




前文中股票高相关k线筛选问题的延伸。基于github上的代码迁移应用到股票高相关预测上。
这里给出一个相对完整的代码实现。
1、数据准备
准备股票的历史k线数据。数据格式: 股票名称、日期、收盘价。
1.1 数据处理和格式转换
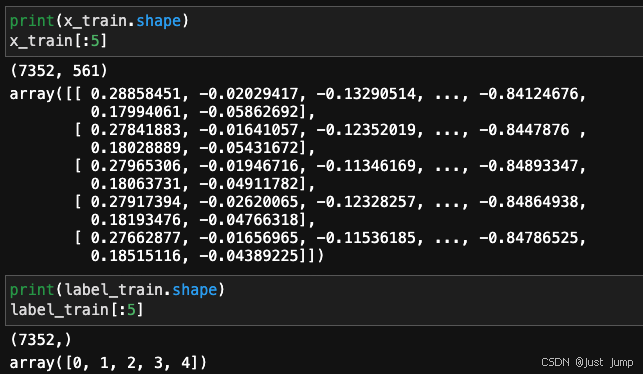
这里我们使用DTW算法来做股票K线的相似性查找,所以是允许时间不一致的。所以,我们会对股票收盘价数据做一个处理,将每支股票的收盘价读取成一个numpy.array,shape为(561,)所以股票的收盘价数据作为x_train,shape为 (7352, 561)。将股票名称读取成numpy.array,shape为(7352,)。
# Import dataset
x_train_file = open('data/train/X_train.txt', 'r')
# Create empty lists
x_train = []
# Loop through datasets
for x in x_train_file:
x_train.append([float(ts) for ts in x.split()])
# Convert to numpy for efficiency
x_train = np.array(x_train)
label_train=np.arange(7352)即数据格式处理为:
1.2 绘制k-线图查看
假设 ta=x_train[0] 是你当前在研究的股票。
我们随机抽取其他几支股票,将目标股票和其它股票的k-线图绘图看下,如下
plt.figure(figsize=(11,7))
colors = ['#E52008','#2C9F2C','#FD7F23','#1F77B4','#0467BD',
'#80564A','#7F7F7F','#1FBECF','#E377C2','#BCBD27']
for i, r in enumerate([0,27,65,100,145,172]):
plt.subplot(3,2,i+1)
plt.plot(x_train[r][:100], label="stock-%d"%label_train[r], color=colors[i], linewidth=2)
plt.xlabel('time sequece')$
plt.legend(loc='upper left')
plt.tight_layout()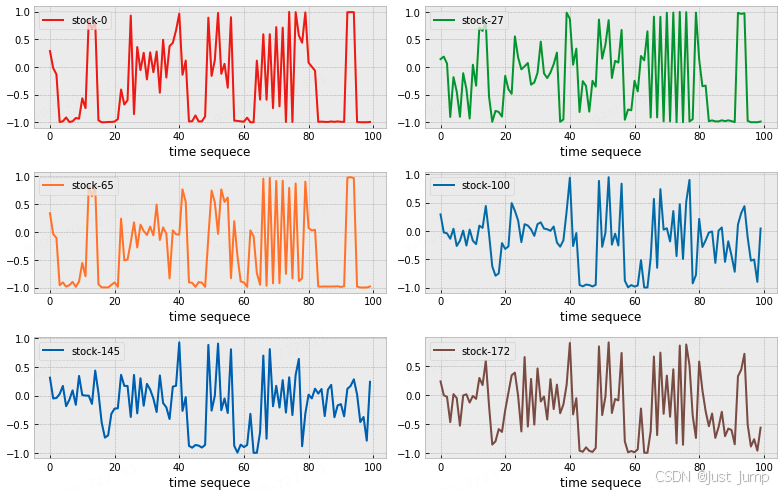
接下来要基于dtw距离计算与目标股票ta高相关的Top10支股票,并将他们的k-线图与ta股票的k-线图进行可视化对比呈现。
2、dtw算法模型
2.1、dtw算法
import sys
import collections
import itertools
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import mode
from scipy.spatial.distance import squareform
plt.style.use('bmh')
%matplotlib inline
try:
from IPython.display 



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










