




 本文介绍SQL执行计划的不同类型及其应用场景,包括全表扫描、索引扫描、全索引扫描及位图扫描等,并提供了实用的SQL查询案例。此外,还分享了一些PostgreSQL中的高级查询技巧,如按指定顺序排序、求时间差、查询函数源码等。
本文介绍SQL执行计划的不同类型及其应用场景,包括全表扫描、索引扫描、全索引扫描及位图扫描等,并提供了实用的SQL查询案例。此外,还分享了一些PostgreSQL中的高级查询技巧,如按指定顺序排序、求时间差、查询函数源码等。
目录
一、执行计划
执行计划能分析语句的性能
这里模拟一张表,用于后面的SQL样例。
表T有800w行数据,
四个字段:主键id、index_a、index_b、column_c。
index_a、index_b 有B-tree索引,column_c无索引
1.1 索引扫描方式
1. 全表扫描(Seq Scan)
当查询条件没使用索引,或者满足条件的数据集较大,索引扫描+回表的成本高于全表扫描,会选择使用全表扫描。
explain select * from T where column_c = '1';
结果
Seq Scan on T(cost=0.00..280929.92 rows=1 width=1192)
Filter: ((column_c )::text = '1'::text)
2. 索引扫描(index scan)
走索引+回表
a. 索引上没有其它列的信息,走索引找到主键后需要回表,从扫描主键对应的一行数据。
explain SELECT * FROM T where index_a = '1';
结果:
Index Scan using index_a on T(cost=0.56..40.71 rows=9 width=1192)
Index Cond: ((index_a )::text = '1'::text)
b. index_a走索引找到主键后需要回表,扫描主键对应的一行数据,根据column_c过滤数据
explain SELECT index_a FROM T where index_a = '1' and column_c = '1';
结果
Index Scan using index_a on T(cost=0.56..40.74 rows=1 width=33)
Index Cond: ((index_a )::text = '1'::text)
Filter: (column_c = '1'::text)
3. 全索引扫描(index only scan)
只通过索引就获取了数据,不需要回表/读取表数据
explain SELECT index_a FROM T where index_a = '1'
结果:
Index Only Scan using index_a on T(cost=0.56..40.71 rows=9 width=33)
Index Cond: (index_a = '1'::text)
4. 位图扫描(Bitmap Index Scan)
走了多个索引。在or、and、in子句和有多个条件都可以同时走不同的索引时,都可能走Bitmap Index Scan
建立一张位图,每一位代表满足条件的行在数据库中的位置。多个索引查询结果会更新到位图,最后根据位图记录的行位置,会到数据库中将满足条件的结果取出来。(因此位图扫描一定会回表,位图不记录具体数据)
explain SELECT index_a FROM T where index_a = '1' or index_b = '1';
结果
Bitmap Heap Scan on T(cost=19.40..1134.02 rows=286 width=33)
Recheck Cond: (((index_a )::text = '1'::text) OR ((index_b )::text = '1'::text))
-> BitmapOr (cost=19.40..19.40 rows=286 width=0)
-> Bitmap Index Scan on index_a (cost=0.00..4.62 rows=9 width=0)
Index Cond: ((index_a )::text = '1'::text)
-> Bitmap Index Scan on index_b (cost=0.00..14.63 rows=276 width=0)
Index Cond: ((index_b )::text = '1'::text)
1.2 执行计划结果语义
- cost: 执行的时间范围(单位不是普通的时间),计算它在总的执行代价的占比,可以分析出性能瓶颈
- rows: 返回结果行数
- width: 返回结果一行的宽度
- index cond: 执行的条件
- loops: 循环次数
二、常用命令
按指定顺序排序
通过下标位置排序(PG9.5以上)
SELECT c_code FROM t_code order by array_position(array['a','b']::varchar[],c_code)
通过字符串匹配位置排序,缺点是可能提前匹配。
SELECT * FROM t_code order by position(c_code in 'a,b')
date_part函数求时间差
PostgreSQL求timestamp的时间差用date_part。但是在取分钟差时发现不是实际的分钟差,而是分钟差%60(也就是不带小时信息)
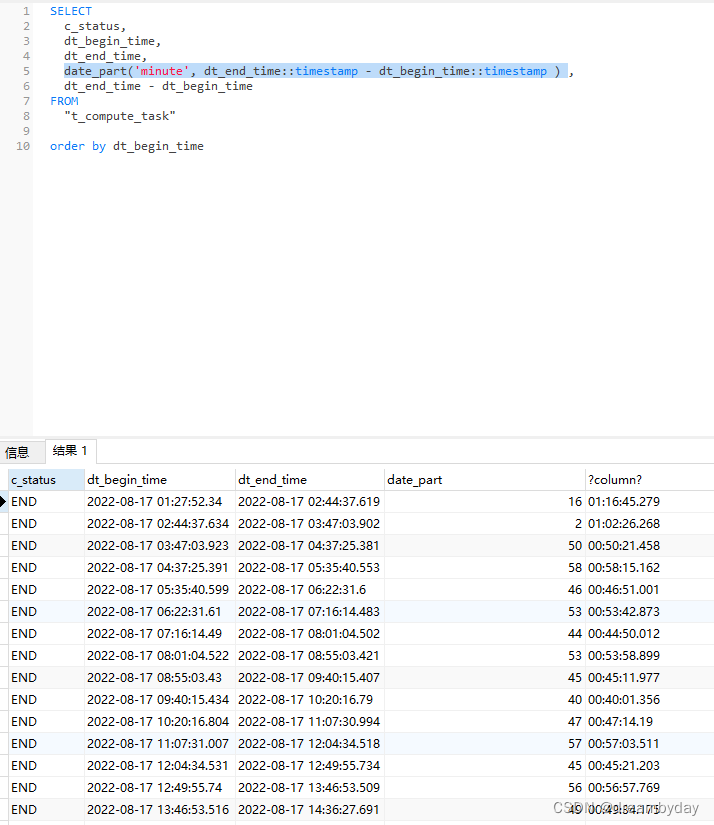
可以看到第一行实际时间差是1小时16分,但函数取值是16分。
求实际分钟差可以用
date_part('minute', dt_end_time::timestamp - dt_begin_time::timestamp )
+ date_part('day', dt_end_time::timestamp - dt_begin_time::timestamp ) * 24 * 60
+ date_part('hour', dt_end_time::timestamp - dt_begin_time::timestamp ) * 60
pg_proc表:根据函数名查询函数
select prosrc from pg_proc where proname='函数名'
更新某表一列的值为另一张表某列随机值
t_user 用户表
| c_id | c_name | c_area | dt_create_time |
|---|---|---|---|
| uuid1 | 小王 | NULL | 2022-06-30 16:59:01.58 |
| uuid2 | 小李 | NULL | 2022-06-30 16:59:01.58 |
| uuid3 | 小张 | NULL | 2022-06-30 16:59:01.58 |
t_code_area 地区码值表
| c_id | c_name |
|---|---|
| 1 | 江苏 |
| 2 | 北京 |
| 3 | 天津 |
给用户表的地区名跟据另一张地区码值表随机赋值。
update t_user set c_area =
(select array_agg(c_name) from t_code_area )
[floor(random() * (select count(1) from t_code_area))::INT + 1];
或者手填随机值
update t_user set c_area =
(array['江苏','北京','天津'] )
[floor(random() * 3)::INT + 1];
查看指定表的所有列信息
根据模式名和表名,查询该表的所有字段,按表字段顺序排列
SELECT
table_schema || '.' || TABLE_NAME, string_agg ( COLUMN_NAME, ',' )
FROM
(
SELECT TABLE_NAME,table_schema,COLUMN_NAME
FROM
information_schema.COLUMNS
WHERE
table_schema = '?' and TABLE_NAME IN ( '?' )
ORDER BY
TABLE_NAME,
ordinal_position
) tables
GROUP BY
TABLE_NAME,
table_schema
表已有数据,翻倍加压
先对要加压的表生成insert语句
SELECT
'insert into ' || table_schema || '.' || TABLE_NAME || ' (' || string_agg ( COLUMN_NAME, ',' ) || ') select '|| string_agg ( COLUMN_NAME, ',' ) ||' from ' || table_schema || '.' || TABLE_NAME
FROM
(
SELECT TABLE_NAME
,
table_schema,
COLUMN_NAME
FROM
information_schema.COLUMNS
WHERE
table_schema = '?'
AND (TABLE_NAME IN ( '?' ) )
ORDER BY
TABLE_NAME,
ordinal_position
) tables
GROUP BY
TABLE_NAME,
table_schema
得到的语句为
INSERT INTO t_user (
c_id,c_name,c_area,dt_create_time
) SELECT
c_id,c_name,c_area,dt_create_time
FROM
caseratiodetail.tyyw_gg_ajjbxx
将数据量翻倍,时间加一年,uuid主键直接用md5重新生成。注意多次翻倍应该加时间条件,否则数据量将以幂次增长。
INSERT INTO t_user (
c_id,c_name,c_area,dt_create_time
) SELECT
md5(c_id),c_name,c_area,dt_create_time + '1 year'
FROM
caseratiodetail.tyyw_gg_ajjbxx


















 4411
4411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










