




 本文深入浅出地介绍了信息熵、信息增益、信息增益率和基尼系数等决策树核心概念。通过实例解析,帮助读者理解如何利用这些指标在决策树算法中进行特征选择,以便构建高效预测模型。
本文深入浅出地介绍了信息熵、信息增益、信息增益率和基尼系数等决策树核心概念。通过实例解析,帮助读者理解如何利用这些指标在决策树算法中进行特征选择,以便构建高效预测模型。

决策树系列目录(文末有彩蛋):
决策树②——决策树算法原理(ID3,C4.5,CART)
决策树③——决策树参数介绍(分类和回归)
决策树④——决策树Sklearn调参(GridSearchCV)
决策树⑤——Python代码实现决策树
决策树应用实例①——泰坦尼克号分类
决策树应用实例②——用户流失预测模型
决策树应用实例③——银行借贷模型
决策树应用实例④——淘宝&京东白条(回归&均方差&随机森林)
本文主要是通过大白话,解释何为 信息,信息熵,信息增益,信息增益率,基尼系数(文末有大礼赠送)
一、信息
能消除不确定性的内容才能叫信息,而告诉你一个想都不用想的事实,那不叫信息。
比如数据分析师的工作经常是要用数据中发现信息,有一天上班你告诉老大从数据中发现我们的用户性别有男有女。。。(这不废话吗?)这不叫信息,但是如果你告诉老大女性用户的登录频次、加购率,浏览商品数量远高于男性,且年龄段在25岁~30岁的女性用户消费金额最多,15-20岁最少,那么我相信你老大会眼前一亮的!!!
如何衡量信息量?1948年有一位科学家香农从引入热力学中的熵概念,得到了信息量的数据公式:
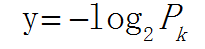
Pk代表信息发生的可能性,发生的可能性越大,概率越大,则信息越少,通常将这种可能性叫为不确定性,越有可能则越能确定则信息越少;比如中国与西班牙踢足球,中国获胜的信息量要远大于西班牙胜利(因为这可能性实在太低~~)
二、信息熵
信息熵则是在信息的基础上,将有可能产生的信息定义为一个随机变量,那么变量的期望就是信息熵,比如上述例子中变量是赢家,有两个取值,中国或西班牙,两个都有自己的信息,再分别乘以概率再求和,就得到了这件事情的信息熵,公式如下:
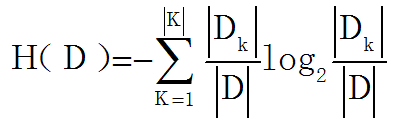
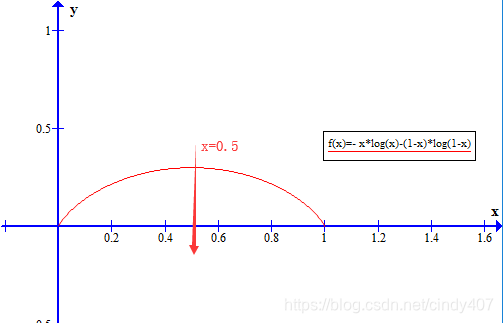
假如只有2个取值,曲线长得特别像金拱门,当Pk=0或1时,信息量为0,当Pk=0.5时,信息熵最大,想想看一件事情有N多种结果,有各种结果都同样有可能的时候,是不是最难以料到结局?
三、信息增益
信息增益是决策树中ID3算法中用来进行特征选择的方法,就是用整体的信息熵减掉以按某一特征分裂后的条件熵,结果越大,说明这个特征越能消除不确定性,最极端的情况,按这个特征分裂后信息增益与信息熵一模一样,那说明这个特征就能获得唯一的结果了。
这里补充一个概念:条件熵,公式为:
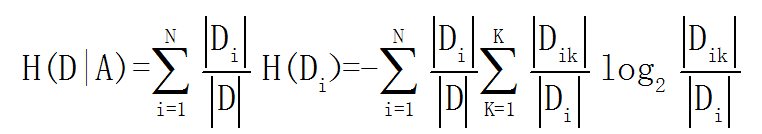
信息增益为:
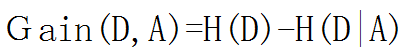
四、信息增益率
信息增益率是在信息增益的基础上,增加了一个关于选取的特征包含的类别的惩罚项,这主要是考虑到如果纯看信息增益,会导致包含类别越多的特征的信息增益越大,极端一点,有多少个样本,这个特征就有多少个类别,那么就会导致决策树非常浅。公式为:
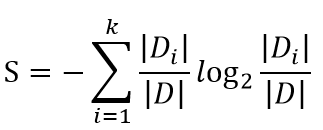
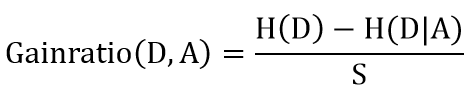
五、基尼系数
基尼系数也是一种衡量信息不确定性的方法,与信息熵计算出来的结果差距很小,基本可以忽略,但是基尼系数要计算快得多,因为没有对数,公式为:
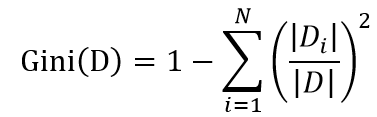
与信息熵一样,当类别概率趋于平均时,基尼系数越大
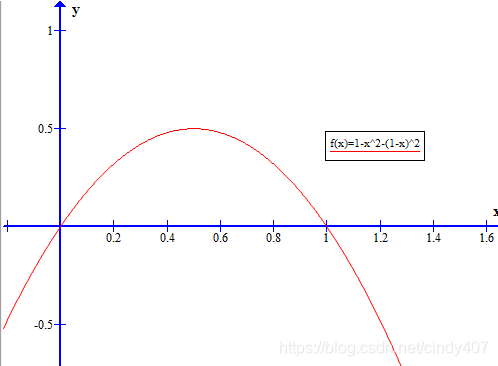
当按特征A分裂时,基尼系数的计算如下:
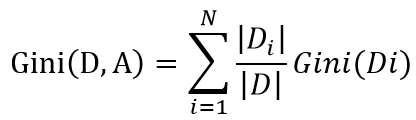
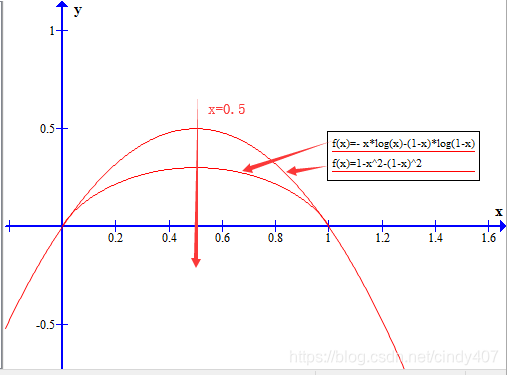
这是二分类时的基尼系数图像,与信息熵形状非常接近,从数据角度看,将信息熵在Pk=1处进行泰勒一阶展开,可以得到log2Pk≈1-Pk
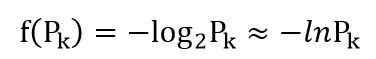
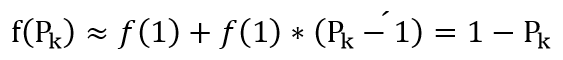
本人互联网数据分析师,目前已出Excel,SQL,Pandas,Matplotlib,Seaborn,机器学习,统计学,个性推荐,关联算法,工作总结系列。
微信搜索 " 数据小斑马" 公众号,回复“数据分析"就可以免费领取数据分析升级打怪 15本必备教材喔


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










