



面对超大规模的模型,Prompt-Tuning的方法远远优于Fine-Tuning,这是因为模型的规模足够大,训练中使用足够的语料,同时设计的预训练任务足够有效。
(1)常用的方法:
1、上下文学习In-Context Learning:
直接挑选少量的样本,作为该任务的提示
2、指令学习Insturction-Tuning:
构建任务指令集,促使模型根据任务指令做出反馈

指令学习和提示学习不同点:
Prompt是为了提升模型的补全能力,比如给出上文补下文,而指令学习激发模型的理解能力,通过给出更明显的指令,让模型理解并作出action,Prompt-Tuning在没有精调的模型也能有一定的效果而Instrution-Tuning则必须对模型精调让他知道这种指令模式
3、思维链Chain-of-Thought:
给予或激发模型具有推理和解释的信息,通过线性链式的模式指导模型生成合理的结果。
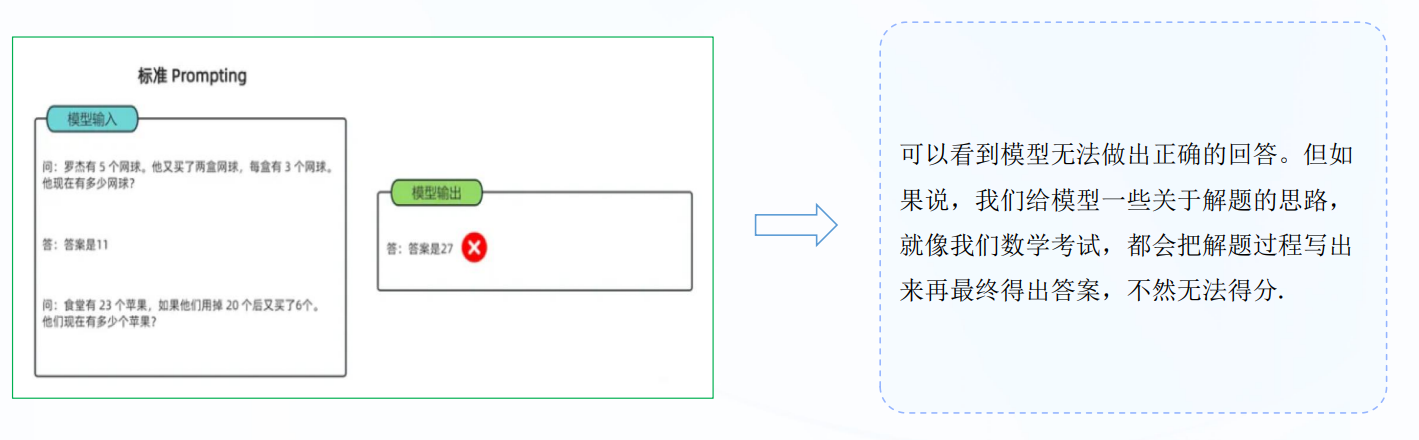
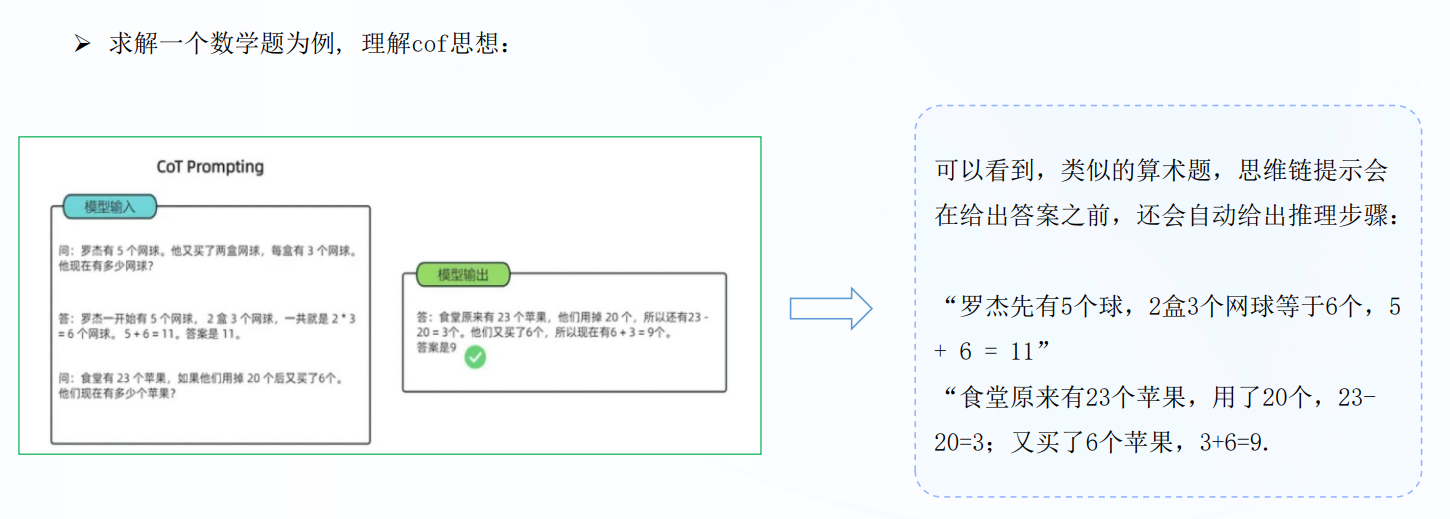
zero-shotCOT:
直接生成推理步骤,然后使用生成的CoT来导出答案.(其中LLM 首先由“Let'sthink step by step”提示生成推理步骤,然后由 “Therefore, the answer is” 提示得出最终答案。他们发现,当模型规模超过一定规模时,这种策略会大大提高性能,但对小规模模型无效,显示出显著的涌现能力模式)
Few-shotCOT:
ICL 的一种特殊情况,它通过融合 CoT 推理步骤,将每个演示〈input, output〉扩充为〈input,CoT, output〉
特点:逻辑性,可行性,全面性,可验证性
(2)PEFT:
PEFT(Parameter-Efficient Fine-Tuning)参数高效微调方法是目前大模型在工业界应用的主流方式之一,PEFT 方法仅微调少量或额外的模型参数,固定大部分预训练参数,大大降低了计算和存储成本,同时最先进的 PEFT 技术也能实现了与全量微调相当的性能.
优势:
该方法可以使PLM高效适应各种下游应用任务,而无需微调预训练模型的所有参数,且让大模型在消费级硬件上进行全量微调变得可行
分类:
1、Prefix/Prompt-Tuning
在模型的输入或隐层添加K个额外可训练的前缀伪token,只训练这些前缀参数。
形式:
Prefix-Tuning 在输入前添加前缀,即z=[Prefix,x,y] ,Pidx为前缀序列的索引,|Pidx|为前缀的长度。前缀索引对应着由θ参数化的向量矩阵Pθ,维度为|Pidx|×dim(hi).
注意:由于直接更新Prefix的参数导致训练不稳定,作者在Prefix层加了MLP结构,相当于将Prefix分解为更小维度的input和MLP,训练完成后,只保留Prefix的参数
对比P-Tuning:
Prefix-Tuning 是将额外的 embedding加在开头,看起来更像 模仿Instruction指令,而PTuning 位置不固定. • Prefix-Tuning 通过在每个层都添 加可训练参数,通过MLP初始化, 而P-Tuning只在输入的时候加入 embedding, 并通过LSTM+MLP初始化.
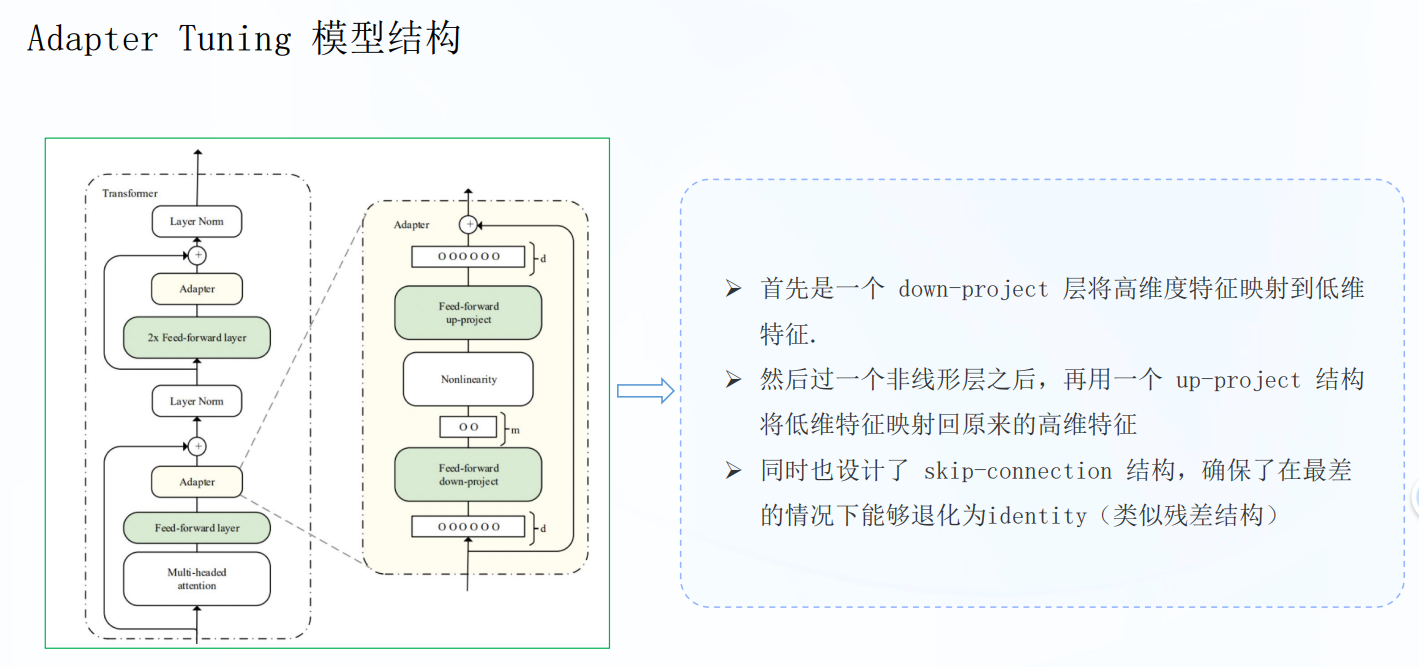
2、Adapter-Tuning
将较小的神经网络层或模块插入预训练模型的每一层,这些新插入的神经模块成为adapter,下游任务微调时也只训练这些适配器的参数
不同于Prefix Tuning这类在输入前添加可训练 prompt参数,以少量参数适配下游任务,AdapterTuning则是在预训练模型内部的网络层之间添加新的网络层或模块来适配下游任务. 当模型训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构进行微调.
3、LoRA:
通过学习小参数的低秩矩阵来近似模型权重矩阵W的参数更新,训练时只优化低秩矩阵参数
低秩适应(Low-Rank Adaptation)是一种参数高效的微调技术,其核心思想是对大型模型的权重矩阵进行隐式的低秩转换,也就是:通过一个较低维度的表示来近似表示一个高维矩阵或数据集.
上述Adapter Tuning 方法在 PLM 基础上添加适配器层会引入额外的计算,带来推理延迟问题;而Prefix Tuning 方法难以优化,其性能随可训练参数规模非单调变化,更根本的是,为前缀保留部分序列长度必然会减少用于处理下游任务的序列长度. 因此微软推出了LoRA方法.
原理:
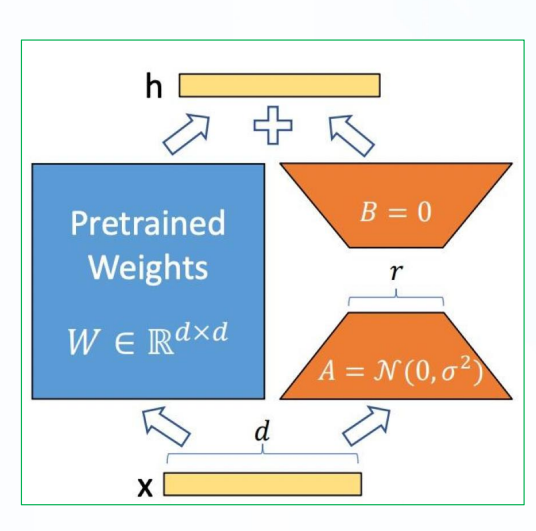
LoRA技术冻结了预训练模型的权重,并在每个Transformer块中注入可训练层(秩分解矩阵),即在模型的Linear层的旁边加一个旁支A和B。其中,A将数据从d维降到r维,这个r是LoRA的秩,是一个重要的参数;B将数据从r维升到d维,B部分的参数初始化为0.模型训练结束后,需要将A+B部分的参数与原大模型的参数合并到一起。


















 1272
1272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










