



最近这几个月,相信大家都被大模型反复“轰炸”了,从4月的DeepSeek V4开始,然后是GLM 5.2 、Kimi 2.7、MiniMax M3,每一个大模型都会拿出跑分来证明,说自己非常厉害。
但是在实际的工作中,它们到底是“真神”还是“花架子”? 这个问题可能每个人都有自己的看法。
作为一名混迹后端多年的资深码农,我不太看重这些评分,更相信自己的手感。
所以,我打算掏点儿真金白银,把DeepSeek V4 Pro、Kimi 2.7、MiniMax M3拉到同一个竞技场(GLM 5.2缺席,实在抢不到它的Coding Plan),在长上下文、多模态理解、办公、Coding领域找一些真实场景,看看它们的表现到底怎么样。
01 真实代码修复
现在的大模型如果不配置1M上下文,感觉都不好意思和人打招呼了。
既然如此,那我就不客气了,找一个大型项目试一试。
Django,我很早之前用过的一个Python Web框架,大概有50万行Python代码,足够大了。
不但考验各个模型的长上下文窗口,更考验它的有效理解和推理能力。

我还特意找了一个真实的issue:
https://code.djangoproject.com/ticket/36940,
打算让这个三个模型修复一下,看看效果如何。
不过这个issue写得太细节了,直接展示了要改的class,不好不好,我重新写了一下,站在用户角度描述:
提示词
在Django部署了两个应用:
/myapp/ → 应用 A
/myapplication/ → 应用 B
最近有用户报告以下异常行为:
用户反馈 1: 当用户访问https://example.com/myapp/profile 行为正常,进入自己的 profile 页面。
用户反馈 2:当用户访问:https://example.com/myapplication/profile 返回了404
你帮我看看是怎么回事?
结果,可能是我这个描述写得有过于贴近用户了,导致难度过高,三个模型虽然都猜到了大概的问题,但是都把注意力放到了应用的urls.py文件,而不是修复框架的Bug。
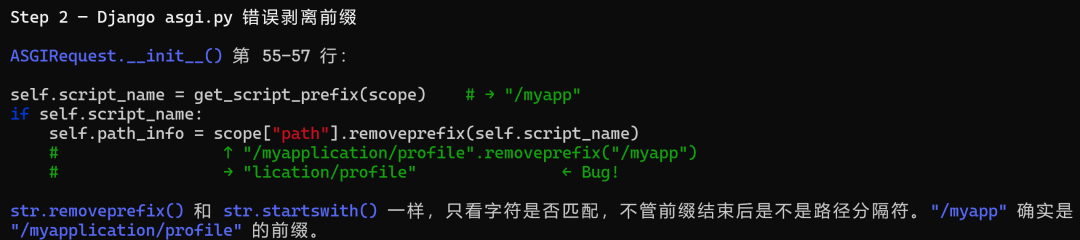
没办法,我只好更加明确一点,提示它们去框架的ASGI模块去看看。
这一下,差别就出来了。
MiniMax M3精准地定位了Bug: removeprefix是纯字符串前缀匹配,不尊重路径段边界。
这正是产生这个Bug的准确原因。
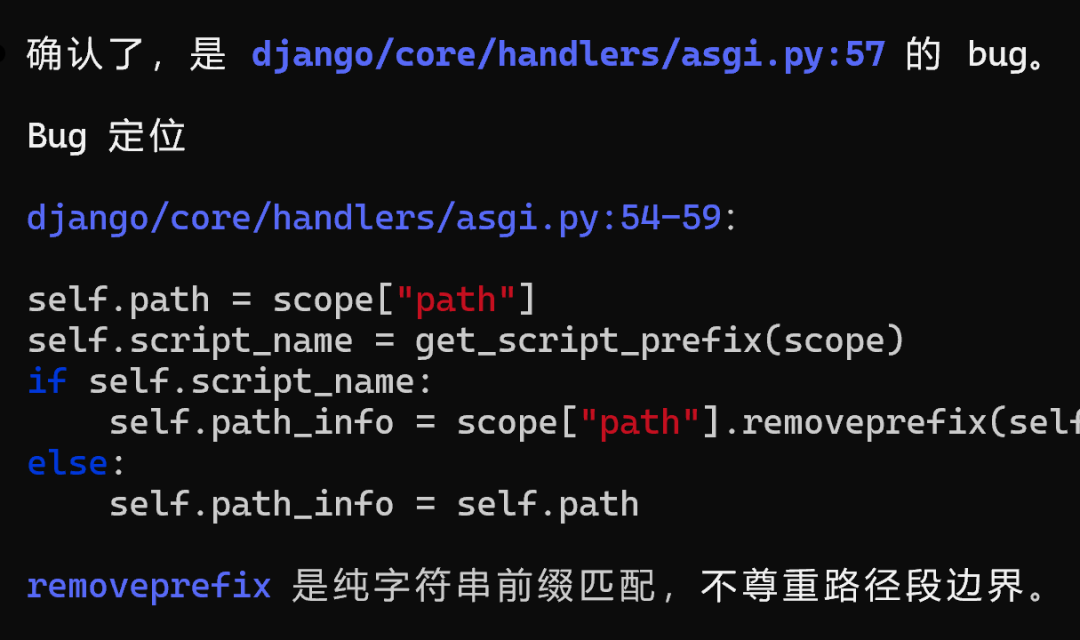
给出的修复建议也非常准确: 按“段边界”做strip.
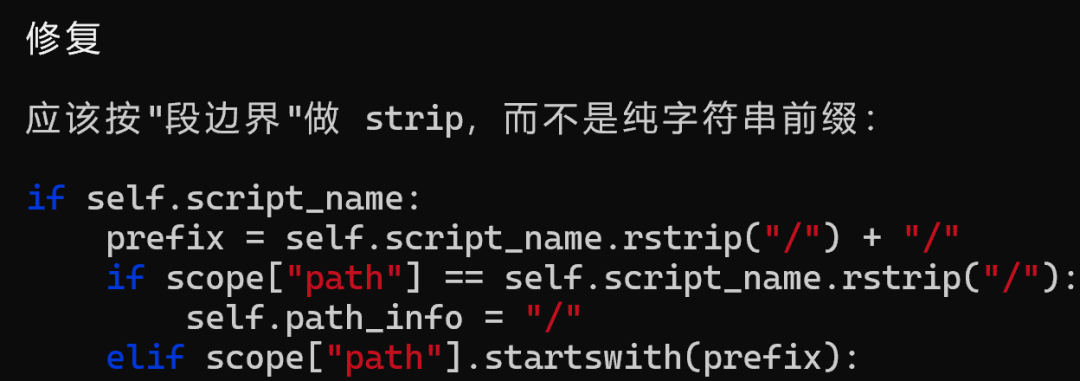
更让我意外的是,它还对比了WSGI ,说WSGI 服务器把 SCRIPT_NAME 和 PATH_INFO 分开传给 Django,Django 不做 strip,直接读 PATH_INFO,ASGI 这层自己动手strip,反而引入了 bug。
嗯,举一反三,观察全局,感觉像个老程序员的样子。
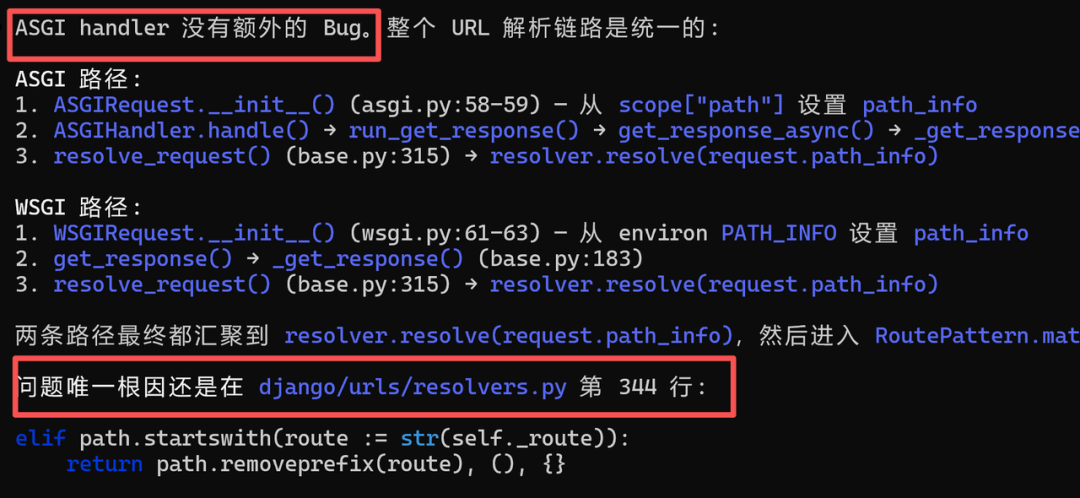
相比而言,Kimi 2.7 和 DeepSeek V4 Pro 还是没有定位到问题。
Kimi说真正出问题的地方在resolvers.py :
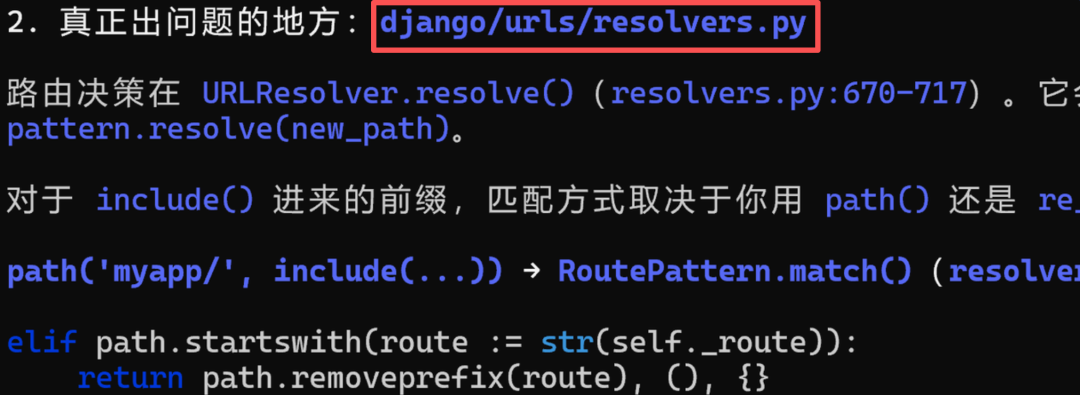
神奇的是,DeepSeek 也认为 ASGI Handler没问题,认为问题出在resolvers.py,两个家伙像商量好的一样。
不过,我再稍微提示一下,Kimi 和 DeepSeek都能正确地解决问题了。
可以看出,三个大模型都准确地理解了问题,并且推导出是url解析匹配的问题。
但是真正定位的时候,MiniMax M3表现要好一些,找到了准确的地方,Kimi 和 DeepSeek差不太多,还需要进一步辅助。
不过我必须得说一下,对于这种巨型复杂项目中一个细碎的Bug,定位和修复起来是非常有挑战的,关键的问题就是一定得提供足够的上下文信息,否则即使是一个非常有经验的程序员,他也不一定能快速搞定,更不用说初次面对这个源码的大模型了。
M3 的 1M 上下文确实很长,但在使用上也有些注意事项,它主要用于项目级代码理解和重构,长文档全文处理,不适合短问答/单轮对话,以及无上下文依赖的轻量创作。
在Agent中使用的时候默认还是512K 上下文,需要 1M 的还要手动切换,Prompt结构最好是固定内容前置(系统提示、参考文档、代码库),变化内容后置(当前查询),这样可以提升cache命中率。
更详细的用法可以参考一下MiniMax官方在小红书上分享的使用指南:

02 城市躲避游戏
测完了大型项目的代码修复,接下来我想试试这几个国产模型的综合编程能力。
我不想用电商网站、博客等CRUD的系统,太简单了,我打算用3D游戏来考验一下它们,毕竟3D游戏涉及到多个技术领域的协同:
3D 图形(Three.js),数学(向量、矩阵、碰撞检测),物理模拟,相机控制,动画系统, 输入系统(键盘、鼠标), 游戏状态管理, UI 与 HUD....
这种测试更接近真实的软件工程,也更能拉开模型之间的差距。
提示词
请生成一个完整的 HTML 文件,实现一个可以直接运行的 3D 城市躲避游戏。
要求所有代码写在一个 HTML 中,仅允许使用 Three.js,不得依赖任何外部模型、贴图、音频或其他资源,所有场景和物体都需要程序生成。
游戏玩法 :玩家扮演一名城市中的行人,需要不断向前奔跑,在繁忙的街道中躲避车辆,同时尽可能收集金币获得更高分数。
游戏目标是在保证生存的情况下获得最高分。
玩家控制: WASD 控制移动, Space 跳跃,Shift 加速奔跑, 鼠标拖动旋转视角
摄像机采用第三人称跟随模式,能够平滑跟随玩家
城市场景: 自动生成一个具有现代城市风格的场景,包括:
道路 十字路口 人行道 建筑物(高度随机,要带窗户纹理)树木 路灯 红绿灯 草地区域
整个城市不需要无限大,但要有一定规模,避免场景过于单调。
所有建筑均使用程序生成。
车辆系统: 自动生成不同颜色和尺寸的车辆。车辆需要:沿道路正常行驶 在路口能够转弯或直行
保持合理车速,不要互相穿模,数量会随着游戏时间逐渐增加
车辆应持续刷新,而不是一次生成后保持静止。
收集系统 : 地图随机生成金币。玩家接触金币后:
金币消失 播放简单动画 分数增加 随机位置重新生成新的金币
碰撞规则 : 玩家撞到汽车:扣除生命值 玩家短暂后退 有短暂无敌时间 生命值归零:游戏结束
显示最终得分 支持重新开始
难度系统: 游戏运行过程中, 每隔 30 秒 汽车数量增加 汽车速度略微提升 金币刷新速度提高
难度应平滑增长。
HUD : 屏幕左上角实时显示:当前分数 剩余生命 游戏时间 当前难度等级
游戏结束时显示:Game Over 最终得分 存活时间 Restart 按钮
光照 : 至少包含:环境光 平行光(太阳)阴影 画面具有一定层次感。
动画效果 : 包括但不限于:玩家跑步动画(可简单摆臂)金币旋转 汽车持续运动 摄像机平滑跟随
玩家受击动画
代码要求
代码结构清晰,建议划分为: 场景初始化 玩家控制 城市生成 车辆系统 金币系统 碰撞检测
UI 游戏循环
所有逻辑放在一个 HTML 文件中,可直接保存后打开运行。
这次测试的结果比较有意思,首先三个模型都是一次开发完成,立刻可以运行,角色移动,Shift加速,Space跳跃,鼠标拖动旋转视角,收集金币,躲避车辆全都一次实现,可见国产的模型现在发展得都相当不错了。
从实现速度上来看, DeepSeek v4 Pro > Kimi 2.7 > MiniMax M3。
但我也注意到,MiniMax M3慢的主要原因是它写完代码后,主动进行了测试,这也让它在逻辑实现上基本没有问题,而另外两家多少有点儿小Bug。
从效果上来看,DeepSeek构建了一个密集街区的“水泥森林”,树和路灯太多了,操作起来略微费劲,道路、长椅、垃圾箱、金币实现得都不错,角色和车辆碰撞时实现了抖动、变色的特效。
(注意:由于我要求不依赖任何外部模型和贴图,所以人物、车辆、树基本上都是几何体的堆叠,这不是测试的重点,不用在意。)
DeepSeek
有个唯一的小Bug:开场时,由于玩家操作的人物出现的位置是随机的,有时候会被困某个障碍物中,动弹不得,不过这是个小问题。
MiniMax M3 生成的地图区域很大,显得比较空旷,光影效果也可以,有意思的是它还给角色戴了一个小红帽。
像DeepSeek一样,基本功能也都实现了,我还注意到还实现了双向两车道效果,DeepSeek有时候会出现两车互相穿过,MiniMax这边不存在这种情况。
MinMax
Kimi设计的街区也很空旷,也实现了基本功能,就是角色形象丑一点儿,道路也没有体现出那种柏油马路的效果,垃圾桶、长椅、路灯也不太好看,但是建筑设计得错落有致的,在玩儿起来的时候感觉更加丝滑。
Kimi
Kimi在开始的时候有个比较严重的Bug,就是“上下键”的效果弄反了,稍一提示就改了过来:

总的来说,我觉得DeepSeek V4 Pro呈现的效果最好,MiniMax M3 在逻辑上实现得最完善。
03 PDF 问答
前面两个都是让大模型看代码,写代码,在办公领域,它们的表现怎么样呢?
我找了一个英伟达的2025年报PDF,这个文件很大,48M,181页。

我想把它发给三个大模型,看看它们能不能像一个人一样“读文件做工作”,能不能在几十页甚至上百页的文档里准确找到需要的数据,看懂表格里的数字关系,把分散在不同页面的信息拼起来,再做一步甚至多步计算,最后给出一个靠谱的答案,而不是凭感觉乱猜。
问题1:Data Center 收入与 Gaming 收入相比,在 FY2025 是多少倍?
这个问题比较简单,就是从表格中提取数据。
MiniMax M3 找到了正确的表格,数据最为精确:
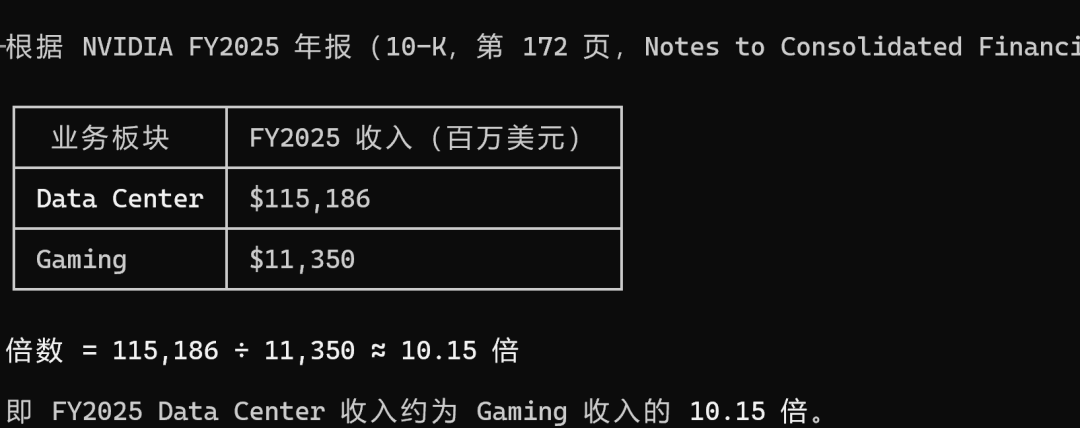
DeepSeek 和 Kimi 又像商量好似的,不约而同地找到了另外一个表格中的粗略的值,真是有意思:

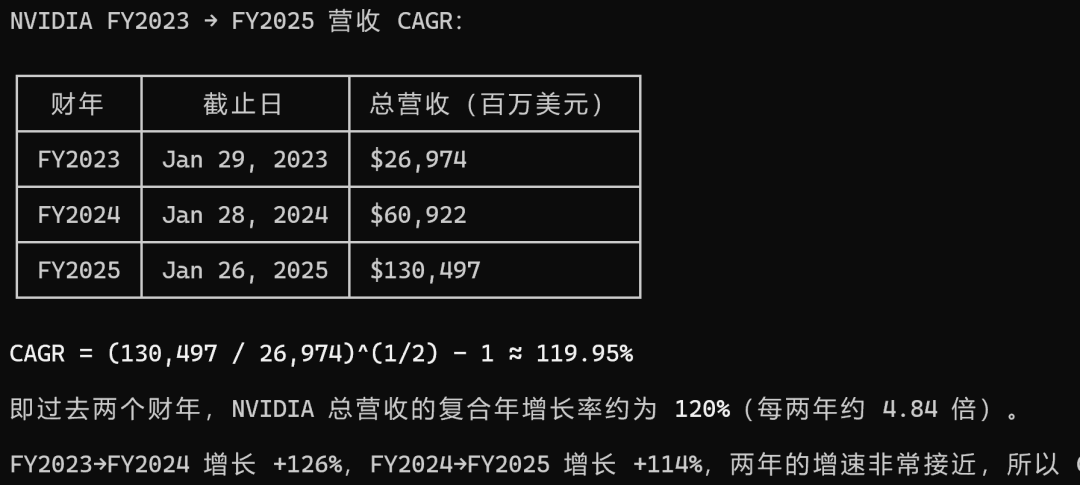
问题2 : 计算 NVIDIA 从 FY2023 到 FY2025 的营收复合年增长率(CAGR)。
这个问题不但涉及到数据提取,还要进行多步计算,三个模型的回答都非常漂亮,完全一致,这里贴一个MiniMax M3的截图:
问题3:在 FY2025 中,是 Data Center 对营收增长的贡献更大,还是其他所有业务合计贡献更大?请给出计算过程。
这个问题就更难了,有点儿像分析师的工作了,这次三个模型都正确地计算了英伟达总营收的增长,Data Center的增长,其他业务的增长,并且计算得出了结论:DataCenter的贡献更大。
但是很明显,MiniMax M3给出的结果最详细,最清晰,最精确:
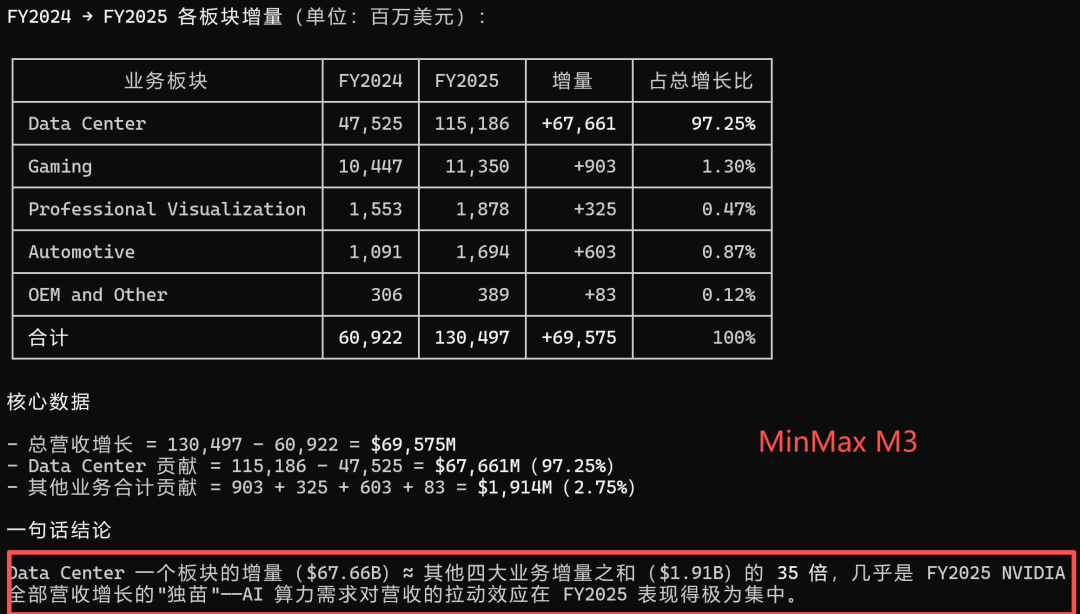

总之,给我的感觉是三个大模型在对PDF问答时表现都相当好,MiniMax M3相对更加精准一些。
04 金融场景
我在测试MiniMax的时候,偶然间发现MiniMax Agent 网页端上线了金融场景相关的模块。
https://agent.minimaxi.com/
通过它可以链接金融数据库,目前覆盖A/H/美股、基金、期货、固收和宏观数据的问答场景。
比如,可以问它一个问题:中证红利低波动指数最近半年怎么样?

这对于投资/炒股的同学来说是个相当不错的工具,有空大家可以去试一下。
05 写在最后
我发现做这种评测还是挺费劲的,先构思场景,然后每种场景都得让几个大模型都跑一遍,仔细观察和分析,看看它们的输出结果,很耗费时间(我甚至有点儿庆幸,没有抢到GLM-5.2,要不然就更费劲了)。
不过,观察各个大模型在同一场景进行竞赛,也是挺有意思的一件事情,从我有限的测试看:
三个大模型PDF问答方面都非常棒,都能理解问题,进行准确推理和计算,可以成为办公的好帮手了。
MiniMax M3 在大型代码库修复Bug,长上下文方面超出我的预料,非常精准。
在复杂的3D游戏领域,DeepSeek V4 Pro干活儿很快,代码也写得很好,很老道,MiniMax M3 在逻辑方面考虑得很完善,Kimi 2.7 则中规中矩。
总之,我觉得完全可以放心地把这些国产开源大模型接入到工作流当中了,但是程序员还得尽可能地去提供更多上下文,指导AI工作。
下一次测试我会争取更多的场景,更多的模型(尤其是海外的模型),也希望国产开源模型有更优异的表现。


















 4463
4463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










