



点击蓝字 关注我们

本文共计3023字 预计阅读时长10分钟

背景
在处理海量日志或新闻数据时,我们经常面临一个痛点:「数据是有了,但它们是非结构化的。」
比如一段文本:“Elastic 由 Shay Banon 在阿姆斯特丹创立。”
对于传统搜索系统来说,这只是一串字符。但对于业务分析来说,我们希望系统能自动识别出:
「Elastic」 是一个组织 (Organization)
「Shay Banon」 是一个人名 (Person)
「阿姆斯特丹」 是一个地点 (Location)
这就是 「命名实体识别 (NER)」 的核心价值。
在 Elasticsearch 8.0 之前,实现这一功能通常需要依赖外部的 Python 服务进行预处理,架构复杂且维护成本高。而现在,我们可以利用腾讯云 Elasticsearch Service(ES)原生的 NLP 能力,将模型直接部署在集群内部,实现数据写入即处理的闭环。
本文将演示如何将 Hugging Face 上的 BERT 模型部署到 Elasticsearch,并构建自动化的处理管道。

环境准备
「Elasticsearch 集群」:版本需为 9.1.3,机器学习节点选择 GPU 型;
ES集群配置-1

ES集群配置-2
「客户端环境」:配置为 8C32G,本地需安装 Docker(推荐)或 Python 环境,用于上传模型。
腾讯云 ES 在标准 Elasticsearch 基础上,提供了开箱即用的 GPU 机器学习节点——无需自行配置 CUDA 驱动与模型运行时环境,创建集群时勾选"ML 节点"即可获得推理算力。

第一步:导入预训练模型
Elasticsearch 本身不负责训练模型,而是作为一个高效的推理(Inference)引擎。我们需要将训练好的模型从 Hugging Face Hub 导入到集群中。
官方推荐使用 Elastic 的 Python 客户端工具 「Eland」 来完成此操作。为了避免本地 Python 环境依赖冲突(PyTorch 版本问题常让人头疼),「强烈建议使用 Docker 运行 Eland」。Eland 是 Elastic 官方开源的 Python 客户端库,专门用于与 ES 机器学习功能交互。
我们以 elastic/distilbert-base-uncased-finetuned-conll03-english 模型为例。在一台客户端执行以下命令:
# 请替换 <ES_URL>, <USERNAME>, <PASSWORD> 为你的实际配置docker run -it --rm elastic/eland \ eland_import_hub_model \ --url https://<ES_URL>:9200 \ -u <USERNAME> -p <PASSWORD> \ --hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english \ --task-type ner \ --start「参数含义:」
--hub-model-id: 指定 Hugging Face 上的模型 ID,也可以提前下载好放在执行目录的相对路径下,对应的 value 就需要改成相对路径的路径名
--task-type ner: 明确任务类型为命名实体识别。
--start: 模型上传后立即在集群中部署并启动

第二步:模型可用性验证
模型上传成功后,建议先在 Kibana 中进行一次冒烟测试,确保推理功能正常。
进入 Kibana,导航至 「Machine Learning > Trained Models」。
检查 elastic__distilbert-base-uncased-finetuned-conll03-english 的状态是否为 「Started」。
点击操作栏的 「Test model」。
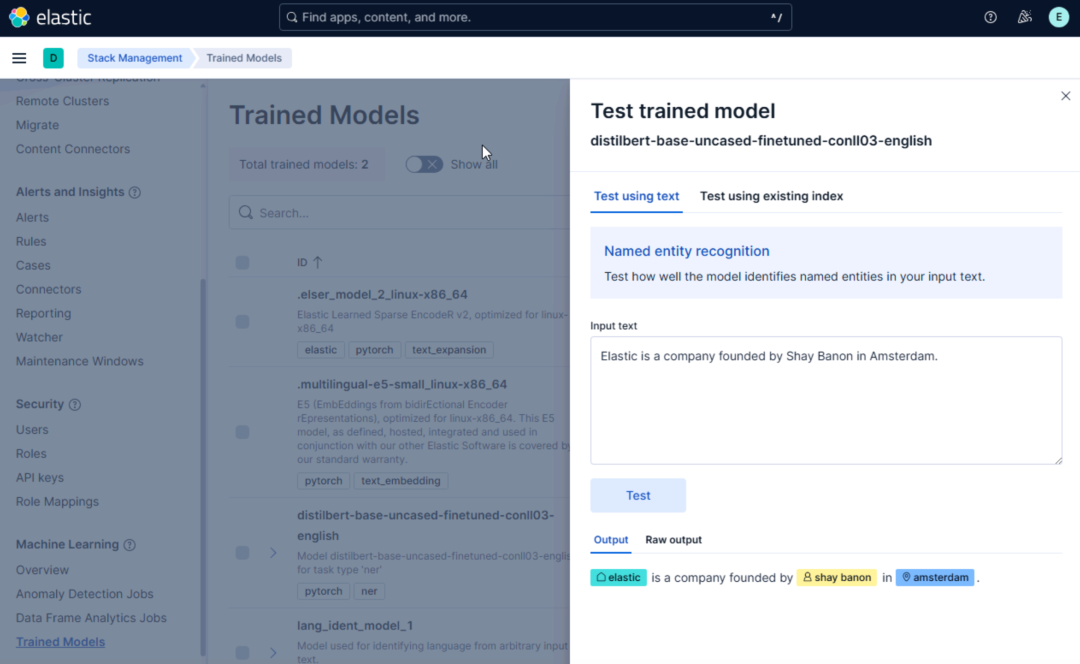
Kibana Trained Models在测试窗口输入一段英文文本,例如:
"Elastic is a company founded by Shay Banon in Amsterdam."
如果配置正确,你将看到如下结构化输出:
「Elastic」 -> ORG
「Shay Banon」 -> PER
「Amsterdam」 -> LOC
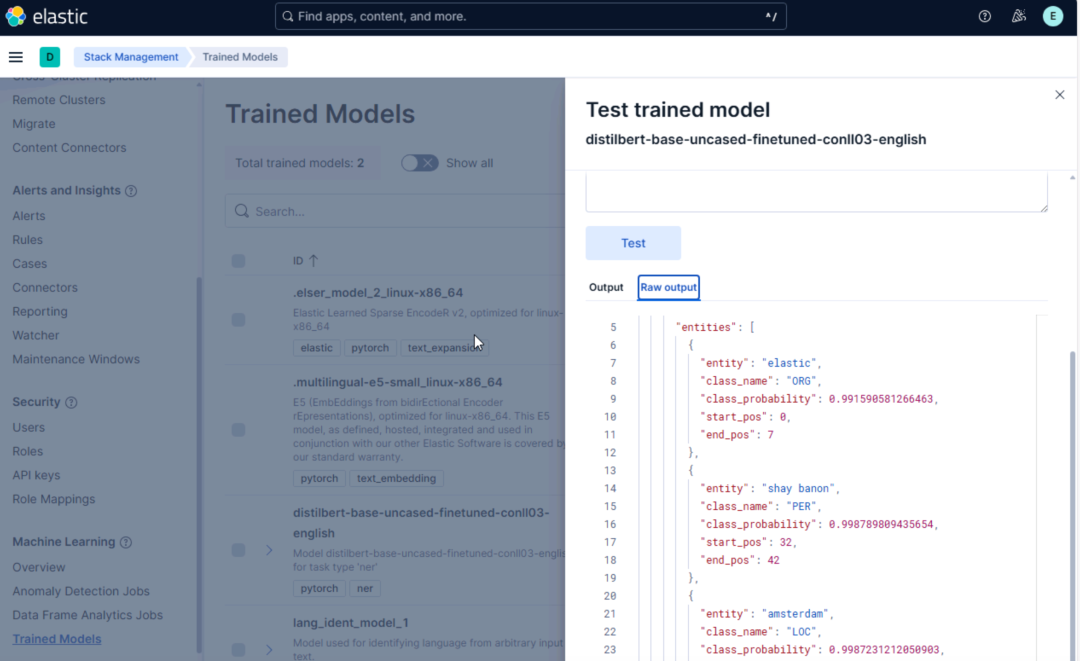
模型测试结果这证明模型已成功加载并可以接受推理请求。

第三步:构建 Ingest Pipeline
手动测试通过后,我们需要将这一能力集成到数据写入流程中。通过定义一个 「Ingest Pipeline」,我们可以让所有经过该管道的文档自动完成实体提取。
在 Kibana 的 「Dev Tools」 中执行以下 DSL:
PUT _ingest/pipeline/ner-pipeline{"description": "NER inference pipeline","processors": [ { "inference": { "model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english", "target_field": "ml.ner", "field_map": { "content": "text_field" } } } ]}「配置详解:」
「inference 处理器」:这是核心组件,用于调用机器学习模型。
「field_map」: 建立映射关系。告诉模型,文档中的 content 字段是需要被分析的文本(模型内部期望的输入名为 text_field)。
「target_field」: 推理结果(即提取出的实体列表)将被写入到文档的 ml.ner 字段中。

第四步:实战测试
现在,我们创建一个索引并写入一条文档,指定使用刚才创建的管道。
POST my-ner-index/_doc?pipeline=ner-pipeline{ "content": "Hello, my name is Josh and I live in Berlin."}写入完成后,检索该文档以查看最终存储的数据结构:
GET my-ner-index/_search「返回结果分析:」
{ "_source": { "content": "Hello, my name is Josh and I live in Berlin.", "ml": { "ner": { "predicted_value": "Hello, my name is Josh and I live in Berlin.", "entities": [ { "entity": "Josh", "class_name": "PER", "class_probability": 0.995, "start_pos": 18, "end_pos": 22 }, { "entity": "Berlin", "class_name": "LOC", "class_probability": 0.999, "start_pos": 37, "end_pos": 43 } ] } } }}可以看到,原始文档被自动丰富了。ml.ner.entities 数组中清晰地标记了 "Josh" 为人名,"Berlin" 为地点,且附带了置信度和字符位置。

总结与应用场景
通过上述步骤,我们摒弃了复杂的外部中间件,使用腾讯云 Elasticsearch 原生功能就实现了 NLP 落地。这种架构不仅降低了运维复杂度,还显著提升了数据处理的实时性。
「结构化后的数据能带来什么?」
「精准的分面搜索」:用户可以点击"地点"过滤器,筛选出所有发生在"Berlin"的新闻,而非简单的关键词匹配。
「趋势分析」:结合 Aggregations(聚合),可以统计出近期提及频率最高的"人物"或"公司"。
「知识图谱基础」:实体提取是构建实体关系网络的第一步。
如果你正在处理大量的文本数据,不妨尝试将 NLP 模型引入你的 ES 集群,挖掘非结构化数据背后的价值。
除 NER 外,腾讯云 ES 的 AI 推理服务还支持文本分类、文本嵌入(用于向量检索/RAG 场景)、Rerank 重排序等模型类型,并可与 Ingest Pipeline 结合实现写入即推理。结合混合检索能力(BM25 + 向量),可构建端到端的语义搜索与结构化提取一体化方案。
腾讯云 Elasticsearch Service 提供开箱即用的机器学习节点与 GPU 推理能力,支持从 NER、文本分类到向量检索的全链路 NLP 场景,助力企业从非结构化数据中快速提取业务价值。
延伸:「💡 关于中文及多语种 NER 支持」
本文以英文模型为例,但整套流程对语种没有限制。只需在 HuggingFaceHub上搜索对应语种的 NER 模型,替换 `--hub-model-id` 即可,其余步骤完全一致。
选型时注意三点:
优先选择 ES 原生支持的 Transformer 架构(BERT / DistilBERT / RoBERTa 等);
关注模型的标签体系是否匹配业务需求;
导入前先用真实文本在 Hugging Face 上做效果验证。
END
关注腾讯云大数据╳探索数据的无限可能
往期精彩



求点赞

求分享

求喜欢



















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










