




 本文详细分析了Spark作业中出现的Out of Memory错误,并通过调整配置参数和优化数据读取策略来解决此问题。文中提到如何正确设置driver和executor资源,以及如何避免因shuffle和join操作引发的内存溢出。
本文详细分析了Spark作业中出现的Out of Memory错误,并通过调整配置参数和优化数据读取策略来解决此问题。文中提到如何正确设置driver和executor资源,以及如何避免因shuffle和join操作引发的内存溢出。
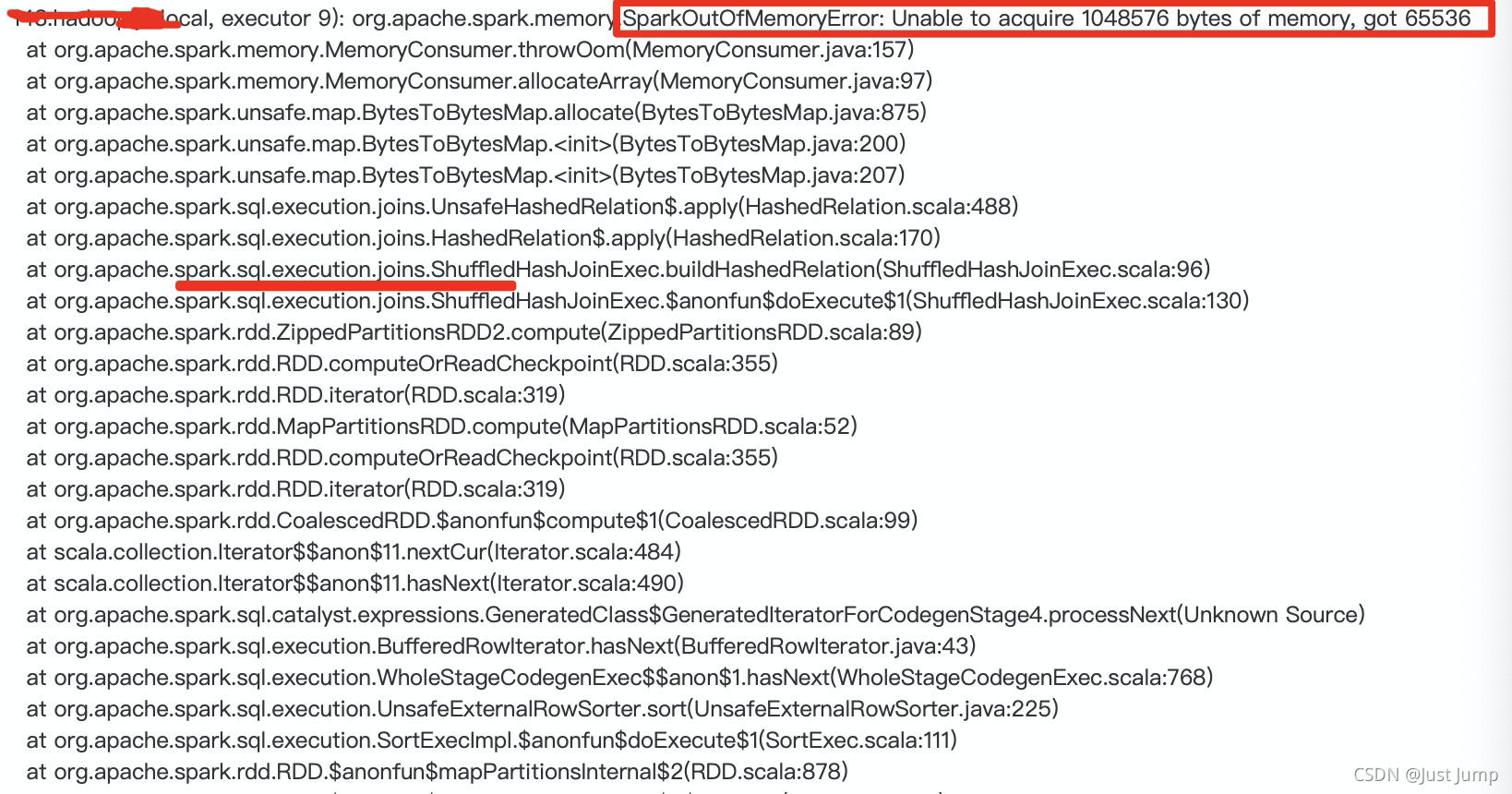
错误信息如下:
org.apache.spark.memory.SparkOutOfMemoryError: Unable to acquire 1048576 bytes of memory, got 65536内存溢出的位置:做JOIN操作的时候,内存溢出了。
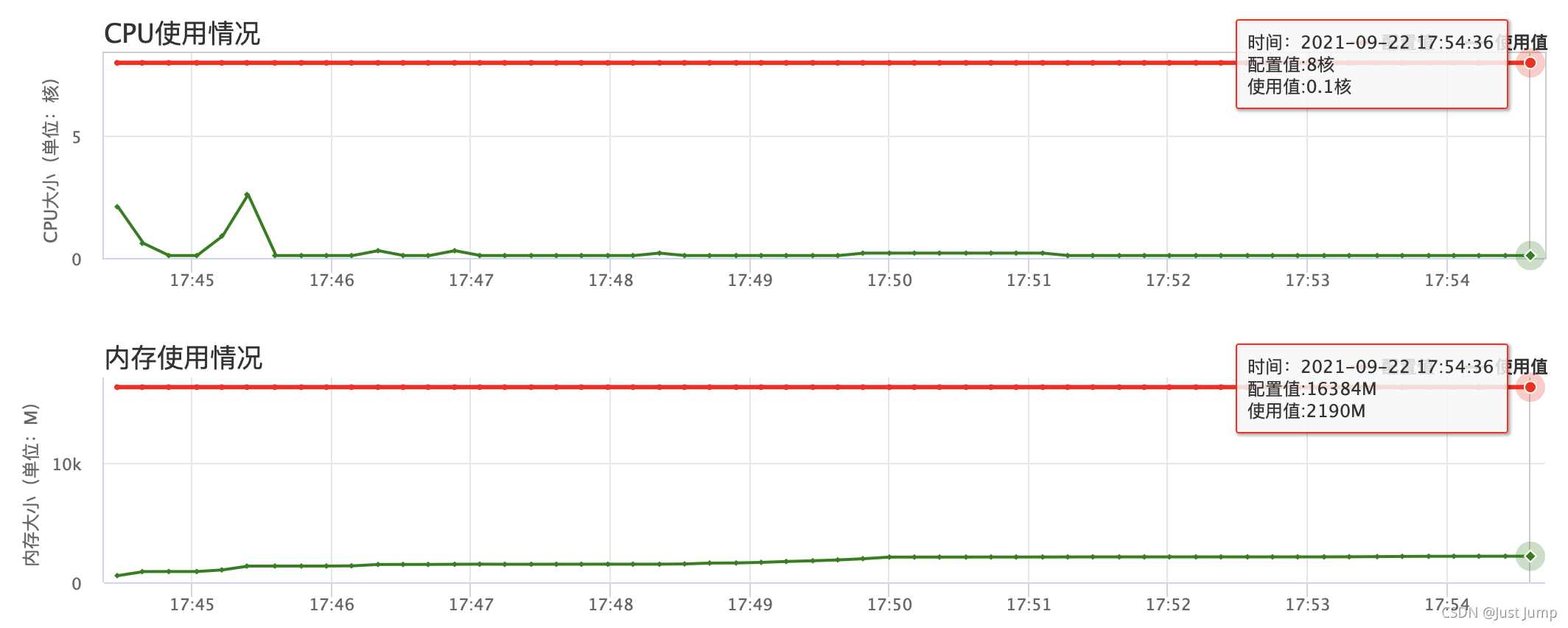
首先,定位下任务使用的资源,
其次,调参数
--driver-cores 4 \
--driver-memory 8G \
--executor-cores 4 \
--executor-memory 16G \
--num-executors 200 \一般我们会设置的参数是 driver的核数、内存,exector的核数、内存,exector个数。
driver的内存用于管理任务调度和记录task工作节点,以及任务返回的结果等。如果任务数、或返回结果超过了内存,任务会失败,报的也是OOM。
exector的内存用于执行任务,比如shuffle、join之类的,4个core共用这里的16G内存,一个核有4G内存可用。
资源使用图显示的是continer的资源使用,并没有真实的反应excutor使用的内存。
我试着调小exector的核数、增大exector内存,使得每个exector可以使用的内存尽量大些。但仍然报OOM。
我从底层数据排查发现,其中一个上游表的partition




















 2568
2568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










