



 在微服务架构的运维实践中,健康检查与监控是保障系统高可用性的基石。当大模型服务被整合到微服务生态中时,系统的复杂性显著提升:不仅要监控传统的服务存活状态、内存使用、线程池饱和度,还需要特别关注大模型调用的健康状况,包括模型服务提供商的可用性、API 调用延迟、Token 消耗率等独特指标。
在微服务架构的运维实践中,健康检查与监控是保障系统高可用性的基石。当大模型服务被整合到微服务生态中时,系统的复杂性显著提升:不仅要监控传统的服务存活状态、内存使用、线程池饱和度,还需要特别关注大模型调用的健康状况,包括模型服务提供商的可用性、API 调用延迟、Token 消耗率等独特指标。
本章将系统性地介绍微服务健康检查与监控的技术体系,从基础概念到企业级实战,帮助读者构建完善的微服务大模型监控体系。
14.1.1 为什么大模型服务需要特殊的健康检查
传统的微服务健康检查通常关注两个层面:存活检查(Liveness Probe)和就绪检查(Readiness Probe)。存活检查判断服务进程是否正常运行,如果失败则重启容器;就绪检查判断服务是否能够处理请求,如果失败则从负载均衡池中移除。这两种检查机制在传统微服务场景下运作良好,但面对大模型服务时却显得不够精细。
大模型服务的特殊性体现在多个方面。首先,大模型本身是高度集中的资源,无论是 OpenAI 的 GPT-4、Anthropic 的 Claude,还是国内的文心一言、通义千问,都是通过 API 调用的外部服务。本地微服务的存活状态正常,并不意味着大模型服务可用——可能存在网络隔离、API Key 过期、配额耗尽等各种问题。其次,大模型调用的响应时间波动很大,正常情况下可能是几百毫秒,但在高负载或网络抖动时可能需要几十秒。这种延迟变化并不意味着服务不可用,但传统的超时机制可能导致误判。
因此,大模型服务需要更加精细的健康检查策略:不仅要检查本地服务的存活状态,还要检查下游大模型服务提供商的可用性;不仅要关注请求是否成功,还要关注响应时间是否在合理范围内;不仅要检查当前状态,还要分析历史趋势,预测潜在风险。
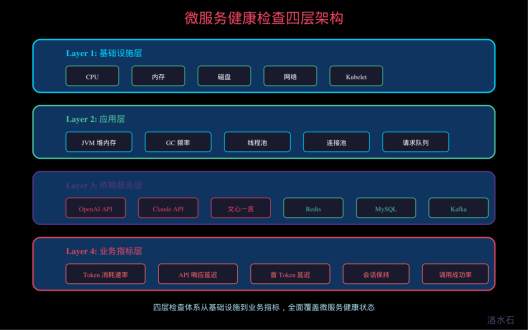
14.1.2 健康检查的多层级架构
一个完善的大模型微服务健康检查体系应该包含四个层级:基础设施层、应用层、依赖服务层和业务指标层。
基础设施层检查是最基础的部分,包括 CPU 使用率、内存使用率、磁盘使用率、网络连通性等。这些指标反映了运行环境的健康状况,通常由 Kubernetes 或运维平台自动检测。在 Kubernetes 中,kubelet 负责定期采集这些数据,当资源使用超过阈值时会触发告警或自动重启。
应用层检查关注应用本身的健康状态,包括 JVM 堆内存使用、非堆内存使用、垃圾回收频率、线程池活跃线程数、连接池使用率等。在 Spring Boot 应用中,可以通过 Spring Boot Actuator 暴露这些健康指标。对于大模型服务应用,还需要关注与 LLM 相关的特定指标,如本地缓存命中率、Token 计数器状态、请求队列长度等。
// 自定义健康检查指标:LLM 连接池状态
@Component
public class LlmConnectionPoolHealthIndicator implements HealthIndicator {
private final LlmConnectionPool connectionPool;
@Override
public Health health() {
int activeConnections = connectionPool.getActiveCount();
int maxConnections = connectionPool.getMaxCount();
double usageRatio = (double) activeConnections / maxConnections;
if (usageRatio > 0.9) {
return Health.down()
.withDetail("reason", "Connection pool saturation")
.withDetail("active", activeConnections)
.withDetail("max", maxConnections)
.build();
}
return Health.up()
.withDetail("active", activeConnections)
.withDetail("max", maxConnections)
.withDetail("usage", String.format("%.2f%%", usageRatio * 100))
.build();
}
}
依赖服务层检查是面向外部依赖的检查,包括数据库连接、消息队列可用性、Redis 缓存可用性等。在大模型场景中,最关键的依赖服务层检查是各大模型服务提供商的可用性。这些检查需要实际发起 API 调用来验证连通性,而不仅仅是检查网络层是否可达。
业务指标层检查是最贴近业务的一层,关注业务功能的健康状况。对于大模型服务而言,业务指标可能包括:最近 N 次调用的成功率、平均响应时间、Token 消耗速率、会话保持能力等。这些指标反映了服务对业务的支撑能力,是最终用户能感受到的服务质量。
14.1.3 健康检查的执行策略与配置
健康检查的执行策略需要根据服务的特性和需求进行精细配置。Kubernetes 原生提供了 livenessProbe、readinessProbe 和 startupProbe 三种探针,每种探针都有其特定的适用场景和配置参数。
Liveness Probe 用于检测应用是否存活。如果探测失败,Kubernetes 会重启容器。在配置 Liveness Probe 时,需要确保检查的是应用的核心功能,避免因为临时性的外部依赖问题导致不必要的重启。例如,对于依赖大模型 API 的服务,不应该将 API 调用失败作为 Liveness Probe 的判断条件,因为这可能导致网络抖动时的频繁重启。
# Kubernetes 健康检查配置示例
apiVersion: v1
kind: Pod
spec:
containers:
- name: llm-api-container
image: llm-api-service:v1.0
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
timeoutSeconds: 3
failureThreshold: 2
startupProbe:
httpGet:
path: /actuator/health/startup
port: 8080
failureThreshold: 30
periodSeconds: 10
Readiness Probe 用于检测应用是否就绪。如果探测失败,Kubernetes 会将 Pod 从 Service 的端点中移除,停止接收新的流量,但不会重启容器。Readiness Probe 的检查条件可以比 Liveness Probe 更严格,因为它不会导致服务中断,只是暂时移除流量。在大模型服务中,Readiness Probe 可以包含对大模型 API 可用性的检查,如果模型服务不可用,可以先将流量切换到备用方案或降级服务。
14.2.1 Spring Boot Actuator 的核心端点
Spring Boot Actuator 是 Spring Boot 官方提供的应用监控模块,通过一系列 HTTP 端点暴露应用的健康信息、 metrics 指标、环境变量等。在微服务大模型整合项目中,合理配置 Actuator 是构建监控体系的第一步。
Actuator 2.x 版本对端点模型进行了重大重构,所有端点默认通过 `/actuator` 前缀暴露,并通过 `management.endpoints.web.exposure.include` 配置控制哪些端点需要暴露。常用的核心端点包括:
`/actuator/health` 是最常用的端点,返回应用的总体健康状态。可以通过 `management.endpoint.health.show-details` 配置展示细节的程度:`never` 表示不展示详情,`when_authorized` 表示仅对授权用户展示,`always` 表示对所有用户展示。在生产环境中,建议设置为 `when_authorized` 并配合 Spring Security 进行权限控制。
`/actuator/metrics` 端点返回所有可用的监控指标,支持通过 `?name=xxx` 参数筛选特定指标。每个指标包含名称、描述、测量单位、可标签化维度等属性。通过 Micrometer 框架,开发者可以方便地注册自定义指标。
`/actuator/prometheus` 端点以 Prometheus 格式暴露指标数据,适用于与 Prometheus + Grafana 技术栈集成。这种格式的指标数据可以通过 Prometheus 自动抓取并存储,为后续的可视化和告警提供数据基础。
# application.yml Actuator 配置
management:
endpoints:
web:
exposure:
include: health,metrics,prometheus,info
base-path: /actuator
endpoint:
health:
show-details: when_authorized
probes:
enabled: true
health:
livenessState:
enabled: true
readinessState:
enabled: true
metrics:
tags:
application: ${spring.application.name}
environment: ${DEPLOY_ENV:dev}
14.2.2 Micrometer 指标体系与自定义指标
Micrometer 是 JVM 应用的指标门面框架,提供了与具体监控系统无关的统一指标 API。通过 Micrometer,开发者可以使用相同的代码向 Prometheus、DataDog、InfluxDB、云厂商监控系统等多种后端发送指标数据。在 Spring Boot 2.x 中,Micrometer 已经作为 Spring Boot Actuator 的底层实现得到了深度集成。
Micrometer 支持四种类型的指标:Gauge(仪表)用于表示一个可变的数值,如当前队列长度、内存使用量等;Counter(计数器)用于表示只能递增的数值,如请求总数、错误总数等;Timer(计时器)用于记录操作耗时,同时自动计算次数、总和、最大值等统计值;Summary(摘要)用于表示百分比分布,如响应时间的分位数。
在大模型服务监控中,最常用的是 Timer 和 Counter。Timer 用于记录大模型 API 调用的耗时,包括总耗时、首 Token 延迟等;Counter 用于记录调用次数、成功次数、失败次数等。
// 大模型调用的自定义指标注册
@Configuration
public class LlmMetricsConfiguration {
@Bean
public MeterRegistry meterRegistry(MeterRegistry registry) {
// 创建一个 Timer 用于记录 LLM 调用延迟
Timer llmCallTimer = Timer.builder("llm.api.call.duration")
.description("LLM API call duration")
.tag("model", "unknown") // 初始为 unknown,后续根据实际调用更新
.publishPercentiles(0.5, 0.95, 0.99) // 发布 p50, p95, p99 分位数
.publishPercentileHistogram()
.register(registry);
// 创建一个 Counter 用于记录 LLM 调用次数
Counter llmCallCounter = Counter.builder("llm.api.call.count")
.description("LLM API call count")
.tag("status", "success")
.register(registry);
// 创建一个 Gauge 用于监控活跃请求数
AtomicInteger activeRequests = new AtomicInteger(0);
Gauge.builder("llm.api.active.requests", activeRequests, AtomicInteger::get)
.description("Number of active LLM API requests")
.register(registry);
return registry;
}
}
14.2.3 指标标签的规范化设计
在微服务架构中,指标的标签(Tags/Labels)设计直接影响数据的可用性和后续分析的效率。一个良好的标签体系应该具备以下特点:标签值应该是有限的枚举值,而非自由文本;标签名称应该语义清晰,便于理解;标签组合应该能够满足主要的查询和分析场景。
对于大模型服务的指标,建议定义以下标准标签:
`model` 标签标识具体的模型名称,如 `gpt-4`、`claude-3-opus`、`ernie-4`。这个标签对于分析不同模型的性能差异和成本差异至关重要。
`provider` 标签标识模型服务提供商,如 `openai`、`anthropic`、`baidu`、`aliyun`。在多提供商场景下,这个标签用于区分不同来源的请求。
`operation` 标签标识操作类型,如 `chat`、`embedding`、`completion`。不同的操作类型具有不同的性能特征和成本结构。
`status` 标签标识请求状态,如 `success`、`error`、`timeout`。通过这个标签可以方便地聚合成功率和错误分布。
`deployment` 标签标识部署环境,如 `production`、`staging`、`development`。这个标签用于区分不同环境的指标,避免在生产问题排查时被开发环境的数据干扰。
// 使用 Micrometer 的标签路由功能
@Service
public class InstrumentedLlmClient {
private final MeterRegistry registry;
private final LlmClient delegate;
public InstrumentedLlmClient(MeterRegistry registry, LlmClient delegate) {
this.registry = registry;
this.delegate = delegate;
}
public LlmResponse chat(ChatRequest request) {
String model = request.getModel();
Timer.Sample sample = Timer.start(registry);
try {
LlmResponse response = delegate.chat(request);
// 记录成功指标
registry.counter("llm.calls",
"model", model,
"provider", getProvider(model),
"operation", "chat",
"status", "success")
.increment();
registry.counter("llm.tokens",
"model", model,
"type", "prompt")
.increment(response.getUsage().getPromptTokens());
registry.counter("llm.tokens",
"model", model,
"type", "completion")
.increment(response.getUsage().getCompletionTokens());
return response;
} catch (Exception e) {
// 记录失败指标
registry.counter("llm.calls",
"model", model,
"provider", getProvider(model),
"operation", "chat",
"status", "error")
.increment();
throw e;
} finally {
sample.stop(Timer.builder("llm.latency")
.tag("model", model)
.tag("provider", getProvider(model))
.publishPercentiles(0.5, 0.95, 0.99));
}
}
private String getProvider(String model) {
if (model.startsWith("gpt")) return "openai";
if (model.startsWith("claude")) return "anthropic";
if (model.startsWith("ernie")) return "baidu";
return "unknown";
}
}
14.3.1 Prometheus 数据模型与查询语言
Prometheus 是 CNCF 的毕业项目,是目前云原生监控领域的事实标准。Prometheus 采用时序数据库存储监控数据,其数据模型以时间序列为核心,每条时间序列由指标名称和标签集唯一标识。
Prometheus 的查询语言 PromQL 是监控分析的核心工具。PromQL 支持多种数据类型:瞬时向量(Instant Vector)表示某一时刻的一组时间序列;范围向量(Range Vector)表示某一时间范围内的一组时间序列;标量(Scalar)表示一个数值;字符串(String)表示一个字符串值。
在大模型服务监控中,PromQL 的典型应用场景包括:计算某个模型的平均响应延迟(使用 `rate()` 函数计算增长率),分析 Token 消耗趋势(使用 `increase()` 函数计算增量),检测异常情况(使用 `max()` 或 `min()` 函数结合阈值比较)。
-- LLM 调用成功率(最近 5 分钟)
sum(rate(llm_calls_total{status="success"}[5m]))
/ sum(rate(llm_calls_total[5m])) * 100
-- 各模型调用量分布
sum by (model) (rate(llm_calls_total[5m]))
-- P99 延迟(按模型分组)
histogram_quantile(0.99,
sum by (model, le) (rate(llm_latency_bucket[5m]))
)
-- Token 消耗速率(每分钟)
sum by (model) (rate(llm_tokens_total[1m])) * 60
-- 活跃请求数突增告警
sum by (application) (llm_api_active_requests) > 100
14.3.2 大模型服务监控大盘设计
Grafana 大盘是监控数据可视化的核心工具。一个设计良好的大盘应该能够回答运维人员最关心的问题:当前系统是否健康?如果不健康,问题在哪里?需要采取什么行动?
对于大模型服务的监控大盘,建议采用分层布局:顶部放置全局健康状态的概览卡片,包括服务可用性、总体延迟、请求量等核心指标;中部放置细分维度的详细图表,包括各模型的性能对比、错误分布、Token 消耗等;底部放置最近告警和异常请求列表,提供快速响应入口。
{
"dashboard": {
"title": "LLM Service Monitoring",
"panels": [
{
"id": 1,
"title": "Service Availability",
"type": "stat",
"gridPos": {"h": 6, "w": 6, "x": 0, "y": 0},
"targets": [{
"expr": "sum(rate(llm_calls_total{status=\"success\"}[5m])) / sum(rate(llm_calls_total[5m])) * 100",
"legendFormat": "Availability %"
}],
"fieldConfig": {
"defaults": {
"unit": "percent",
"thresholds": {
"mode": "absolute",
"steps": [
{"value": 0, "color": "red"},
{"value": 95, "color": "yellow"},
{"value": 99, "color": "green"}
]
}
}
}
},
{
"id": 2,
"title": "Average Latency by Model",
"type": "timeseries",
"gridPos": {"h": 8, "w": 12, "x": 6, "y": 0},
"targets": [{
"expr": "histogram_quantile(0.95, sum by (model, le) (rate(llm_latency_bucket[5m])))",
"legendFormat": "{{model}}"
}]
},
{
"id": 3,
"title": "Token Consumption Trend",
"type": "timeseries",
"gridPos": {"h": 8, "w": 12, "x": 18, "y": 0},
"targets": [{
"expr": "sum by (model) (rate(llm_tokens_total[5m])) * 60",
"legendFormat": "{{model}} tokens/min"
}]
}
]
}
}
14.3.3 智能告警规则配置
Prometheus AlertManager 是 Prometheus 生态中的告警处理组件,负责接收、处理和路由告警通知。一个完善的告警体系需要考虑告警触发条件、告警分组、告警静默、告警通知等多个环节。
在大模型服务场景中,告警规则的设计需要特别注意避免误报和漏报。由于大模型调用的固有延迟波动,单纯的单次超时不应该触发严重告警,而应该设置合理的窗口期和阈值。同时,由于大模型服务的特殊性,某些告警可能需要考虑业务高峰和低峰的时间因素。
# Prometheus 告警规则配置
groups:
- name: llm-service-alerts
rules:
# 服务不可用告警
- alert: LLMServiceDown
expr: up{job="llm-api"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "LLM Service is down"
description: "LLM API service has been down for more than 1 minute"
# 调用失败率过高
- alert: LLMCallFailureRateHigh
expr: |
sum(rate(llm_calls_total{status="error"}[5m]))
/ sum(rate(llm_calls_total[5m])) > 0.05
for: 5m
labels:
severity: warning
annotations:
summary: "LLM call failure rate exceeds 5%"
description: "模型调用失败率在5分钟内持续超过5%"
# 延迟突增告警
- alert: LLM LatencySpike
expr: |
histogram_quantile(0.99, sum by (model, le) (rate(llm_latency_bucket[5m]))) > 30000
for: 3m
labels:
severity: warning
annotations:
summary: "LLM latency spike detected for {{ $labels.model }}"
description: "模型 {{ $labels.model }} P99延迟超过30秒"
# Token 消耗异常
- alert: TokenConsumptionAnomaly
expr: |
sum by (model) (increase(llm_tokens_total[1h])) > 1.5 * avg_over_time(sum by (model) (increase(llm_tokens_total[1h]))[7d:1h])
for: 10m
labels:
severity: info
annotations:
summary: "Token consumption anomaly for {{ $labels.model }}"
14.4.1 模型调用质量监控
除了传统的性能指标外,大模型服务还需要关注模型调用质量的特殊指标。这些指标反映了模型输出的有效性,虽然难以通过技术手段完全自动化评估,但可以通过代理指标进行间接监控。
首次响应时间(Time to First Token,TTFT)是衡量流式输出场景下用户体验的重要指标。在流式对话中,用户不需要等待完整的回答生成完成,而是逐步看到模型生成的文字。TTFT 越短,用户感知到的响应速度越快。这个指标受网络延迟、模型加载时间、推理速度等多重因素影响。通过监控 TTFT,可以及时发现模型服务端的性能退化。
首次响应时间的监控实现通常需要在客户端和流式处理逻辑中嵌入计时逻辑。在 OpenAI 的流式 API 中,可以监听 `data: [" DONE"]` 或类似的事件来标识流式响应的开始。
// TTFT 监控实现
@Service
public class StreamingLlmMonitor {
private final MeterRegistry registry;
public StreamingLlmMonitor(MeterRegistry registry) {
this.registry = registry;
}
public Flux<String> chatStream(ChatRequest request) {
Timer.Sample sample = Timer.start(registry);
AtomicBoolean firstTokenReceived = new AtomicBoolean(false);
long ttft = 0;
return delegate.chatStream(request)
.publishOn(Schedulers.boundedElastic())
.doOnNext(chunk -> {
if (!firstTokenReceived.get()) {
ttft = sample.elapsed(TimeUnit.MILLISECONDS);
firstTokenReceived.set(true);
// 记录 TTFT 指标
registry.timer("llm.time.to.first.token",
"model", request.getModel())
.record(ttft, TimeUnit.MILLISECONDS);
}
})
.doOnComplete(() -> {
// 记录总耗时
sample.stop(Timer.builder("llm.stream.duration")
.tag("model", request.getModel())
.register(registry));
});
}
}
14.4.2 Token 消耗与成本监控
Token 消耗是监控大模型服务成本的核心指标。由于大模型服务通常按照 Token 用量计费,精确的 Token 监控不仅有助于成本控制,还能帮助识别异常消耗和潜在的安全问题。
Token 监控需要关注几个关键维度:按模型的消耗分布,按时间周期的消耗趋势,按用户/应用的消耗排名,以及按操作类型(对话、Embedding 等)的消耗结构。
// Token 消耗计数器
@Component
public class TokenConsumptionTracker {
private final MeterRegistry registry;
private final Map<String, AtomicLong> userConsumptions = new ConcurrentHashMap<>();
public void trackPromptTokens(String userId, String model, int tokens) {
registry.counter("llm.tokens.consumed",
"model", model,
"type", "prompt",
"user_id", userId)
.increment(tokens);
// 追踪用户累计消耗
userConsumptions.computeIfAbsent(userId, k -> new AtomicLong())
.addAndGet(tokens);
// 记录用户消耗分位数
Gauge.builder("llm.user.total.tokens", userConsumptions, map ->
map.getOrDefault(userId, new AtomicLong()).doubleValue())
.tag("user_id", userId)
.register(registry);
}
public void trackCompletionTokens(String userId, String model, int tokens) {
registry.counter("llm.tokens.consumed",
"model", model,
"type", "completion",
"user_id", userId)
.increment(tokens);
}
// 检查用户是否超过配额
public boolean checkUserQuota(String userId, long quota) {
long current = userConsumptions.getOrDefault(userId, new AtomicLong()).get();
return current < quota;
}
}
14.4.3 模型降级与熔断策略
在大模型服务架构中,模型降级和熔断机制是保障服务韧性的关键。当主模型服务不可用或响应质量下降时,系统应该能够自动切换到备用模型或降级服务,避免整体故障。
熔断器模式是实现这一目标的核心技术。Netflix Hystrix 是最早流行的熔断器实现,虽然目前已进入维护模式,但其核心思想仍被广泛采用。Resilience4j 是 Spring Cloud Circuit Breaker 的默认实现,提供了更加轻量级和函数式的 API。
在大模型场景中,熔断器的触发条件可以包括:连续失败次数超过阈值、错误率超过阈值、响应延迟超过阈值等。熔断触发后,后续请求会直接返回降级响应,而不是继续调用不可用的服务。经过一段冷却时间后,熔断器会进入半开状态,允许一个试探性请求,如果成功则关闭熔断器恢复正常。
// 基于 Resilience4j 的 LLM 熔断器配置
@Configuration
public class LlmCircuitBreakerConfig {
@Bean
public Registry<CircuitBreakerConfig> circuitBreakerRegistry() {
CircuitBreakerConfig defaultConfig = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // 失败率阈值 50%
.slowCallRateThreshold(80) // 慢调用率阈值 80%
.slowCallDurationThreshold(Duration.ofSeconds(10)) // 超过10秒视为慢调用
.waitDurationInOpenState(Duration.ofSeconds(30)) // 熔断开放30秒后进入半开
.permittedNumberOfCallsInHalfOpenState(3) // 半开状态允许3个试探请求
.slidingWindowType(SlidingWindowType.COUNT_BASED)
.slidingWindowSize(10) // 基于最近10次调用判断
.build();
return CircuitBreakerRegistry.of(defaultConfig);
}
@Bean
public CircuitBreakerRegistryMeterBinder circuitBreakerMeterBinder() {
return registry -> registry.getAllCircuitBreakers();
}
}
// 使用熔断器包装 LLM 调用
@Service
public class ResilientLlmClient {
private final LlmClient delegate;
private final CircuitBreaker llmCircuitBreaker;
public ResilientLlmClient(LlmClient delegate,
Registry<CircuitBreakerConfig> registry) {
this.delegate = delegate;
this.llmCircuitBreaker = registry.circuitBreaker("llmApi");
}
public LlmResponse chat(ChatRequest request) {
return CircuitBreaker.decorateSupplier(llmCircuitBreaker,
() -> delegate.chat(request)
).recover(throwable -> {
// 熔断触发时的降级处理
log.warn("LLM API circuit breaker triggered, using fallback", throwable);
return getFallbackResponse(request);
}).get();
}
private LlmResponse getFallbackResponse(ChatRequest request) {
// 返回降级响应,例如使用本地规则引擎或缓存的回答
return LlmResponse.fallback("服务繁忙,请稍后重试");
}
}
14.5.1 整体监控架构设计
综合前面章节的内容,我们可以设计一个完整的大模型服务监控架构。该架构采用分层设计,包括数据采集层、数据存储层、数据分析层和展示告警层。
数据采集层负责从各个微服务实例中收集指标和日志。在 Kubernetes 环境中,Prometheus Operator 是推荐的数据采集方案,它通过 CRD(Custom Resource Definition)管理 Prometheus 实例,实现了与 Kubernetes API 的深度集成。Fluent Bit 作为日志采集代理,运行在每个节点上,收集所有容器的日志并发送到 Loki。
数据存储层根据数据类型选择合适的存储引擎。时序数据(Metrics)存储在 Prometheus 中,通过 Thanos 或 Cortex 实现长期存储和高可用;日志数据存储在 Loki 中,支持高效的日志检索;追踪数据存储在 Tempo 中,支持端到端的请求追踪关联。
数据分析层是监控体系的大脑,负责数据的聚合、计算和告警判断。Prometheus AlertManager 处理告警的分组、静默和路由;Thanos Ruler 或 Prometheus Recording Rules 实现复杂指标的预计算;Grafana Explore 工具支持交互式的 PromQL 和 LogQL 查询。
展示告警层通过 Grafana 提供统一的可视化界面。Grafana 支持多数据源,可以在同一个大盘中展示来自 Prometheus、Loki、Tempo 的各类数据。告警通知通过 AlertManager 发送到企业微信、钉钉、飞书等协作平台。
14.5.2 关键监控指标体系定义
一个完善的大模型服务监控指标体系应该覆盖以下类别:
系统层指标包括 CPU 使用率、内存使用率、磁盘 I/O、网络吞吐等。这些指标反映基础设施的健康状况,是判断服务是否正常的基础。
JVM 层指标包括堆内存使用量、垃圾回收频率和耗时、线程池活跃线程数、类加载数量等。这些指标对于 Java 服务的性能分析至关重要。
HTTP 层指标包括请求速率、响应延迟分布、错误率、连接池使用率等。这些指标反映了服务间调用的质量。
LLM 特有指标包括 Token 消耗速率、API 调用延迟、首次响应时间、模型调用成功率、熔断器状态等。这些指标是大模型服务监控的核心。
业务层指标包括活跃会话数、平均对话轮次、用户满意度评分等。这些指标反映了服务对业务的支撑能力。
# Micrometer 指标定义规范
micrometer:
metrics:
export:
prometheus:
enabled: true
distribution:
percentiles-histogram:
http.server.requests: true
llm.api.call: true
percentiles:
http.server.requests: 0.5, 0.95, 0.99
llm.api.call: 0.5, 0.95, 0.99
slo:
http.server.requests: 50ms, 100ms, 200ms, 500ms
llm.api.call: 500ms, 1s, 5s, 10s
14.5.3 监控体系落地实施步骤
监控体系的建设是一个渐进式的过程,建议按照以下步骤逐步推进:
第一步,建立基础设施监控。将基本的系统指标和 JVM 指标接入 Prometheus,通过 Grafana 大盘展示。这一步工作量最小,但收益明显,能够快速建立起基础的监控能力。
第二步,埋点 LLM 特有指标。在 LLM 客户端代码中嵌入指标埋点,收集 Token 消耗、调用延迟、错误分布等数据。这一步需要开发团队的配合,建议作为 sprint 的技术债务进行偿还。
第三步,配置告警规则。根据业务需求配置告警规则,从简单的资源告警开始,逐步增加业务层面的告警。这一步需要与业务方充分沟通,确保告警阈值的合理性。
第四步,优化大盘和报告。建立运维值班大盘和定期报告机制,将监控数据转化为可行动的洞察。这一步是监控价值变现的关键。
本章系统性地介绍了微服务健康检查与监控的技术体系,重点关注了大模型服务场景下的特殊需求和解决方案。
从健康检查的理论基础出发,我们理解了多层级的检查架构如何覆盖从基础设施到业务指标的全方位监控。Spring Boot Actuator 与 Micrometer 的结合提供了标准化的指标暴露机制。Prometheus 与 Grafana 的组合则是云原生监控的事实标准。
在实践层面,我们详细介绍了如何设计大模型服务特有的监控指标,包括 Token 消耗、首次响应时间、模型调用质量等。通过 Resilience4j 实现的熔断器机制为服务韧性提供了保障。
监控体系的建设不是一蹴而就的,需要在实践中持续优化。建议读者从小处着手,先建立起基础的监控能力,再逐步完善细节,最终构建起覆盖全面、告警精准、响应及时的监控体系。



















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












