



编者按:长期以来,3D打印行业一直在等待规模化爆发。大家都在设备端持续加码,比如提高激光功率、优化设备设计、做大成型尺寸。但真正限制行业发展的,不只是设备,更关键的是材料。
原因在于,3D打印属于增材制造,不同于传统减材工艺。金属粉末需要在极短时间内完成熔化和凝固,热过程复杂,应力状态也与传统制造方式完全不同。
因此,传统锻造或铸造使用的合金材料,往往不能直接用于3D打印,否则很容易出现开裂或性能不达标等问题。
这也意味着,要真正释放3D打印的潜力,不能只靠设备升级,还必须从底层重新设计适用于增材制造的合金配方,让“几何自由”进一步转化为“性能自由”。
但这件事并不容易。
传统材料研发更像“试错式”推进,不仅变量多、周期长,往往还要花费3到5年,研发成本也非常高。
而AI的出现,正在为金属3D打印材料研发带来新的可能。
据资源库了解,自2025年9月以来,不到半年,创材深造Deep Material已借助AI研发出多达13款新型金属材料,并逐步完成客户认证。
这是公司用AI“造材料”的彪悍实力。对于3D打印圈,大家对创材深造可能不是特别熟悉,但在AI领域,它连续入选中国最具潜力的Science AI创业企业Top10。

在刚刚结束的2026年TCT亚洲展上,创材深造一口气发布了6款新材料。其中,一款钛合金的抗拉强度超过1500MPa,成本却比同类产品低30%。

不过,今天这篇文章想讲的,不只是这些新材料有多强,真正更值得关注的是:这些材料,究竟是怎么被“造”出来的。
材料成行业“隐形天花板”
有一件事,金属3D打印领域的人都知道,但不常对外说:3D打印规模化量产,到今天还没有真正爆发,卡点不在设备,在材料。
设备这几年进步飞快,LPBF、电弧增材……工艺成熟度已经相当高。但每当一家制造企业想把3D打印引入批量生产线,最终摔倒的地方往往是材料:性能参数差了一截、批次稳定性不够、或者成本压不下来。
这背后是材料研发本身的困难——金属材料的性能由成分、工艺、微观组织、服役条件共同决定,涉及变量超百个维度,任意一个参数的改变都可能引发连锁反应。传统的材料研发靠经验摸索,一款高端合金从立项到小批量验证,标准周期是3~5年。
事实上,当下游需求已经进入“摩尔定律”节奏,上游材料供给还停留在“农耕时代”。此外,中国高端合金材料70%依赖进口。高温合金、高强钛合金等这些航空航天和消费电子的命脉材料,长期被卡在供应链上,既贵,又随时有断供风险。
这是整个行业面临的真实困境,直到AI开始进入这个领域。创材深造Deep Material要填平的,正是这个断层。
不是"查文献",而是"让AI设计配方"
很多人以为AI在材料领域的应用,就是用大模型检索论文、生成报告。创材深造做的事情完全不是这么回事。其中要解决的核心问题是:如何让AI在"成分-工艺-性能"这个超高维空间里,做出真实可用、性能可预测的配方决策?
这个问题的难点在于,要让AI做出有效决策,需要三个条件同时满足:① 足够干净、标准化的实验数据(AI的学习原料)② 足够快的数据产出速度(喂饱模型的前提) ③ 足够精准的预测与逆向优化能力(最终落地成配方)
这三个条件,缺一不可。
传统实验室做不到,因为人工操作带来的误差无法消除,数据质量参差不齐;计算机模拟做不到,因为缺乏真实实验的反馈闭环;纯数据模型做不到,因为现有材料数据库的覆盖范围远远不够。
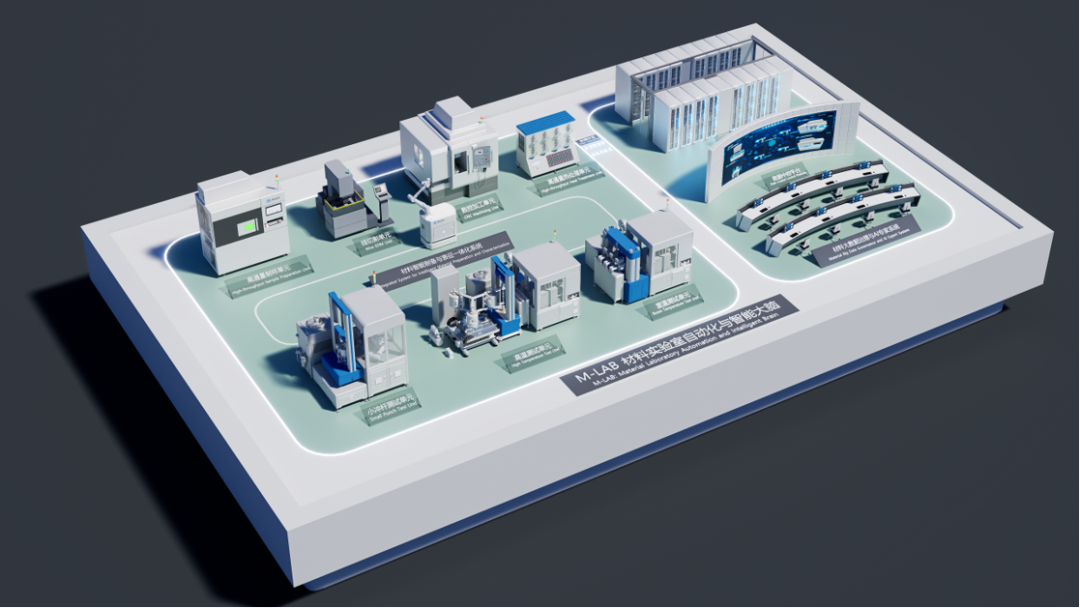
创材深造Deep Material的解法,是把这三件事同时做——通过软硬件结合,搭建高通量无人实验室,用它产生高质量数据,再用AI处理这些数据,进一步用AI的结论指导下一轮实验,形成一个持续加速的闭环。他们把这套东西叫做:M-LAB(材料实验室自动化与智能大脑)。
M-LAB:一条没有工程师的材料研发流水线
它以“材料智能制备与表征一体化”硬件与“材料大数据治理与AI专家系统”软件双核驱动,构建了从高通量制样、加工、热处理到室温、高温及小冲杆蠕变测试的全流程自动化无人实验室。

第一站:高通量制备。前端是一台高通量3D打印机(LPBF工艺)。它的特殊之处在于,单次运行可以同时制备上百种不同成分配方的金属样品——相当于把原本需要排队进行数月的实验,压缩成一次平行扫描。紧接着,全自动线切割与数控加工设备将样品切割成标准形态,8通道独立温控热处理单元完成热处理工艺,数据实时上传。整个过程,没有人工干预。
第二站:高通量测试。样品进入测试流水线。
室温力学测试:三工位测试机,单轴力达25KN,误差≤2%。配备协作机器人、DIC相机、自动打点和尺寸检测模块。单日可完成600个样品测试,全程自动打包贴标,零人工干预。
高温力学测试:三工位高温测试机,单日可测100个高温样品,同样由协作机器人操作,配DIC检测。
小冲杆高温蠕变测试:从上料、组装、高温炉开闭、升降温到废料处理,全流程自动化。
这里有一个关键技术点值得单独说:创材深造Deep Material采用小微试样和小冲杆测试技术,相比传统标准棒样,测试同等配方空间所需的粉末消耗最高可降至1/20。这意味着,同样的材料预算,可探索的配方扩大了20倍——这是他们能以极低成本持续产出新材料的底层秘密之一。
在软件端,系统从数据到决策,AI全程接管。数据进入软件系统后,经历三层处理。
数据中台:支持PB级数据体量,对原料到成品的全链路数据进行清洗与融合,确保输入AI的数据是高质量、可信的。
AI专家系统:这是系统的决策核心。它建立"成分-工艺-性能"映射模型,正向预测性能误差仅5%~10%。更强大的是反向模式:给定一个目标性能,系统用贝叶斯算法逆向推算最优配方,效率比传统方式提升超60%。这意味着,研发人员不再需要猜测"这个成分会不会有好性能",而是直接问AI:"我想要1400MPa的抗拉强度,你给我推一个配方。"
知识库平台(RAG技术):自动解析材料领域的文献与专利,用自然语言就可以检索,相当于一位永不休息的材料文献专家随时待命。
|
版本 |
时间 |
核心升级 |
数据通量 |
|
HMPT-1000 |
2023年 |
机械臂自动上下样 |
100条/天 |
|
HMPT-2000 |
2025年 |
尺寸自动测量 + 视觉监控 |
150条/天 |
|
HMPT-3000 |
2026年 |
全自动高温测试 + 3工位扩展 |
600条/天 |
M-LAB的硬件平台经历了三次迭代
三年时间,数据产出能力提升了6倍。AI可以学习的数据量是三年前的6倍,材料迭代速度也相应加快。意味着AI驱动的材料研发范式在持续进化。
DM Agent:当材料实验室有了一个会思考的大脑
M-LAB的硬件和软件系统负责产生和处理数据,但整个体系的"最高决策者"是DM Agent——这是创材深造在去年发布的行业首个金属材料智能体。
在新升级的DM Agent中,创材深造打造了一个金属材料的专用知识图谱,通过逻辑推理,常识校验,逆向优化建议,智能检索,实测数据显示等,为科研人员提供更可靠、更透明的智能分析支持。
实测数据显示,接入DM Agent后,复杂问答的答案一致性提升20%,事实性错误降低30%。
更值得关注的是,DM Agent已经具备初步的自主实验规划能力——它不只是在回答"这个成分性能如何",而是开始能判断"接下来应该往哪个方向探索"。这正是创材深造定义的L3(多模态智能体)向L4(自主科学发现)过渡的核心特征。
按照他们的路线图,L4阶段的实验室将能够自主产生涌现式的材料探索路径,不再依赖人类研究员的先验假设。某种意义上,这是AI第一次有机会在材料科学领域真正意义上"超越"人类经验的上限。
13款新材料,多项参数刷新行业高度
2025年9月,创材深造Deep Material在TCT深圳举办发布会, 高温合金、模具钢、中/高强铝合金等7款新材料首次亮相,涵盖航空航天和工业应用核心品类。

而此次TCT亚洲展再发6款,多项参数更是刷新行业高度。
|
材料 |
型号 |
核心性能 |
|
超高强度钛合金 |
CT1300H / CT1400H / CT1500H |
屈服强度>1100 MPa,抗拉强度>1400 MPa |
|
无稀土耐热铝合金 |
CA300T |
低成本,无稀土,耐热 |
|
高强度铝合金 |
CA760H |
高强,可打印,低成本 |
|
耐磨难熔高熵合金 |
CH800H |
耐磨、耐高温,多场景适用 |
以CT1400H钛合金为例:屈服强度>1100 MPa,抗拉强度>1400 MPa,成本比市场同类产品低30%——高性能与低成本同时实现,在传统研发逻辑下几乎是一个不可能完成的任务,但在这套系统里,它是降低成本后自然产生的结果。

目前,中/高强铝合金等系列产品均已通过第三方专业机构测试认证,进入批量交付阶段,多个消费电子和新能源应用预计2026年下半年进入大规模量产。
结语:打穿天花板的,是速度
做投资的都清楚,一个项目最重要的就三点:创新,成本和增速。如果只选一项,那就是速度!
金属3D打印走向规模化量产,需要三件事同时发生:性能稳定、成本可控、供货持续的材料。过去,传统研发范式的速度跟不上需求端的迭代节奏。现在,创材深造Deep Material用一套每天自动跑600次实验的无人工厂,用一个能逆向设计配方的AI大脑,用13款已经开始进入批量交付的新材料,告诉整个行业,金属3D打印的边界被打穿了。
正如创材深造CEO王轩泽在TCT发布会上说的那句话:"AI正在让创新从偶然走向必然。"
当AI真正实现研发全流程的智能化决策和闭环迭代,当2~6个月就能推出一款经过严格验证的批量级新材料,攻克增材制造产业链上最关键的"材料天花板",整个行业将快速迎来规模化量产的崭新时代。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










