




表面码的快速高精度AI预解码器
摘要
快速、可扩展的解码架构,以跨空间和时间的块级并行方式运行,对于实时容错量子计算至关重要。我们介绍了一种用于表面码的可扩展AI预解码器,该预解码器执行局部并行纠错,具有低解码运行时间,在将残余综合征传递给下游全局解码器之前,去除了大部分物理错误。这种模块化架构与后端无关,可与为表面码设计的任意全局解码算法组合,且我们的实现完全开源。与非相关PyMatching集成后,该流水线在NVIDIA GB300 GPU上于大码距处实现了每轮 O ( 1 μ s ) \mathcal{O}(1\,\mu\text{s}) O(1μs) 量级的端到端解码运行时间,同时相对于单独全局解码降低了逻辑错误率(LER)。在具有多个GPU访问权限的块级并行解码方案中,解码运行时间可降至远低于 O ( 1 μ s ) \mathcal{O}(1\,\mu\text{s}) O(1μs) 每轮。我们通过训练更大的模型进一步观察到LER改善,在高达13码距时超过相关PyMatching。此外,我们引入了一种噪声学习架构,该架构直接从实验可及的综合征统计中推断解码权重,无需显式的电路级噪声模型。我们表明,纯数据驱动的图权重估计在某些情况下几乎可以匹配非相关PyMatching并超过相关PyMatching,当硬件噪声模型未知或随时间变化时,可实现高度优化的解码,同时也可用于训练具有现实噪声模型的预解码器。总之,这些结果建立了一个实用、模块化且高吞吐量的解码框架,适用于大码距表面码实现。
代码: GitHub
模型: Hugging Face
1 引言
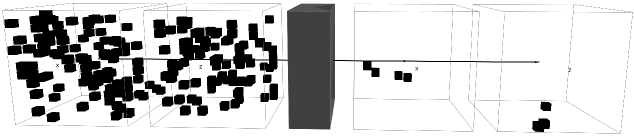
Figure 1: Example showing the syndrome density being reduced by the pre-decoder for both
X
X
X-type and
Z
Z
Z-type stabilizers. The residual syndromes are passed on to a global decoder to perform final corrections.
量子纠错(QEC)是构建大规模容错量子计算机(FTQC)的基础要求。QEC解码器是经典算法,用于从综合征测量数据中推断物理错误——或者等价地,逻辑可观测量的值——并且在某些方案中,还利用附加信息如标志量子比特结果。如文献所示,解码器运行时间必须足够高,以防止在量子算法执行期间未处理综合征数据的指数级积压。在下文中,运行时间将指解码器处理一轮综合征测量数据块所需的时间。对于许多硬件平台,滑动窗口解码对每轮综合征测量施加 O ( 1 μ s ) \mathcal{O}(1\,\mu\text{s}) O(1μs) 量级的运行时间要求,这是一个对当前最先进经典硬件具有挑战性的领域。并行块级解码架构可以通过并发解码提交和清理窗口来部分缓解这一约束,前提是提供足够的经典资源。然而,即使当 d m ≪ d d_m \ll d dm≪d 时,量子算法的运行时间仍然根本上受限于解码距离为 d d d 的码的 d m d_m dm 轮综合征测量数据块所需的时间。因此,在块级别最小化解码运行时间对于可扩展FTQC至关重要。
各种基于AI的QEC解码器已被提出,旨在实现低解码运行时间和改进的逻辑错误率(LER)。然而,许多此类方法遇到可扩展性挑战,既包括随着码距增加所需的训练数据量,也包括其与时间和空间上并行块级解码架构的兼容性。空间并行性对于基于晶格手术的容错逻辑操作尤为关键,其中合并的码片可以具有 d eff ≫ 100 d_{\text{eff}} \gg 100 deff≫100 的有效距离。在此范围内,满足实时解码要求可能需要跨大片区域的空间并行块级解码。因此,不兼容空间并行的解码器可能成为逻辑操作的瓶颈,即使它们在中等码距的存储设置中表现良好。
基于AI的预解码器已被明确开发以解决速度和非常大码距的可扩展性问题。由于预解码器在标记数据上训练并局部操作,此类预解码器自然地兼容空间和时间上的并行块级解码。此外,它们的局部性允许在适中码距 d 1 d_1 d1 训练的模型推广到更大的码距 d 2 ≫ d 1 d_2 \gg d_1 d2≫d1。在典型的流水线中,预解码器局部处理综合征数据,执行校正,并将残余综合征和逻辑信息传递给执行最终校正的全局解码器。预解码器应用后传递给全局解码器的残余综合征示例如图\ref{fig:visualization_3d}所示。虽然这种混合方法利用了学习和算法解码器的优势,但在本工作之前,尚未证明预解码器与最先进的全局解码器结合可以同时实现每轮 O ( 1 μ s ) \mathcal{O}(1\,\mu\text{s}) O(1μs) 量级的总解码运行时间并且比单独全局解码器更低的逻辑错误率。
在本工作中,我们为旋转表面码引入了一种新的基于AI的预解码器架构。我们开发了处理标记训练数据的新方法,明确解决了类空间和类时失效机制。这些方法显著提高了预解码器性能,并使每轮综合征测量的端到端解码运行时间达到 O ( 1 μ s ) \mathcal{O}(1\,\mu\text{s}) O(1μs) 量级,包括预解码和随后使用PyMatching的全局解码。我们在码距 d = 21 d=21 d=21 和 d = 31 d=31 d=31 处展示了这些结果,其中组合预解码器 + 非相关PyMatching流水线实现了比单独非相关PyMatching更低的逻辑错误率,同时减少了总解码运行时间。此外,相对于PyMatching的总解码时间改进随码距增加而增加。对于相关PyMatching全局解码器,我们训练了一个更大的模型,该模型超过单独相关PyMatching并在高达13码距处实现更低的运行时间。更大的模型可以被训练以实现低于相关PyMatching的LER,适用于 d ≤ 13 d \leq 13 d≤13 的码距。低运行时间源于预解码器产生的有效综合征密度的显著降低,以及在最先进NVIDIA GB300 GPU上的高效部署。当在我们的预解码器应用于时间并行块级解码方案时,在访问足够GPU的情况下,运行时间可以远低于 1 μ s 1\,\mu\text{s} 1μs。
在PyMatching的标准实现中,匹配图中的边权重源自假设的电路级噪声模型,以优化逻辑错误率(LER)性能。然而,预解码器的应用以原始噪声模型未捕获的方式修改了综合征统计,导致次优匹配权重。更广泛地说,在许多实际设置中,完整电路级噪声模型要么未知,要么随时间漂移,而来自底层硬件的综合征数据仍然可访问。这促使需要直接从观测数据中推断有效解码参数的方法。
为应对这些挑战,我们引入了一种基于AI的噪声学习架构,该架构仅使用综合征统计推断非相关和相关PyMatching的近最优边权重,无需显式了解底层噪声模型。我们证明将此协议应用于原始综合征数据产生的边权重,对于非相关匹配实现了几乎相同的LER,对于相关匹配相比从已知噪声模型获得的权重有所改进。
将噪声学习架构应用于预解码器产生的综合征统计时,我们未观察到LER的进一步改善。这种行为与预解码器输出的残余错误的结构化性质一致,后者已经编码了下游解码的大部分相关信息,从而限制了通过权重重新优化实现额外收益的程度。
本文组织如下。在第\ref{sec:SurfaceCodeReview}节中,我们回顾了与预解码器开发相关的旋转表面码的关键特性。预解码器架构在第\ref{sec:PreDecArch}节中介绍。在第\ref{subsec:Motivation}小节中阐述其使用动机后,我们在第\ref{subsec:NNArchHyperParam}小节中描述神经网络架构和相关仿真与数据处理技术。在第\ref{sec:EffectivePreDecNoiseModel}节中,我们介绍基于综合征统计的噪声学习框架。预解码器和噪声学习模型的数值结果在第\ref{sec:Numerics}节中呈现。具体而言,第\ref{subsec:SynDensLER}小节分析了综合征密度降低以及将预解码器与非相关PyMatching组合时产生的逻辑错误率(LER),而第\ref{subsec:SynDensLERCorrMatch}小节使用更大模型将这些结果扩展到相关PyMatching。运行时间性能在第\ref{subsec:GPURuntimes}小节中考察,我们报告了在NVIDIA GB300 GPU上预解码器的每轮解码时间,以及组合预解码器和PyMatching流水线的总运行时间。在第\ref{subsec:TimeLikeParallel}小节中,我们展示了在具有多个GPU的时间并行块级解码方案中,每轮解码时间如何进一步减少。在第\ref{subsec:NoiseLearnImprove}小节中,我们评估了从电路级噪声模型生成的综合征数据上的噪声学习模型,比较使用学习边权重与从已知噪声模型导出的权重获得的LER。第\ref{sec:BatchingImprove}节探讨了更大批量大小对减少实时解码资源需求的影响。最后,第\ref{sec:Conclusion}节总结了我们的结果并概述了未来工作方向。
2 贡献总结
本工作的主要贡献如下:
-
具有类空间和类时校正的预解码器架构。 我们引入了一种用于旋转表面码的全卷积3D神经网络预解码器,该预解码器联合预测全时空综合征体积上的类空间(数据量子比特)和类时(测量)校正(第\ref{sec:PreDecArch}节)。该架构与后端无关:它不仅与PyMatching组合,还可与为表面码设计的任何全局解码器组合,并且可以通过调整模型深度、宽度和训练配置来适应不同的噪声模型、码距和运行时间预算。我们开发了新的数据处理技术——包括用于隔离类时失效分量的协议(算法\ref{Algo:TimelikeOutputGen})、防止人工类时检测事件的故障延迟方案(算法\ref{Algo:DataGenOptimize}),以及类时同调等价协议(算法\ref{Algo:TimelikeHomologicalEquivZ})——显著提高了训练标签质量和预解码器性能。
-
同时实现LER改进和端到端运行时间减少。 我们证明,将我们的预解码器与非相关PyMatching组合,在表面码码距 d ≥ 21 d \ge 21 d≥21 接近阈值处,同时实现了比单独非相关PyMatching更低的逻辑错误率和更低的总解码运行时间(第\ref{subsec:SynDensLER}、\ref{subsec:GPURuntimes}小节)。据我们所知,这是首次证明基于AI的预解码器可以同时相对于最先进的全局解码器改进这两个指标。LER和运行时间的相对改进都随码距增加而增长。通过训练具有残差连接的更大模型(图\ref{fig:Model8Representation}),我们进一步展示了在高达 d = 13 d=13 d=13 的码距上超过相关PyMatching的LER改进(第\ref{subsec:SynDensLERCorrMatch}小节)。
-
GPU部署和解码器运行时间基准测试。 我们在NVIDIA GB300 GPU上以FP8精度对五种预解码器架构进行了基准测试,系统探索了模型宽度、深度、核大小、推理运行时间和LER性能之间的权衡(第\ref{subsec:GPURuntimes}小节)。组合预解码器 + PyMatching流水线实现了高达 3.4 × 3.4\times 3.4× 于非相关PyMatching和 3.5 × 3.5\times 3.5× 于相关PyMatching的总加速,在 d = 31 d=31 d=31 和 p = 0.006 p=0.006 p=0.006 处(表\ref{tab:Summary_Speedup}、表\ref{tab:runtimes_mwpm_bs1_correlated_total_speedup})。当部署在具有多个GPU的时间并行块级解码方案中时,每轮预解码器运行时间远低于 1 μ s 1\,\mu\text{s} 1μs(第\ref{subsec:TimeLikeParallel}小节)。
-
来自综合征统计的噪声学习架构。 我们引入了一种基于AI的架构,该架构直接从实验可及的综合征统计中推断非相关和相关PyMatching的近最优边和超边权重,无需了解底层电路级噪声模型(第\ref{sec:EffectivePreDecNoiseModel}节)。该架构利用所有18种边类型和43种超边类型组合的码距无关概率公式,使在单个码距训练的模型能够推广到任意码距。应用于原始综合征数据时,学习权重几乎匹配非相关PyMatching性能,并相对于从已知噪声模型导出的权重改善了相关PyMatching的LER(第\ref{subsec:NoiseLearnImprove}小节)。
-
通过批处理减少资源。 我们表明,在并行块级解码方案中增加GPU批处理大小可以将实时解码所需的并行经典资源 N par N_{\text{par}} Npar 减少高达 12.5 × 12.5\times 12.5×,当在非常大的合并片上解码晶格手术操作时,这一考虑变得至关重要(第\ref{sec:BatchingImprove}节)。
3 表面码简要回顾
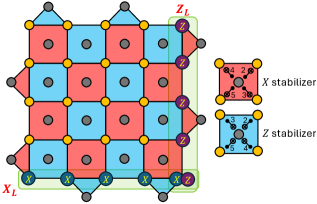
Figure 2: Example of a surface code patch for
d
=
5
d=5
d=5. Data qubits correspond to yellow vertices, whereas ancillas used to measure the stabilizers correspond to grey vertices.
X
(
Z
)
X (Z)
X(Z) stabilizers are represented by red (blue) plaquettes. Minimum-weight representatives for logical
X
L
(
Z
L
)
X_L (Z_L)
XL(ZL) observables are shown as horizontal (vertical) strings. We provide a gate scheduling such that weight-two errors arising from a single fault propagate perpendicular to its corresponding logical observable.
在整个工作中,我们使用表面码训练我们的模型。然而,第\ref{sec:PreDecArch}节中介绍的方法不特定于表面码,可以适应其他拓扑QEC码。为使表述尽可能自包含,我们首先简要回顾表面码并建立全文使用的符号。
表面码是一种二维拓扑量子纠错码,其稳定子可以使用最近邻相互作用测量,并且在电路级去极化噪声模型下表现出约 0.7 % 0.7\% 0.7% 的阈值。此外,通用容错量子计算可以仅通过最近邻相互作用经由晶格手术实现。因此,尽管开发了许多具有吸引力的理论性质的替代码,表面码仍然是近中期量子计算架构的领先候选者,特别是那些具有有限量子比特连接性的架构。
表面码由参数 [ [ d x d z , k , min ( d x , d z ) ] ] [\![ d_x d_z, k, \min(d_x,d_z) ]\!] [[dxdz,k,min(dx,dz)]] 表征,其中 k = 1 k=1 k=1 是编码逻辑量子比特的数量, d x d_x dx( d z d_z dz)表示逻辑 X X X( Z Z Z)算子的最小权重。在本工作中,我们关注 d x = d z = d d_x = d_z = d dx=dz=d 的方形片,尽管第\ref{sec:PreDecArch}节中介绍的方法自然地扩展到具有任意 d x d_x dx 和 d z d_z dz 的矩形片。 d = 5 d=5 d=5 表面码片的示例如图\ref{fig:SurfaceCodeExamp}所示。对于选定的片方向,逻辑算子 X L X_L XL 和 Z L Z_L ZL 的最小权重代表分别对应于水平弦和垂直弦。图\ref{fig:SurfaceCodeExamp}还说明了用于测量 X X X 和 Z Z Z 型稳定子的有效门调度,选择使得由单个故障产生的权重二错误垂直于其相应逻辑可观测量的方向传播。CNOT门旁显示的数字表示门应用的时间步,时间步1和6保留用于辅助态制备和测量。
我们将错误综合征定义为稳定子测量结果的集合。为区分类空间和类时错误,稳定子测量在多轮中重复。所需测量轮数取决于对类时逻辑失效的期望抑制程度,这对基于晶格手术的协议特别相关。在整个工作中,错误综合征被理解为包括所有综合征测量轮的稳定子测量结果。我们将第
k
k
k 轮
X
X
X 和
Z
Z
Z 型稳定子的测量综合征分别记为
SynX
(
k
)
\text{SynX}^{(k)}
SynX(k) 和
SynZ
(
k
)
\text{SynZ}^{(k)}
SynZ(k),并定义完整综合征为
Syn
=
(
SynX
(
1
)
,
SynZ
(
1
)
,
⋯
,
SynX
(
d
m
)
,
SynZ
(
d
m
)
)
\text{Syn} = (\text{SynX}^{(1)},\text{SynZ}^{(1)}, \cdots, \text{SynX}^{(d_m)},\text{SynZ}^{(d_m)})
Syn=(SynX(1),SynZ(1),⋯,SynX(dm),SynZ(dm))
解码算法处理
Syn
\text{Syn}
Syn 以推断可能的错误配置。两种广泛使用的表面码解码器是最小权重完美匹配(MWPM)和并查集(UF)。重要的是,两种解码器的运行时间都取决于综合征密度
s
s
s。对于
d
m
d_m
dm 轮测量和每轮
S
(
d
)
=
d
2
−
1
S(d)=d^2-1
S(d)=d2−1 个稳定子,我们定义
s
=
∣
Syn
∣
/
(
d
m
S
(
d
)
)
s = |\text{Syn}| / (d_m S(d))
s=∣Syn∣/(dmS(d))
其中 ∣ Syn ∣ |\text{Syn}| ∣Syn∣ 表示非平凡检测事件的数量。MWPM的解码复杂度按 O ( s 3 ) \mathcal{O}(s^3) O(s3) 缩放,而UF按 O ( s ) \mathcal{O}(s) O(s) 缩放。尽管UF提供更快的运行时间,MWPM通常实现更低的逻辑错误率。相比之下,基于AI的解码器具有与 s s s 无关的固定复杂度。
如文献所示,当使用滑动窗口方法解码一系列综合征测量轮时,如果每轮解码时间
T
DEC
T_{\text{DEC}}
TDEC 超过测量稳定子所需的时间
T
s
T_s
Ts,则会产生指数级积压。在文献中,更新Pauli框架的等待时间作为电路深度的函数被导出为
T
b
j
=
c
j
r
T
s
j
−
1
+
T
l
[
T
s
1
−
j
(
c
j
−
T
s
j
)
c
−
T
s
]
,
(1)
T^{b_j} = \frac{c^j r}{T_s^{j-1}} + T_l\Big[ \frac{T_s^{1-j}(c^j - T_s^j)}{c - T_s} \Big], \tag{1}
Tbj=Tsj−1cjr+Tl[c−TsTs1−j(cj−Tsj)],(1)
其中 T l T_l Tl 表示将测量的稳定子传输到经典处理设备的运行时间。方程(1)假设线性时间解码器, T DEC ( r ) = c r T_{\text{DEC}}(r) = c r TDEC(r)=cr,其中 c c c 是依赖于码距 d d d 的常数, r r r 是综合征测量轮数。
为缓解
T
DEC
>
T
s
T_{\text{DEC}} > T_s
TDEC>Ts 时的指数积压,文献引入了并行窗口解码策略。 syndrome测量历史被划分为大小为
d
m
d_m
dm 的提交区域,每个提交区域前后放置等大小的缓冲区域。所有提交区域并行解码,剩余的清理区域同样可以划分为并发解码的块。文献表明,只要并行解码资源数量
N
par
N_{\text{par}}
Npar 满足
N
par
≥
2
T
DEC
(
T
l
+
T
s
)
(
n
com
+
n
W
)
,
(2)
N_{\text{par}} \ge \frac{2 T_{\text{DEC}}}{(T_l + T_s)(n_{\text{com}} + n_W)}, \tag{2}
Npar≥(Tl+Ts)(ncom+nW)2TDEC,(2)
就可以避免指数积压,其中 n com n_{\text{com}} ncom 是提交区域中的综合征测量轮数, n W n_W nW 是每个缓冲区域的轮数。然而,即使在此并行化设置中,整体算法运行时间仍然强烈依赖于 T DEC T_{\text{DEC}} TDEC。在第\ref{sec:PreDecArch}节中,我们介绍了一种预解码架构,该架构在GPU上实现快速执行并显著降低综合征密度 s s s,从而在组合全局算法解码器(如MWPM或并查集)时最小化 T DEC T_{\text{DEC}} TDEC。
4 预解码器架构
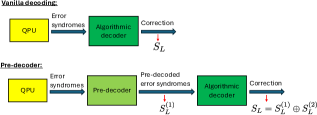
Figure 3: In a vanilla decoding algorithm, an algorithmic decoder receives the error syndromes from the QPU and performs corrections to determine the signs
S
L
S_L
SL of the relevant logical observables. When using a pre-decoder, the pre-decoder receives the error syndrome from the QPU and applies spacelike and timelike corrections across all syndrome measurement rounds that were used as inputs. Such corrections produce the signs
S
L
(
1
)
S_L^{(1)}
SL(1) of the logical observables. The new error syndrome obtained from the corrections are then passed to an algorithmic decoder to apply the final set of corrections resulting in a sign
S
L
(
2
)
S_L^{(2)}
SL(2) of the logical observables. The final sign is computed as
S
L
=
S
L
(
1
)
⊕
S
L
(
2
)
S_L=S_L^{(1)} \oplus S_L^{(2)}
SL=SL(1)⊕SL(2).
4.1 使用预解码器的动机
如第\ref{sec:SurfaceCodeReview}节所述,算法解码器(如最小权重完美匹配MWPM或并查集UF)的解码时间 T DEC T_{\text{DEC}} TDEC 强烈依赖于综合征密度 s s s。综合征密度本身由诸如底层噪声模型和用于综合征提取的电路等因素决定。这种依赖性在接近错误阈值时变得尤为显著,其中 s s s 可能很大——特别是对于MWPM,其运行时间按 T DEC ∝ O ( s 3 ) T_{\text{DEC}} \propto \mathcal{O}(s^3) TDEC∝O(s3) 缩放。因此,通过在全局解码之前降低有效综合征密度,可以实现解码运行时间的实质性减少。
使用第\ref{sec:SurfaceCodeReview}节中引入的定义,单独使用算法解码器处理
r
r
r 轮综合征测量所需的总时间为
T
tot
(
al
)
(
r
,
s
)
=
T
s
+
T
l
+
T
DEC
(
a
l
)
(
r
,
s
)
,
(3)
T^{(\text{al})}_{\text{tot}}(r,s) = T_s + T_l + T^{(al)}_{\text{DEC}}(r,s), \tag{3}
Ttot(al)(r,s)=Ts+Tl+TDEC(al)(r,s),(3)
其中 T DEC ( a l ) ( r , s ) T^{(al)}_{\text{DEC}}(r,s) TDEC(al)(r,s) 表示以综合征密度 s s s 解码 r r r 轮所需的时间。
可以通过引入基于AI的预解码器来降低综合征密度,该预解码器在测量综合征的时空体积上执行局部校正。所得混合解码流水线——由预解码器和全局算法解码器组成——如图\ref{fig:PreDecOverview}所示。局部时空校正使用全卷积三维神经网络实现,如第\ref{subsec:NNArchHyperParam}小节所述。
设
T
l
1
T_{l_1}
Tl1 表示将测量综合征从量子处理单元(QPU)传输到实现预解码器的经典设备所需的时间,设
T
l
2
T_{l_2}
Tl2 表示将更新后的综合征从预解码器传输到实现全局解码器的设备所需的时间。在此设置中,处理
r
r
r 轮综合征测量的总时间为
T
tot
(
pra
)
(
r
,
s
)
=
T
s
+
T
l
1
+
T
DEC
(
pre
)
(
r
)
+
T
l
2
+
T
DEC
(
a
l
)
(
r
,
s
′
)
,
(4)
T^{(\text{pra})}_{\text{tot}}(r,s) = T_s + T_{l_1} + T^{(\text{pre})}_{\text{DEC}}(r)+ T_{l_2} + T^{(al)}_{\text{DEC}}(r,s'), \tag{4}
Ttot(pra)(r,s)=Ts+Tl1+TDEC(pre)(r)+Tl2+TDEC(al)(r,s′),(4)
其中 T DEC ( pre ) ( r ) T^{(\text{pre})}_{\text{DEC}}(r) TDEC(pre)(r) 是预解码器运行时间, s ′ s' s′ 是应用预解码器后从 s s s 获得的降低综合征密度。至关重要的是,由于其基于AI的实现, T DEC ( pre ) ( r ) T^{(\text{pre})}_{\text{DEC}}(r) TDEC(pre)(r) 与输入综合征密度 s s s 无关。
比较方程(3)和(4),当满足以下条件时实现净加速:
T
tot
(
pra
)
(
r
,
s
)
<
T
tot
(
al
)
(
r
,
s
)
.
T^{(\text{pra})}_{\text{tot}}(r,s) < T^{(\text{al})}_{\text{tot}}(r,s).
Ttot(pra)(r,s)<Ttot(al)(r,s).
换言之,当源于更低综合征密度 s ′ s' s′ 的全局解码时间减少超过预解码和额外通信引入的开销时,预解码的开销就被抵消了。在第\ref{subsec:GPURuntimes}小节中,我们在NVIDIA GB300 GPU上提供了一系列时空体积的 T DEC ( pre ) ( r ) T^{(\text{pre})}_{\text{DEC}}(r) TDEC(pre)(r) 和 T tot ( pra ) ( r , s ) T^{(\text{pra})}_{\text{tot}}(r,s) Ttot(pra)(r,s) 的详细运行时间估计。
4.2 神经网络架构和超参数

Figure 4: Example of a four-layer fully connected three-dimensional convolutional neural network used to train our AI-based pre-decoder. The first three layers use
n
f
=
128
n_f=128
nf=128 filters with three-dimensional kernels of size (3,3,3). The final layer always uses four filters since the network has 4 output correction channels.
在本小节中,我们描述用于构建基于AI的预解码器的神经网络架构,并总结产生最优性能的训练超参数。
我们的基于AI的预解码器实现为全卷积三维神经网络,意味着它仅由3D卷积层组成,不使用线性或投影层。这种全卷积设计确保网络输出在每个通道上具有与其输入相同的时空维度,从而能够在综合征数据的整个时空体积上应用局部校正。
此架构的一个关键优势是其可扩展性:网络可以在大小为 ( d , d , d m ) (d,d,d_m) (d,d,dm) 的输入体积上训练,并在推理时应用于大小为 ( d ′ , d ′ , d m ′ ) (d',d',d'_m) (d′,d′,dm′) 的体积,其中 d ≠ d ′ d \neq d' d=d′ 且 d m ≠ d m ′ d_m \neq d'_m dm=dm′。具有四个3D卷积层的示例架构如图\ref{fig:ConvArch}所示,其中每层由其三维核大小和滤波器数量指定。最后一层始终使用四个滤波器,对应于下面描述的四个输出通道。
更深的架构需要跳跃连接以避免梯度消失,这在文献中已有探索。虽然本工作的主要关注点是最小化预解码器运行时间,但我们也在第\ref{subsec:SynDensLERCorrMatch}小节中考虑它们以实现进一步的LER改进。
3D卷积网络的一个重要架构参数是感受野,它量化影响给定输出元素的输入局部三维窗口的大小。感受野在确定预解码器的最大有效解码距离方面起着核心作用,因为空间或时间范围大于感受野的错误链通常无法仅通过局部操作完全校正。
考虑具有
l
l
l 个卷积层的网络,其中第
j
j
j 层的核大小为
(
k
j
,
k
j
,
k
j
)
(k_j, k_j, k_j)
(kj,kj,kj)。假设所有层使用步幅1和膨胀系数
D
=
1
D=1
D=1,感受野由下式给出
R
l
=
1
+
∑
i
=
1
l
(
k
i
−
1
)
.
(5)
R_l = 1 + \sum_{i=1}^l (k_i - 1). \tag{5}
Rl=1+i=1∑l(ki−1).(5)
因此,可以通过增加层数或使用更大的卷积核来增加感受野。然而,如第\ref{subsec:GPURuntimes}小节所示,增加核大小比增加深度导致 T DEC ( pre ) ( r ) T^{(\text{pre})}_{\text{DEC}}(r) TDEC(pre)(r) 的显著更大增加,这促使了本工作采用的架构选择。
4.2.1 输入训练数据
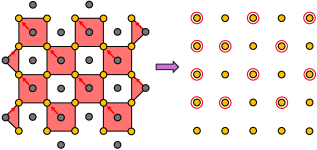
(a)
(b)
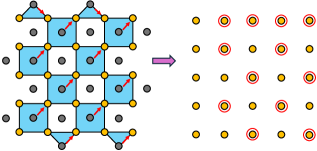
Figure 5: (a) Example mapping of X X X-type stabilizers to a D × D D×D D×D grid (with D = 5 D=5 D=5). For any D D D, measurement outcomes of weight-four X X X-type stabilizers are mapped to the top-left data qubit in its support. Weight-two stabilizers on the left or right boundary are mapped to the top data in its support. (b) Similar mapping as in (a) but for Z Z Z-type stabilizers.
在本小节中,我们描述用于训练神经网络的结构。贯穿全文,表示输入和输出训练数据的张量分别记为 trainX 和 trainY。
为使神经网络能够识别由重复稳定子测量引起的类空间和类时错误,必须在每轮测量中将测量综合征高效编码在二维网格上。此外,晶格边界附近的稳定子统计与体内部不同。为考虑这一点,我们为网络提供显式的几何信息,编码稳定子位置及其相应权重(标准表面码片上为二或四),如下所述。
考虑嵌入在 D × D D \times D D×D 网格上的表面码片,其中 D D D 表示沿任意行或列的数据量子比特(图\ref{fig:SurfaceCodeExamp}中的黄色顶点)的最大数量。假设生成了 N train N_{\text{train}} Ntrain 个训练样本。对于每个样本 1 ≤ j ≤ N train 1 \le j \le N_{\text{train}} 1≤j≤Ntrain,稳定子测量进行 d m d_m dm 轮综合征测量。对于电路中的每个故障位置,根据底层噪声模型采样错误并通过电路传播。
错误传播后,我们存储(i)连续轮之间数据量子比特错误的差异(以及类时失效,更多内容见第\ref{subsec:OutputTrain}小节)和(ii)连续轮之间稳定子测量结果的差异,通常称为检测器事件。设
s
i
,
k
s_{i,k}
si,k 表示第
i
i
i 个稳定子在第
k
k
k 轮的测量结果。相应的检测器事件定义为
d
i
,
k
=
s
i
,
k
⊕
s
i
,
k
−
1
d_{i,k} = s_{i,k} \oplus s_{i,k-1}
di,k=si,k⊕si,k−1
第
k
k
k 轮和第
j
j
j 个训练样本中所有
X
X
X 型稳定子的检测器事件收集为
D
k
(
j
)
(
X
)
≡
(
d
1
,
k
(
X
)
,
…
,
d
K
x
,
k
(
X
)
)
,
D^{(j)}_k(X) \equiv (d_{1,k}(X), \ldots, d_{K_x,k}(X)),
Dk(j)(X)≡(d1,k(X),…,dKx,k(X)),
其中对于
d
x
=
d
z
=
D
d_x = d_z = D
dx=dz=D 的表面码,
X
X
X 稳定子的数量为
K
x
=
(
D
2
−
1
)
/
2
K_x = (D^2 - 1)/2
Kx=(D2−1)/2。类似地,
Z
Z
Z 型稳定子的检测器事件由下式给出
D
k
(
j
)
(
Z
)
≡
(
d
1
,
k
(
Z
)
,
…
,
d
K
z
,
k
(
Z
)
)
.
D^{(j)}_k(Z) \equiv (d_{1,k}(Z), \ldots, d_{K_z,k}(Z)).
Dk(j)(Z)≡(d1,k(Z),…,dKz,k(Z)).
设
E
(
j
)
(
X
)
(
i
,
k
)
∈
{
I
,
X
}
E^{(j)}(X)_{(i,k)} \in \{I,X \}
E(j)(X)(i,k)∈{I,X} 表示第
j
j
j 个训练样本中第
k
k
k 轮影响第
i
i
i 个数据量子比特的
X
X
X 错误。我们定义连续轮之间的错误差异为
X
~
i
,
k
(
j
)
=
E
(
j
)
(
X
)
i
,
k
⊕
E
(
j
)
(
X
)
i
,
k
−
1
\tilde{X}^{(j)}_{i,k} = E^{(j)}(X)_{i,k} \oplus E^{(j)}(X)_{i,k-1}
X~i,k(j)=E(j)(X)i,k⊕E(j)(X)i,k−1
收集所有数据量子比特的这些差异得到
X
~
k
(
j
)
≡
(
X
~
(
1
,
k
)
(
j
)
,
…
,
X
~
(
D
2
,
k
)
(
j
)
)
.
\tilde{X}^{(j)}_k \equiv (\tilde{X}^{(j)}_{(1,k)}, \ldots, \tilde{X}^{(j)}_{(D^2,k)}).
X~k(j)≡(X~(1,k)(j),…,X~(D2,k)(j)).
Z
Z
Z 错误的类似定义适用,
Z
~
k
(
j
)
≡
(
Z
~
(
1
,
k
)
(
j
)
,
…
,
Z
~
(
D
2
,
k
)
(
j
)
)
,
\tilde{Z}^{(j)}_k \equiv (\tilde{Z}^{(j)}_{(1,k)}, \ldots, \tilde{Z}^{(j)}_{(D^2,k)}),
Z~k(j)≡(Z~(1,k)(j),…,Z~(D2,k)(j)),
它们一起构成训练期间使用的目标标签。
输入张量 trainX 的形状为
(
N
train
,
D
,
D
,
d
m
,
N
s
)
(N_{\text{train}}, D, D, d_m, N_s)
(Ntrain,D,D,dm,Ns),其中
N
s
N_s
Ns 表示输入通道数。对于本工作中考虑的量子存储设置,
N
s
=
4
N_s = 4
Ns=4,如下所述。在更一般的设置中——如晶格手术——需要额外的通道,导致
N
s
>
4
N_s > 4
Ns>4;这些扩展留给未来工作。
我们首先描述 trainX 的两个检测器事件通道,遵循文献中引入的编码方案。对于第
k
k
k 轮综合征测量和第
j
j
j 个训练样本,我们定义
trainX
(
j
,
1
:
D
,
1
:
D
,
k
,
1
)
=
x_type
(
k
,
j
)
,
trainX
(
j
,
1
:
D
,
1
:
D
,
k
,
2
)
=
z_type
(
k
,
j
)
,
\begin{aligned} \texttt{trainX}(j,1{:}D,1{:}D,k,1) &= \texttt{x\_type}(k,j), \\ \texttt{trainX}(j,1{:}D,1{:}D,k,2) &= \texttt{z\_type}(k,j), \end{aligned}
trainX(j,1:D,1:D,k,1)trainX(j,1:D,1:D,k,2)=x_type(k,j),=z_type(k,j),
其中 x_type ( k , j ) \texttt{x\_type}(k,j) x_type(k,j) 和 z_type ( k , j ) \texttt{z\_type}(k,j) z_type(k,j) 对应于映射到 D × D D \times D D×D 网格上的检测器事件 D k ( j ) ( X ) D^{(j)}_k(X) Dk(j)(X) 和 D k ( j ) ( Z ) D^{(j)}_k(Z) Dk(j)(Z)。
此映射过程的示例如图\ref{fig:StabMap}所示。权重四 X X X( Z Z Z)型稳定子的检测事件被映射到稳定子支撑中的左上(右上)数据量子比特。对于权重二稳定子, X X X 型检测事件映射到顶部数据量子比特,而 Z Z Z 型检测事件映射到右侧数据量子比特。如果稳定子结果在连续轮之间变化,则检测事件被赋值为1,否则为0。没有接收检测事件的网格位置始终设为0。
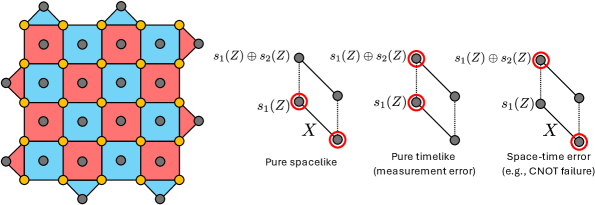
Figure 6: Example illustrations of the computation of
s
1
(
Z
)
⊕
s
2
(
Z
)
s_1(Z)\oplus s_2(Z)
s1(Z)⊕s2(Z) used in Algorithm 1. Only pure timelike and space-time failures result in a non-trivial value for
s
1
(
Z
)
⊕
s
2
(
Z
)
s_1(Z)\oplus s_2(Z)
s1(Z)⊕s2(Z). Red circles illustrate stabilizers that are measured as −1 instead of +1 (vertices without a red circle) in a given round.
除检测器事件外,我们使用相同的稳定子到量子比特映射编码局部几何信息。这些通道不映射检测事件,而是在相应网格位置编码归一化的稳定子权重。对于每轮 k k k,这些通道记为 x_present ( k ) \texttt{x\_present}(k) x_present(k) 和 z_present ( k ) \texttt{z\_present}(k) z_present(k)。
在逻辑量子比特初始化期间,如果逻辑量子比特初始化为 ∣ 0 ⟩ |0\rangle ∣0⟩( ∣ + ⟩ |+\rangle ∣+⟩),则 x_present ( 1 ) \texttt{x\_present}(1) x_present(1)( z_present ( 1 ) \texttt{z\_present}(1) z_present(1))的所有项设为零。类似地,在最终测量轮 k = d m k=d_m k=dm,当在 Z Z Z( X X X)基中测量时, x_present ( d m ) \texttt{x\_present}(d_m) x_present(dm)( z_present ( d m ) \texttt{z\_present}(d_m) z_present(dm))的所有项设为零。
对于图\ref{fig:StabMap}中所示的
D
=
5
D=5
D=5 表面码片,几何通道的形式为
x_present
(
k
)
=
[
1
0
1
0
0.5
0.5
1
0
1
0
1
0
1
0
0.5
0.5
1
0
1
0
0
0
0
0
0
]
,
\texttt{x\_present}(k) = \begin{bmatrix} 1 & 0 & 1 & 0 & 0.5 \\ 0.5 & 1 & 0 & 1 & 0 \\ 1 & 0 & 1 & 0 & 0.5 \\ 0.5 & 1 & 0 & 1 & 0 \\ 0 & 0 & 0 & 0 & 0 \end{bmatrix},
x_present(k)=
10.510.500101010100010100.500.500
,
z_present ( k ) = [ 0 0.5 1 0.5 1 0 1 0 1 0 0 0 1 0 1 0 1 0 1 0 0 0 0.5 0 0.5 ] , \texttt{z\_present}(k) = \begin{bmatrix} 0 & 0.5 & 1 & 0.5 & 1 \\ 0 & 1 & 0 & 1 & 0 \\ 0 & 0 & 1 & 0 & 1 \\ 0 & 1 & 0 & 1 & 0 \\ 0 & 0 & 0.5 & 0 & 0.5 \end{bmatrix}, z_present(k)= 000000.5101010100.50.5101010100.5 ,
对于
1
<
k
<
d
m
1 < k < d_m
1<k<dm。然后将这些通道并入 trainX 为
trainX
(
j
,
1
:
D
,
1
:
D
,
k
,
3
)
=
x_present
(
k
)
,
trainX
(
j
,
1
:
D
,
1
:
D
,
k
,
4
)
=
z_present
(
k
)
.
\begin{aligned} \texttt{trainX}(j,1{:}D,1{:}D,k,3) &= \texttt{x\_present}(k), \\ \texttt{trainX}(j,1{:}D,1{:}D,k,4) &= \texttt{z\_present}(k). \end{aligned}
trainX(j,1:D,1:D,k,3)trainX(j,1:D,1:D,k,4)=x_present(k),=z_present(k).
4.2.2 输出训练数据
我们现在描述用于训练预解码器的输出标签。为降低传递给全局解码器的综合征密度,预解码器必须同时执行类空间(数据量子比特)和类时(稳定子测量)校正。因此,训练目标编码两种类型的校正。
输出张量 trainY 由四个通道组成:两个通道对应于数据量子比特上的
Z
Z
Z 和
X
X
X 型Pauli校正,两个通道对应于
X
X
X 和
Z
Z
Z 型稳定子的类时校正。
我们首先描述 trainY 的前两个通道中的类空间输出通道。使用第\ref{eq:XerrorDiff}、\ref{eq:ZerrorDiff}方程中引入的错误差异定义,我们设置
trainY
(
j
,
1
:
D
,
1
:
D
,
k
,
1
)
=
Z
~
k
(
j
)
,
trainY
(
j
,
1
:
D
,
1
:
D
,
k
,
2
)
=
X
~
k
(
j
)
,
\begin{aligned} \texttt{trainY}(j,1{:}D,1{:}D,k,1) &= \tilde{Z}^{(j)}_{k}, \\ \texttt{trainY}(j,1{:}D,1{:}D,k,2) &= \tilde{X}^{(j)}_{k}, \end{aligned}
trainY(j,1:D,1:D,k,1)trainY(j,1:D,1:D,k,2)=Z~k(j),=X~k(j),
对于第 j j j 个训练样本和第 k k k 轮综合征测量。这些通道跟踪连续轮之间数据量子比特上 Z Z Z 和 X X X 型Pauli错误的变化,通过在噪声模型的每个电路位置采样故障并通过综合征提取电路传播它们获得。
剩余两个通道编码纯类时校正,对应于单个综合征测量轮内由故障引起的稳定子测量结果变化。由于数据量子比特在最后一轮被测量,类时校正仅对轮 k = 1 , … , d m − 1 k = 1, \ldots, d_m - 1 k=1,…,dm−1 定义。
为构建这些标签,我们通过比较在将相同错误配置通过额外一轮电路传播之前和之后获得的稳定子综合征,来隔离每个故障机制的类时分量,如算法\ref{Algo:TimelikeOutputGen}所述。

算法 1:类时输出通道生成
对于 k = 1 到 d_m - 1:
令 E_k 为第 k 轮综合征测量中噪声模型在每个故障位置生成的错误。
传播 E_k 并计算:
X 和 Z 稳定子综合征 s_1(X), s_1(Z)
令 E^{(k)}_{out} 为传播 E_k 后的输出数据量子比特错误。
传播 E^{(k)}_{out} 并计算:
X 和 Z 稳定子综合征 s_2(X), s_2(Z)
trainY(j,1:D,1:D,k,3) ← s_1(X) ⊕ s_2(X)
trainY(j,1:D,1:D,k,4) ← s_1(Z) ⊕ s_2(Z)
算法\ref{Algo:TimelikeOutputGen}中使用的 s 1 ( Z ) ⊕ s 2 ( Z ) s_1(Z) \oplus s_2(Z) s1(Z)⊕s2(Z) 计算的图示如图\ref{fig:trainYvisualAid}所示。直观上,两阶段传播程序通过消去跨轮持续的类空间效应来隔离给定综合征测量轮中故障的纯类时贡献。这些类时标签使预解码器能够学习抑制时间相关检测事件的局部校正,从而进一步降低传递给全局解码器的综合征密度。
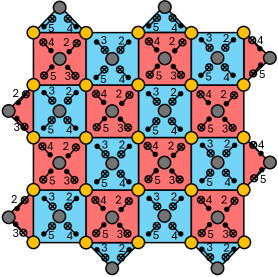
Figure 7: Circuit for a
d
=
5
d=5
d=5 surface code showing the CNOT gates and corresponding time steps used to generate our data. The time step
t
=
1
t=1
t=1 is used for preparing the ancillas (grey vertices) in the
∣
+
⟩
|+\rangle
∣+⟩ and
∣
0
⟩
|0\rangle
∣0⟩ basis. The time step
t
=
6
t=6
t=6 is for measuring the ancillas in the
X
X
X or
Z
Z
Z basis.
4.2.3 数据处理
在本小节中,我们描述在生成输出标签 trainY 期间应用的数据处理技术,以避免引入人工类时检测事件。此类伪影可能源于综合征提取电路中故障和稳定子测量的时间顺序。
为说明此效应,考虑图\ref{fig:CircuitMainCNOT}中所示的稳定子测量电路,其中CNOT门由其执行时间步标记。关注第
k
k
k 轮综合征测量,
k
>
1
k>1
k>1。假设在辅助量子比特测量期间的时间步6发生
Z
Z
Z 错误。受此错误影响的稳定子直到第
k
+
1
k+1
k+1 轮才被测量。然而,由于故障发生在第
k
k
k 轮,产生的数据量子比特错误可能被错误地分配到 trainY 中第
k
k
k 轮的类空间输出通道,而相应的综合征出现在 trainX 的第
k
+
1
k+1
k+1 轮。
更一般地,存在许多前导阶故障过程,其中数据量子比特错误在第 k k k 轮生成,但仅在第 k + 1 k+1 k+1 轮产生可检测的综合征信息。如果不仔细处理,此类过程会导致虚假的时空垂直对,人为地增加网络看到的类时事件数量。
为防止引入这些伪影,我们应用算法\ref{Algo:DataGenOptimize}中描述的数据生成协议。关键思想是仅在故障在同轮中产生非平凡稳定子综合征时才更新训练标签;否则,结果数据量子比特错误被推迟并视为下一轮中的输入错误。

算法 2:数据生成协议
对于 k = 1 到 d_m - 1:
令 E_k 为第 k 轮综合征测量中噪声模型在每个故障位置生成的完整故障集。
令 N_{E_k} 为 E_k 中的故障数量,e^{(k)}_j 表示第 j 个故障(1 ≤ j ≤ N_{E_k})。
对于 j = 1 到 N_{E_k}:
通过表面码稳定子测量电路传播 e^{(k)}_j。
令 s_{e^{(k)}_j} 为结果稳定子综合征。
令 |s_{e^{(k)}_j}| 表示 s_{e^{(k)}_j} 的汉明权重。
如果 |s_{e^{(k)}_j}| > 0:
按第4.2.1和4.2.2节描述更新 trainX 和 trainY。
否则:
如果 e^{(k)}_j 导致非平凡数据量子比特错误 e^{(k)}_{d_j}:
将 e^{(k)}_{d_j} 附加到 E_{k+1} 的时间步1,并忽略对 trainY 的更新。
处理包含 Y Y Y 错误的故障时需要额外注意。例如,数据量子比特上的单个 Y Y Y 错误可以在第 k k k 轮产生 X X X 型检测事件,在第 k + 1 k+1 k+1 轮产生 Z Z Z 型检测事件,导致混合的类空间–类时特征。为避免引入此类人工相关性,所有包含 Y Y Y 错误的故障在应用算法\ref{Algo:DataGenOptimize}之前被分解为等效的 X X X 和 Z Z Z only错误组合。
对于单量子比特故障,此分解是直接的,因为 Y = X ⊕ Z Y = X \oplus Z Y=X⊕Z 且两个分量可以独立传播。对于包含至少一个 Y Y Y 错误的双量子比特故障,情况更微妙但仍然是系统的。此类故障仅在CNOT门后出现,因此总是涉及一个数据量子比特和一个辅助量子比特。
分解被选择为使数据量子比特错误的
X
/
Z
X/Z
X/Z 内容与辅助量子比特可检测的错误类型相关联。例如,用于
X
X
X 稳定子测量的辅助量子比特检测
Z
Z
Z 错误。因此,形式为
Y
Y
Y(数据)
Z
Z
Z(辅助)的故障被分解为
Y
Z
→
Z
Z
⊕
X
I
,
YZ \to ZZ \oplus XI,
YZ→ZZ⊕XI,
其中每项独立传播。这确保检测事件在时间上正确定位。
本工作中使用的完整分解规则集总结在表\ref{tab:Ydecomp}中。分解后,每个结果故障被独立处理并根据算法\ref{Algo:DataGenOptimize}传播。
| Error | X-ancilla | Z-ancilla |
|---|---|---|
| YX | X I ⊕ Z I ⊕ I X XI \oplus ZI \oplus IX XI⊕ZI⊕IX | X X ⊕ Z I XX \oplus ZI XX⊕ZI |
| YZ | Z Z ⊕ X I ZZ \oplus XI ZZ⊕XI | X I ⊕ Z I ⊕ I Z XI \oplus ZI \oplus IZ XI⊕ZI⊕IZ |
| YY | Z Z ⊕ X I ⊕ I X ZZ \oplus XI \oplus IX ZZ⊕XI⊕IX | X X ⊕ Z I ⊕ I Z XX \oplus ZI \oplus IZ XX⊕ZI⊕IZ |
| XY | X I ⊕ I X ⊕ I Z XI \oplus IX \oplus IZ XI⊕IX⊕IZ | X X ⊕ I Z XX \oplus IZ XX⊕IZ |
| ZY | Z Z ⊕ I X ZZ \oplus IX ZZ⊕IX | Z I ⊕ I X ⊕ I Z ZI \oplus IX \oplus IZ ZI⊕IX⊕IZ |
表:包含 Y Y Y 错误的双量子比特故障的分解规则。第一个量子比特始终是数据量子比特,第二个是辅助量子比特。列区分辅助类型。
4.2.4 同调等价函数
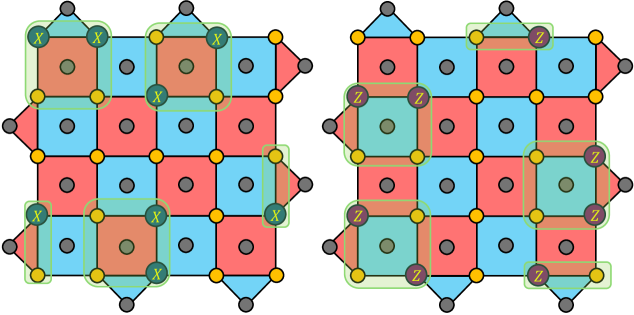
Figure 8: Spacelike homological equivalence convention as shown in a d=5 surface code lattice. On the left part of the figure, we show X error configurations which are invariant under the transformations of the functions weightReductionX and fixEquivalenceX. On the right part of the figure, we show Z error configurations which are invariant under the transformations of the functions weightReductionZ and fixEquivalnceZ.
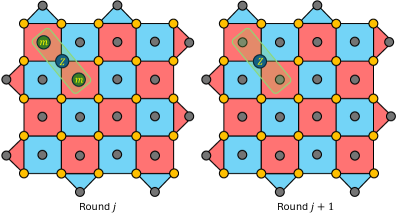
Figure 9: Timelike homological equivalence convention for a d=5 surface code. (a) For each data qubit in two consecutive syndrome measurement rounds, we apply a Z correction. Measurement errors that anti-commute with the Z error are added in the first round that a Z data qubit error is added. If the number of 1’s in trainY is reduced, we accept the trivial correction. (b) Same as (a) but with X corrections.
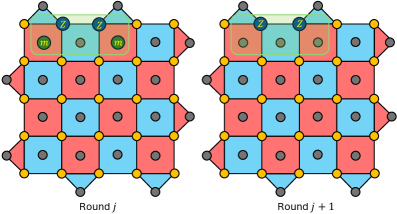
(a)
(b)
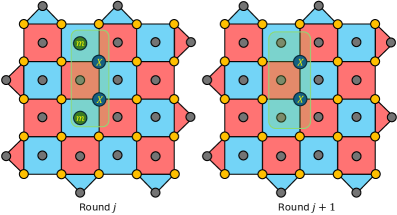
Figure 10: Timelike homological equivalence convention for a d=5 surface code for weight-two errors arising from a single fault. (a) For each weight-four Z-type stabilizer, after applying the fixEquivalenceZ function in two consecutive rounds, add a horizontal weight-two Z error in the direction set by fixEquivalenceZ in two consecutive syndrome measurement rounds, along with measurement errors on X-type stabilizers that anticommute with the Z errors in the first round the Z errors are introduced. Apply such corrections to trainY. If the number of 1’s in trainY is reduced, we accept the trivial correction. (b) Same as (a) but with X corrections, and where the weight-two X errors are added in the vertical direction.
作用于数据量子比特的许多错误配置在物理上是等价的。如果存在稳定子
g
∈
S
g \in \mathcal{S}
g∈S 使得
E
1
=
g
E
2
,
E_1 = gE_2,
E1=gE2,
我们说两个Pauli错误 E 1 E_1 E1 和 E 2 E_2 E2 是同调等价的,其中 S \mathcal{S} S 表示表面码的稳定子群。为降低标记训练数据的复杂性并从而提高训练性能,我们在每个同调等价类内固定一个规范代表选择。在下文中,所有变换都被选择为保持诱导的综合征历史和错误的逻辑等价类。
我们首先描述类空间同调等价协议,紧密遵循文献。然后我们引入一个补充的类时同调等价协议,简化连续综合征测量轮之间的标签结构。
对于类空间协议,考虑图\ref{fig:Homological_equiv}中红色方块表示的权重四
X
X
X 型稳定子
g
k
(
X
)
g_k(X)
gk(X)。任何在
g
k
(
X
)
g_k(X)
gk(X) 上支撑的权重三
X
X
X 错误
E
3
E_3
E3 可以通过乘以稳定子来降低为权重一错误,即通过形成
g
k
(
X
)
E
3
g_k(X)E_3
gk(X)E3。类似地,在
g
k
(
X
)
g_k(X)
gk(X) 上支撑的权重四
X
X
X 错误等价于
g
k
(
X
)
g_k(X)
gk(X) 本身,因此可以完全移除。我们定义函数 weightReductionX 在所有相关稳定子上应用这些权重降低变换。此外,weightReductionX 移除沿表面码片左右边界支撑的权重二
X
X
X 稳定子上的权重二
X
X
X 错误。
接下来,设
E
x
E_x
Ex 为在权重四稳定子
g
k
(
X
)
g_k(X)
gk(X) 上支撑的权重二
X
X
X 错误,其左上数据量子比特在
D
×
D
D \times D
D×D 网格上的坐标为
(
α
,
β
)
(\alpha,\beta)
(α,β)(
α
\alpha
α 表示行索引,
β
\beta
β 表示列索引)。我们通过以下规范化规则定义 fixEquivalenceX:
- 垂直
X
X
X 链: 如果
E
x
E_x
Ex 在
(
α
,
β
)
(\alpha,\beta)
(α,β) 和
(
α
+
1
,
β
)
(\alpha+1,\beta)
(α+1,β) 上支撑,则
fixEquivalenceX将其映射到 ( α , β + 1 ) (\alpha,\beta+1) (α,β+1) 和 ( α + 1 , β + 1 ) (\alpha+1,\beta+1) (α+1,β+1)。 - 水平
X
X
X 链: 如果
E
x
E_x
Ex 在
(
α
+
1
,
β
)
(\alpha+1,\beta)
(α+1,β) 和
(
α
+
1
,
β
+
1
)
(\alpha+1,\beta+1)
(α+1,β+1) 上支撑,则
fixEquivalenceX将其映射到 ( α , β ) (\alpha,\beta) (α,β) 和 ( α , β + 1 ) (\alpha,\beta+1) (α,β+1)。 - 对角
X
X
X 链: 如果
E
x
E_x
Ex 在
(
α
,
β
)
(\alpha,\beta)
(α,β) 和
(
α
+
1
,
β
+
1
)
(\alpha+1,\beta+1)
(α+1,β+1) 上支撑,则
fixEquivalenceX将其映射到 ( α , β + 1 ) (\alpha,\beta+1) (α,β+1) 和 ( α + 1 , β ) (\alpha+1,\beta) (α+1,β)。
边界稳定子需要特殊处理。设
g
k
(
X
)
g_k(X)
gk(X) 为沿左边界分布的权重二
X
X
X 稳定子,其支撑中最上方的量子比特位于坐标
(
α
,
β
)
(\alpha,\beta)
(α,β)。如果
E
x
E_x
Ex 是在
(
α
+
1
,
β
)
(\alpha+1,\beta)
(α+1,β) 处的权重一错误,则 fixEquivalenceX 将其映射到
(
α
,
β
)
(\alpha,\beta)
(α,β)。相反,如果
g
k
(
X
)
g_k(X)
gk(X) 是沿右边界分布的权重二
X
X
X 稳定子,最上方量子比特在
(
α
,
β
)
(\alpha,\beta)
(α,β),则在
(
α
,
β
)
(\alpha,\beta)
(α,β) 的权重一错误被映射到
(
α
+
1
,
β
)
(\alpha+1,\beta)
(α+1,β)。这些映射在图\ref{fig:Homological_equiv}的左侧说明。
我们现在定义 simplifyX 为在所有
X
X
X 型稳定子上依次应用 weightReductionX 和 fixEquivalenceX。函数 simplifyX 迭代应用直至收敛。具体地,设
M
e
(
X
α
,
β
)
(
j
)
M_e^{(X_{\alpha,\beta})}(j)
Me(Xα,β)(j) 为表示第
j
j
j 轮综合征测量中
X
X
X 错误的二元矩阵,其中
M
e
(
X
α
,
β
)
(
j
)
=
1
M_e^{(X_{\alpha,\beta})}(j)=1
Me(Xα,β)(j)=1 表示在
(
α
,
β
)
(\alpha,\beta)
(α,β) 处的
X
X
X 错误,否则为0。我们应用 simplifyX 直到
simplifyX
(
M
e
(
X
α
,
β
)
(
j
)
)
=
M
e
(
X
α
,
β
)
(
j
)
,
\texttt{simplifyX}(M_e^{(X_{\alpha,\beta})}(j)) = M_e^{(X_{\alpha,\beta})}(j),
simplifyX(Me(Xα,β)(j))=Me(Xα,β)(j),
对于所有 1 ≤ j ≤ d m 1 \le j \le d_m 1≤j≤dm 和 D × D D \times D D×D 网格上的所有坐标 ( α , β ) (\alpha,\beta) (α,β)。
对于
Z
Z
Z 型数据量子比特错误,我们类似地定义 weightReductionZ。设
E
z
E_z
Ez 为在权重四
Z
Z
Z 稳定子
g
k
(
Z
)
g_k(Z)
gk(Z) 上支撑的权重二
Z
Z
Z 错误,其左上数据量子比特坐标为
(
α
,
β
)
(\alpha,\beta)
(α,β)。函数 fixEquivalenceZ 实现以下变换:
- 垂直链: 如果
E
z
E_z
Ez 在
(
α
,
β
)
(\alpha,\beta)
(α,β) 和
(
α
+
1
,
β
)
(\alpha+1,\beta)
(α+1,β) 上支撑,则
fixEquivalenceZ将其映射到 ( α , β + 1 ) (\alpha,\beta+1) (α,β+1) 和 ( α + 1 , β + 1 ) (\alpha+1,\beta+1) (α+1,β+1)。 - 水平链: 如果
E
z
E_z
Ez 在
(
α
+
1
,
β
)
(\alpha+1,\beta)
(α+1,β) 和
(
α
+
1
,
β
+
1
)
(\alpha+1,\beta+1)
(α+1,β+1) 上支撑,则
fixEquivalenceZ将其映射到 ( α , β ) (\alpha,\beta) (α,β) 和 ( α , β + 1 ) (\alpha,\beta+1) (α,β+1)。 - 对角链: 如果
E
z
E_z
Ez 在
(
α
,
β
+
1
)
(\alpha,\beta+1)
(α,β+1) 和
(
α
+
1
,
β
)
(\alpha+1,\beta)
(α+1,β) 上支撑,则
fixEquivalenceZ将其映射到 ( α , β ) (\alpha,\beta) (α,β) 和 ( α + 1 , β + 1 ) (\alpha+1,\beta+1) (α+1,β+1)。
对于边界权重二 Z Z Z 稳定子,如果 g k ( Z ) g_k(Z) gk(Z) 沿上边界分布,最左量子比特在 ( α , β ) (\alpha,\beta) (α,β),则在 ( α , β ) (\alpha,\beta) (α,β) 的权重一错误被映射到 ( α , β + 1 ) (\alpha,\beta+1) (α,β+1)。如果 g k ( Z ) g_k(Z) gk(Z) 沿下边界分布,最左量子比特在 ( α , β ) (\alpha,\beta) (α,β),则在 ( α , β + 1 ) (\alpha,\beta+1) (α,β+1) 的权重一错误被映射到 ( α , β ) (\alpha,\beta) (α,β)。这些映射显示在图\ref{fig:Homological_equiv}的右侧。
然后我们定义 simplifyZ 为应用 weightReductionZ 后接 fixEquivalenceZ,迭代直至
Z
Z
Z 错误稳态。
在对所有综合征测量轮独立应用类空间同调等价协议后,我们应用一个简化连续轮之间标签结构的类时同调等价协议。假设有
d
m
d_m
dm 轮综合征测量和
d
2
d^2
d2 个数据量子比特。设
t
t
t 索引训练样本,
1
≤
t
≤
N
train
1 \le t \le N_{\text{train}}
1≤t≤Ntrain。对于连续轮
k
k
k 和
k
+
1
k+1
k+1,我们定义
t
Y
1
(
1
)
(
k
)
=
trainY
(
t
,
j
1
(
1
)
,
j
1
(
2
)
,
k
,
1
)
,
t
Y
1
(
3
)
(
k
)
=
trainY
(
t
,
s
x
(
j
1
)
,
s
y
(
j
1
)
,
k
,
3
)
,
t
Y
2
(
3
)
(
k
)
=
trainY
(
t
,
s
x
(
j
2
)
,
s
y
(
j
2
)
,
k
,
3
)
,
t
p
Y
1
(
1
)
(
k
)
=
trainY
(
t
,
j
1
(
1
)
,
j
1
(
2
)
,
k
,
1
)
⊕
1
,
t
p
Y
1
(
3
)
(
k
)
=
trainY
(
t
,
s
x
(
j
1
)
,
s
y
(
j
1
)
,
k
,
3
)
⊕
1
,
t
p
Y
2
(
3
)
(
k
)
=
trainY
(
t
,
s
x
(
j
2
)
,
s
y
(
j
2
)
,
k
,
3
)
⊕
1
,
\begin{aligned} t^{(1)}_{Y_1}(k) &= \texttt{trainY}(t,j_1^{(1)},j_1^{(2)},k,1), \\ t^{(3)}_{Y_1}(k) &= \texttt{trainY}(t,s^{(j_1)}_x,s^{(j_1)}_y,k,3), \\ t^{(3)}_{Y_2}(k) &= \texttt{trainY}(t,s^{(j_2)}_x,s^{(j_2)}_y,k,3), \\ t^{(1)}_{p_{Y_1}}(k) &= \texttt{trainY}(t,j_1^{(1)},j_1^{(2)},k,1) \oplus 1, \\ t^{(3)}_{p_{Y_1}}(k) &= \texttt{trainY}(t,s^{(j_1)}_x,s^{(j_1)}_y,k,3) \oplus 1, \\ t^{(3)}_{p_{Y_2}}(k) &= \texttt{trainY}(t,s^{(j_2)}_x,s^{(j_2)}_y,k,3) \oplus 1, \end{aligned}
tY1(1)(k)tY1(3)(k)tY2(3)(k)tpY1(1)(k)tpY1(3)(k)tpY2(3)(k)=trainY(t,j1(1),j1(2),k,1),=trainY(t,sx(j1),sy(j1),k,3),=trainY(t,sx(j2),sy(j2),k,3),=trainY(t,j1(1),j1(2),k,1)⊕1,=trainY(t,sx(j1),sy(j1),k,3)⊕1,=trainY(t,sx(j2),sy(j2),k,3)⊕1,
其中 ( j 1 ( 1 ) , j 1 ( 2 ) ) (j_1^{(1)},j_1^{(2)}) (j1(1),j1(2)) 是数据量子比特 q j ( 1 ) q_j^{(1)} qj(1) 的坐标,与 q j ( 1 ) q_j^{(1)} qj(1) 反对易的稳定子坐标为 ( s x ( j 1 ) , s y ( j 1 ) ) (s^{(j_1)}_x,s^{(j_1)}_y) (sx(j1),sy(j1)) 和 ( s x ( j 2 ) , s y ( j 2 ) ) (s^{(j_2)}_x,s^{(j_2)}_y) (sx(j2),sy(j2))。如果单个稳定子与 q j ( 1 ) q_j^{(1)} qj(1) 反对易,我们设 t Y 2 ( 3 ) ( k ) = 0 t^{(3)}_{Y_2}(k)=0 tY2(3)(k)=0 和 t p Y 2 ( 3 ) ( k ) = 0 t^{(3)}_{p_{Y_2}}(k)=0 tpY2(3)(k)=0。
我们进一步定义
s
Y
(
k
)
=
t
Y
1
(
1
)
(
k
)
+
t
Y
1
(
3
)
(
k
)
+
t
Y
2
(
3
)
(
k
)
,
s
Y
(
k
+
1
)
=
t
Y
1
(
1
)
(
k
+
1
)
+
t
Y
1
(
3
)
(
k
+
1
)
+
t
Y
2
(
3
)
(
k
+
1
)
,
s
p
Y
(
k
)
=
t
p
Y
1
(
1
)
(
k
)
+
t
p
Y
1
(
3
)
(
k
)
+
t
p
Y
2
(
3
)
(
k
)
,
s
p
Y
(
k
+
1
)
=
t
p
Y
1
(
1
)
(
k
+
1
)
+
t
Y
1
(
3
)
(
k
+
1
)
+
t
Y
2
(
3
)
(
k
+
1
)
,
\begin{aligned} s_Y(k) &= t^{(1)}_{Y_1}(k) + t^{(3)}_{Y_1}(k) + t^{(3)}_{Y_2}(k), \\ s_Y(k+1) &= t^{(1)}_{Y_1}(k+1) + t^{(3)}_{Y_1}(k+1) + t^{(3)}_{Y_2}(k+1), \\ s_{p_Y}(k) &= t^{(1)}_{p_{Y_1}}(k) + t^{(3)}_{p_{Y_1}}(k) + t^{(3)}_{p_{Y_2}}(k), \\ s_{p_Y}(k+1) &= t^{(1)}_{p_{Y_1}}(k+1) + t^{(3)}_{Y_1}(k+1) + t^{(3)}_{Y_2}(k+1), \end{aligned}
sY(k)sY(k+1)spY(k)spY(k+1)=tY1(1)(k)+tY1(3)(k)+tY2(3)(k),=tY1(1)(k+1)+tY1(3)(k+1)+tY2(3)(k+1),=tpY1(1)(k)+tpY1(3)(k)+tpY2(3)(k),=tpY1(1)(k+1)+tY1(3)(k+1)+tY2(3)(k+1),
以及
s
X
(
k
)
=
trainX
(
t
,
s
x
(
j
1
)
,
s
y
(
j
1
)
,
k
,
1
)
+
trainX
(
t
,
s
x
(
j
2
)
,
s
y
(
j
2
)
,
k
,
1
)
.
s_X(k) = \texttt{trainX}(t,s^{(j_1)}_x,s^{(j_1)}_y,k,1) + \texttt{trainX}(t,s^{(j_2)}_x,s^{(j_2)}_y,k,1).
sX(k)=trainX(t,sx(j1),sy(j1),k,1)+trainX(t,sx(j2),sy(j2),k,1).
最后,我们定义
s
max
=
max
(
s
Y
(
k
)
+
s
X
(
k
)
,
s
Y
(
k
+
1
)
+
s
X
(
k
+
1
)
)
,
s
max
(
HE
)
=
max
(
s
p
Y
(
k
)
+
s
X
(
k
)
,
s
p
Y
(
k
+
1
)
+
s
X
(
k
+
1
)
)
,
s
(
k
,
k
+
1
)
=
s
Y
(
k
)
+
s
X
(
k
)
+
s
Y
(
k
+
1
)
+
s
X
(
k
+
1
)
,
s
(
HE
)
(
k
,
k
+
1
)
=
s
p
Y
(
k
)
+
s
X
(
k
)
+
s
p
Y
(
k
+
1
)
+
s
X
(
k
+
1
)
.
\begin{aligned} s_{\text{max}} &= \max(s_Y(k) + s_X(k), s_Y(k+1) + s_X(k+1)), \\ s^{(\text{HE})}_{\text{max}} &= \max(s_{p_Y}(k) + s_X(k), s_{p_Y}(k+1) + s_X(k+1)), \\ s(k,k+1) &= s_Y(k) + s_X(k) + s_Y(k+1) + s_X(k+1), \\ s^{(\text{HE})}(k,k+1) &= s_{p_Y}(k) + s_X(k) + s_{p_Y}(k+1) + s_X(k+1). \end{aligned}
smaxsmax(HE)s(k,k+1)s(HE)(k,k+1)=max(sY(k)+sX(k),sY(k+1)+sX(k+1)),=max(spY(k)+sX(k),spY(k+1)+sX(k+1)),=sY(k)+sX(k)+sY(k+1)+sX(k+1),=spY(k)+sX(k)+spY(k+1)+sX(k+1).
单个数据量子比特
Z
Z
Z 校正的类时同调等价协议在算法\ref{Algo:TimelikeHomologicalEquivZ}中给出。相应的
X
X
X 校正协议通过在方程中将 trainY 的通道
(
1
,
3
)
(1,3)
(1,3) 替换为通道
(
2
,
4
)
(2,4)
(2,4) 获得。

算法 3:类时同调等价 Z Z Z
对于 k = 1 到 d_m - 1:
对于 j = 1 到 d^2:
令 q_j 为 d × d 网格上坐标为 (j_x,j_y) 的数据量子比特。
确定与 q_j 上 Z 错误反对易的稳定子集合 S_j。
如果 |S_j| = 1:
令稳定子坐标为 (s^{(j_1)}_x, s^{(j_1)}_y)。
设 t^{(3)}_{Y_2}(k) = 0 和 t^{(3)}_{p_{Y_2}}(k) = 0。
否则如果 |S_j| = 2:
令稳定子坐标为 (s^{(j_1)}_x, s^{(j_1)}_y) 和 (s^{(j_2)}_x, s^{(j_2)}_y)。
计算 s_max 和 s^{(HE)}_max。
计算 s(k,k+1) 和 s^{(HE)}(k,k+1)。
如果 s^{(HE)}(k,k+1) < s(k,k+1):
设置 trainY(t,j_1^{(1)},j_1^{(2)},k,1) = t^{(1)}_{p_{Y_1}}(k)
设置 trainY(t,s^{(j_1)}_x,s^{(j_1)}_y,k,3) = t^{(3)}_{p_{Y_1}}(k)
设置 trainY(t,s^{(j_2)}_x,s^{(j_2)}_y,k,3) = t^{(3)}_{p_{Y_2}}(k)
设置 trainY(t,j_1^{(1)},j_1^{(2)},k+1,1) = t^{(1)}_{p_{Y_1}}(k+1)
否则如果 s^{(HE)}(k,k+1) = s(k,k+1):
如果 s^{(HE)}_max > s_max:
(同上设置)
否则:
保持 trainY 不变
否则:
保持 trainY 不变
重复上述过程直到 trainY 中1的数量不再减少。
算法\ref{Algo:TimelikeHomologicalEquivZ}的图示如图\ref{fig:Timelike_Homological}所示。直观上,将
X
X
X 或
Z
Z
Z 错误应用于两个连续轮的同一数据量子比特——连同第一轮中与添加的错误反对易的稳定子上的测量错误——可以对应于平凡操作,因为未注册净综合征变化。利用这种自由度可以通过引入CNN更容易学习的额外结构来简化 trainY。
没有这种简化,在第
k
k
k 轮引入但被测量错误掩盖(因此仅在第
k
+
1
k+1
k+1 轮检测到)的错误仍将作为标签出现在第
k
k
k 轮的 trainY 中。这可能鼓励网络在错误的轮中应用校正,导致传递给全局解码器的残余类时失效。
算法\ref{Algo:TimelikeHomologicalEquivZ}关注两个连续轮之间的单数据量子比特错误。由于权重二数据量子比特错误也可以由单个故障产生,我们额外考虑协议的权重二扩展,其中包含由单个故障产生的所有权重二 Z Z Z(或 X X X)错误。此扩展的图示如图\ref{fig:Timelike_Homological_High}所示。

Figure 11: Sequence of operations for the complete homological equivalence protocol. We first apply the spacelike homological equivalence protocol, followed by the timelike homological equivalence protocol (for weight-one errors), and finally reapply the spacelike protocol as a cleanup step.
因此,完整的同调等价协议在迭代方案中结合了类空间和类时变换。我们首先对所有轮应用类空间同调等价,然后对权重一数据量子比特错误应用类时同调等价。由于类时变换可能为类空间简化创造新机会,我们执行最终的类空间通道作为清理步骤。此序列如图\ref{fig:HomologicalSequence}所示。
最后,我们注意到许多替代的同调等价函数选择是可能的;例如,参见文献中关于简化器操作的讨论。
4.2.5 损失函数
为训练预解码器网络,我们使用二元交叉熵(BCE)目标,因为模型预测类空间Pauli校正和类时综合征翻转的独立逐体素概率。具体地,网络产生四个输出通道,我们对每个通道应用sigmoid非线性以获得 [ 0 , 1 ] [0,1] [0,1] 中的概率。
对于
D
×
D
D \times D
D×D 网格上具有
d
m
d_m
dm 轮综合征测量的表面码片,设真实标签
Y
Y
Y 和模型输出
Y
^
\hat{Y}
Y^ 为
Y
∈
{
0
,
1
}
4
×
D
×
D
×
d
m
,
Y
^
∈
[
0
,
1
]
4
×
D
×
D
×
d
m
.
\begin{aligned} Y &\in \{0,1\}^{4 \times D \times D \times d_m}, \\ \hat{Y} &\in [0,1]^{4 \times D \times D \times d_m}. \end{aligned}
YY^∈{0,1}4×D×D×dm,∈[0,1]4×D×D×dm.
损失计算为所有通道和体素上BCE项的和,
L
B
C
E
(
Y
,
Y
^
)
=
∑
c
=
1
4
∑
α
=
1
D
∑
β
=
1
D
∑
k
=
1
d
m
[
−
Y
c
,
α
,
β
,
k
log
(
Y
^
c
,
α
,
β
,
k
)
−
(
1
−
Y
c
,
α
,
β
,
k
)
log
(
1
−
Y
^
c
,
α
,
β
,
k
)
]
,
\mathcal{L}_{\mathrm{BCE}}(Y,\hat{Y}) = \sum_{c=1}^{4} \sum_{\alpha=1}^{D} \sum_{\beta=1}^{D} \sum_{k=1}^{d_m} \Big[-Y_{c,\alpha,\beta,k}\log(\hat{Y}_{c,\alpha,\beta,k}) -(1-Y_{c,\alpha,\beta,k})\log(1-\hat{Y}_{c,\alpha,\beta,k})\Big],
LBCE(Y,Y^)=c=1∑4α=1∑Dβ=1∑Dk=1∑dm[−Yc,α,β,klog(Y^c,α,β,k)−(1−Yc,α,β,k)log(1−Y^c,α,β,k)],
这对应于每个体素每个通道一个BCE损失,总共 4 D 2 d m 4D^2 d_m 4D2dm 项。
4.2.6 推理步骤
我们现在描述使用第\ref{subsec:NNArchHyperParam}小节中方法获得的训练预解码器的推理过程。给定格式化为 trainX 的综合征数据,预解码器预测局部类空间和类时校正,然后用于在传递给全局解码器之前修改综合征历史。
设 out 表示训练预解码器的输出张量。对于第
j
j
j 次和第
k
k
k 轮综合征测量,
D
×
D
D \times D
D×D 网格上预测的类空间校正为
Z
corr
(
j
,
k
)
=
out
(
j
,
1
:
D
,
1
:
D
,
k
,
1
)
,
X
corr
(
j
,
k
)
=
out
(
j
,
1
:
D
,
1
:
D
,
k
,
2
)
.
\begin{aligned} Z_{\text{corr}}^{(j,k)} &= \texttt{out}(j,1{:}D,1{:}D,k,1), \\ X_{\text{corr}}^{(j,k)} &= \texttt{out}(j,1{:}D,1{:}D,k,2). \end{aligned}
Zcorr(j,k)Xcorr(j,k)=out(j,1:D,1:D,k,1),=out(j,1:D,1:D,k,2).
预测的类时稳定子校正为
SynX
corr
(
j
,
k
)
=
out
(
j
,
1
:
D
,
1
:
D
,
k
,
3
)
,
SynZ
corr
(
j
,
k
)
=
out
(
j
,
1
:
D
,
1
:
D
,
k
,
4
)
.
\begin{aligned} \text{SynX}_{\text{corr}}^{(j,k)} &= \texttt{out}(j,1{:}D,1{:}D,k,3), \\ \text{SynZ}_{\text{corr}}^{(j,k)} &= \texttt{out}(j,1{:}D,1{:}D,k,4). \end{aligned}
SynXcorr(j,k)SynZcorr(j,k)=out(j,1:D,1:D,k,3),=out(j,1:D,1:D,k,4).
设
SynX
(
j
,
k
)
\text{SynX}^{(j,k)}
SynX(j,k) 和
SynZ
(
j
,
k
)
\text{SynZ}^{(j,k)}
SynZ(j,k) 表示推理期间第
k
k
k 轮
X
X
X 和
Z
Z
Z 型稳定子的测量检测器事件。预测类空间校正引起的综合征为
S
X
(
j
,
k
)
=
M
X
(
Z
corr
(
j
,
k
)
)
,
S
Z
(
j
,
k
)
=
M
Z
(
X
corr
(
j
,
k
)
)
,
\begin{aligned} S^{(j,k)}_X &= M_X\Big( Z_{\text{corr}}^{(j,k)} \Big), \\ S^{(j,k)}_Z &= M_Z\Big( X_{\text{corr}}^{(j,k)} \Big), \end{aligned}
SX(j,k)SZ(j,k)=MX(Zcorr(j,k)),=MZ(Xcorr(j,k)),
其中 M X M_X MX 和 M Z M_Z MZ 将数据量子比特Pauli错误映射到相应的 X X X 和 Z Z Z 稳定子综合征。
如果 SynX corr ( j , k ) ( l ) = 1 \text{SynX}_{\text{corr}}^{(j,k)}(l)=1 SynXcorr(j,k)(l)=1,则第 l l l 个 X X X 稳定子的测量结果在第 k k k 和 k + 1 k+1 k+1 轮都被翻转。类似地,如果 SynZ corr ( j , k ) ( l ) = 1 \text{SynZ}_{\text{corr}}^{(j,k)}(l)=1 SynZcorr(j,k)(l)=1,则第 l l l 个 Z Z Z 稳定子的结果在第 k k k 和 k + 1 k+1 k+1 轮被翻转。这实现了预解码器预测的类时校正。
应用类空间和类时校正后,传递给全局解码器的残余综合征为
R
(
j
,
1
)
(
X
)
=
SynX
(
j
,
1
)
⊕
SynX
corr
(
j
,
1
)
⊕
S
X
(
j
,
1
)
,
R
(
j
,
k
>
1
)
(
X
)
=
SynX
(
j
,
k
)
⊕
SynX
corr
(
j
,
k
)
⊕
SynX
corr
(
j
,
k
−
1
)
⊕
S
X
(
j
,
k
)
,
R
(
j
,
1
)
(
Z
)
=
SynZ
(
j
,
1
)
⊕
SynZ
corr
(
j
,
1
)
⊕
S
Z
(
j
,
1
)
,
R
(
j
,
k
>
1
)
(
Z
)
=
SynZ
(
j
,
k
)
⊕
SynZ
corr
(
j
,
k
)
⊕
SynZ
corr
(
j
,
k
−
1
)
⊕
S
Z
(
j
,
k
)
.
\begin{aligned} R^{(j,1)}(X) &= \text{SynX}^{(j,1)} \oplus \text{SynX}_{\text{corr}}^{(j,1)} \oplus S^{(j,1)}_X, \\ R^{(j,k>1)}(X) &= \text{SynX}^{(j,k)} \oplus \text{SynX}_{\text{corr}}^{(j,k)} \oplus \text{SynX}_{\text{corr}}^{(j,k-1)} \oplus S^{(j,k)}_X, \\ R^{(j,1)}(Z) &= \text{SynZ}^{(j,1)} \oplus \text{SynZ}_{\text{corr}}^{(j,1)} \oplus S^{(j,1)}_Z, \\ R^{(j,k>1)}(Z) &= \text{SynZ}^{(j,k)} \oplus \text{SynZ}_{\text{corr}}^{(j,k)} \oplus \text{SynZ}_{\text{corr}}^{(j,k-1)} \oplus S^{(j,k)}_Z. \end{aligned}
R(j,1)(X)R(j,k>1)(X)R(j,1)(Z)R(j,k>1)(Z)=SynX(j,1)⊕SynXcorr(j,1)⊕SX(j,1),=SynX(j,k)⊕SynXcorr(j,k)⊕SynXcorr(j,k−1)⊕SX(j,k),=SynZ(j,1)⊕SynZcorr(j,1)⊕SZ(j,1),=SynZ(j,k)⊕SynZcorr(j,k)⊕SynZcorr(j,k−1)⊕SZ(j,k).
设
E
(
j
,
k
)
(
X
)
E^{(j,k)}(X)
E(j,k)(X) 和
E
(
j
,
k
)
(
Z
)
E^{(j,k)}(Z)
E(j,k)(Z) 表示第
k
k
k 轮引入的
X
X
X 和
Z
Z
Z 型数据量子比特错误(不包括前几轮累积的错误)。应用预解码器校正后的残余类空间错误为
R
e
(
j
,
k
)
(
Z
)
=
Z
corr
(
j
,
k
)
⊕
E
(
j
,
k
)
(
Z
)
,
R
e
(
j
,
k
)
(
X
)
=
X
corr
(
j
,
k
)
⊕
E
(
j
,
k
)
(
X
)
.
\begin{aligned} R^{(j,k)}_e(Z) &= Z_{\text{corr}}^{(j,k)} \oplus E^{(j,k)}(Z), \\ R^{(j,k)}_e(X) &= X_{\text{corr}}^{(j,k)} \oplus E^{(j,k)}(X). \end{aligned}
Re(j,k)(Z)Re(j,k)(X)=Zcorr(j,k)⊕E(j,k)(Z),=Xcorr(j,k)⊕E(j,k)(X).
设
C
(
j
,
k
)
(
X
)
C^{(j,k)}(X)
C(j,k)(X) 和
C
(
j
,
k
)
(
Z
)
C^{(j,k)}(Z)
C(j,k)(Z) 表示第
k
k
k 轮全局算法解码器应用的
X
X
X 和
Z
Z
Z 型校正,从方程中的残余综合征计算。总累积校正为
L
(
j
)
(
X
)
=
⨁
k
=
1
d
m
[
C
(
j
,
k
)
(
X
)
⊕
R
e
(
j
,
k
)
(
X
)
]
,
L
(
j
)
(
Z
)
=
⨁
k
=
1
d
m
[
C
(
j
,
k
)
(
Z
)
⊕
R
e
(
j
,
k
)
(
Z
)
]
.
\begin{aligned} L^{(j)}(X) &= \bigoplus_{k=1}^{d_m} \left[C^{(j,k)}(X) \oplus R^{(j,k)}_e(X)\right], \\ L^{(j)}(Z) &= \bigoplus_{k=1}^{d_m} \left[C^{(j,k)}(Z) \oplus R^{(j,k)}_e(Z)\right]. \end{aligned}
L(j)(X)L(j)(Z)=k=1⨁dm[C(j,k)(X)⊕Re(j,k)(X)],=k=1⨁dm[C(j,k)(Z)⊕Re(j,k)(Z)].
如果 L ( j ) ( X ) L^{(j)}(X) L(j)(X)( L ( j ) ( Z ) L^{(j)}(Z) L(j)(Z))与 D × D D \times D D×D 表面码片的逻辑算子 Z L Z_L ZL( X L X_L XL)反对易,则称发生了逻辑 X X X( Z Z Z)错误。


















 865
865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










