




问题分析
Ajax是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页实现异步更新。这意味着在不重新加载整个网页的情况下,可以对网页的某部分进行更新。怎么判断一个网页是否使用了ajax技术呢?可以点击网页上任意更新网页内容的按钮,看一下网页的url(Uniform Resource Locator)是否发生变化,如果没有变化,应该就是使用了ajax技术。使用了这个技术的网页对应的html源代码里面没有包含我们需要的所有信息,这时单单使用requests库再用bs4库解析的套路就行不通了。解决方法有两种1:
- 解析接口:既然网站的内容发生了变化,那就说明服务器传东西过来了,从而咱也一定向服务器发送了请求。我们只需要使用浏览器的检查工具,弄清楚向哪个url偷偷发送请求得到了数据就ok了,咱也去请求这个url。
- Selenium库(本文使用第一种方法)
本文以爬取https://www.cnss.com.cn/html/gkryjg/ 网站上的油价数据为例,说明如何使用解析接口的方式爬取使用了ajax技术的网页。

我们点击加载更多,可以发现网页偷偷向https://www.cnss.com.cn/api/content/list.jspx 这个url发送了请求,从负载中可以看到这个url的查询参数有三个。

在响应中我们可以看到这个url给网页返回了一些json数据构成的列表。列表中包含了网页更新内容对应的url。

多次尝试可以发现每次点击加载更多,网页都是悄悄向上述url偷偷发送请求,而查询参数部分只有first这一个参数发送变化,经过分析可以知道first参数实际上就是新一批内容首个内容的序号。到这里基本思路就出来了——首先,不断调整查询参数first向上述url发送请求,收集所有包含了某日油价数据网页的url。然后再依次对这些网页进行爬取,收集出这些网页中的数据。
编程实现
首先来设计一个url管理器,避免网页重复爬取2。
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 26 16:22:53 2025
urlmanager模块
@author: syaunsheng
"""
class Urlmanager(object):
"""url管理器"""
def __init__(self):
self.not_crawled_url_set = set() # 还没有被爬取的url的集合
self.is_craled_url_set = set() # 已经被爬取的url的集合
def has_url(self):
"""检查是否还有待爬取的url"""
return len(self.not_crawled_url_set)
def get_url(self):
"""从not_crawled_url_set返回一个url并放入is_craled_url_set"""
if self.has_url():
url = self.not_crawled_url_set.pop()
self.is_craled_url_set.add(url)
return url
else:
return None
def add_url(self,url):
if url not in self.not_crawled_url_set and url not in self.is_craled_url_set:
self.not_crawled_url_set.add(url)
def add_urls(self,urls):
for url in urls:
self.add_url(url)
if __name__ == "__main__":
urlmanager = Urlmanager()
urlmanager.add_url("http://www.bilibili.com")
print(urlmanager.not_crawled_url_set)
print(urlmanager.get_url())
print(urlmanager.not_crawled_url_set,urlmanager.is_craled_url_set)
然后收集所有待爬取网页的url,并依次爬取各个url。
# -*- coding: utf-8 -*-
"""
Created on Fri Feb 28 20:48:09 2025
@author: syaunsheng
"""
import requests
import pandas as pd
from io import StringIO
from urlmanager import Urlmanager
from bs4 import BeautifulSoup
# 收集所有待爬取url
def get_all_necessary_urls(days=22):
"""默认获取近22天油价数据对应的所有网页的url"""
all_necessary_urls = []
counter = 0
for first in range(11,days+1,11):
r = requests.post(url1,headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36 Edg/133.0.0.0',
'referer':'https://www.cnss.com.cn/html/gkryjg/'
},params={
'first' : first,
'count': 11,
'channelIds': 63
})
if r.status_code == 200:
counter += 11
print('获取成功,url总数{}'.format(counter))
else:
print('获取失败')
continue
# url1返回的是json数据,对每一个json数据做单独处理
for json_data in r.json():
all_necessary_urls.append(base_url+json_data["url"])
return all_necessary_urls
# 依次爬取每个url中的数据
def get_data_from_urls():
big_df_lst = []
while urlmanager.has_url():
url = urlmanager.get_url()
r = requests.get(url,headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36 Edg/133.0.0.0',
'referer':'https://www.cnss.com.cn/html/gkryjg/'
})
if r.status_code == 200:
print('请求成功。剩余待访问url数={}'.format(urlmanager.has_url()))
else:
print('请求失败!剩余待访问url数={}'.format(urlmanager.has_url()))
continue
r.encoding = 'utf-8'
#soup = BeautifulSoup(r.text,'html.parser')
# 使用bs4解析获取每个url对应数据的日期,方便后续处理
# date = soup.find('p',class_='article-title').get_text()[:10]
date = url[37:45]
# 使用pandas解析出表格数据
s = StringIO();s.write(r.text);s.seek(0)
df_lst = pd.read_html(s,header=0)
concatenated_df = pd.concat(df_lst,join='outer',ignore_index=True,axis=0)
concatenated_df['date'] = date
big_df_lst.append(concatenated_df)
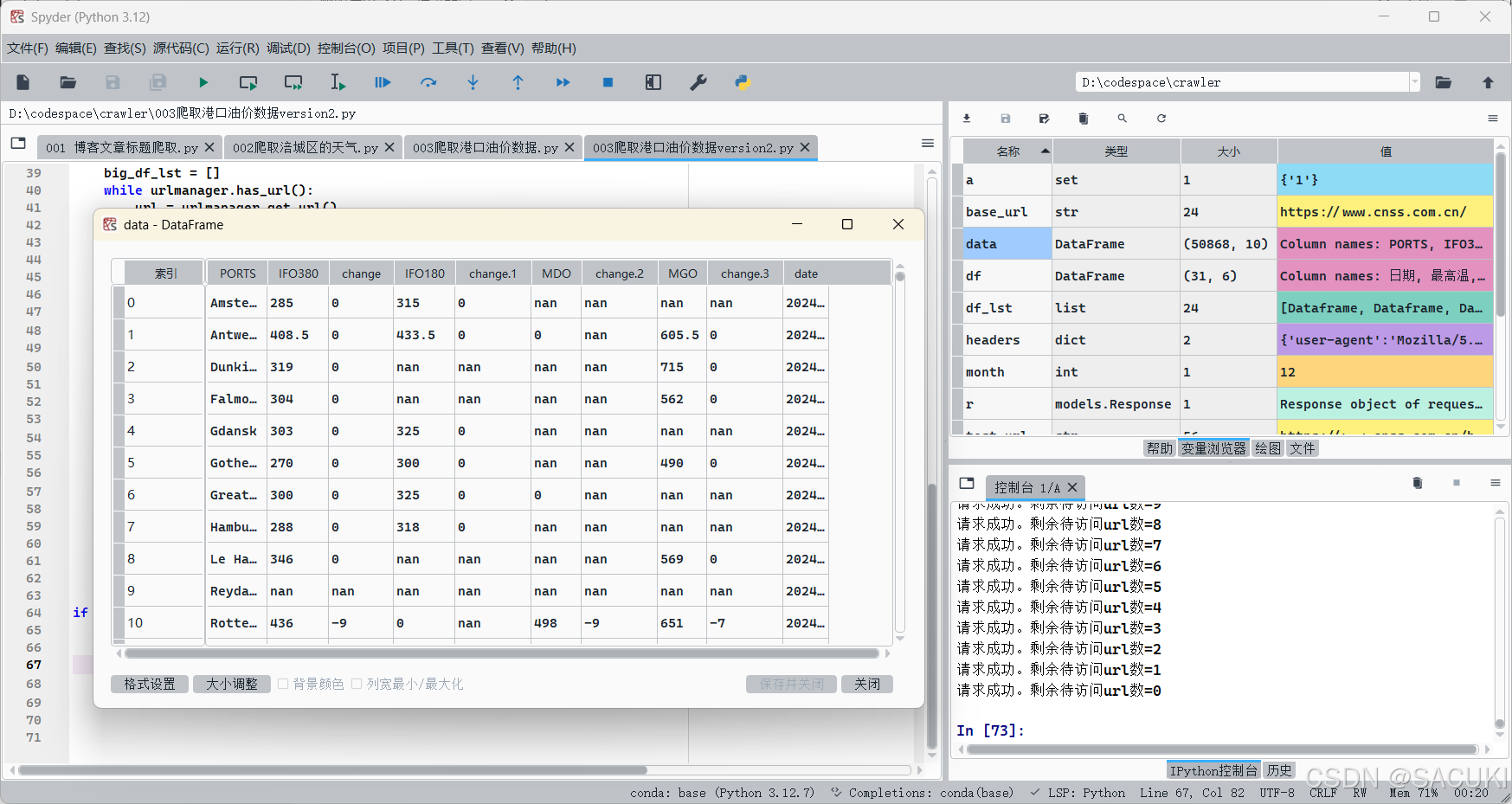
return pd.concat(big_df_lst,join='outer',ignore_index=True,axis=0)
if __name__ == '__main__':
base_url = 'https://www.cnss.com.cn/'
url1 = "https://www.cnss.com.cn/api/content/list.jspx"
urlmanager = Urlmanager();urlmanager.add_urls(get_all_necessary_urls(days=330)) # 获取近330天的油价
data = get_data_from_urls();data.to_excel('.\油价数据.xlsx')
实验结束,获得近330天的油价数据,并写入excel中。
附:前端基础知识
了解一些前端知识是python爬虫的基础。参考:
- html,css和javascript相关知识:https://www.bilibili.com/video/BV1BT4y1W7Aw
- http协议,浏览器开发者工具相关知识:https://www.bilibili.com/video/BV165411A7ef
HTML(Hyper Text Marked Language)、CSS(Cascading Style Sheets)、Javascript是构建现代网页的关键技术,它们之间有着紧密的关系。HTML是一种标记语言,主要用于描述网页的结构和内容;CSS用于设置网页的样式;JavaScript是一种脚本语言,用于增强网页的交互性和动态性。HTML和CSS相对简单,主要是把搞懂JavaScript搞懂。
- HTML常用标签的含义以及常用CSS属性:https://zhuanlan.zhihu.com/p/9201482393
- HTML的块标签、行内标签、行内块标签的含义和区别:https://blog.csdn.net/weixin_44706267/article/details/121022104
- HTML中导入CSS的方式:https://www.runoob.com/w3cnote/html-import-css-method.html
- CSS必须加分号的坑:https://www.zhihu.com/question/20283093
- HTML,CSS,JS注释写法不同,避坑:https://blog.csdn.net/woshisangsang/article/details/120839199
- CSS盒子模型概念,用于页面布局:https://blog.csdn.net/m0_46958731/article/details/114544954 推荐使用定位布局方式,更好控制。
- JavaScript基本语法:https://blog.csdn.net/2301_80208072/article/details/143455858
- JavaScript构成:https://blog.csdn.net/qq_52736131/article/details/123563321 ,其中dom这个概念非常重要,简单讲dom使得我们可以用js语言去操作html文档,获取html中的节点、修改节点内容、插入新节点、删除节点…使得网页发生动态变化。
- JavaScript函数和触发事件的绑定:https://blog.csdn.net/wangxuanyang_zer/article/details/129626676
下面来实战,写一个网页,实现数据的增删查改。
<!DOCTYPE html>
<html lang='en'>
<head>
<meta charset = 'utf-8'>
<title>一个信息表格</title>
<style>
/*内嵌方式使用css*/
table{
width:100%;
border-collapse:collapse; /*设置表格内元素无间隙*/
margin-top:5px;
}
th,td{
border:1px solid;
text-align:center;
padding:8px;
}
th{
background-color:gray;
}
button{
margin-right:5px;
}
</style>
</head>
<body>
<h1 style="text-align:center">表格的增删改查</h1>
<!--通过on前缀+事件类型的属性为新增数据这个按钮绑定监听函数add_data-->
<button onclick='add_data()'>新增数据</button>
<!--这里设置id的目的是便于js获取到这个节点-->
<table id=0>
<tr>
<th>姓名</th>
<th>电话</th>
<th>操作</th>
</tr>
</table>
<script src='./table.js'></script> <!--导入外部js代码-->
</body>
</html>
// table.js文件
// 给新增数据这个按钮创建监听函数
function add_data(){
// 通过table节点的id属性获取到table节点
var table_node = document.getElementById(0)
// 新增数据的方法很简单,就是在html对应位置再插入一行三列
var row_1d = table_node.rows.length // 获取要插入行对应的索引,然后使用table节点的insertRow方法插入row节点并返回
var table_row = table_node.insertRow(row_1d)
// 在再table_row节点中插入列节点对象并返回
var table_col1 = table_row.insertCell(0)
var table_col2 = table_row.insertCell(1)
var table_col3 = table_row.insertCell(2)
console.log(table_row)
// 最后来设置table_col节点中间的文本
table_col1.innerHTML = "未命名"
table_col2.innerHTML = "无联系方式"
// this属性相当于当前节点对象
table_col3.innerHTML = "<button onclick='edit(this)'>编辑</button><button onclick='delete_data(this)'>删除</button>"
}
// 给删除这个按钮创建监听函数
function delete_data(button){
// 参数传进来要删除的那行数据对应的button,方便定位,获取到它父节点的父节点
var node_to_delete = button.parentNode.parentNode
// 再找到node_to_delete的父节点——即整个表格,在在整个表格的基础上删掉node_to_delete节点即可
node_to_delete.parentNode.removeChild(node_to_delete)
}
// 给编辑这个按钮创建监听函数
function edit(button){
var row_to_edit = button.parentNode.parentNode
var table_col1 = row_to_edit.childNodes[0]
var table_col2 = row_to_edit.childNodes[1]
var name = prompt('输入姓名')
var phone = prompt('输入电话号')
table_col1.innerHTML = name
table_col2.innerHTML = phone
}
Hyper Text Transfer Protocol(http协议)相关知识参考:https://mp.weixin.qq.com/s/5zkMuUNMzugyfxNtg1VkIQ


















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










