




CASE表达式
1、概述
CASE表达式是从SQL-92标准开始被引入的。它虽然已经被引入了二十多年,但在主流DBMS中仍然可以正常使用。不过,可能因为它是相对较新的技术,所以尽管使用起来非常便利,但人们(尤其是初级者)并不怎么理解其真正的价值。很多人不用它,或者用它的简略版函数,例如DECODE(Oracle)、IF(MySQL)等。然而,正如著名的SQL专家乔·塞尔科所说,CASE表达式也许是SQL-92标准里加入的最有用的特性。如果能用好它,那么SQL能解决的问题就会更广泛,写法也会更加漂亮。而且,CASE表达式是不依赖于具体数据库的技术,具有提高SQL代码的可移植性等优点。
2、语法
CASE表达式有简单CASE表达式(simple case expression)和搜索CASE表达式(searched case expression)两种写法,它们分别如下所示。
--简单 CASE 表达式
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
--搜索 CASE 表达式
CASE WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END
这两种写法的执行结果是相同的,sex列(字段)如果是’1’,那么结果为男;如果是 ‘2’,那么结果为女。
简单CASE表达式正如其名,写法简单,但能实现的事情比较有限。简单CASE表达式能写的条件,搜索CASE表达式也能写。
需要注意,在发现结果为真的WHEN子句时,CASE表达式的真假值判断就会中止,而剩余的WHEN子句会被忽略(不再判断)。为了避免引起不必要的混乱,使用WHEN子句时要注意条件的排他性。
-- 例如,这样写的话,结果里不会出现“第二”
CASE WHEN col_1 IN ('a', 'b')THEN '第一'
WHEN col_1 IN ('a') THEN '第二'
ELSE '其他' END
此外,使用CASE表达式的时候,还需要注意以下几点:
- 统一各分支返回的数据类型:一定要注意CASE表达式里各个分支返回的数据类型是否一致。某个分支返回字符型,而其他分支返回数值型的写法是不正确的。这是因为,CASE表达式是最终要得出单一值的表达式。
- 不要忘了写END:END是必不可少的,如果忘记写,就会发生语法错误。
- 养成写ELSE子句的习惯:与END不同,ELSE子句是可选的,不写也不会出错。不写ELSE子句时,CASE表达式的执行结果是NULL,但是不写可能会造成“语法没有错误,结果却不对”这种不易追查原因的麻烦,所以最好明确地写上ELSE子句(即便是在结果可以为NULL的情况下)。养成这样的习惯后,我们从代码上就可以清楚地看到这种条件下会生成NULL,而且将来代码有修改时也能减少失误。
在单独使用CASE表达式的情况下,它只是一个将某列的值换为其他值的工具。这样的话,它与IF或DECODE等依赖于具体实现的函数没有什么区别。当与其他的SQL工具搭配使用时,CASE表达式才能发挥出真正的价值,特别是与聚合函数(SUM或AVG)和GROUP BY子句一起使用时,甚至会发挥出巨大的威力。
3、将已有编号方式转换为新的方式并统计
在进行非定制化统计时,我们经常会遇到将已有编号方式转换为另外一种便于分析的方式并进行统计的需求。
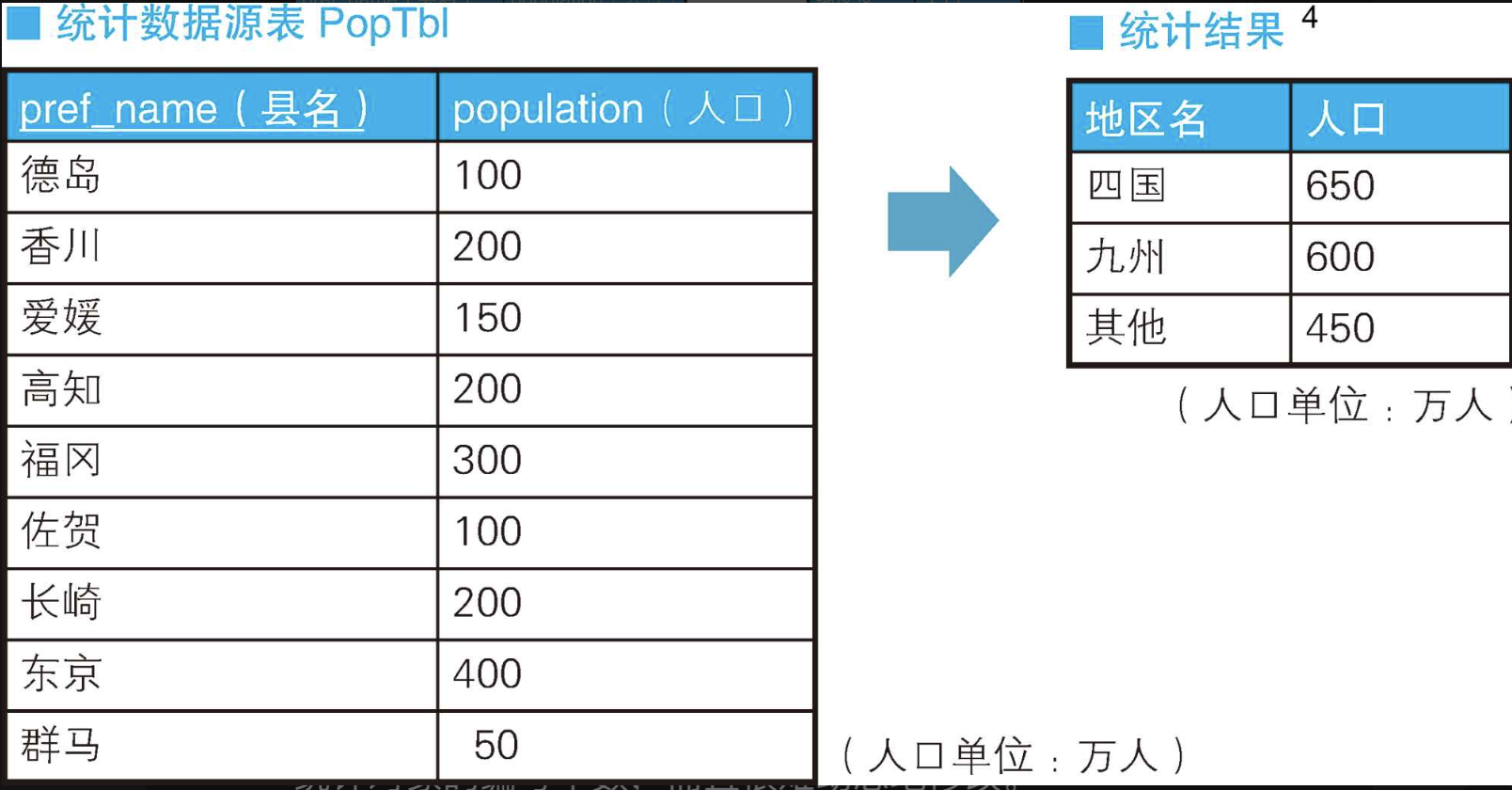
例如,现在有一张以北海道、青森等县(日本的县级市)为单位记录人口的表,我们需要以东北、关东、九州等地区为单位来分组,并统计人口数量。
具体来说,就是统计下页表PopTbl中的内容,得出如右表“统计结果”所示的结果。从表的设计上来说,这种表其实最好使用“县的编号”作为键,但这里为了方便理解,我们使用“县的名称”作为键。
CREATE TABLE PopTbl (
pref_name VARCHAR(32) PRIMARY KEY,
population INTEGER NOT NULL
);
INSERT INTO PopTbl VALUES('德岛', 100);
INSERT INTO PopTbl VALUES('香川', 200);
INSERT INTO PopTbl VALUES('爱媛', 150);
INSERT INTO PopTbl VALUES('高知', 200);
INSERT INTO PopTbl VALUES('福冈', 300);
INSERT INTO PopTbl VALUES('佐贺', 100);
INSERT INTO PopTbl VALUES('长崎', 200);
INSERT INTO PopTbl VALUES('东京', 400);
INSERT INTO PopTbl VALUES('群马', 50);
在“统计结果”这张表中,“四国”对应的是表PopTbl中的“德岛、香川、爱媛、高知”,“九州”对应的是表PopTbl中的“福冈、佐贺、长崎”。
-- 把县名转换成地区名
select
case pref_name
when '德岛' then '四国'
when '香川' then '四国'
when '爱媛' then '四国'
when '高知' then '四国'
when '福冈' then '九州'
when '佐贺' then '九州'
when '长崎' then '九州'
else '其他' end as '地区名' ,
sum(population) as '人口'
from PopTbl
group by 1
order by 2 desc;
+--------+------+
| 地区名 | 人口 |
+--------+------+
| 四国 | 650 |
| 九州 | 600 |
| 其他 | 450 |
+--------+------+
同样地,也可以将数值按照适当的级别进行分类统计。例如,要按人口数量等级(pop_class)查询都道府县个数的时候,就可以像下面这样写SQL语句。
-- 按人口数量等级划分都道府县
SELECT CASE WHEN population < 100 THEN '01'
WHEN population >= 100 AND population < 200 THEN '02'
WHEN population >= 200 AND population < 300 THEN '03'
WHEN population >= 300 THEN '04'
ELSE NULL END AS pop_class,
COUNT(*)AS cnt
FROM PopTbl
GROUP BY CASE WHEN population < 100 THEN '01'
WHEN population >= 100 AND population < 200 THEN '02'
WHEN population >= 200 AND population < 300 THEN '03'
WHEN population >= 300 THEN '04'
ELSE NULL END;
4、用一条SQL语句进行多条件统计
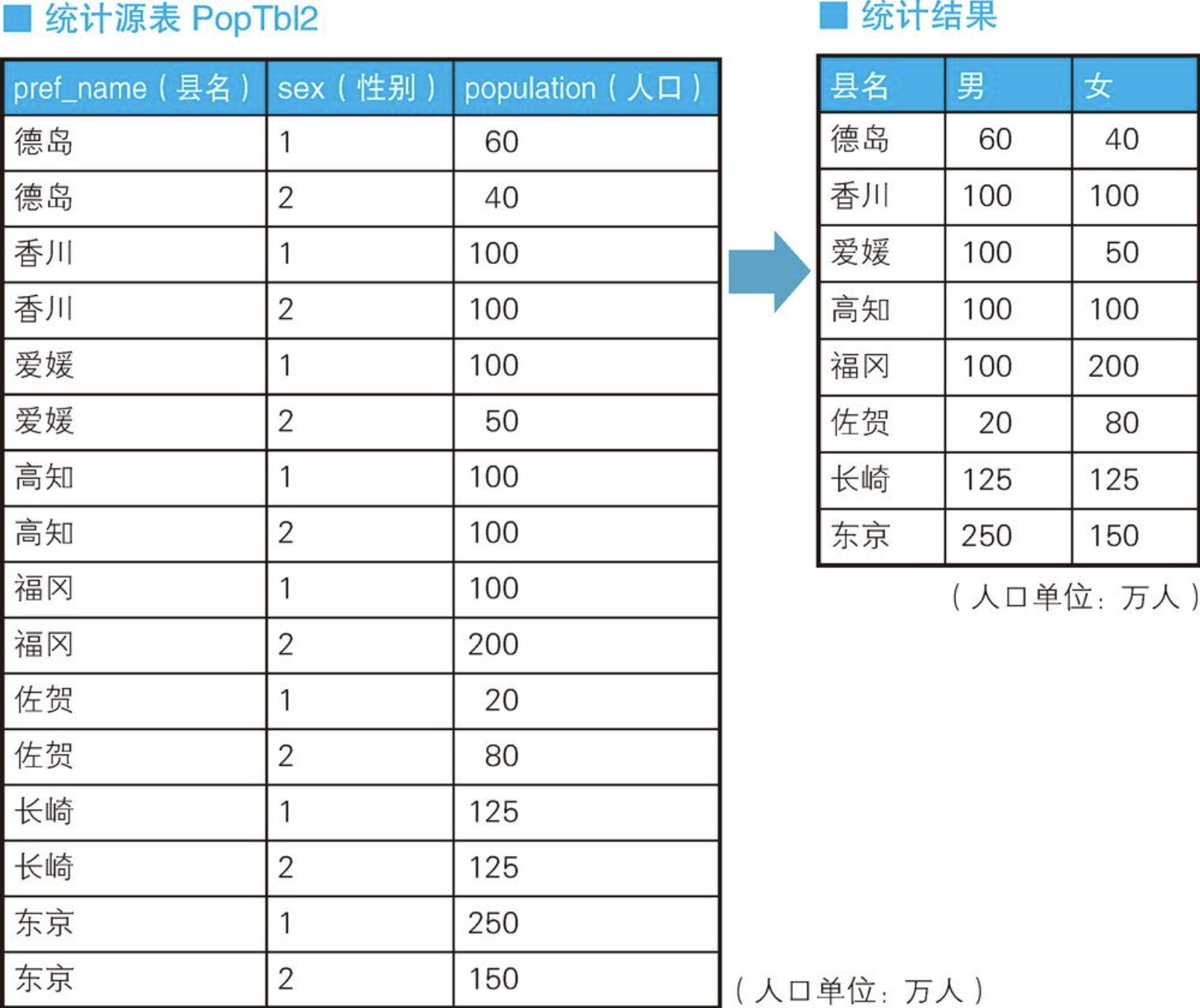
多条件统计是CASE表达式的著名用法之一。例如,我们需要往存储各县人口数量的表PopTbl里添加上“性别”列,然后求按性别、县名汇总的人数。具体来说,就是统计表PopTbl2中的数据,然后求出如表“统计结果”所示的结果。其中,1表示男性,2表示女性。
CREATE TABLE PopTbl2 (
pref_name VARCHAR(32),
sex CHAR(1) NOT NULL,
population INTEGER NOT NULL,
PRIMARY KEY(pref_name, sex)
);
INSERT INTO PopTbl2 VALUES('德岛', '1', 60 );
INSERT INTO PopTbl2 VALUES('德岛', '2', 40 );
INSERT INTO PopTbl2 VALUES('香川', '1', 100);
INSERT INTO PopTbl2 VALUES('香川', '2', 100);
INSERT INTO PopTbl2 VALUES('爱媛', '1', 100);
INSERT INTO PopTbl2 VALUES('爱媛', '2', 50 );
INSERT INTO PopTbl2 VALUES('高知', '1', 100);
INSERT INTO PopTbl2 VALUES('高知', '2', 100);
INSERT INTO PopTbl2 VALUES('福冈', '1', 100);
INSERT INTO PopTbl2 VALUES('福冈', '2', 200);
INSERT INTO PopTbl2 VALUES('佐贺', '1', 20 );
INSERT INTO PopTbl2 VALUES('佐贺', '2', 80 );
INSERT INTO PopTbl2 VALUES('长崎', '1', 125);
INSERT INTO PopTbl2 VALUES('长崎', '2', 125);
INSERT INTO PopTbl2 VALUES('东京', '1', 250);
INSERT INTO PopTbl2 VALUES('东京', '2', 150);
通常的做法是像下面这样,分别在WHERE子句里写上不同的条件,然后执行两条SQL语句。
-- 男性人口
SELECT pref_name,
population
FROM PopTbl2
WHERE sex = '1';
-- 女性人口
SELECT pref_name,
population
FROM PopTbl2
WHERE sex = '2';
接着,还需要通过宿主语言或者应用程序将查询结果按列展开。如果使用UNION,只用一条SQL语句就可以实现查询,但使用这种做法时,工作量是一样的,性能并没有得到优化,SQL语句也会变得很长。如果使用CASE表达式,一条简单的SQL语句就可以搞定。
select pref_name as '县名',
sum(case when sex = '1' then population else 0 end) as '男',
sum(case when sex = '2' then population else 0 end) as '女'
from PopTbl2
group by pref_name;
+------+-----+-----+
| 县名 | 男 | 女 |
+------+-----+-----+
| 东京 | 250 | 150 |
| 佐贺 | 20 | 80 |
| 德岛 | 60 | 40 |
| 爱媛 | 100 | 50 |
| 福冈 | 100 | 200 |
| 长崎 | 125 | 125 |
| 香川 | 100 | 100 |
| 高知 | 100 | 100 |
+------+-----+-----+
这个技巧可贵的地方在于,它能将SQL的查询结果转换为二维表的格式。如果只是简单地用GROUP BY进行聚合,那么查询后必须通过宿主语言或者Excel等应用程序将结果的格式转换一下,才能使之成为交叉表。看上面的执行结果会发现,此时输出的已经是侧栏为县名、表头为性别的交叉表了。在制作统计表时,这个功能非常方便。如果用一句话来形容这个技巧,可以这样说:新手用WHERE子句进行条件分支,高手用SELECT子句进行条件分支。
5、用CHECK约束定义多个列的条件关系
假设某公司规定“女性员工的工资必须在20万日元以下”,而在这个公司的人事表中,这条无理的规定是使用CHECK约束来描述的,代码如下所示。
CONSTRAINT check_salary CHECK
(
CASE WHEN sex = '2'
THEN CASE WHEN salary <= 200000
THEN 1 ELSE 0 END
ELSE 1 END = 1
)
在这段代码里,CASE表达式被嵌入CHECK约束里,描述了“如果是女性员工,则工资是20万日元以下”这个命题(判断事情的语句)。在命题逻辑中,该命题是名为蕴含式(conditional)的逻辑表达式,记作P → Q。这里的P和Q表示任意命题,整体读作“P蕴含Q”。
这里需要重点理解的是蕴含式和逻辑与(logical product)的区别。逻辑与也是一个逻辑表达式,意思是“P且Q”,记作P ∧ Q。用逻辑与改写的CHECK约束如下所示。
CONSTRAINT check_salary CHECK
(
sex = '2' AND salary <= 200000
)
当然,这两个约束的程序行为不一样。究竟哪里不一样呢?如果在CHECK约束里使用逻辑与,该公司将不能雇佣男性员工。而如果使用蕴含式,男性也可以在这里工作。
要想让逻辑与P ∧ Q为真,需要命题P和命题Q均为真,或者一个为真且另一个无法判定真假。也就是说,能在这家公司工作的是“性别为女且工资在20万日元以下”的员工,以及性别或者工资无法确定的员工(如果一个条件为假,那么即使另一个条件无法确定真假,也不能在这里工作)。
而要想让蕴含式P → Q为真,需要命题P和命题Q均为真,或者P为假,或者P无法判定真假。也就是说如果不满足“是女性”这个前提条件,则无须考虑工资约束。
/* 用CHECK约束定义多个列的条件关系 */
CREATE TABLE TestSal
(
sex CHAR(1) ,
salary INTEGER,
CONSTRAINT check_salary CHECK
(
CASE WHEN sex = '2'
THEN CASE WHEN salary <= 200000
THEN 1 ELSE 0 END
ELSE 1 END = 1
)
);
INSERT INTO TestSal VALUES(1, 200000);
INSERT INTO TestSal VALUES(1, 300000);
INSERT INTO TestSal VALUES(1, NULL);
INSERT INTO TestSal VALUES(2, 200000);
INSERT INTO TestSal VALUES(2, 300000); -- error
INSERT INTO TestSal VALUES(2, NULL); -- error
INSERT INTO TestSal VALUES(1, 300000);
6、在UPDATE语句里进行条件分支
下面思考一下这样一种需求:以某数值型的列的当前值为判断对象,将其更新成别的值。这里的问题是,此时UPDATE操作的条件会有多个分支。例如,我们通过下面这样一张出自某公司人事部的员工工资信息表Salaries来看一下这种情况。
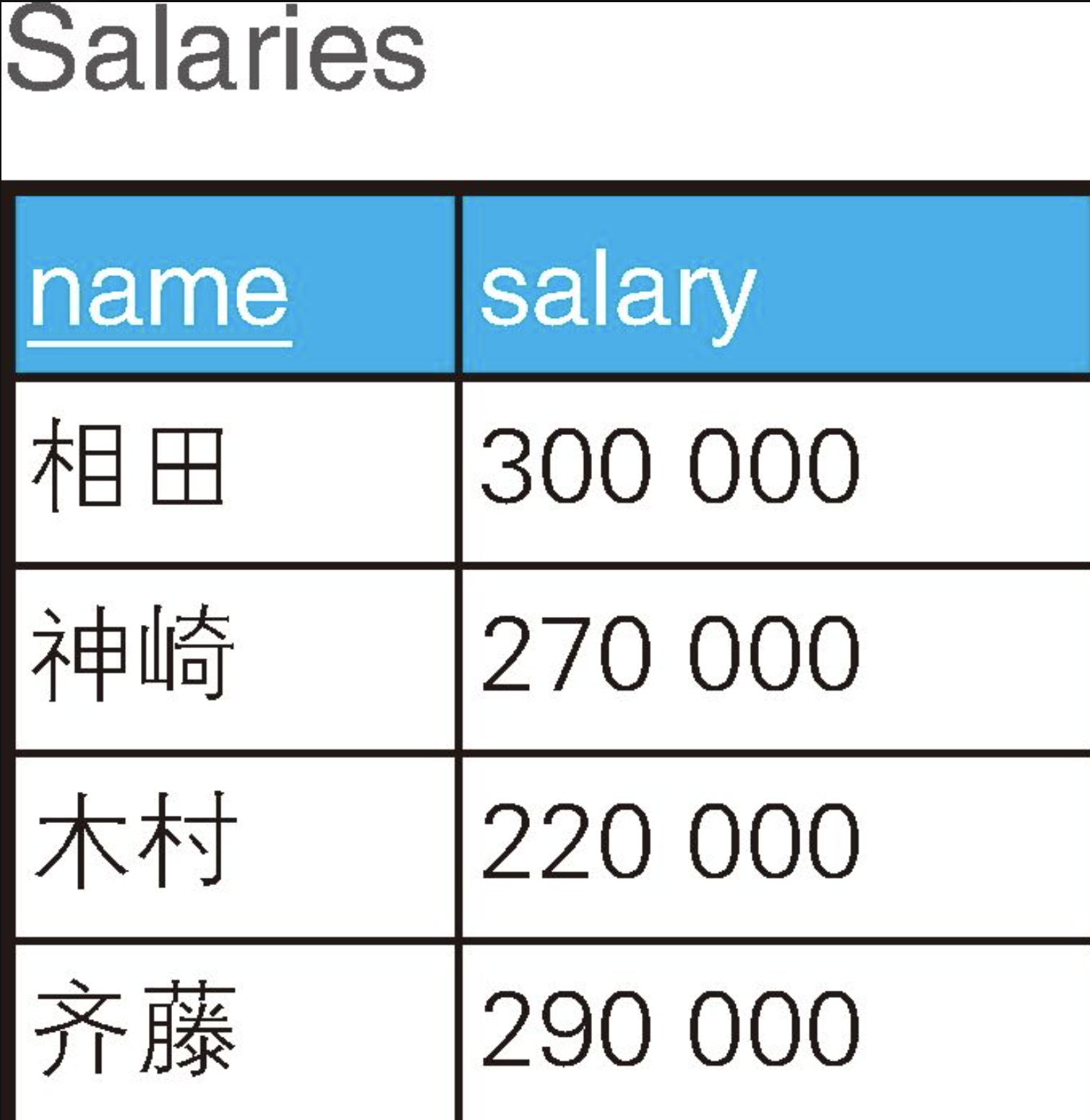
假设现在需要根据以下条件对该表的数据进行更新。
- 对当前工资为30万日元以上的员工,降薪10%。
- 对当前工资为25万日元以上且不满28万日元的员工,加薪20%。
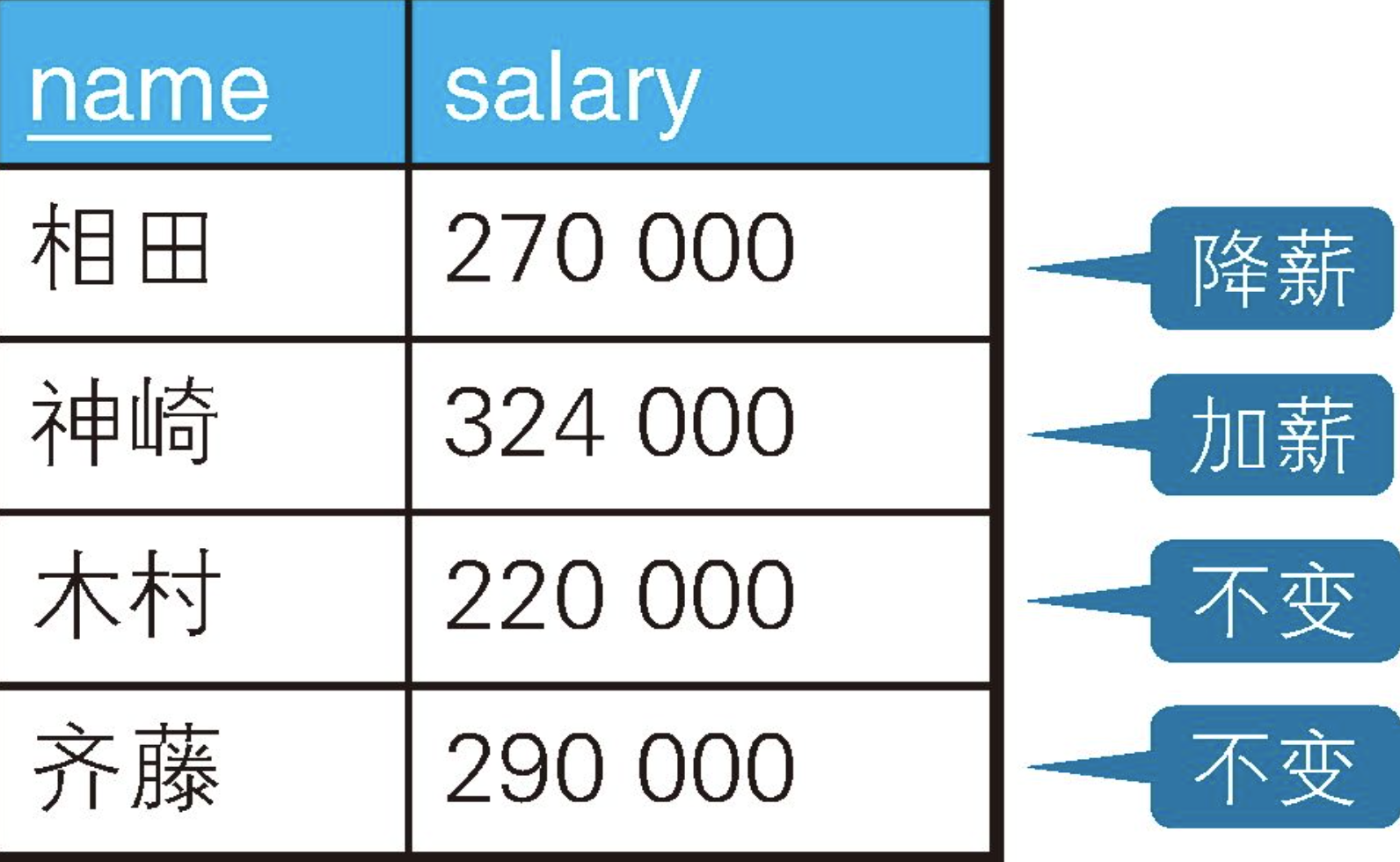
按照这些要求更新完的数据应该如下表所示。
create table Salaries (
name varchar(20),
salary INT(10)
);
INSERT INTO Salaries VALUES
('相田', 270000),
('神祇', 324000),
('木村', 220000),
('齐藤', 290000);
乍一看,分别执行下面两个UPDATE操作好像就可以做到,但这样做的结果是不正确的。
-- 条件 1
UPDATE Salaries
SET salary = salary * 0.9
WHERE salary >= 300000;
-- 条件 2
UPDATE Salaries
SET salary = salary * 1.2
WHERE salary >= 250000 AND salary < 280000;
我们来分析一下不正确的原因。例如这里有一个员工,当前工资是30万日元,按“条件1”执行UPDATE操作后,工资会被更新为27万日元,但继续按“条件2”执行UPDATE操作后,工资又会被更新为32.4万日元。这样一来,本来应该被降薪的员工却被加薪了2.4万日元。
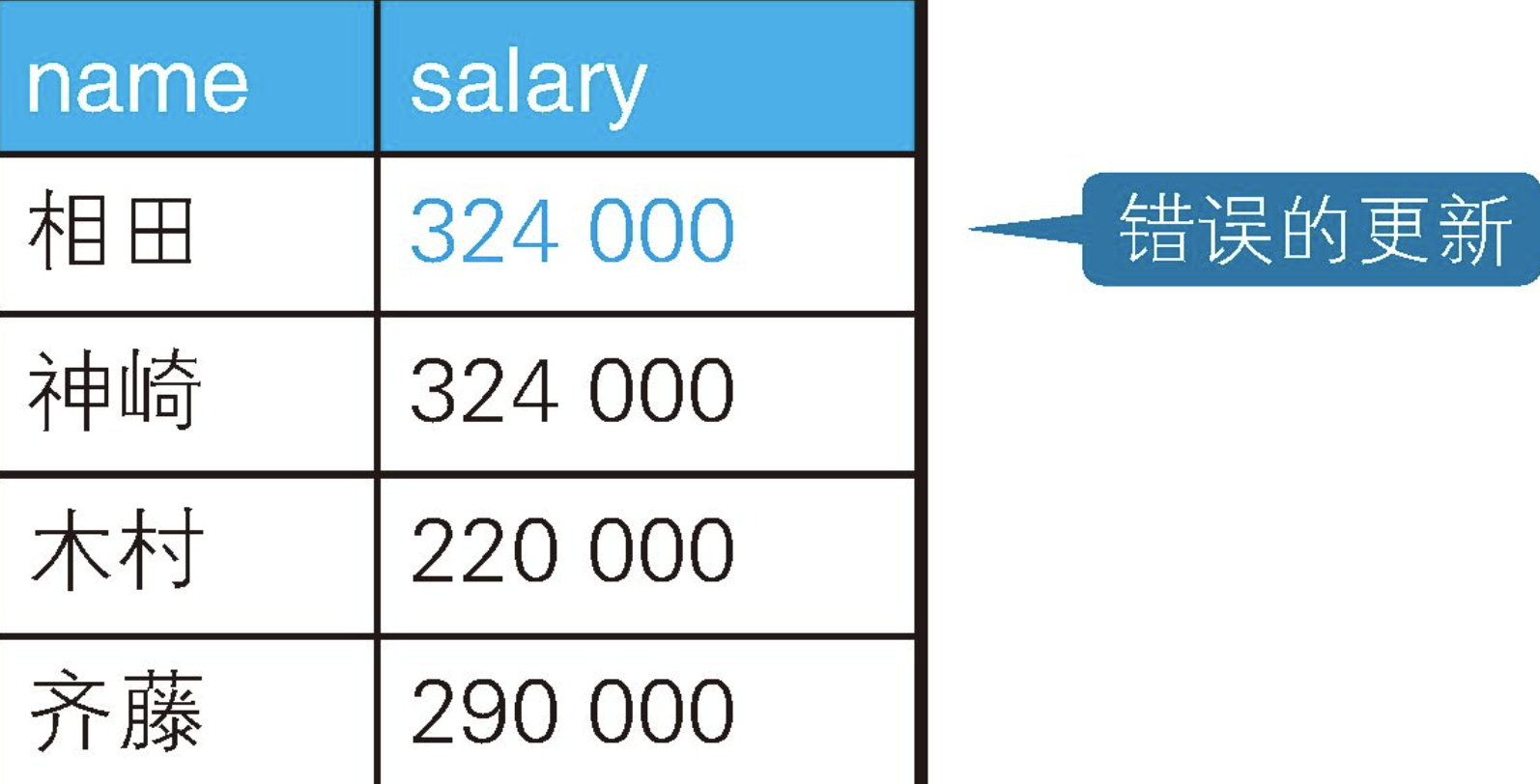
这样的结果当然并非人事部所愿。员工相田的工资必须被准确地降为27万日元。问题在于,第1次的UPDATE操作执行后,“当前工资”发生了变化,如果还拿它当作第2次UPDATE的判定条件,结果就会不准确。然而,即使将两条SQL语句的执行顺序颠倒一下,当前工资为27万日元的员工,其工资的更新结果也会出现问题。为了避免出现这些问题,准确地表达出可恶的人事部长的意图,可以像下面这样用CASE表达式来写SQL。
update Salaries
set salary = case when salary >= 300000 then salary * 0.9
when salary >= 250000 and salary < 280000 then salary * 1.2
else salary end;
select * from Salaries;
+------+--------+
| name | salary |
+------+--------+
| 相田 | 324000 |
| 神祇 | 291600 |
| 木村 | 220000 |
| 齐藤 | 290000 |
+------+--------+
需要注意的是,SQL语句最后一行的ELSE salary非常重要,必须写上。因为如果没有它,条件1和条件2都不满足的员工的工资就会被更新成NULL。这一点与CASE表达式的设计有关,在前面介绍CASE表达式的时候我们就已经了解到,如果CASE表达式里没有明确指定ELSE子句,执行结果会被默认地处理成ELSE NULL。
7、表之间的数据匹配
与DECODE函数等相比,CASE表达式的一大优势在于能够判断表达式。也就是说,在CASE表达式里,我们能使用BETWEEN、LIKE和 <、>等便利的谓词组合,还能嵌套子查询的IN和EXISTS谓词。因此,CASE表达式具有非常强大的表达能力。
如下所示,这里有一张培训学校的课程一览表和一张展示每个月所设课程的表。
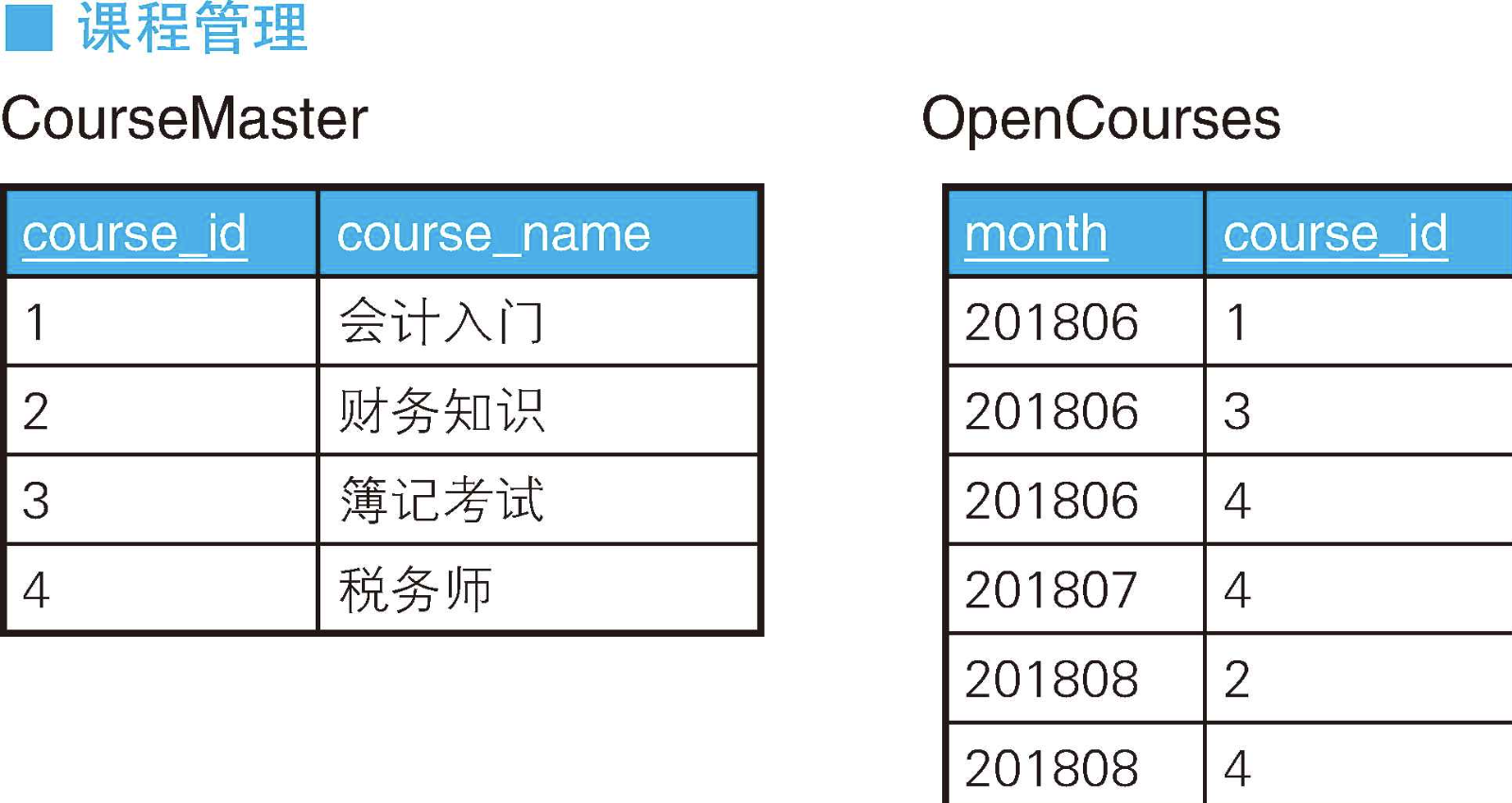
我们要用这两张表来生成下面这样的交叉表,以便于一目了然地知道每个月开设的课程。
course_name 6 月 7 月 8 月
----------- ---- ---- ----
会计入门 〇 × ×
财务知识 × × 〇
簿记考试 〇 × ×
税务师 〇 〇 〇
CREATE TABLE CourseMaster (
course_id INTEGER PRIMARY KEY,
course_name VARCHAR(32) NOT NULL
);
INSERT INTO CourseMaster VALUES(1, '会计入门');
INSERT INTO CourseMaster VALUES(2, '财务知识');
INSERT INTO CourseMaster VALUES(3, '簿记考试');
INSERT INTO CourseMaster VALUES(4, '税务师');
CREATE TABLE OpenCourses (
month INTEGER ,
course_id INTEGER ,
PRIMARY KEY(month, course_id)
);
INSERT INTO OpenCourses VALUES(201806, 1);
INSERT INTO OpenCourses VALUES(201806, 3);
INSERT INTO OpenCourses VALUES(201806, 4);
INSERT INTO OpenCourses VALUES(201807, 4);
INSERT INTO OpenCourses VALUES(201808, 2);
INSERT INTO OpenCourses VALUES(201808, 4);
我们需要做的是,检查表OpenCourses中的各月里有表CourseMaster中的哪些课程。这个匹配条件可以用CASE表达式来写。
-- 表的匹配:使用 IN 谓词
SELECT course_name,
CASE WHEN course_id IN
(SELECT course_id FROM OpenCourses
WHERE month = 201806) THEN '〇'
ELSE '×' END AS "6 月",
CASE WHEN course_id IN
(SELECT course_id FROM OpenCourses
WHERE month = 201807) THEN '〇'
ELSE '×' END AS "7 月",
CASE WHEN course_id IN
(SELECT course_id FROM OpenCourses
WHERE month = 201808) THEN '〇'
ELSE '×' END AS "8 月"
FROM CourseMaster;
-- 表的匹配:使用 EXISTS 谓词
SELECT CM.course_name,
CASE WHEN EXISTS
(SELECT course_id FROM OpenCourses OC
WHERE month = 201806
AND OC.course_id = CM.course_id) THEN '〇'
ELSE '×' END AS "6 月",
CASE WHEN EXISTS
(SELECT course_id FROM OpenCourses OC
WHERE month = 201807
AND OC.course_id = CM.course_id) THEN '〇'
ELSE '×' END AS "7 月",
CASE WHEN EXISTS
(SELECT course_id FROM OpenCourses OC
WHERE month = 201808
AND OC.course_id = CM.course_id) THEN '〇'
ELSE '×' END AS "8 月"
FROM CourseMaster CM;
+-------------+------+------+------+
| course_name | 6 月 | 7 月 | 8 月 |
+-------------+------+------+------+
| 会计入门 | 〇 | × | × |
| 财务知识 | × | × | 〇 |
| 簿记考试 | 〇 | × | × |
| 税务师 | 〇 | 〇 | 〇 |
+-------------+------+------+------+
这样的查询没有进行聚合,因此也不需要排序,月份增加的时候仅修改SELECT子句就可以了,扩展性比较好。
无论使用IN还是EXISTS,得到的结果是一样的,但从性能方面来说,EXISTS更好。通过EXISTS进行的子查询能够用到“month, course_id”这样的主键索引,因此当表OpenCourses里的数据比较多时,使用EXISTS的优势会更大。
换个角度来看,表之间的数据匹配就是生成一张表侧栏固定的交叉表,因此使用外连接的方法也可以完成。
8、在CASE表达式中使用聚合函数
接下来介绍一下稍微高级的用法。这个用法乍一看可能让人觉得是语法错误,实际上并非如此,而且它在所有的DBMS中都可以使用。我们来看一道例题,假设这里有一张显示了学生及其加入的社团的一览表。这张表的主键是“学号、社团ID”。
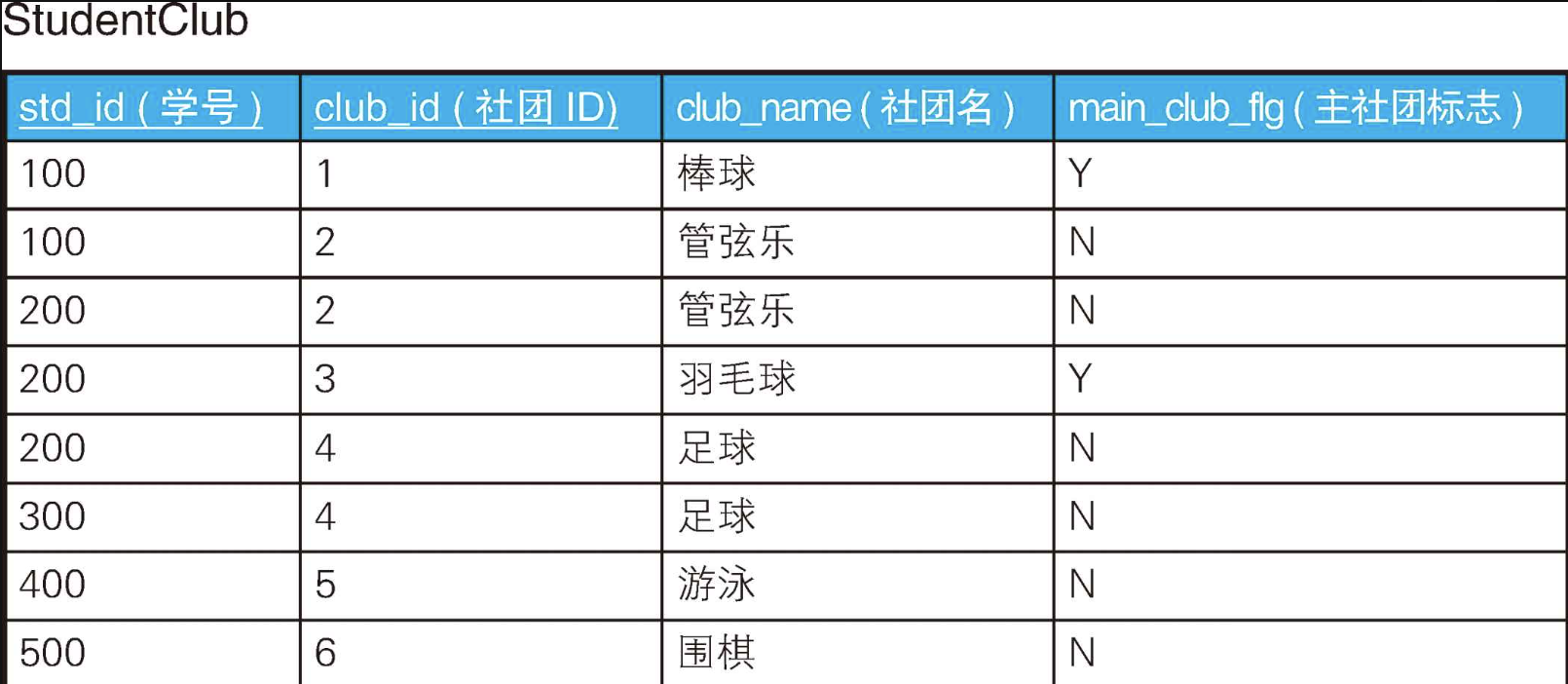
CREATE TABLE StudentClub (
std_id INTEGER,
club_id INTEGER,
club_name VARCHAR(32),
main_club_flg CHAR(1),
PRIMARY KEY (std_id, club_id)
);
INSERT INTO StudentClub VALUES(100, 1, '棒球', 'Y');
INSERT INTO StudentClub VALUES(100, 2, '管弦乐', 'N');
INSERT INTO StudentClub VALUES(200, 2, '管弦乐', 'N');
INSERT INTO StudentClub VALUES(200, 3, '羽毛球', 'Y');
INSERT INTO StudentClub VALUES(200, 4, '足球', 'N');
INSERT INTO StudentClub VALUES(300, 4, '足球', 'N');
INSERT INTO StudentClub VALUES(400, 5, '游泳', 'N');
INSERT INTO StudentClub VALUES(500, 6, '围棋', 'N');
有的学生同时加入了多个社团(如学号为100、200的学生),有的学生只加入了一个社团(如学号为300、400、500的学生)。对于加入了多个社团的学生,我们通过将其“主社团标志”列设置为Y或者N来表明哪一个社团是他的主社团;对于只加入了一个社团的学生,我们将其“主社团标志”列设置为N。
接下来,我们按照下面的条件查询这张表里的数据。
- 获取只加入了一个社团的学生的社团ID。
- 获取加入了多个社团的学生的主社团ID。
很容易想到的办法是,针对两个条件分别写SQL语句来查询。要想知道学生“是否加入了多个社团”,我们需要用HAVING子句对聚合结果进行判断。
-- 条件 1 :选择只加入了一个社团的学生
SELECT std_id, MAX(club_id) AS main_club
FROM StudentClub
GROUP BY std_id
HAVING COUNT(*)= 1;
+--------+-----------+
| std_id | main_club |
+--------+-----------+
| 300 | 4 |
| 400 | 5 |
| 500 | 6 |
+--------+-----------+
-- 条件 2 :选择加入了多个社团的学生
SELECT std_id, club_id AS main_club
FROM StudentClub
WHERE main_club_flg = 'Y' ;
+--------+-----------+
| std_id | main_club |
+--------+-----------+
| 100 | 1 |
| 200 | 3 |
+--------+-----------+
这样做也能得到正确的结果,但需要写多条SQL语句,存在性能问题。如果使用CASE表达式,下面这一条SQL语句就可以了。
SELECT std_id,
CASE WHEN COUNT(*) = 1
THEN MAX(club_id)
ELSE MAX(CASE WHEN main_club_flg = 'Y'
THEN club_id
ELSE NULL END) END AS main_club
FROM StudentClub
GROUP BY std_id;
+--------+-----------+
| std_id | main_club |
+--------+-----------+
| 100 | 1 |
| 200 | 3 |
| 300 | 4 |
| 400 | 5 |
| 500 | 6 |
+--------+-----------+
这种写法比较新颖,因为我们在初学SQL的时候,都学过对聚合结果进行条件判断时要用HAVING子句,但从这道例题可以看出,在SELECT语句里使用CASE表达式也可以完成同样的工作,如果用一句话来形容这个技巧,可以这样说:新手用HAVING子句进行条件分支,高手用SELECT子句进行条件分支。
9、总结
面向过程语言中也有“CASE语句”这样的条件分支,因此CASE表达式经常会与其混淆,被叫作CASE“语句”。这是错误的。准确来说,它并不是语句,而是和1+1或者a/b一样,属于表达式的范畴。结束符END确实看起来像是在标记一连串处理过程的终结,所以初次接触CASE表达式的人容易对这一点感到困惑。“表达式”和“语句”的名称区别恰恰反映了二者在功能处理方面的差异。
作为表达式,CASE表达式在执行时会被判定为一个固定值,因此它可以写在聚合函数内部;也正因为它是表达式,所以还可以写在SELECT子句、GROUP BY子句、WHERE子句、ORDER BY子句里。简单点说,在能写列名和常量的地方,通常都可以写CASE表达式。从这个意义上来说,与CASE表达式最接近的不是面向过程语言里的CASE语句,而是Lisp和Scheme等函数式语言里的case和cond这样的条件表达式。
CASE表达式可以写在任何地方:
- SELECT子句
- WHERE子句
- GROUP BY子句
- HAVING子句
- ORDER BY子句
- PARTITION BY子句
- 在CHECK约束中
- 函数的参数
- 谓词的参数
- 在其他表达式中(也包含CASE表达式本身)
- 在GROUP BY子句里使用CASE表达式,可以灵活地选择聚合单位的编号或等级。这一点在进行非定制化统计时能发挥巨大的威力。
- 在聚合函数中使用CASE表达式,可以轻松地将行结构的数据转换成列结构的数据。
- 聚合函数也可以嵌套进CASE表达式里,因此可以在不使用HAVING子句的情况下汇总查询。
- 相比依赖于具体数据库的函数,CASE表达式拥有更强大的表达能力和更好的可移植性。
- 正因为CASE表达式是一种表达式而不是语句,才有了这诸多的优点。
- 使用CASE表达式,可以将多条SQL语句汇总为一条,可读性和性能都能得到提升。
11、示例
11.1、多列数据的最大值
用SQL从多行数据里选出最大值或最小值很容易——通过GROUP BY子句对合适的列进行聚合操作,并使用MAX或MIN聚合函数就可以求出。那么,从多列数据里选出最大值该怎么做呢?
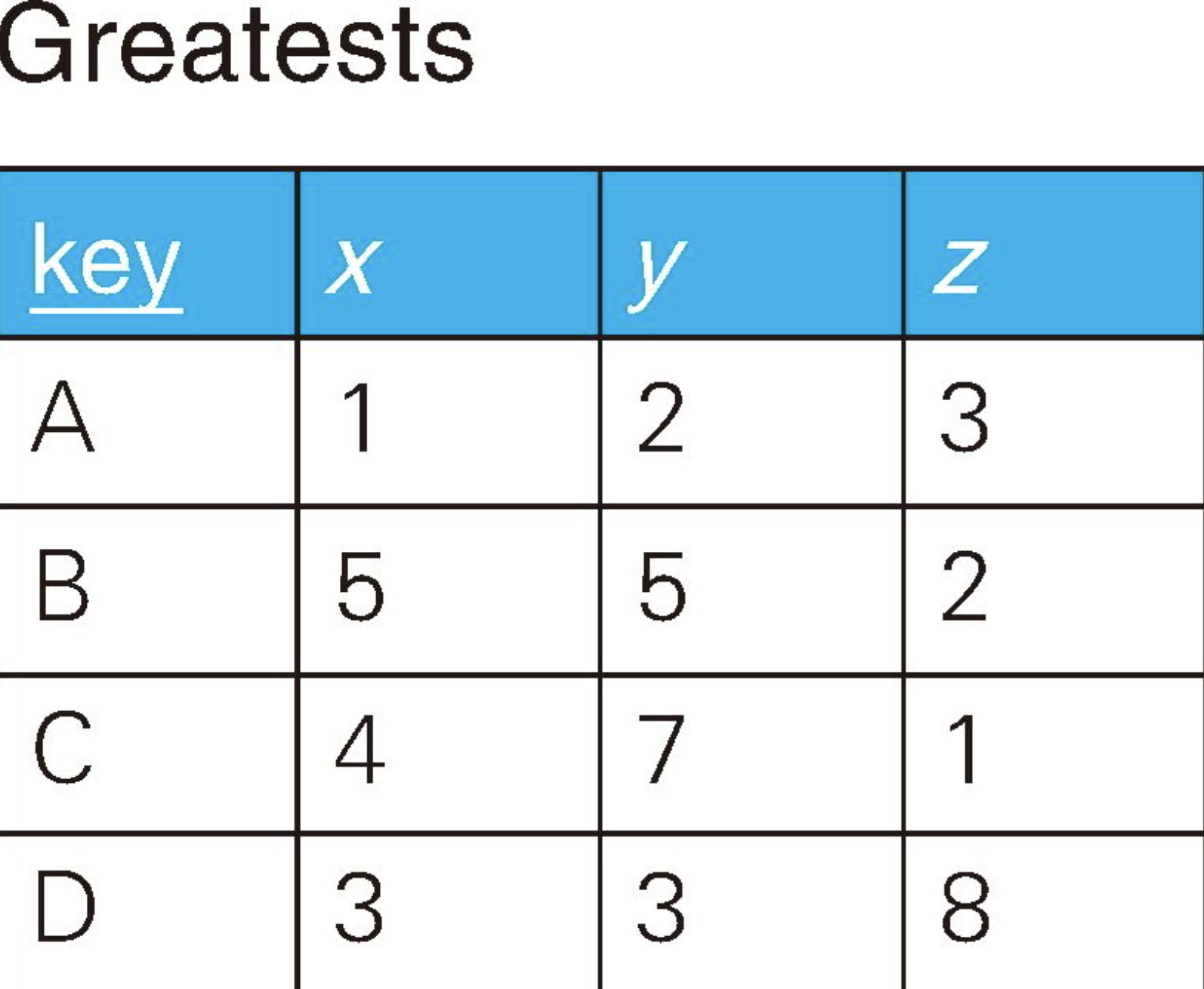
先思考一下从表里选出 x和 y二者中较大的值的情况。此时,求得的结果应该如下所示。
key greatest
----- ---------
A 2
B 5
C 7
D 3
CREATE TABLE Greatests (
`key` CHAR(1) PRIMARY KEY,
x INT NOT NULL,
y INT NOT NULL,
z INT NOT NULL
);
INSERT INTO Greatests VALUES('A', 1, 2, 3);
INSERT INTO Greatests VALUES('B', 5, 5, 2);
INSERT INTO Greatests VALUES('C', 4, 7, 1);
INSERT INTO Greatests VALUES('D', 3, 3, 8);
Oracle、PostgreSQL和MySQL数据库直接提供了可以实现这个需求的GREATEST函数,但是这里请不要用这些函数,而是用标准SQL的方法来实现。
求出 x和 y二者中较大的值后,再试着将列数扩展到3列以上吧。这次求的是 x、y和 z三者中的最大值,因此结果应该如下所示。
key greatest
----- ---------
A 3
B 5
C 7
D 8
解法如下:
/* 求x和y二者中较大的值 */
SELECT `key`,
CASE WHEN x < y THEN y
ELSE x END AS greatest
FROM Greatests;
+-----+----------+
| key | greatest |
+-----+----------+
| A | 2 |
| B | 5 |
| C | 7 |
| D | 3 |
+-----+----------+
/* 求x、y和z中的最大值 */
SELECT `key`,
CASE WHEN
CASE WHEN x < y THEN y ELSE x END < z
THEN z
ELSE
CASE WHEN x < y THEN y ELSE x END
END AS greatest
FROM Greatests;
+-----+----------+
| key | greatest |
+-----+----------+
| A | 3 |
| B | 5 |
| C | 7 |
| D | 8 |
+-----+----------+
11.2、转换行列——在表头里加入汇总和再揭
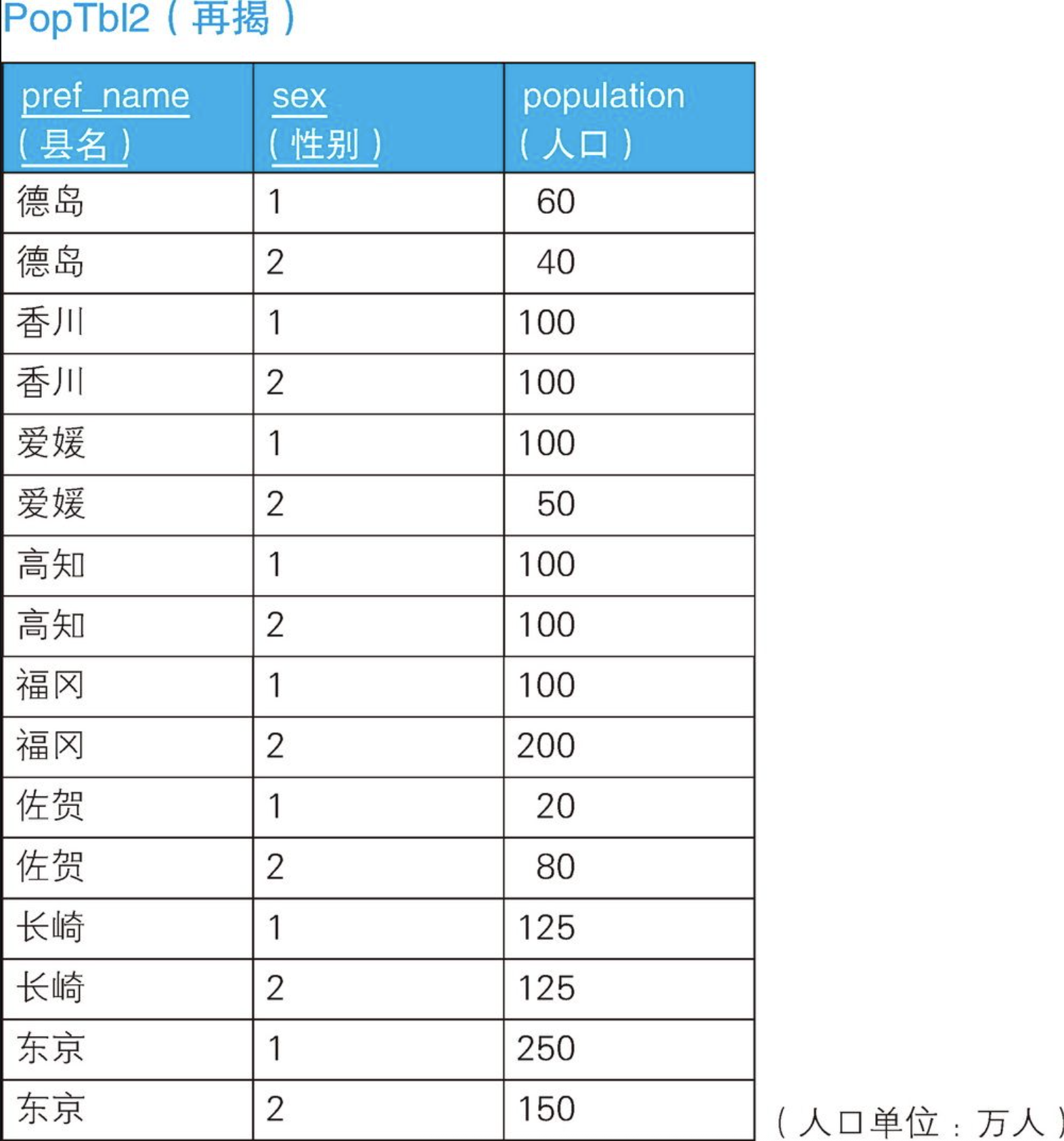
这次请生成下面这样的表头里带有汇总和再揭的二维表。
性别 全国 德岛 香川 爱媛 高知 四国(再揭)
---- ------ ----- ------ ------ ------- ----------
1 855 60 100 100 100 360
2 845 40 100 50 100 290
“全国”列里是表PopTbl2中所有都道府县(限于篇幅,还有一些都道府县未列出)人口的合计值。另外,最右边的“四国(再揭)”列里是四国地区4个县的合计值。
解法如下:
/* 转换行列——在表头里加入汇总和再揭(p.287) */
SELECT sex as '性别',
SUM(population) AS '全国',
SUM(CASE WHEN pref_name = '德岛' THEN population ELSE 0 END) AS '德岛',
SUM(CASE WHEN pref_name = '香川' THEN population ELSE 0 END) AS '香川',
SUM(CASE WHEN pref_name = '爱媛' THEN population ELSE 0 END) AS '爱媛',
SUM(CASE WHEN pref_name = '高知' THEN population ELSE 0 END) AS '高知',
SUM(CASE WHEN pref_name IN ('德岛', '香川', '爱媛', '高知')
THEN population ELSE 0 END) AS '四国(再揭)'
FROM PopTbl2
GROUP BY sex;
+------+------+------+------+------+------+------------+
| 性别 | 全国 | 德岛 | 香川 | 爱媛 | 高知 | 四国(再揭) |
+------+------+------+------+------+------+------------+
| 1 | 855 | 60 | 100 | 100 | 100 | 360 |
| 2 | 845 | 40 | 100 | 50 | 100 | 290 |
+------+------+------+------+------+------+------------+
11.3、用ORDER BY生成“排序”列
表Greatests正常执行SELECT key FROM Greatests ORDER BY key;这个查询后,结果通常会按照key列的值的字母表顺序显示出来。
那么,请思考一个查询语句,使得结果按照B-A-D-C这样的指定顺序进行排列。这个顺序并没有什么具体的意义,大家也可以在实现完上述需求后,试着实现让结果按照其他顺序排列。
解法如下:
/* 用ORDER BY生成“排序”列 */
SELECT `key`
FROM Greatests
ORDER BY CASE `key`
WHEN 'B' THEN 1
WHEN 'A' THEN 2
WHEN 'D' THEN 3
WHEN 'C' THEN 4
ELSE NULL END;
+-----+
| key |
+-----+
| B |
| A |
| D |
| C |
+-----+
/* 把“排序”列也包括在结果中*/
SELECT `key`,
CASE `key`
WHEN 'B' THEN 1
WHEN 'A' THEN 2
WHEN 'D' THEN 3
WHEN 'C' THEN 4
ELSE NULL END AS sort_col
FROM Greatests
ORDER BY sort_col;
+-----+----------+
| key | sort_col |
+-----+----------+
| B | 1 |
| A | 2 |
| D | 3 |
| C | 4 |
+-----+----------+


















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










