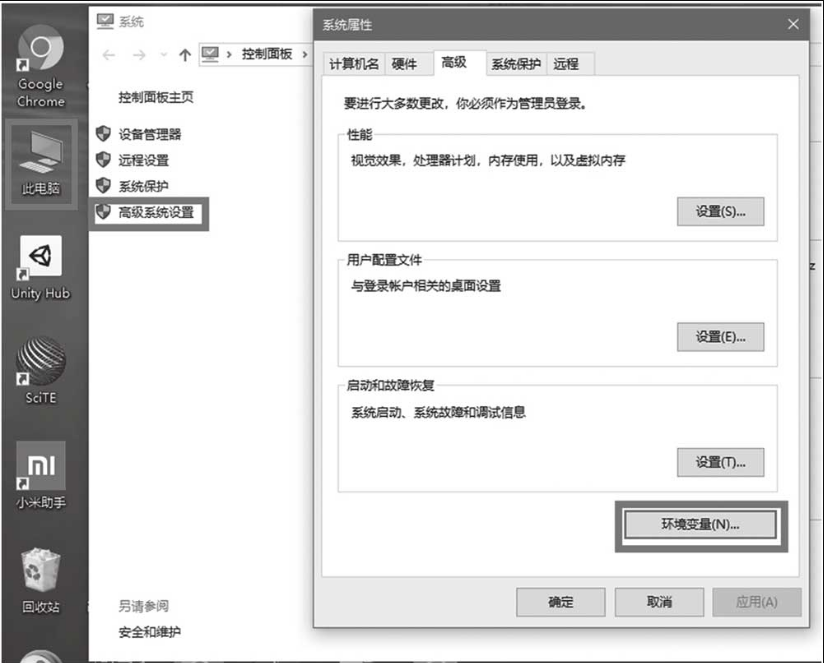
图1-13 环境变量设置入口
双击Path变量,单击“新建”将bin目录设置为环境变量,最后单击“确定”保存设置,如图1-14所示。
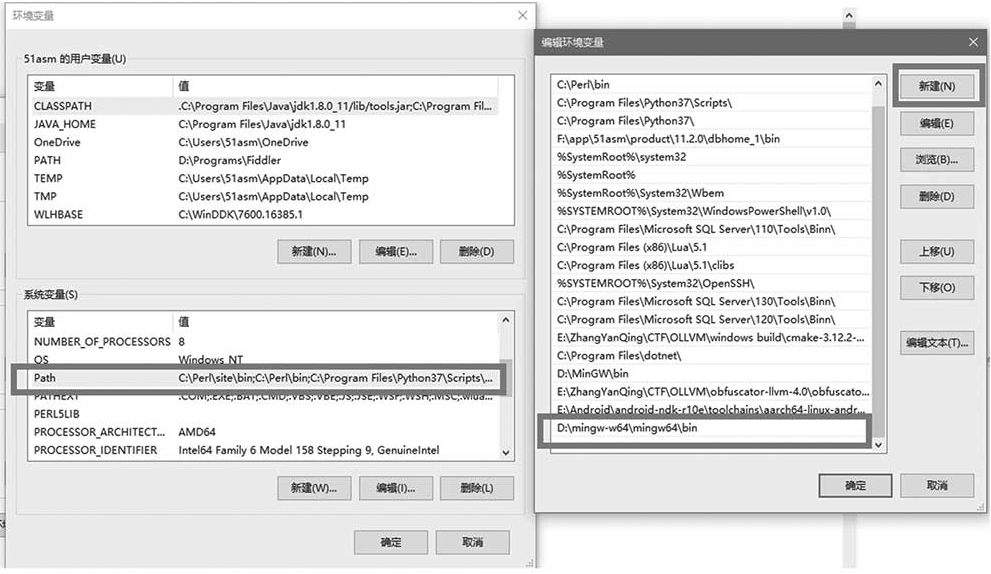
图1-14 环境变量设置
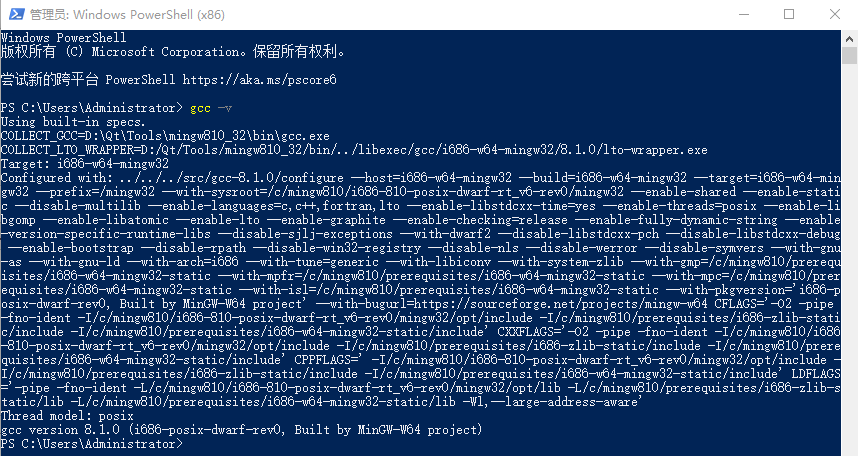
单击开始菜单运行cmd,输入gcc -v查看gcc版本信息是否安装成功,如图1-15所示。
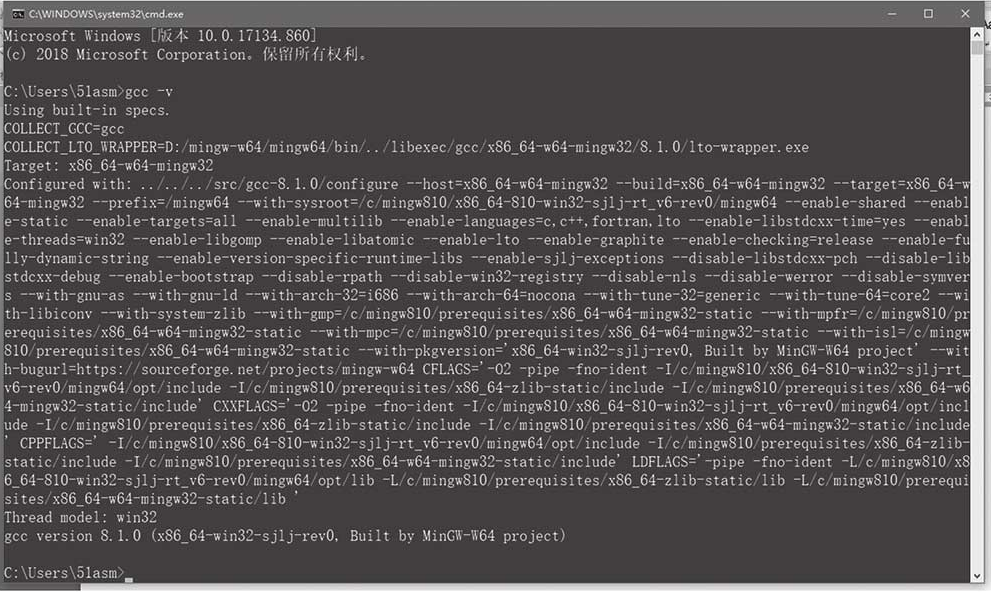
图1-15 查看gcc版本信息
3. 编译
运行cmd,输入以下命令编译程序。
cd <源码目录>
gcc -m32 -O2 -o x86_gcc.exe hello.c
编译选项说明如下。
-m32表示编译32位程序,-m64表示编译64位程序。
-O2表示编译Release版,以最快执行速度优化;默认编译Debug版。
-o指定可执行文件名称,是现在比较流行的一个编译器,越来越多的软件选择使用Clang编译器编译。
笔记------------------------------------------start
编译:

笔记------------------------------------------end
(1)下载并安装Clang
Clang的官方下载地址为http://releases.llvm.org/download.html,选择下载Windows版本,如图1-16所示。
图1-16 安装Clang
运行下载LLVM-8.0.1-win64.exe,选择安装目录,一直单击“下一步”直到安装完成,如图1-17所示。
图1-17 Clang安装
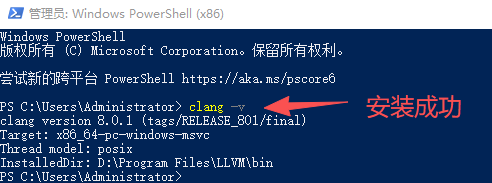
将Clang安装路径的bin目录设置到环境变量,为防止与VS2019的Clang编译器冲突,可调整环境变量顺序。运行cmd并输入命令clang -v,显示版本信息表示安装成功,如图1-18所示。
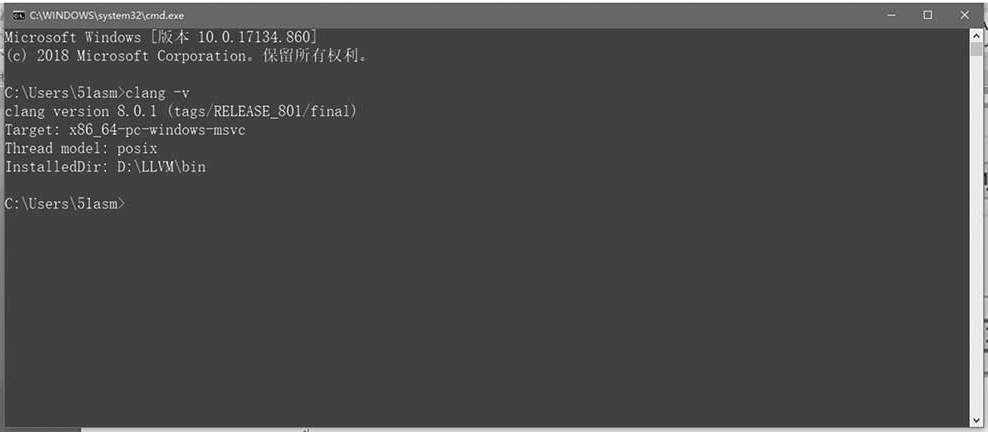
图1-18 Clang安装成功
(2)编译
运行cmd,输入以下命令编译程序,编译选项与GCC一致,其中O0表示Debug版,如图1-19所示。
cd <源码目录>
clang -m32 -O0 -o x86_clang.exe hello.c
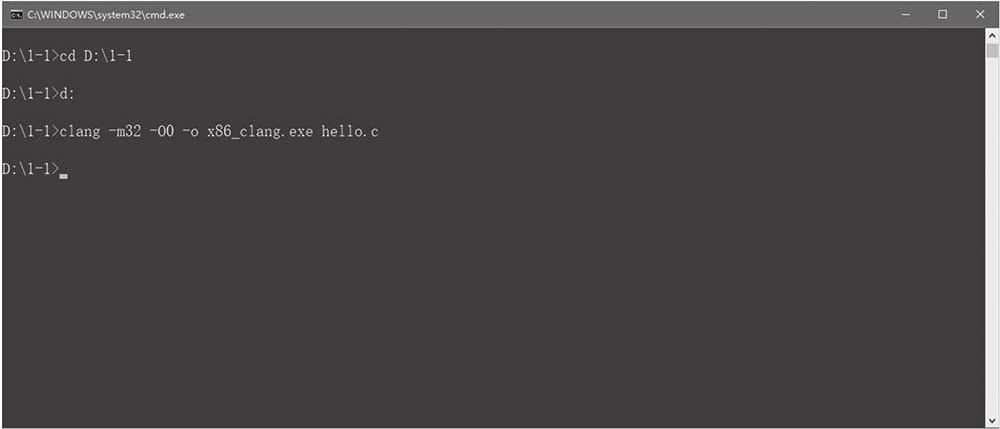
图1-19 使用Clang编译程序
笔记------------------------------------------start
下载地址: https://releases.llvm.org/download.html
安装检查
编译测试:
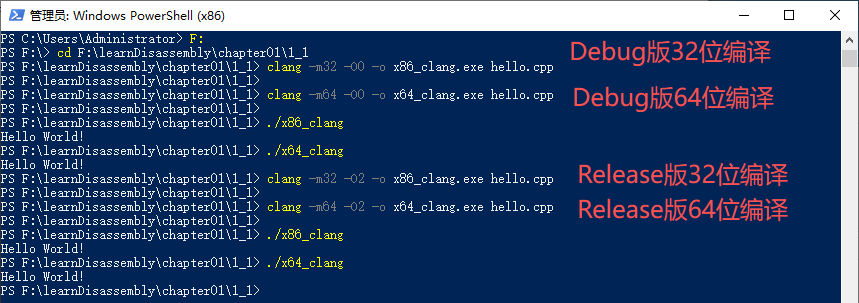
笔记------------------------------------------end
1.3 调试工具OllyDbg
在软件的开发过程中,程序员会使用一些调试工具,以便高效地找出软件中存在的错误。而在逆向分析领域,分析者也会利用调试工具来分析软件的行为并验证分析结果。由于操作系统提供了完善的调试接口,所以通过各类调试工具可以非常方便灵活地观察和控制目标软件。在使用调试工具分析程序的过程中,程序会按调试者的意愿,以指令为单位执行。调试者可以随时中断目标的指令流程,以观察相关计算结果和当前设备状况,也可以随时执行程序的后续指令。像这样使用调试工具加载程序并一边运行一边分析的过程,我们称之为动态分析。
对于有源代码的程序,我们使用Visual Studio 2019进行调试,它可以将C++源码反汇编;对于无源码的程序,我们使用OllyDbg进行调试分析,它的调试功能十分强大。Visual Studio 2019的调试功能相对简单,同时有源码作对照,故不过多讲解。OllyDbg的默认功能界面如图1-20所示。

图1-20 OllyDbg的默认功能界面
图1-20中的标号说明如下。
1:汇编代码对应的地址窗口。
2:汇编代码对应的十六进制机器码窗口。
3:反汇编窗口。
4:反汇编代码对应的注释信息窗口。
5:寄存器信息窗口。
6:当前执行到的反汇编代码的信息窗口。
7:数据窗口,数据所在的内存地址。
8:数据窗口,数据的十六进制编码信息。
9:数据窗口,数据对应的ASCII码信息。
10:栈窗口,栈地址。
11:栈窗口,栈地址中存放的数据。
12:栈窗口,对应的说明信息。
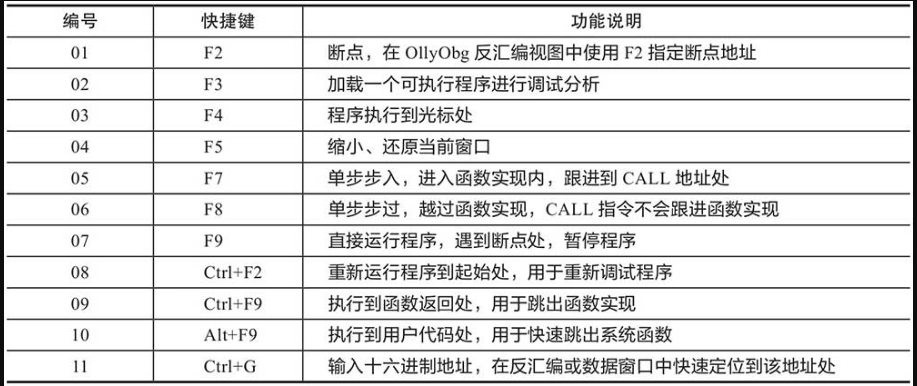
熟悉了各窗口视图的功能之后,我们来进一步了解OllyDbg的操作方法。首先介绍一下OllyDbg的快捷键。掌握各个快捷键,可以提高分析效率。OllyDbg的基本快捷键及其功能如表1-1所示。
表1-1 OllyDbg的基本快捷键及其功能
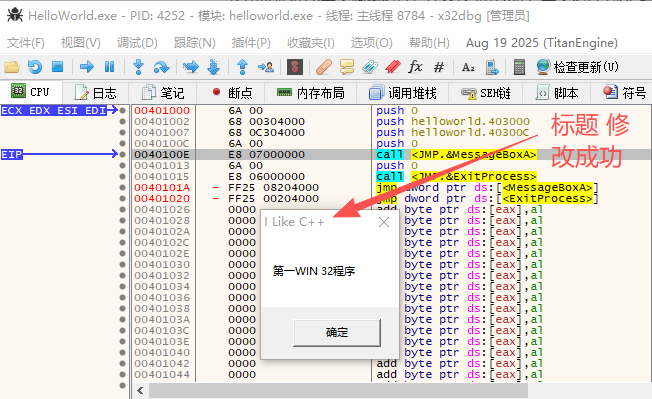
通过实际操作演练,我们可以进一步熟悉OllyDbg。调试一个简单的“Hello world”程序,将对话框标题“Hello world”修改为“I Like C++”,步骤如下。
1. 加载可执行程序
选择调试程序的方式有以下3种。
使用快捷键F3选择要调试程序的路径。在菜单选项中(“文件”→“打开”)选择调试程序路径。将OllyDbg加入系统资源管理菜单中,鼠标右键“打开”。依次选择OllyDbg菜单“选项”→“添加到浏览器”→“添加OllyDbg到系统资源管理菜单”→“完成”,即可将OllyDbg加入系统资源管理菜单中,如图1-21所示。
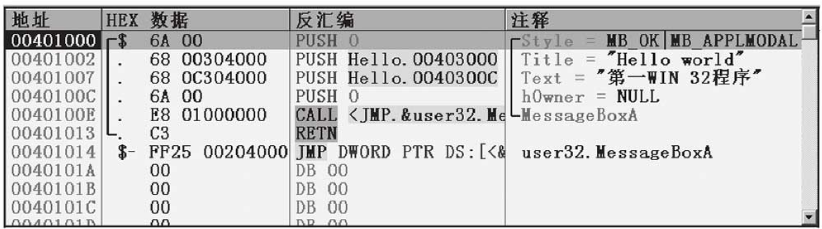
图1-21 初识OllyDbg
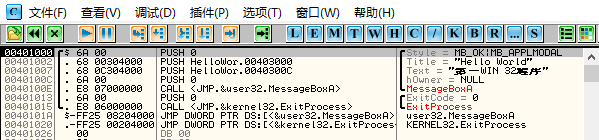
在图1-21中,代码运行到地址0x00401000处,对应反汇编指令PUSH 0,此汇编指令对应的机器码为6A 00(汇编指令对应的机器码可查询Intel的指令帮助手册)。在OllyDbg的注释窗口中,已经分析出此汇编指令的含义:OllyDbg根据CALL指令的地址,得知这个函数的首地址为API MessageBoxA的首地址,进而分析出对应的参数个数和参数功能。
2. 查看API MessageBoxA各参数的功能
查看MSDN文档,获取MessageBoxA各参数的功能,找到弹出对话框的标题参数(PUSH Hello.00403000),此参数保存了字符串“Hello world”的首地址。
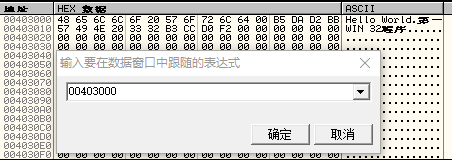
3. 定位数据
选中数据窗口,使用快捷键Ctrl+G,弹出数据跟随窗口。输入查询地址0x00403000,单击“确定”快速定位到该地址处。
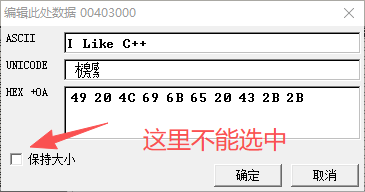
4. 修改数据
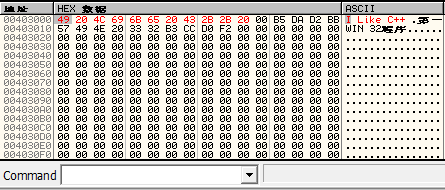
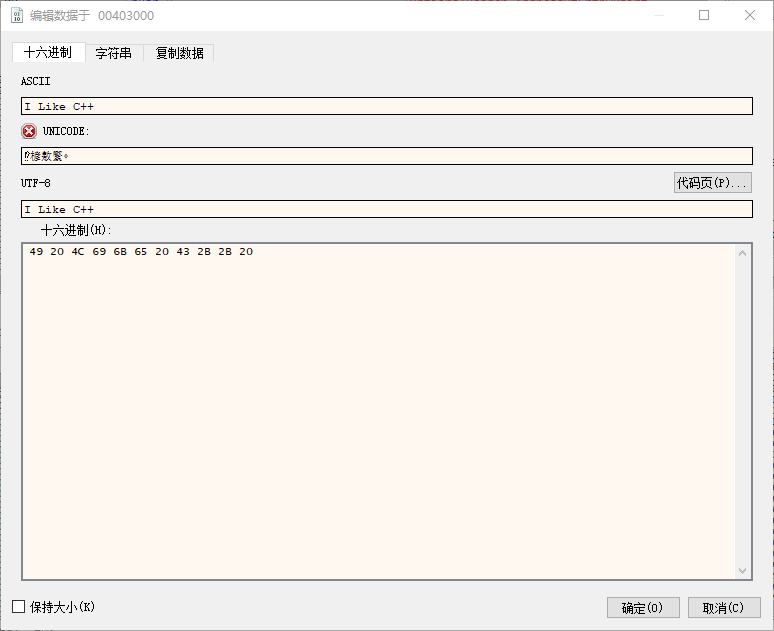
找到要修改数据的地址对应的HEX数据,在图1-22中,地址0x00403000对应的十六进制数据为0x48。双击HEX数据窗口中“48”处,弹出对应的编辑数据对话框,如图1-23所示。
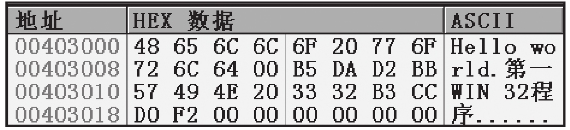
图1-22 初识数据窗口
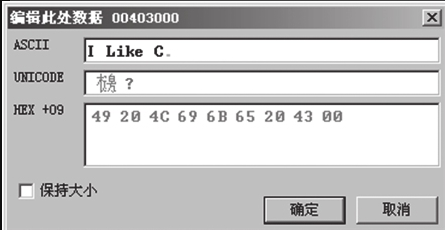
图1-23 数据编辑对话框
去掉“保持大小”的勾选,可向后修改数据。在ASCII文本编辑框中,输入“I Like C++”,由于C\C++中字符串以00结尾,需要将字符串最末尾的数据修改为00。选择十六进制编码文本框,在末尾处插入00。单击“确定”按钮,完成对字符串的修改。
5. 调试程序
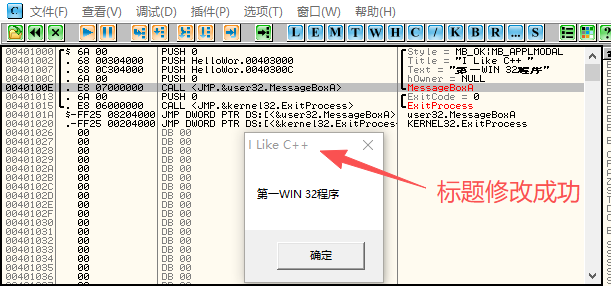
使用快捷键F8单步调试运行,连续按4次F8键,单步运行4条汇编指令,观察栈窗口变化,如图1-24所示。函数MessageBoxA所需参数都已被保存在栈中。按快捷键F7可跟进到函数MessageBoxA的实现代码中,这个API为一个间接调用,须再次按快捷键F7,程序运行到函数MessageBoxA的首地址处。MessageBoxA的实现代码较多,不适合初学者学习,使用快捷键Alt+F9返回到用户代码处,MessageBoxA运行结束,弹出运行结果对话框,查看是否修改成功。
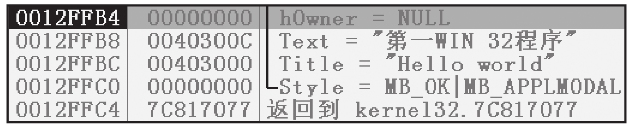
图1-24 栈窗口信息
如图1-25所示,标题已经修改成功。到此,OllyDbg的初识之旅就结束了。本节我们初步认识了OllyDbg,在后面的章节中,还会进一步介绍它的强大功能。
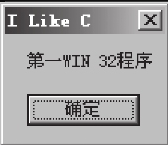
图1-25 运行结果
笔记------------------------------------------start
测试的源码:
;F:\learnDisassembly\chapter01\1_3\HelloWorld.asm
;ml -c -coff HelloWorld.asm
;link -subsystem:windows HelloWorld.obj
;在XP系统nmake编译 Makefile即可生成可执行程序
;----------------------------------------
.386
.model flat, stdcall
option casemap:none
include C:/masm32/include/windows.inc
include C:/masm32/include/user32.inc
includelib C:/masm32/lib/user32.lib
include C:/masm32/include/kernel32.inc
includelib C:/masm32/lib/kernel32.lib
;数据段
.data
szTitle db 'Hello World', 0
szText db '第一WIN 32程序', 0
;代码段
.code
start:
invoke MessageBox, NULL, offset szText, offset szTitle, MB_OK or MB_APPLMODAL
invoke ExitProcess, NULL
end start nmake生成HelloWorld.exe
1. 按F3加载可执行程序
2.查找对话框标题的参数地址
由PUSH HelloWor.00403000得出字符串“Hello world”的首地址为00403000
3.定位数据
选中数据窗口,使用快捷键Ctrl+G,弹出数据跟随窗口。输入查询地址0x00403000,单击“确定”快速定位到该地址处。
4.修改数据
右击地址0x00403000或数据窗口“48”处,弹出菜单,选择【二进制】=》【编辑】,然后修改数据
点【确定】按钮
5.调试程序
使用快捷键F8单步调试运行,连续按4次F8键,单步运行4条汇编指令,观察栈窗口变化,如图1-24所示。
笔记------------------------------------------end
1.4 调试工具x64dbg
OllyDbg虽然功能强大,但是并不支持64位应用程序的调试。x64dbg是一个开源的调试器,支持32/64位程序的调试,其功能、界面、快捷键与OllyDbg大体一致,会使用OllyDbg的人很容易适应x64dbg的使用方式。读者可以自行使用x64dbg修改“Hello world”程序的标题来熟悉x64dbg的使用。x64dbg的界面如图1-26所示。
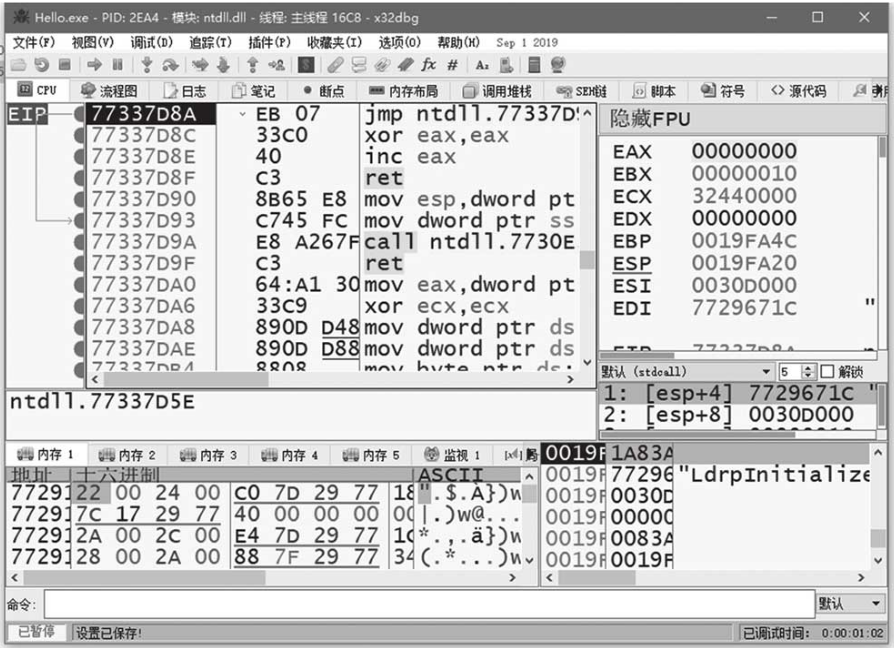
图1-26 x64dbg界面
笔记------------------------------------------start
1. 按F3加载可执行程序
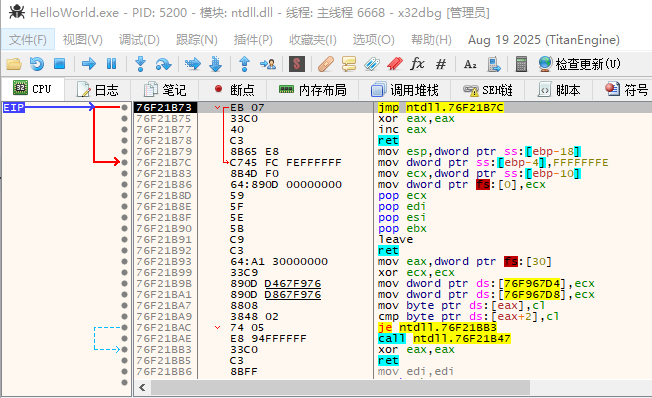
按F9运行到程序入口处理
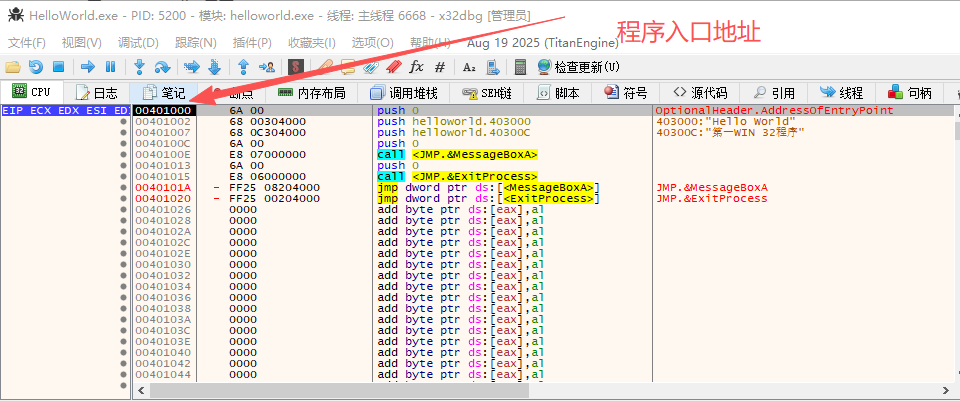
2.查找对话框标题的参数地址
由push hellowrold.403000得出字符串“Hello world”的首地址为00403000
3.定位数据
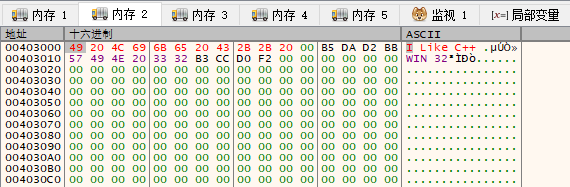
选中【内存2】窗口,使用快捷键Ctrl+G,弹出数据跟随窗口。输入查询地址00403000,单击“确定”快速定位到该地址处。
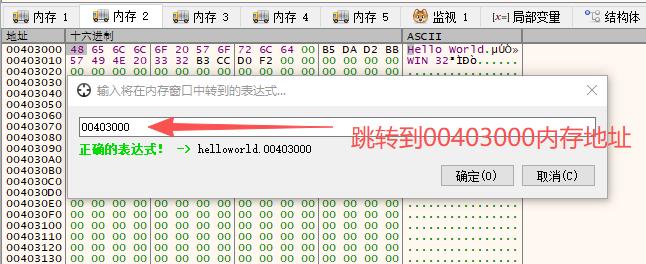
4.修改数据
右击地址0x00403000或数据窗口“48”处,弹出菜单,选择【二进制编辑】=》【编辑】,然后修改数据
点【确定】按钮
5.调试程序
使用快捷键F8单步调试运行,连续按4次F8键,单步运行4条汇编指令,观察栈窗口变化,如图1-24所示。
笔记------------------------------------------end
总结:OllyDbg和x64dbg的操作是一样的。
1.5 调试工具WinDbg
WinDbg是微软公司出品的一个支持32/64位程序调试的免费调试器,既支持有源码的程序调试,又支持无源码的程序调试。WinDbg不仅可以调试应用程序,还可以进行内核调试。WinDbg的一个强大之处在于可以从微软的符号服务器中获取系统符号文件,使应用程序或内核调试的反汇编代码可读性更好。WinDbg界面如图1-27所示,图中的标号说明如下。
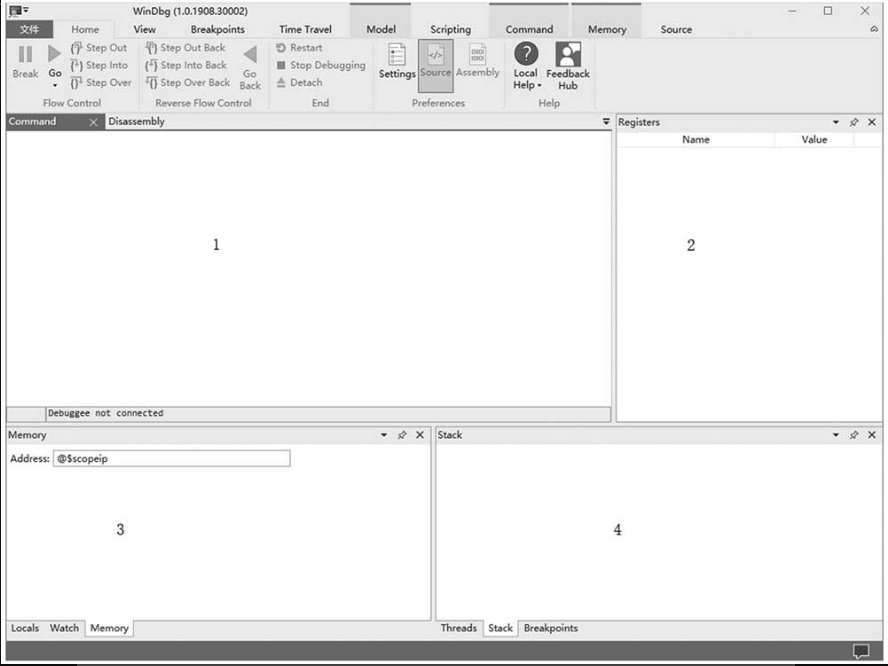
图1-27 WinDbg界面
1:命令汇编窗口。
2:寄存器窗口。
3:内存变量窗口。
4:栈窗口。
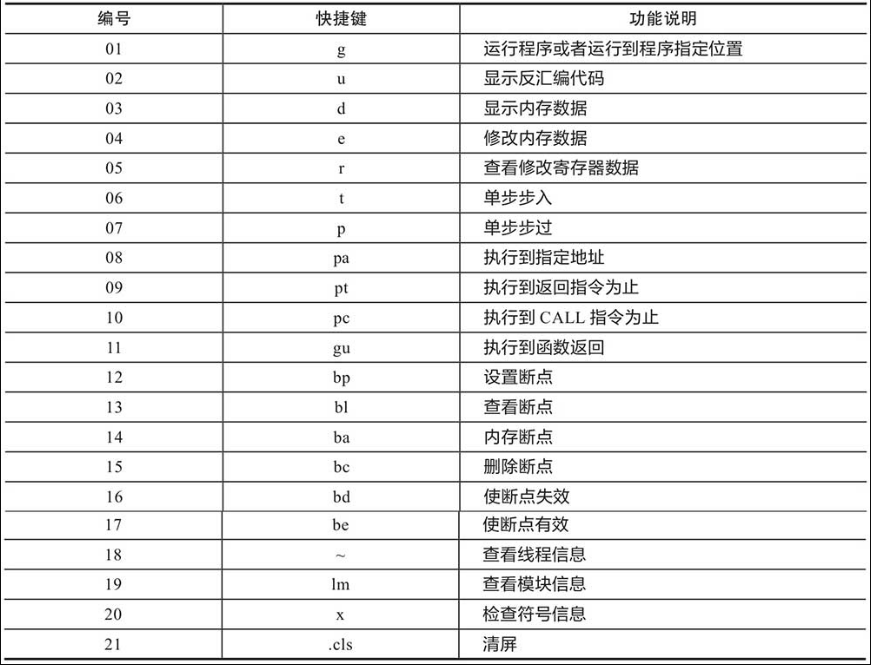
虽然WinDbg也提供图形界面操作,但它最强大的地方还是调试命令,通常情况下会结合图形界面和命令行进行操作,初学者可以从一些常用的调试命令开始,通过快捷键F1查看命令的使用帮助,WinDbg的常用命令如表1-2所示。
表1-2 WinDbg的常用命令
a命令 向内存写入一段汇编指令——这么重要的测试指令都不介绍
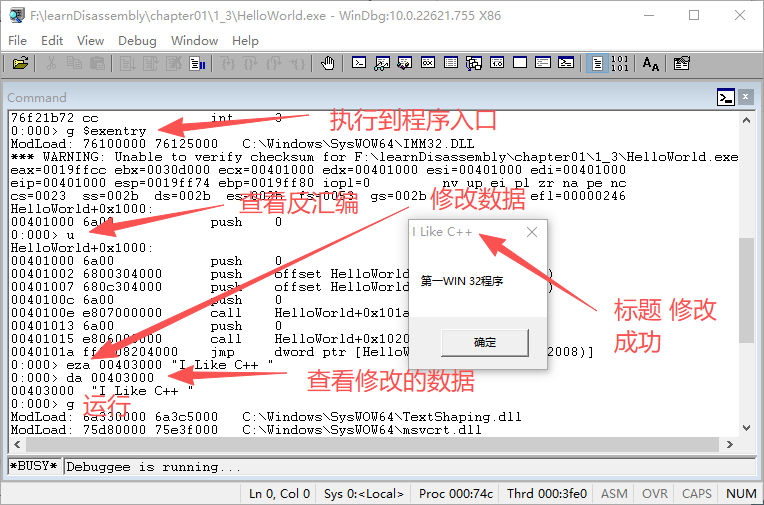
通过实际操作演练,我们使用命令调试“Hello world”程序,将“Hello world”程序对话框标题修改为“I Like C++”,如图1-28所示,步骤如下。
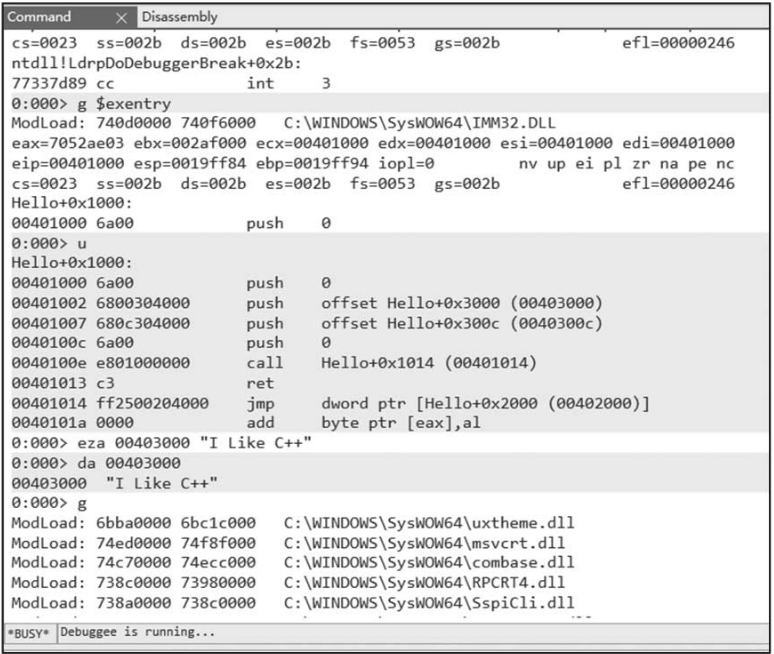
图1-28 使用WinDbg修改程序
加载可执行程序Ctrl+E。
输入命令执行到入口代码:g $exentry。
输入命令查看反汇编代码:u。
输入命令修改内存:eza 00403000 "I Like C++"。
输入命令查看修改的数据:da 00403000。
输入命令运行程序:g。
笔记------------------------------------------start
笔记------------------------------------------end
1.6 反汇编静态分析工具IDA
所谓静态分析,是相对于动态分析而言的。在动态分析的过程中,调试器加载程序,并以调试模式运行起来,分析者可以在执行过程中观察程序的执行流程和计算结果。但是,在实际分析中,很多场合不方便运行目标,比如软件的某一模块(无法单独运行)病毒程序、设备环境不兼容导致无法运行。那么,在这个时候,需要直接把程序的二进制代码翻译成汇编语言,方便程序员阅读。像这样由目标软件的二进制代码到汇编代码的翻译过程,我们称之为反汇编。OllyDbg也具有反汇编功能,但它是调试工具,其反汇编辅助分析功能有限,不适用于静态分析。
本节将介绍辅助功能极为强大的反汇编静态分析工具IDA。它的图标是被称为“世界上第一位程序员”的Ada Lovelace的头像,可译为阿达。本书使用的IDA版本为7.0英文版。成功安装IDA后,会出现两个可执行程序图标,一个是黑白的阿达头像,另一个是在阿达头部写有“64”字样的图像,它们分别对应32位程序和64位程序的分析,本节分析的程序全部为32位。
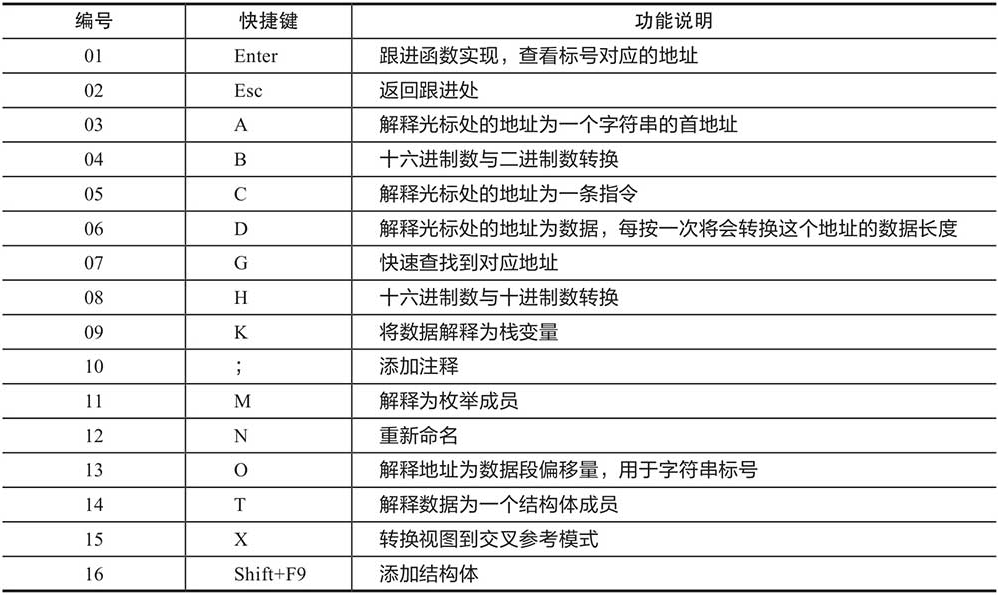
IDA窗口中的工具条、菜单选项较多,初学IDA时只要掌握基本操作即可。IDA的常用快捷键使用说明如表1-3所示。
表1-3 IDA的常用快捷键使用说明
下面我们使用IDA静态分析1.1节的调试程序“Hello world”,通过实例进一步学习IDA的基本使用方法。
1. 加载分析文件
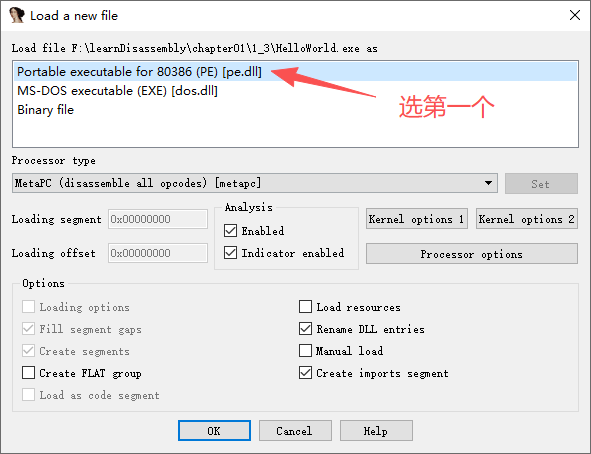
IDA加载分析文件后,会询问分析的方式。有3种分析方式供选择,如图1-29所示。

图1-29 IDA加载分析文件
Portable executable for 80386(PE)[pe.ldw]:分析文件为PE格式。MS-DOS executable(EXE)[dos.ldw]:分析文件为DOS控制台下的一个文件。Binary file:分析文件为二进制格式。
根据分析文件的格式进行选择,本示例为一个PE格式文件,故选择第一种分析方式,单击“确定”,分析结束后,IDA默认情况下会显示流程视图窗口。
2. 认识各视图功能
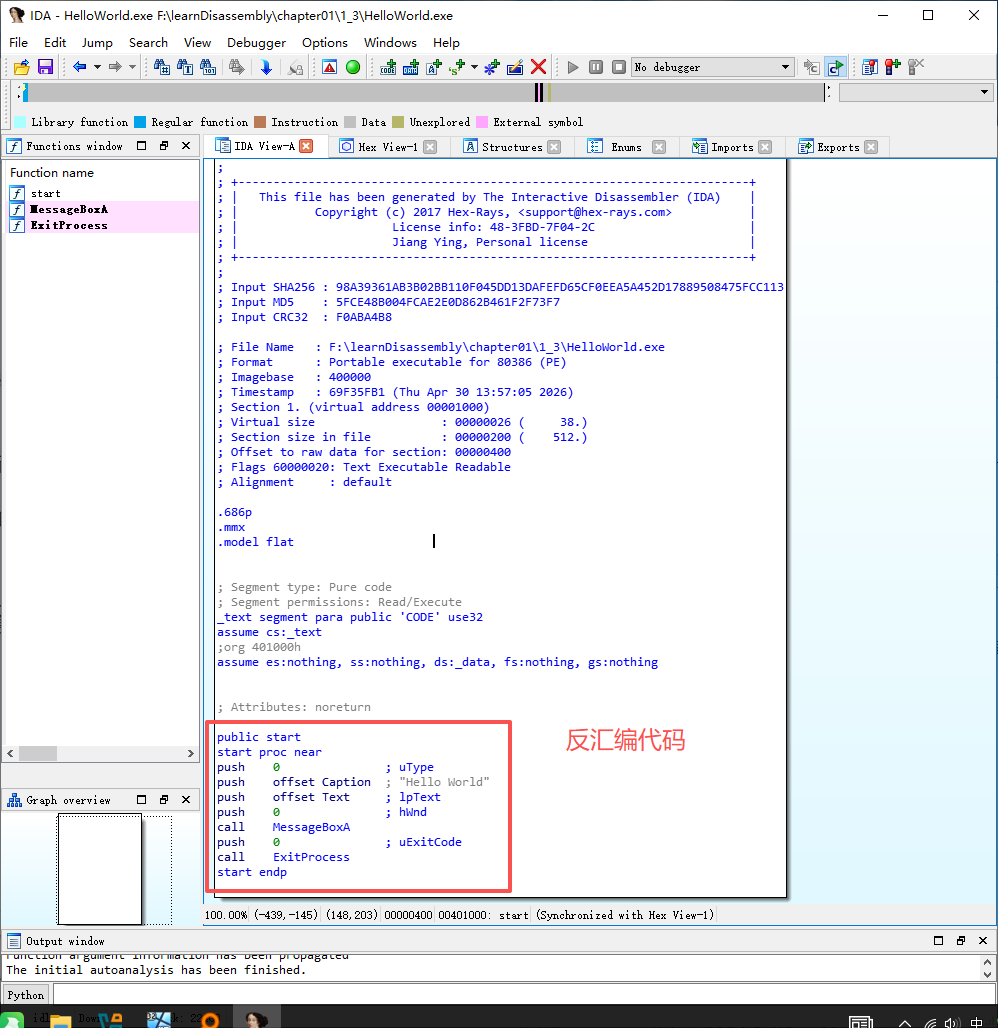
视图窗口如图1-30所示,说明如下。
![]()
图1-30 IDA的各视图窗口
IDA View-A:分析视图窗口,用于显示分析结果,可选用流程图或代码形式。
Hex View-1:二进制视图窗口,打开文件的二进制信息。
Exports:分析文件中的导出函数信息窗口。
Imports:分析文件中的导入函数信息窗口。
Names Window:名称窗口,分析文档用到的标称。
Functions Window:分析文件中的函数信息窗口。
Structures:添加结构体信息窗口。
Enums:添加枚举信息窗口。
3. 查看分析结果
“Hello world”反汇编分析示例如图1-31所示,图中为IDA分析后的反汇编代码,将其复制到汇编IDE中,只要稍加修改,就可以进行编译和连接。IDA的数据查询非常简单,只需要双击标号,即可跟踪到该数据的定义处。查看函数实现的方式也是如此,如果需要返回调用处,按Esc键即可返回。由于有IDA的帮助,将一个二进制文件还原成等价的C\C++代码的难度大大降低了。
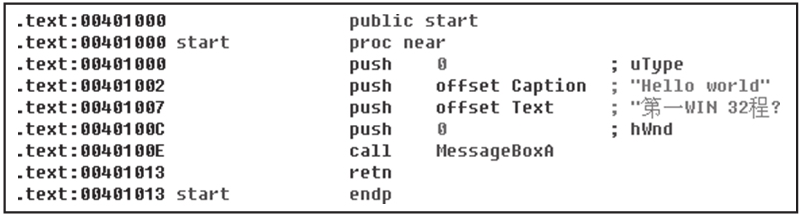
图1-31 “Hello world”反汇编分析示例
4. 切换反汇编视图与流程视图
图1-31中的反汇编代码是从IDA的反汇编视图中提取的。IDA的默认视图为流程视图,需要进行转换。在函数体内,选择Text view。同理,如果要从反汇编视图切换回流程视图,可选择Graph view(流程视图),使分析程序的流程结构和工程量变得更加容易。
5. IDA函数名称识别
在图1-31中,IDA可以识别出函数MessageBoxA及各参数的信息,IDA通过SIG文件识别已知的函数信息。在安装IDA的同时,已将常用库制作为SIG文件,放置在IDA安装目录的SIG文件夹下。利用此功能可识别第三方提供的库函数,从而简化分析流程。
制作SIG文件有如下两个步骤(使用前须设置环境变量路径)。
(1)将每个OBJ或者LIB文件制作成PAT文件
OBJ文件中包含函数的名称和对应实现代码的二进制机器码,LIB文件包含OBJ文件(见图1-32)。

图1-32 LIBC.lib中包含的部分OBJ信息
在制作PAT文件的过程中,会提取出这些二进制机器码的特征,将二进制机器码的特征码及对应函数的名称保存在PAT文件中。特征码就好像是人的五官,我们可以通过五官特征来识别一个人,将函数比作独立的人,它们有各自不同的特点。如果某个文件拥有这些特征信息,便可确认此文件使用了这个OBJ,并可以借此识别函数名称。OBJ生成PAT时使用的是pcf.exe或者pelf.exe(见随书文件1.2[1]=>登录www.hzbook.com下载随书文件。)。其中pcf.exe用于制作COFF文件格式(.obj、.lib库文件)、pelf用于制作ELF文件格式(.o、.a库文件)。在控制台下使用如下pcf命令。
pcf [Obj name].obj
pcf [Lib name].lib
指令说明如下。
[Obj name]:OBJ文件名称。
[Lib name]:LIB文件名称。
(2)多PAT文件联合编译SIG文件
SIG文件是由一个或多个PAT文件编译而成的。在生成SIG文件的过程中,如果多个PAT文件中有两个或两个以上的函数特征码相同,将会过滤掉重复特征,只保存一份。在控制台下使用sigmake.exe将PAT文件编译成SIG文件,格式如下所示。
sigmake [Pat name].pat [Sig name].sig
指令说明如下。
[Pat name]:PAT文件名称。当多个PAT文件参与编译时,用*代替名称,将所选目录下所有后缀名为pat的文件编译为一个后缀名为sic的文件。[Sig name]:编译后生成的SIG文件的名称。
在制作SIG文件的过程中,如果包含的LIB文件过多,如何快速将所有LIB文件生成SIG文件呢?我们可根据SIG文件的制作流程编写程序,将LIB文件逐个提取出来,生成对应的PAT文件,再将所有PAT文件编译为SIG文件;也可以编写批处理文件快速生成SIG文件。将生成后的SIG文件放置在IDA的安装目录SIG文件夹下。使用快捷键Shift+F5添加SIG文件到分析工程中,如图1-33所示。

图1-33 SIG文件的签名窗口
图1-33显示了当前分析工程中使用到的SIG文件。使用Insert键可加载SIG文件用于此工程;也可以在视图中单击Apply new signature添加SIG文件。SIG解析前后对比如图1-34所示。

图1-34 SIG解析对比
通过图1-34可知,IDA已经成功解析出函数sub_40505A对应名称为__cexit,同时将参数解析出来。有了SIG文件的帮助,分析工作将更为简单。SIG文件制作批处理文件的过程如代码清单1-1所示。
代码清单1-1 SIG文件制作批处理文件的过程
if %1=="" goto end
for %%i in (*.lib,*.obj) do (pcf %%i)
sigmake -r *.pat %1.sig
del *.pat
:end代码清单1-1说明了如下几个问题。
if %1=="" goto end检查命令行参数。在当前目录下循环遍历所有LIB和OBJ文件,并逐一通过PCF转换成对应的PAT文件。通过sigmake工具将所有PAT文件打包为一个SIG文件。删除生成的所有PAT文件。
将代码清单1-1保存为“lib2sig.bat”,放置在自己创建的目录下,将第三方库或者编译器的库复制到此目录下,在控制台下使用此批处理文件,“lib2sig.bat”的使用方法如下。
lib2sig [ 生成SIG文件名称 ]设置环境变量时,需要获取pcf.exe、sigmake.exe的路径,即依次选择“我的电脑”→“属性”→“高级”→“环境变量”→“新建系统变量”→“变量名path”→“变量值”。
在使用这些指令的过程中,如果出现“不是内部或外部命令,也不是可运行的程序”的提示,请检查环境变量是否设置正确。每次修改pcf.exe、sigmake.exe的路径时,都需要重新设置环境变量,否则只能在对应目录中使用它们。读者可以使用此批处理文件将编译器自带的所有32位库和64位库分别制作成SIG文件。
笔记------------------------------------------start
1.打开分析文件
2.各视图功能介绍
IDA View-A:分析视图窗口,用于显示分析结果,可选用流程图或代码形式。
Hex View-1:二进制视图窗口,打开文件的二进制信息。
Exports:分析文件中的导出函数信息窗口。
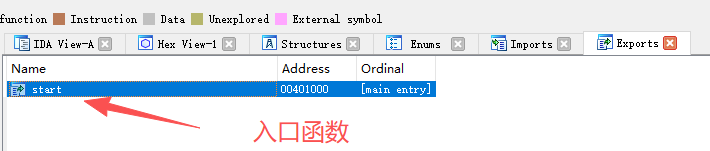
Imports:分析文件中的导入函数信息窗口。

Names Window:名称窗口,分析文档用到的标称。
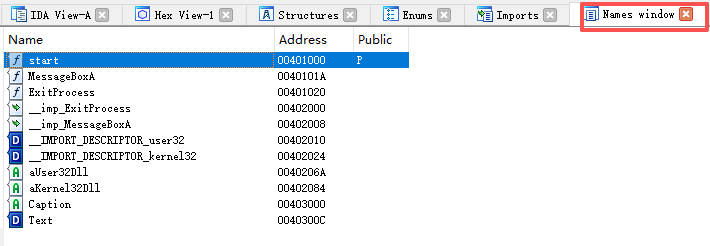
Functions Window:分析文件中的函数信息窗口。
Structures:添加结构体信息窗口。
Enums:添加枚举信息窗口。
3.查看分析结果

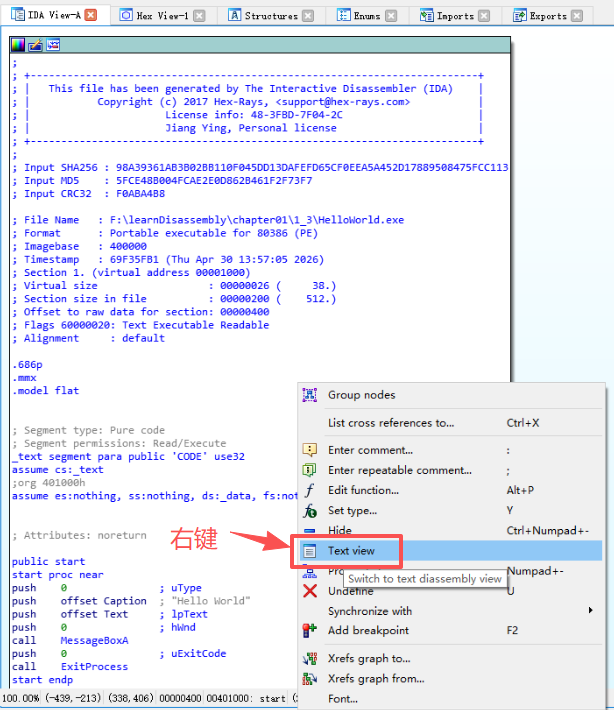
4.切换反汇编视图与流程视图
右键,选择Text view切换反汇编视图
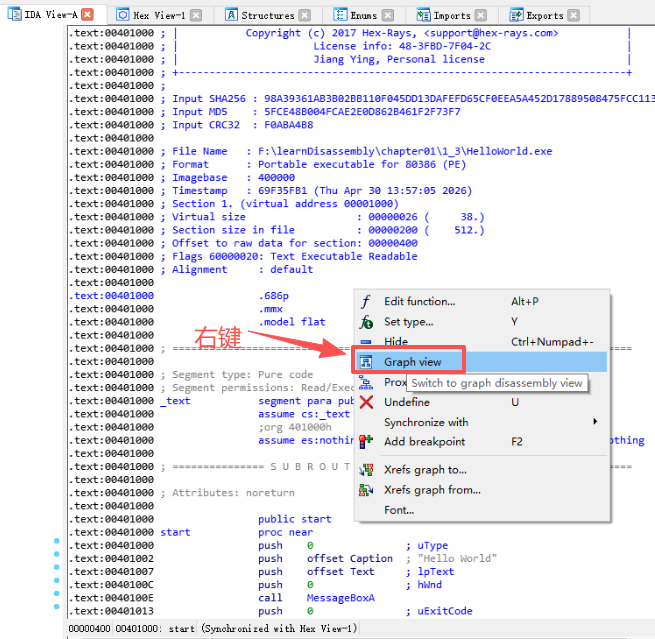
右键,选择TGraph view切换流程视图
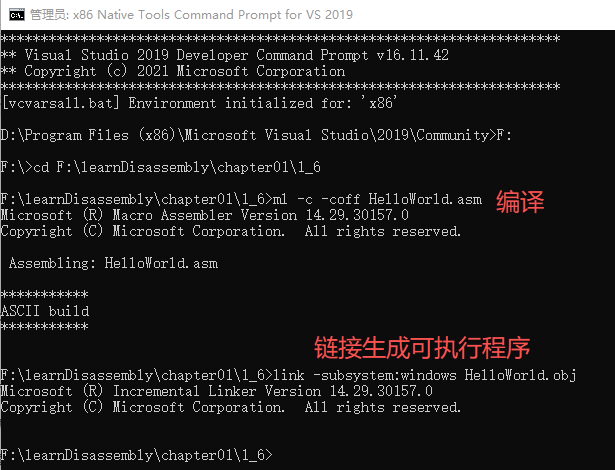
5.IDA函数名称识别
这里以HelloWorld为例,源码如下:
;F:\learnDisassembly\chapter01\1_6\HelloWorld.asm
;ml -c -coff HelloWorld.asm
;link -subsystem:windows HelloWorld.obj
;在XP系统nmake编译 Makefile即可生成可执行程序
;----------------------------------------
.386
.model flat, stdcall
option casemap:none
include C:/masm32/include/windows.inc
include C:/masm32/include/user32.inc
includelib C:/masm32/lib/user32.lib
include C:/masm32/include/kernel32.inc
includelib C:/masm32/lib/kernel32.lib
;数据段
.data
szTitle db 'Hello World', 0
szText db '第一WIN 32程序', 0
theSum DWORD ?
;代码段
.code
main proc
mov eax, 30h
mov eax, 40h
call SumOf
mov theSum, eax
invoke MessageBox, NULL, offset szText, offset szTitle, MB_OK or MB_APPLMODAL
invoke ExitProcess, NULL
main endp
SumOf proc
add eax, ebx
ret
SumOf endp
end main
编译&&链接 生成obj和exe文件
a.设置环境变量
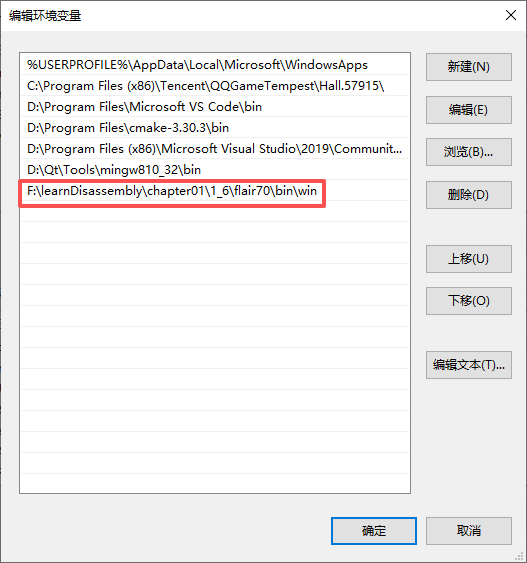
b.生成pat文件
pcf HelloWorld.obj HelloWorld.pat
c.生成sig文件
sigmake HelloWorld.pat HelloWorld.sig
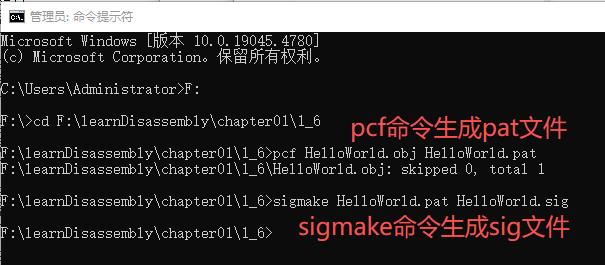
d.使用批处理命令生成sig文件
把HelloWorld.obj文件放到批处理文件目录F:\learnDisassembly\chapter01\1_6\lib2sig
然后执行lib2sig.bat HelloWorld2 (不用加后缀sig, 生成时会自带后缀)
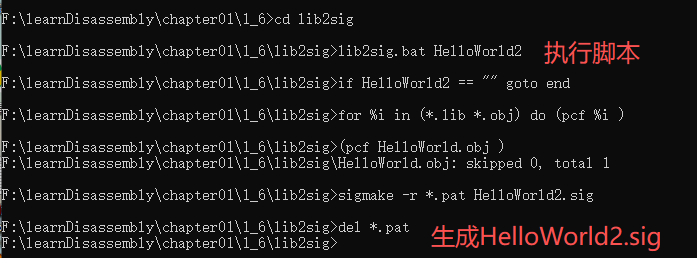
用Beyond Compare对比,HelloWorld.sig和HelloWorld2.sig文件是一样的。
e.测试
用IDA打开HelloWorld.exe
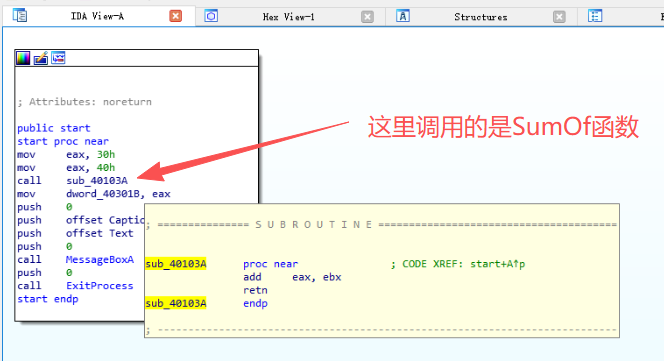
将HelloWorld.sig放到IDA安装目录SIG文件夹下。(D:\Program Files\IDA 7.0\sig\pc目录)按Shift+F5加载sig
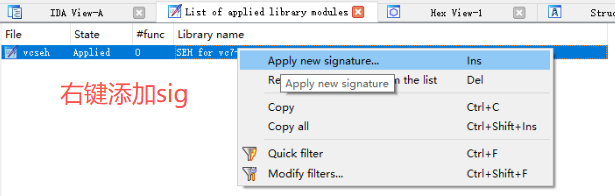
添加HelloWorld.sig
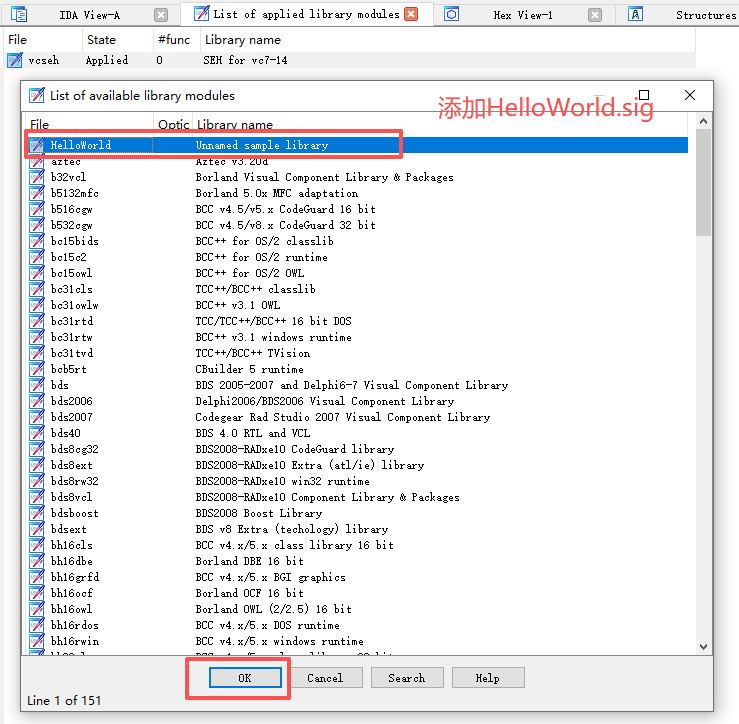
点【OK】,然后切换到IDA View-A分析视图窗口
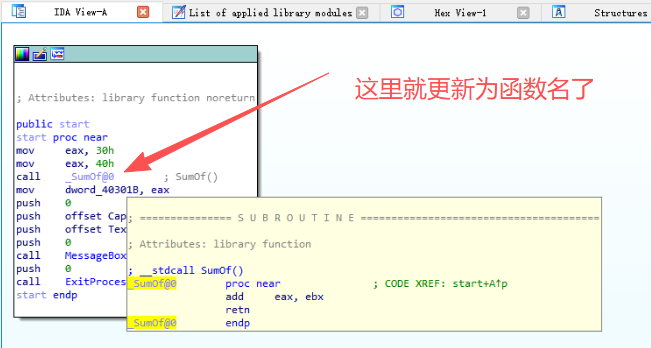
笔记------------------------------------------end
1.7 反汇编引擎的工作原理
通过以上的例子,相信读者已经发现OllyDbg和IDA都有一个很重要的功能:反汇编。现在为大家讲解反汇编引擎的工作原理。
在x86平台下使用的汇编指令对应的二进制机器码为Intel指令集Opcode。
Intel指令手册中描述的指令由6部分组成,如图1-35所示。

图1-35 Intel指令结构图
针对图1-35结构图进行如下说明。
1. Instruction Prefixes:指令前缀
指令前缀是可选项,作为指令的补充说明信息,主要用于以下4种情况。
重复指令,如REP、REPE\REPZ。
跨段指令,如MOV DWORD PTR FS:[XXXX], 0。
将操作数从32位转为16位,如MOV AX,WORD PTR DS:[EAX]。
将地址从16位转为32位,如MOV EAX,DWORD PTR DS:[BX+SI]。
2. Opcode:指令操作码
Opcode是机器码中的操作符部分,用来说明指令语句执行什么操作,比如说明某条汇编语句是MOV、JMP还是CALL。Opcode是汇编指令语句必不可少的组成部分,解析Opcode也是反汇编引擎的主要工作。
汇编指令助记符与Opcode是一一对应的关系。每一条汇编指令助记符都会对应一条Opcode,但由于操作数类型不同,所占长度也不相同,因此对于非单字节指令来说,解析一条汇编指令单凭Opcode是不够的,想要完整地解析出汇编信息,还需要Mode R/M、SIB、Displacement的帮助。
3. Mode R/M:操作数类型
Mode R/M的作用是辅助Opcode解释汇编指令助记符后面的操作数类型。R表示寄存器,M表示内存单元。Mode R/M占一字节的固定长度,如图1-36所示。第6、7位可以描述4种状态,分别用来描述第0、1、2位是寄存器还是内存单元,以及3种寻址方式。第3、4、5位用于辅助Opcode。

图1-36 Mode R/M结构
4. SIB:辅助Mode R/M计算地址偏移
SIB的寻址方式为基址+变址,如MOV EAX,DWORD PTR DS:[EBX+ECX*2],其中的ECX、乘数2都是由SIB指定的。SIB的结构如图1-37所示,SIB占1字节,第0、1、2位用于指定作为基址的寄存器;第3、4、5位用于指定作为变址的寄存器;第6、7位用于指定乘数,由于只有两位,因此可以表示4种状态,这4种状态分别表示乘数为1、2、4、8。

图1-37 SIB结构
5. Displacement:辅助Mode R/M,计算地址偏移
Displacement用于辅助SIB,如MOV EAX,DWORD PTR DS:[EBX+ECX*2+3]这条指令,其中“+3”是由Displacement指定的。
6. Immediate:立即数
用于解释指令语句中操作数为一个常量值的情况。
反汇编引擎通过查表将由以上6种方案组合而成的机器指令编码解释为对应的汇编指令,从而完成机器码的转换工作。本节将介绍一款成熟的反汇编引擎Proview的开源代码,其源码片段如代码清单1-2所示。
代码清单1-2 Proview的源码片段
// 机器码解析函数
/*
DISASSEMBLY 结构说明
typedef struct Decoded
{
char Assembly[256]; // 汇编指令信息
char Remarks[256]; // 汇编指令说明信息
char Opcode[30]; // Opcode信息
DWORD Address; // 当前指令地址
BYTE OpcodeSize; // Opcode长度
BYTE PrefixSize; // 指令前缀长度
} DISASSEMBLY;
*/
void Decode(DISASSEMBLY *Disasm,
char *Opcode,
DWORD *Index)
{
/*
源码中函数说明信息略
源码中变量局部定义略
*/
// 机器码格式分析略
// 判断是否符合Opcode格式,Op为参数Opcode[0]项
switch(Op) // 分析Op对应的机器码
{ // 部分PUSH指令分析机器码信息,对照图1-2
case 0x68:
// 方式1:PUSH 4字节内存地址信息
{
// 判断寄存器指令前缀
if(RegPrefix == 0) {
// PUSH 指令后按4字节方式解释
// 如当前机器码为:6800304000
// 因为在内存中为小尾方式排序,所以取出内容需要重新排列数据
// 此函数对指令地址加1,偏移到00304000处,将其排序为00403000
// 提取出的机器指令存放在dwOp中
// 转换后的地址信息保存在dwMem中
SwapDword((BYTE *) (Opcode + i + 1), &dwOp, &dwMem);
// 将机器指令信息转换为汇编指令信息
wsprintf(menemonic, push %08X",dwMem);
// 保存汇编指令语句到Disasm结构中,用于返回
lstrcat(Disasm->Assembly, menemonic);
// 组装机器码信息,用空格将指令码与操作数分离
wsprintf(menemonic, 68 %08X",dwOp);
// 将机器码信息保存到Disasm结构中,用于返回
lstrcat(Disasm->Opcode, menemonic);
// 设置指令要占用的内存空间
Disasm->OpcodeSize = 5;
// 设置指令前缀长度
Disasm->PrefixSize = PrefixesSize;
// 对当前分析指令地址下标加4字节偏移量
(*Index) += 4;
}
else{
// PUSH指令后按2字节方式解释
// 解析机器码,与以上代码相同
SwapWord((BYTE *) (Opcode + i + 1), &wOp, &wMem);
// 按2字节解释操作数
"push %04X" wsprintf(menemonic, "push %04X", wMem);
lstrcat(Disasm->Assembly, menemonic);
// 按2字节解释操作数"push %04X"
wsprintf(menemonic, "68 %04X", wOp);
lstrcat(Disasm->Opcode, menemonic);
// 设置指令长度
Disasm->OpcodeSize = 3;
// 设置指令前缀长度
Disasm->PrefixSize = PrefixesSize;
// 对当前分析指令地址下标加2字节偏移量
(*Index) += 2;
}
}
break; case
0x6A:
// 方式2:PUSH指令的操作数是小于等于1字节的立即数
{
// 有符号数判断,负数处理
if((BYTE) Opcode[i + 1] >= 0x80){
// 负数在内存中为补码,用0x100-补码得回原码
// "push -%02X"中对原码加负号
wsprintf(menemonic, "push -%02X", (0x100 - (BYTE) Opcode[i + 1]));
}
// 有符号数判断,正数处理
else{
// 正数直接转换
wsprintf(menemonic, "push %02X", (BYTE) Opcode[i + 1]);
}
// 保存汇编指令语句
lstrcat(Disasm->Assembly, menemonic);
// 组装机器码信息
wsprintf(menemonic, "6A%02X", (BYTE) * (Opcode + i + 1));
// 保存机器码信息
lstrcat(Disasm->Opcode, menemonic);
// 设置指令长度与指令前缀长度
Disasm->OpcodeSize = 2;
Disasm->PrefixSize = PrefixesSize;
// 对当前分析指令地址下标加2字节偏移量
++(*Index);
}
break;
}
// 机器码格式分析略代码清单1-2中省略了其他机器码的解析过程,只列举了汇编助记符PUSH的两种指令方式。通过解析Opcode,可以找到对应的解析方式,将机器码重组为汇编代码。通过第一个参数DISASSEMBLY *Disasm传出解析结果,将机器码指令长度由参数Index传出,用于寻找下一个Opcode指令操作码。使用函数Decode对机器码进行分析,见代码清单1-3。
代码清单1-3 使用反汇编引擎解析机器码
// 假设此字符数组为机器指令编码
unsigned char szAsmData[] = {
0x6A, 0x00, // PUSH 00
0x68,0x00,0x30,0x40,0x00, // PUSH 00403000
0x50, // PUSH EAX
0x51, // PUSH ECX
0x52, // PUSH EDX
0x53 // PUSH EBX
};
char szCode[256] = {0}; // 存放汇编指令信息
unsigned int nIndex = 0; // 每条机器指令的长度,用于地址偏移
unsigned int nLen = 0; // 分析机器码总长度
unsigned char *pCode = szAsmData;
// 获取分析机器码长度
nLen = sizeof(szAsmData); while
(nLen)
{
// 检查是否超出分析范围
if (nLen < nIndex)
{
break;
}
// 修改 pCode 偏移
pCode += nIndex;
// 解析机器码,此函数实现见代码清单1-4
// 参数一 pCode :分析机器码首地址
// 参数二 szCode :返回值,保存解析后的汇编指令语句信息
// 参数三 nIndex :返回值,保存机器码指令的长度
// 由于参数四是模拟机器码,没有对应代码地址,因此传入0 Decode2Asm(pCode, szCode,
&nIndex, 0);
// 显示汇编指令
puts(szCode);
memset(szCode, 0, sizeof(szCode));
}通过函数Decode2Asm,启动反汇编引擎Proview,通过代码清单1-3中的分析流程,解析出对应汇编指令语句代码并输出。PUSH寄存器指令的分析并没有在代码清单1-3中列举,分析过程大致相同,读者可查看Proview源码并自行分析。
代码清单1-4 Decode2Asm实现流程
void stdcall
Decode2Asm(IN PBYTE pCodeEntry, // 分析Opcode地址,无符号字符型指针
OUT char* strAsmCode, // 传出值,保存汇编指令的语句信息OUT
UINT* pnCodeSize, // 传出值,保存机器码指令的大小UINT nAddress)
// 分析机器码所在地址
{
DISASSEMBLY Disasm; // 此结构信息见代码清单1-3
// 保存Opcode指针,用于传递函数参数
char *Linear = (char *)pCodeEntry;
// 初始化指令长度
DWORD Index = 0;
// 设置机器码所在地址
Disasm.Address = nAddress;
// 初始化Disasm
FlushDecoded(&Disasm);
// 调用Decode进行机器码分析
Decode(&Disasm, Linear, &Index);
// 保存汇编指令语句信息
strcpy(strAsmCode, Disasm.Assembly);
// 组装汇编语句的字符串,从参数strAsmCode返回信息
if(strstr((char *)Disasm.Opcode, ":"))
{
Disasm.OpcodeSize++; char ch =' ';
strncat(strAsmCode,&ch,sizeof(char));
}
strcat(strAsmCode,Disasm.Remarks);
*pnCodeSize = Disasm.OpcodeSize; FlushDecoded(&Disasm);
return;
}代码清单1-4对汇编引擎Proview的使用进行了封装,以简化Decode函数的调用过程,方便使用者调用。本节源码见随书文件,在工程Disasm_Push目录下,其Disasm、Disasm_Functions为Proview的源码,Decode2Asm为使用封装代码。
笔记------------------------------------------start
实验代码所在路径 F:\learnDisassembly\chapter01\1_7\Disasm_Push
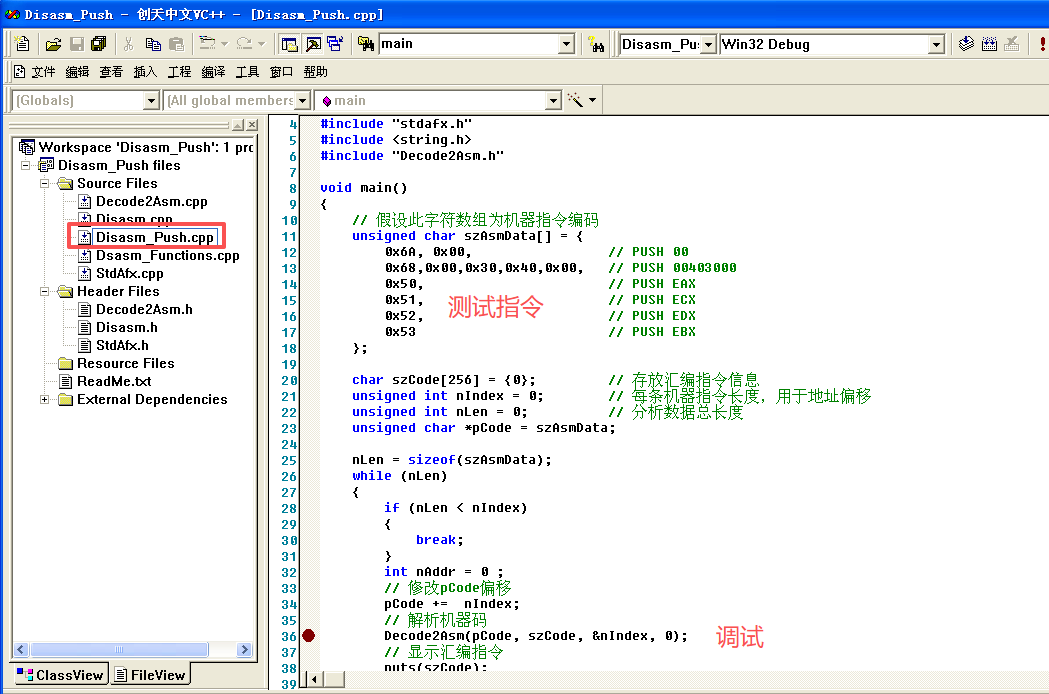
笔记------------------------------------------end
更多关于汇编指令及其对应机器码的信息请参考Intel的指令帮助手册,读者可在Intel的官方网站下载最新版的帮助手册(https://software.intel.com/en-us/articles/intel-sdm)。另外,随书文件中还提供了一个低版本的Intel指令帮助手册。
1.8 本章小结
本章介绍了进行C++反汇编和逆向分析的工作环境和必备工具的使用方法,在继续学习后面的内容之前,读者要先学会配置工作环境并掌握这些工具的使用方法。随着学习的深入,相信读者对C++反汇编和逆向分析的工作环境会越来越熟悉。
虽然本书没有介绍调试器的原理,但是笔者在教学工作中经常要求学员自己开发调试器引擎,并且在看雪安全论坛(www.pediy.com)的调试版块免费发布相关技术文档、调试器引擎的demo和源码,有兴趣的读者可以自行搜索并阅读。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










